回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
上面的文字是百度百科对回溯算法的定义。怎么说呢,官方认可的肯定是正确无疑。但是却不是很利于理解。反正我个人而已看了好几次,逐词逐句的读,也只是有个简单的概念,具体怎么用还是一头雾水。我更喜欢被各位大佬所通俗理解后的解释。
什么是回溯算法
解决一个回溯问题,实际上就是一个决策树的遍历过程。
所谓决策树就是所有可选择的可能列出来的树。这个其实我们在不知道回溯,不懂算法的时候就已经有这个意识了(超喜欢这句话,其实所有的算法都是在实践基础上的整理和形成的规律。比如不懂dp,但是在有限范围的数字时我们会口算笔算,一个个词的加,这个也是动规的方法。)
无意识的回溯
我们在高中的时候就做过排列组合的数学题,我们也知道 n 个不重复的数,全排列共有 n! 个。
那么我们当时是怎么穷举全排列的呢?比方说给三个数 [1,2,3],你肯定不会无规律地乱穷举,一般是这样:
先固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;然后就只能变化第一位,变成 2,然后再穷举后两位……
其实这个过程不就是回溯么?只不过当时可能没有体系化的认识和学习,依靠的是本能来实现的。而现在在这里只不过是把这个本能整理成实实在在的数学思维和公式(其实我也不知道算不算公式,但是是有一套成型的框架)。
回溯框架
刚刚说了,这里就是把无意识的回溯整理成框架。
解决一个回溯问题,实际上就是一个决策树的遍历过程。你只需要思考 3 个问题:
路径:也就是已经做出的选择。
选择列表:也就是你当前可以做的选择。
结束条件:也就是到达决策树底层,无法再做选择的条件。
如果上文的名词你不是很理解,别着急继续往下看,会有更形象具体的解释。
咱们继续说刚刚的排列组合的题目,你可能有了一个简单的解决思路,然后穷举一点点写可能,但是我们可以更加形象的把它全部的思路“画”出来:
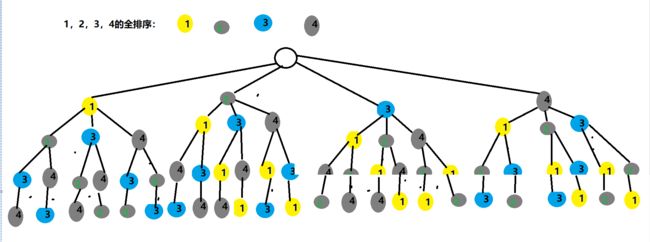
这个就是一个决策树。回到最上文,解决一个回溯问题,实际上就是一个决策树的遍历过程。
我用非算法,单纯的思路来表述这句话:每一个分支抛出去当前选择的节点和以前已选的节点,然后遍历剩下的节点。因为我例子是1,2,3,4四个数的全排序,如果换成1,2,3,4,5这个树将会成倍增加,此时整个树只是一个选择下的决策。1,2,3,4,5的图解应该是五颗这样的树。
咱们用刚刚的三个问题来看这个树和这个思路:
- 路径就是一个可能的路径,比如图中1-2-3-4就是一个完整路径。1,2就是一段路径。
- 选择列表就是可选的元素:比如第一个元素可以选择1,2,3,4任意元素,选择列表就是全元素。但是1-以后因为不可重复选择,所有选择列表只剩下2,3,4.再往下1-2后,选择列表只剩下3,4。以此类推
- 结束条件就是当选择列表没有元素了,这个路径就结束了。比如1,2,3,4后没有可选择的元素了,所以就结束了。
这么一说是不是对回溯有了很清晰的理解了?
回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
其实回溯的思路很好理解,但是怎么把它用代码实现是个问题。但是也没那么难。
ps:因为我只会java。所以所有的代码示例都用java写的,别的语言应该思路明确了就能写出来吧。
代码实现回溯的核心就一句话: for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」,特别简单.
这个应该很容易理解的,不抬杠的情况下,代码是一条路跑的。哪怕递归循环,也都是顺序执行代码。我们只能尽量让代码像是我们的思维一样一步一步走。
继续说这个1,2,3,4.
- 首先,让代码选择一个元素,正常按顺序应该是1,然后继续往下判断。我们可以用一些辅助的数组或者别的操作,使这个1被标记。说这条路径1已经被选择了。
- 选择完1后,递归操作,继续让代码再选择一个数。因为1已经被标记选择了,所以不可重复选择,所以继续选,选择了2。标记2。
- 再次递归,第三次选择。1,2都被标记了,只能继续往下选,选择3。标记3,递归。
- 第四次选择,选择了4。注意这个时候这条路径已经没有可选择的了。但是这个条件我们如果去看哪个元素可选太麻烦了,不如换个思路。一个就四个数,如果这条路径已经有四个元素了,是不是说已经没选择了?这就是结束条件。当我们发现list已经有四个元素,说明这个list已经是一条完整路径了,加到结果集,return跳出递归。
- 这里很重要,我们走到这里不是一层递归,而是层层递归,只跳出一层递归,是返回了上一层。也就是1,2,3,4路径跳出一层是变成了1,2,3,而我们还要注意,这个时候第四个节点选择4,都已经跳出来了,也应该把这个节点还原,所以list中这个4还是要删除的,这个也就是回溯的过程。
- 这个时候我们是在for循环里递归的,但是因为for循环中1,2,3都直接跳了,所以也只不过4能进循环,而4我们又跳出来了,所以这层代码也走完了,继续到上一层循环。到了1,2的路径,同时把第三个节点3回溯。
- 我们进入到1,2,之前选择3的这层递归已经走完了,该走选择4了,和选择3的代码走势是一样的,1,2,4,3走完,一层层循环往上走,结果集加了1,2,4,3。代码走回1,2,因为3,4都走完了,这层循环也运行完了,继续往上跳。同时回溯2,此时list中只有节点1了。
- 在第一个节点1时for循环2已经跳出来了,继续往下循环,变成了1,3.然后继续走。按顺序来,应该是1,3,2,4走到结束存到结果集,出了循环继续回溯,到了1,3能走到1,3,4,2。
- 等到1的第一个元素的所有路径都走完了,这个第一个元素换成2,重复走之前的所有流程,直到所有的情况都被遍历完,出了循环,这个时候结果集中的元素就是所有情况。
说了这么多附上java代码和题目:
例1
题目:给定一个没有重复数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
class Solution {
List> res = new LinkedList<>();
public List> permute(int[] nums) {
backtrack(nums, new boolean[nums.length], new LinkedList<>());
return res;
}
public void backtrack(int[] nums, boolean[] visited, LinkedList track) {
if (track.size() == nums.length) {
res.add(new LinkedList<>(track));
return;
}
for (int i = 0; i < nums.length; i++) {
if (visited[i]) {
continue;
}
visited[i] = true;
track.add(nums[i]);
backtrack(nums, visited, track);
track.removeLast();
visited[i] = false;
}
}
}
注意一下,以上的代码是没有重复元素。如果有的话又会分为是结果集不能相等还是怎么样。
例2
题目:给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
示例 1:
输入: candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
示例 2:
输入: candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
class Solution {
List> res;
public List> combinationSum(int[] candidates, int target) {
res = new ArrayList>();
List list = new ArrayList();
backtrack(0,candidates,target,list);
return res;
}
public void backtrack(int start,int[] candidates,int target,List list){
//结束条件1.都是非负数,当target小于0则肯定不行了,直接return
if(target<0){
return;
}else if(target==0){//结束条件2,等于0说明是结果集,因为非负数不用往下判断了。
res.add(new ArrayList(list));//这里list引用传递,不能直接add(list)
}else{//到这说明target大于0.继续挨个算
for(int i = start;i=candidates[i]){//如果target小于当前元素没必要算了
list.add(candidates[i]);
backtrack(i,candidates,target-candidates[i],list);
list.remove(list.size()-1);//回溯,删除最后一个元素
}
}
}
}
}
这个题看似和第一个差不多,但是还是有细小的区别,比如这个元素可重复使用,所以这里遍历是从start开始。
例3
题目:给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。candidates 中的每个数字在每个组合中只能使用一次。
说明:
所有数字(包括目标数)都是正整数。
解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
所求解集为:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
所求解集为:
[
[1,2,2],
[5]
]
class Solution {
List> res;
public List> combinationSum2(int[] candidates, int target) {
if(candidates.length==0) return res;
res = new ArrayList>();
Arrays.sort(candidates);
dfs(0,candidates,target,new ArrayList());
return res;
}
public void dfs(int start,int[] array,int target, List list){
if(target<0) return;
if(target==0){
res.add(new ArrayList(list));
}else{
for(int i = start;istart && array[i]==array[i-1]) continue;
if(target>=array[i]){
list.add(array[i]);
dfs(i+1,array,target-array[i],list);
list.remove(list.size()-1);
}
}
}
}
}
这个代码和例2其实差不多是一样的,区别就是多了个判断,就是如果相同元素则后面的直接跳过。
例4
题目;给定一个可包含重复数字的序列,返回所有不重复的全排列。
示例:
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]
class Solution {
List> res;
public List> permuteUnique(int[] nums) {
Arrays.sort(nums);
res = new ArrayList>();
List list = new ArrayList();
boolean[] flag = new boolean[nums.length];
dfs(nums,flag,list);
return res;
}
public void dfs(int[] nums,boolean[] flag, List list){
if(list.size()==nums.length){
res.add(new ArrayList(list));
return;
}
for(int i = 0;i0 && nums[i]==nums[i-1] && !flag[i-1]) continue;
flag[i] = true;
list.add(nums[i]);
dfs(nums,flag,list);
list.remove(list.size()-1);
flag[i] = false;
}
}
}
(因为我写这个笔记的时候只刷了这四道题,不过感觉挺典型的,以后刷到了会继续写上的)
通过上面的四个例子其实很容易看出点什么,就是每一个虽然题目啊,结束条件啊,细节啊都有所不同,但是代码的主体是不变的!
那就是for循环里添加,递归,回溯(删除)。
也就是上文说的:for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」
剪枝
其实这个剪枝我个人感觉和回溯不是必然联系。而是使用的时候多一起使用。比如上面例子中,不可重复数组元素,就用到了剪枝。target小于0也用到了剪枝。
就是某条路径还没有走完,但是因为已经不符合条件了,所以直接这个路径就不走了。
剪枝只是为了减少时间复杂度,可以直接pass很多无用的可能性。
简单说几个例子:
- 例2中target小于0,直接剪枝,因为不可能有正确结果集了。
- 例3中,因为每个元素只能使用一次,并且结果集不能相同,所以相同元素直接剪枝
if(i>start && array[i]==array[i-1]) continue; - 例4中,也是不能结果集重复元素,所以重复判断不做,相同元素如果已经排序了则剩余的直接剪枝。
我更加觉得剪枝是一种优化而不是必要。我们使用剪枝是为了使代码性能更好,最开始我就说了回溯本身就是穷举法,时间复杂度肯定不低,剪枝是在这基础上尽量少做无用功。
反正我的态度就是先弄明白回溯,然后在这基础上熟悉,然后做到”剪枝“。
总结
回溯算法就是个多叉树的遍历问题,关键就是在前序遍历和后序遍历的位置做一些操作。
只要弄懂框架别的其实不是难。
某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而上面的几个例子都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。