Mybatis(三)Mybatis源码解析(中)
文章目录
-
- 一、SQL 执行流程
-
- 1.1 SQL 执行入口
-
- 1.1.1 为 Mapper 接口创建代理对象
- 1.1.2 执行代理逻辑
- 1.2 查询语句的执行过程
-
- 1.2.1 selectOne 方法
- 1.2.2 获取 BoundSql
- 1.2.3 创建 StatementHandler
- 1.2.4 设置运行时参数到 SQL 中
- 1.2.5 #{}占位符的解析与参数的设置过程梳理
- 1.2.6 处理查询结果
- 1.3 更新语句的执行过程
-
- 1.3.1 更新语句执行过程全貌
- 1.3.2 KeyGenerator
- 1.3.3 处理更新结果
- 1.4 SQL 执行过程总结
- 二、内置数据源
-
- 2.1 内置数据源初始化过程
- 2.2 UnpooledDataSource
- 2.3 PooledDataSource
-
- 2.3.1 辅助类
- 2.3.2 获取连接
- 2.3.3 回收连接
一、SQL 执行流程
经过前面复杂的解析过程后,现在MyBatis 已经进入了就绪状态,等待使用者调用。
MyBatis 执行 SQL 的过程比较复杂,涉及的技术点很多。包括但不限于以下技术点:
- 为 mapper 接口生成实现类
- 根据配置信息生成 SQL,并将运行时参数设置到 SQL 中
- 一二级缓存的实现
- 插件机制
- 数据库连接的获取与管理
- 查询结果的处理,以及延迟加载等
本章仅分析以上列表中的第 1 个、第 2 个以及第 6 个技术点。
1.1 SQL 执行入口
在单独使用 MyBatis 进行数据库操作时,我们通常都会先调用 SqlSession 接口的getMapper方法为我们的Mapper接口生成实现类。然后就可以通过Mapper进行数据库操作。
ArticleMapper articleMapper = session.getMapper(ArticleMapper.class);
Article article = articleMapper.findOne(1);
先来看一下 Mapper 接口的代理对象创建过程。
1.1.1 为 Mapper 接口创建代理对象
从 DefaultSqlSession(位于org.apache.ibatis.session.defaults) 的 getMapper 方法开始看起:
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}
接着看Configuration(位于org.apache.ibatis.session):
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
接着MapperRegistry(位于org.apache.ibatis.binding):
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 从 knownMappers 中获取与 type 对应的 MapperProxyFactory
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 创建代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
MyBatis 在解析配置文件的节点的过程中,会调用MapperRegistry 的 addMapper 方法将 Class 到 MapperProxyFactory 对象的映射关系存入到knownMappers。
在获取到 MapperProxyFactory 对象后,即可调用工厂方法为 Mapper 接口生成代理对象,看MapperProxyFactory(位于org.apache.ibatis.binding):
public T newInstance(SqlSession sqlSession) {
// 创建 MapperProxy 对象,MapperProxy 实现了 InvocationHandler 接口,
// 代理逻辑封装在此类中
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
// 通过 JDK 动态代理创建代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] {
mapperInterface }, mapperProxy);
}
首先创建了一个 MapperProxy 对象,该对象实现了InvocationHandler 接口。然后将对象作为参数传给重载方法,并在重载方法中调用 JDK 动态代理接口为 Mapper 生成代理对象。代理对象已经创建完毕,下面就可以调用接口方法进行数据库操作了。
1.1.2 执行代理逻辑
Mapper 接口方法的代理逻辑首先会对拦截的方法进行一些检测,以决定是否执行后续的数据库操作。看MapperProxy(位于org.apache.ibatis.binding):
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 如果方法是定义在 Object 类中的,则直接调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
MapperMethodInvoker invoker = methodCache.get(method);
if (invoker != null) {
return invoker;
}
return methodCache.computeIfAbsent(method, m -> {
if (m.isDefault()) {
try {
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
} catch (IllegalAccessException | InstantiationException | InvocationTargetException
| NoSuchMethodException e) {
throw new RuntimeException(e);
}
} else {
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}
private static class PlainMethodInvoker implements MapperMethodInvoker {
private final MapperMethod mapperMethod;
public PlainMethodInvoker(MapperMethod mapperMethod) {
super();
this.mapperMethod = mapperMethod;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
// 调用 execute 方法执行 SQL
return mapperMethod.execute(sqlSession, args);
}
}
代理逻辑会首先检测被拦截的方法是不是定义在 Object 中的,比如 equals、hashCode 方法等。对于这类方法,直接执行即可。完成相关检测后,者创建 MapperMethod 对象,然后通过该对象中的 execute 方法执行 SQL。们先来看一下 MapperMethod 对象的创建过程。
- 1、 创建 MapperMethod 对象
MapperMethod (位于org.apache.ibatis.binding):
public class MapperMethod {
private final SqlCommand command;
private final MethodSignature method;
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
// 创建 SqlCommand 对象,该对象包含一些和 SQL 相关的信息
this.command = new SqlCommand(config, mapperInterface, method);
// 创建 MethodSignature 对象,由类名可知,该对象包含了被拦截方法的一些信息
this.method = new MethodSignature(config, mapperInterface, method);
}
}
MapperMethod 构造方法的逻辑很简单,主要是创建 SqlCommand 和 MethodSignature 对象。
- 2、 创建 SqlCommand对象
SqlCommand(在MapperMethod 类中) 中保存了一些和 SQL 相关的信息:
public static class SqlCommand {
private final String name;
private final SqlCommandType type;
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
// 解析 MappedStatement
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
// 检测当前方法是否有对应的 MappedStatement
if (ms == null) {
// 检测当前方法是否有 @Flush 注解
if (method.getAnnotation(Flush.class) != null) {
// 设置 name 和 type 遍历
name = null;
type = SqlCommandType.FLUSH;
} else {
// 若 ms == null 且方法无 @Flush 注解,此时抛出异常。
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
// 设置 name 和 type 变量
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
}
SqlCommand 的构造方法主要用于初始化它的两个成员变量。
- 3、 创建 MethodSignature对象
MethodSignature(在MapperMethod 类中) 即方法签名,顾名思义,该类保存了一些和目标方法相关的信息。比如目标方法的返回类型,目标方法的参数列表信息等。
public static class MethodSignature {
private final boolean returnsMany;
private final boolean returnsMap;
private final boolean returnsVoid;
private final boolean returnsCursor;
private final boolean returnsOptional;
private final Class<?> returnType;
private final String mapKey;
private final Integer resultHandlerIndex;
private final Integer rowBoundsIndex;
private final ParamNameResolver paramNameResolver;
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {
// 通过反射解析方法返回类型
Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);
if (resolvedReturnType instanceof Class<?>) {
this.returnType = (Class<?>) resolvedReturnType;
} else if (resolvedReturnType instanceof ParameterizedType) {
this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();
} else {
this.returnType = method.getReturnType();
}
// 检测返回值类型是否是 void、集合或数组、Cursor、Map 等
this.returnsVoid = void.class.equals(this.returnType);
this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray();
this.returnsCursor = Cursor.class.equals(this.returnType);
this.returnsOptional = Optional.class.equals(this.returnType);
// 解析 @MapKey 注解,获取注解内容
this.mapKey = getMapKey(method);
this.returnsMap = this.mapKey != null;
// 获取 RowBounds 参数在参数列表中的位置,如果参数列表中
// 包含多个 RowBounds 参数,此方法会抛出异常
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
// 获取 ResultHandler 参数在参数列表中的位置
this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);
// 解析参数列表
this.paramNameResolver = new ParamNameResolver(configuration, method);
}
}
上面的代码用于检测目标方法的返回类型,以及解析目标方法参数列表。其中,检测返回类型的目的是为避免查询方法返回错误的类型。下面分析参数列表的解析过程,即ParamNameResolver(位于org.apache.ibatis.reflection):
public class ParamNameResolver {
public static final String GENERIC_NAME_PREFIX = "param";
private final boolean useActualParamName;
private final SortedMap<Integer, String> names;
private boolean hasParamAnnotation;
public ParamNameResolver(Configuration config, Method method) {
this.useActualParamName = config.isUseActualParamName();
// 获取参数类型列表
final Class<?>[] paramTypes = method.getParameterTypes();
// 获取参数注解
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
final SortedMap<Integer, String> map = new TreeMap<>();
int paramCount = paramAnnotations.length;
// get names from @Param annotations
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
// 检测当前的参数类型是否为 RowBounds 或 ResultHandler
if (isSpecialParameter(paramTypes[paramIndex])) {
// skip special parameters
continue;
}
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
hasParamAnnotation = true;
// 获取 @Param 注解内容
name = ((Param) annotation).value();
break;
}
}
// name 为空,表明未给参数配置 @Param 注解
if (name == null) {
// 检测是否设置了 useActualParamName 全局配置
if (useActualParamName) {
// 通过反射获取参数名称。此种方式要求 JDK 版本为 1.8+,
// 且要求编译时加入 -parameters 参数,否则获取到的参数名
// 仍然是 arg1, arg2, ..., argN
name = getActualParamName(method, paramIndex);
}
if (name == null) {
/*
* 使用 map.size() 返回值作为名称,思考一下为什么不这样写:
* name = String.valueOf(paramIndex);
* 因为如果参数列表中包含 RowBounds 或 ResultHandler,这两个
* 参数会被忽略掉,这样将导致名称不连续。
* 比如参数列表 (int p1, int p2, RowBounds rb, int p3)
* - 期望得到名称列表为 ["0", "1", "2"]
* - 实际得到名称列表为 ["0", "1", "3"]
*/
name = String.valueOf(map.size());
}
}
// 存储 paramIndex 到 name 的映射
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
}
方法参数列表解析完毕后,可得到参数下标与参数名的映射关系,这些映射关系最终存储在 ParamNameResolver 的 names 成员变量中。
- 4、 执行 execute 方法
已经分析了 MapperMethod 的初始化过程,接下来要做的事情是调用 MapperMethod 的 execute 方法,执行 SQL。看MapperMethod:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 根据 SQL 类型执行相应的数据库操作
switch (command.getType()) {
case INSERT: {
// 对用户传入的参数进行转换,
Object param = method.convertArgsToSqlCommandParam(args);
// 执行插入操作,rowCountResult 方法用于处理返回值
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行更新操作
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行删除操作
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
// 根据目标方法的返回类型进行相应的查询操作
if (method.returnsVoid() && method.hasResultHandler()) {
// 如果方法返回值为 void,但参数列表中包含 ResultHandler,表明
// 使用者想通过 ResultHandler 的方式获取查询结果,而非通过返回值
// 获取结果
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 执行查询操作,并返回多个结果
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 执行查询操作,并将结果封装在 Map 中返回
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 执行查询操作,并返回一个 Cursor 对象
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行查询操作,并返回一个结果
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
// 执行刷新操作
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
// 如果方法的返回值为基本类型,而返回值却为 null,此种情况下应抛出异常
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
上面多次出现了convertArgsToSqlCommandParam:
public Object convertArgsToSqlCommandParam(Object[] args) {
return paramNameResolver.getNamedParams(args);
}
接着看ParamNameResolver:
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
/*
* 如果方法参数列表无 @Param 注解,且仅有一个非特别参数,则返回该
* 参数的值。比如如下方法:
* List findList(RowBounds rb, String name)
* names 如下:
* names = {1 : "0"}
* 此种情况下,返回 args[names.firstKey()],即 args[1] -> name
*/
Object value = args[names.firstKey()];
return wrapToMapIfCollection(value, useActualParamName ? names.get(0) : null);
} else {
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
// 添加 <参数名, 参数值> 键值对到 param 中
param.put(entry.getValue(), args[entry.getKey()]);
// genericParamName = param + index。比如 param1, param2,... paramN
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
// 检测 names 中是否包含 genericParamName,什么情况下会包含?
// 答案如下:使用者显式将参数名称配置为 param1,即 @Param("param1")
if (!names.containsValue(genericParamName)) {
// 添加 到 param 中
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
MyBatis 对哪些 SQL 指令提供了支持,如下:
查询语句:SELECT
更新语句:INSERT/UPDATE/DELETE
存储过程:CALL
这里把 SELECT 称为查询语句,INSERT/UPDATE/DELETE 等称为更新语句。
1.2 查询语句的执行过程
查询语句对应的方法比较多,有如下几种:
executeWithResultHandler
executeForMany
executeForMap
executeForCursor
这些方法在内部调用了 SqlSession 中的一些 select类方法,比如 selectList、selectMap、selectCursor 等。这些方法的返回值类型是不同的,因此对于每种返回类型,需要有专门的处理方法。以 selectList 方法为例,该方法的返回值类型为 List。但如果我们的 Mapper 或 Dao的接口方法返回值类型为数组,或者 Set,直接将 List 类型的结果返回给 Mapper/Dao 就不合适。execute类等方法只是对 select类等方法做了一层简单的封装,因此接下来我们应们应该把目光放在这些 select类方法上。
1.2.1 selectOne 方法
是 selectOne 在内部会调用 selectList 方法,分析 selectOne 方法等同于分析selectList 方法。看DefaultSqlSession(位于org.apache.ibatis.session.defaults):
public <T> T selectOne(String statement, Object parameter) {
// 调用 selectList 获取结果
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
// 返回结果
return list.get(0);
} else if (list.size() > 1) {
// 如果查询结果大于 1 则抛出异常,
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
下面来看看 selectList 方法的实现。
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
private final Executor executor;
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
// 获取 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
// 调用 Executor 实现类中的 query 方法
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
上面的executor 变量,该变量类型为 Executor。Executor 是一个接口,它的实现类:
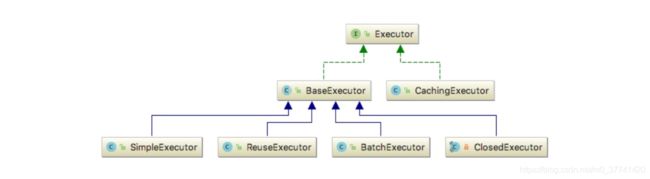
默认情况下,executor 的类型为 CachingExecutor,该类是一
个装饰器类,用于给目标 Executor 增加二级缓存功能。那目标 Executor 是谁呢?默认情况下是 SimpleExecutor。
继续分析 selectOne 方法的调用栈。先来看看 CachingExecutor(位于org.apache.ibatis.executor) 的 query 方法是怎样实现的。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取 BoundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建 CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 调用重载方法
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
于获取 BoundSql 对象,创建 CacheKey 对象,然后再将这两个对象传给重载方法。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 从 MappedStatement 中获取缓存
Cache cache = ms.getCache();
// 若映射文件中未配置缓存或参照缓存,此时 cache = null
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 若缓存未命中,则调用被装饰类的 query 方法
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 调用被装饰类的 query 方法
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
以上代码涉及到了二级缓存,若二级缓存为空,或未命中,则调用被装饰类的 query 方法。下面来看一下 BaseExecutor(位于org.apache.ibatis.executor) 的中签名相同的 query 方法是如何实现的。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 从一级缓存中获取缓存项
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 存储过程相关处理逻辑
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 一级缓存未命中,则从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 从一级缓存中延迟加载嵌套查询结果
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
上面的方法主要用于从一级缓存中查找查询结果,若缓存未命中,再向数据库进行查询。在上面的代码中,出现了一个新的类 DeferredLoad,这个类用于延迟加载。接来下看下queryFromDatabase 方法:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 向缓存中存储一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 调用 doQuery 进行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 移除占位符
localCache.removeObject(key);
}
// 缓存查询结果
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
上面的代码仍然不是 selectOne 方法调用栈的终点,抛开缓存操作,queryFromDatabase最终还会调用 doQuery 进行查询。接下来看下SimpleExecutor(位于org.apache.ibatis.executor)中的doQuery :
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询操作
return handler.query(stmt, resultHandler);
} finally {
// 关闭 Statement
closeStatement(stmt);
}
}
先跳过 StatementHandler 和 Statement 创建过程,这两个对象的创建过程会在后面进行说明。这里,我们以 PreparedStatementHandler(位于org.apache.ibatis.executor.statement)为例,看看它的 query 方法是怎样实现的。
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行 SQL
ps.execute();
// 处理执行结果
return resultSetHandler.handleResultSets(ps);
}
以上就是 selectOne 方法的执行过程。
1.2.2 获取 BoundSql
在执行 SQL 之前,需要将 SQL 语句完整的解析出来。我们都知道 SQL 是配置在映射文件中的,但由于映射文件中的 SQL 可能会包含占位符#{},以及动态 SQL 标签,比如

对片段树进行解析,以便从每个片段对象中获取相应的内容。然后将这些内容组合起来即可得到一个完成的 SQL 语句,这个完整的 SQL 以及其他的一些信息最终会存储在 BoundSql 对象中。BoundSql(位于org.apache.ibatis.mapping) 类的成员变量信息:
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Object parameterObject;
private final Map<String, Object> additionalParameters;
private final MetaObject metaParameters;
各个成员变量的含义:
| 变量名 | 类型 | 用途 |
|---|---|---|
| sql | String | 一个完整的 SQL 语句,可能会包含问号 ? 占位符 |
| parameterMappings | List | 参数映射列表,SQL 中的每个 #{xxx} 占位符都会被解析成相应的 ParameterMapping 对象 |
| parameterObject | Object | 运行时参数,即用户传入的参数,比如 Article 对象,或是其他的参数 |
| additionalParameters | Map | 附加参数集合,用于存储一些额外的信息,比如 datebaseId 等 |
| metaParameters | MetaObject | additionalParameters 的元信息对象 |
接下来,开始分析 BoundSql 的构建过程,首先是 MappedStatement (位于org.apache.ibatis.mapping)的 getBoundSql 方法:
public BoundSql getBoundSql(Object parameterObject) {
// 调用 sqlSource 的 getBoundSql 获取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
// 创建新的 BoundSql,这里的 parameterMap 是 ParameterMap 类型。
// 由 节点进行配置,该节点已经废弃,不推荐使用。
// 默认情况下,parameterMap.getParameterMappings() 返回空集合
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}
MappedStatement 的 getBoundSql 在内部调用了 SqlSource 实现类的 getBoundSql方法。处理此处的调用,余下的逻辑都不是重要逻辑。SqlSource 是一个接口,它有如下几个实现类:
DynamicSqlSource
RawSqlSource
StaticSqlSource
ProviderSqlSource
VelocitySqlSource
先我们把最后两个排除掉,不常用。剩下的三个实现类中,仅前两个实现类会在映射文件解析的过程中被使用。当 SQL 配置中包含${}(不是#{})占位符,或者包含
public BoundSql getBoundSql(Object parameterObject) {
// 创建 DynamicContext
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 解析 SQL 片段,并将解析结果存储到 DynamicContext 中
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 构建 StaticSqlSource,在此过程中将 sql 语句中的占位符 #{} 替换为问号 ?, 并为每个占位符构建相应的 ParameterMapping
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
// 调用 StaticSqlSource 的 getBoundSql 获取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 将 DynamicContext 的 ContextMap 中的内容拷贝到 BoundSql 中
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
DynamicSqlSource 的 getBoundSql 方法的步骤:
- 创建 DynamicContext
- 解析 SQL 片段,并将解析结果存储到 DynamicContext 中
- 解析 SQL 语句,并构建 StaticSqlSource
- 调用 StaticSqlSource 的 getBoundSql 获取 BoundSql
- 将 DynamicContext 的 ContextMap 中的内容拷贝到 BoundSql 中
- 1、DynamicContext
DynamicContext(位于org.apache.ibatis.scripting.xmltags)是 SQL 语句构建的上下文,每个 SQL 片段解析完成后,都会将解析结果存入 DynamicContext 中。待所有的 SQL 片段解析完毕后,一条完整的 SQL 语句就会出现在 DynamicContext 对象中。
public class DynamicContext {
public static final String PARAMETER_OBJECT_KEY = "_parameter";
public static final String DATABASE_ID_KEY = "_databaseId";
private final ContextMap bindings;
private final StringJoiner sqlBuilder = new StringJoiner(" ");
public DynamicContext(Configuration configuration, Object parameterObject) {
// 创建 ContextMap
if (parameterObject != null && !(parameterObject instanceof Map)) {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
boolean existsTypeHandler = configuration.getTypeHandlerRegistry().hasTypeHandler(parameterObject.getClass());
bindings = new ContextMap(metaObject, existsTypeHandler);
} else {
bindings = new ContextMap(null, false);
}
// 存放运行时参数 parameterObject 以及 databaseId
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
}
}
sqlBuilder 变量用于存放 SQL 片段的解析结果,bindings 则用于存储一些额外的信息,比如运行时参数和 databaseId 等。bindings类型为 ContextMap,ContextMap 定义在 DynamicContext 中,是一个静态内部类。该类继承自 HashMap,并覆写了 get 方法。
static class ContextMap extends HashMap<String, Object> {
private final MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject, boolean fallbackParameterObject) {
this.parameterMetaObject = parameterMetaObject;
this.fallbackParameterObject = fallbackParameterObject;
}
@Override
public Object get(Object key) {
String strKey = (String) key;
// 检查是否包含 strKey,若包含则直接返回
if (super.containsKey(strKey)) {
return super.get(strKey);
}
if (parameterMetaObject == null) {
return null;
}
if (fallbackParameterObject && !parameterMetaObject.hasGetter(strKey)) {
return parameterMetaObject.getOriginalObject();
} else {
// 从运行时参数中查找结果
return parameterMetaObject.getValue(strKey);
}
}
}
DynamicContext 对外提供了两个接口,用于操作 sqlBuilder:
public String getSql() {
return sqlBuilder.toString().trim();
}
public void appendSql(String sql) {
sqlBuilder.add(sql);
}
- 2、解析 SQL 片段
对于一个包含了KaTeX parse error: Expected 'EOF', got '&' at position 332: …r_FFFFFF,t_70) &̲emsp; 在众多实…{}占位符的文本,IfSqlNode 则用于存储
public class MixedSqlNode implements SqlNode {
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
// 遍历 SqlNode 集合,调用 salNode 对象本身的 apply 方法解析 sql
contents.forEach(node -> node.apply(context));
return true;
}
}
MixedSqlNode 可以看做是 SqlNode 实现类对象的容器,凡是实现了 SqlNode 接口的类都可以存储到 MixedSqlNode 中,包括它自己。MixedSqlNode 解析方法 apply 逻辑比较简单,即遍历 SqlNode 集合,并调用其他 SalNode 实现类对象的 apply 方法解析 sql。再看个StaticTextSqlNode(位于org.apache.ibatis.scripting.xmltags):
public class StaticTextSqlNode implements SqlNode {
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
}
StaticTextSqlNode 用于存储静态文本,所以它不需要什么解析逻辑,直接将其存储的SQL 片段添加到 DynamicContext 中即可。再看一下TextSqlNode(也在org.apache.ibatis.scripting.xmltags):
public class TextSqlNode implements SqlNode {
private final String text;
private final Pattern injectionFilter;
@Override
public boolean apply(DynamicContext context) {
// 创建 ${} 占位符解析器
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
// 解析 ${} 占位符,并将解析结果添加到 DynamicContext 中
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
// 创建占位符解析器,GenericTokenParser 是一个通用解析器,
// 并非只能解析 ${} 占位符
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
// 通过 ONGL 从用户传入的参数中获取结果
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
// 通过正则表达式检测 srtValue 有效性
checkInjection(srtValue);
return srtValue;
}
private void checkInjection(String value) {
if (injectionFilter != null && !injectionFilter.matcher(value).matches()) {
throw new ScriptingException("Invalid input. Please conform to regex" + injectionFilter.pattern());
}
}
}
}
GenericTokenParser 是一个通用的标记解析器,用于解析形如${xxx},#{xxx}等标记 。GenericTokenParser 负责将标记中的内容抽取出来,并将标记内容交给相应的TokenHandler 去处理。BindingTokenParser 负责解析标记内容,并将解析结果返回给GenericTokenParser,用于替换${xxx}标记。
比如:
SELECT * FROM article WHERE author = '${author}'
假设我们我们传入的 author 值为zhangsan,那么该 SQL 最终会被解析成如下的结果:
SELECT * FROM article WHERE author = 'zhangsan'
一般情况下,使用${author}接受参数都没什么问题。但是怕就怕在有人不怀好意,构建了一些恶意的参数。当用这些恶意的参数替换${author}时就会出现灾难性问题——SQL 注入。比如我们构建这样一个参数 author=zhangsan’;DELETE FROM article;#,然后我们把这个参数传给 TextSqlNode 进行解析。得到的结果如下:
SELECT * FROM article WHERE author = 'zhangsan'; DELETE FROM article;#'
该SQL 会把 article 表的数据清空,这个后果就很严重了。
接下来看IfSqlNode(也在org.apache.ibatis.scripting.xmltags):
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator;
private final String test;
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
@Override
public boolean apply(DynamicContext context) {
// 通过 ONGL 评估 test 表达式的结果
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// 若 test 表达式中的条件成立,则调用其他节点的 apply 方法进行解析
contents.apply(context);
return true;
}
return false;
}
}
IfSqlNode 对应的是
接下来看WhereSqlNode(也在org.apache.ibatis.scripting.xmltags):
public class WhereSqlNode extends TrimSqlNode {
/** 前缀列表 */
private static List<String> prefixList = Arrays.asList("AND ","OR ",
"AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 调用父类的构造方法
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
在 MyBatis 中,WhereSqlNode 和 SetSqlNode 都是基于 TrimSqlNode 实现的,WhereSqlNode 对应于
public class TrimSqlNode implements SqlNode {
private final SqlNode contents;
private final String prefix;
private final String suffix;
private final List<String> prefixesToOverride;
private final List<String> suffixesToOverride;
private final Configuration configuration;
public boolean apply(DynamicContext context) {
// 创建具有过滤功能的 DynamicContext
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
// 解析节点内容
boolean result = contents.apply(filteredDynamicContext);
// 过滤掉前缀和后缀
filteredDynamicContext.applyAll();
return result;
}
}
apply 方法首选调用了其他 SqlNode 的 apply 方法解析节点内容,这步操作完成后,FilteredDynamicContext 中会得到一条 SQL 片段字符串。接下里需要做的事情是过滤字符串前缀后和后缀,并添加相应的前缀和后缀。这个事情由 FilteredDynamicContext 负责,FilteredDynamicContext 是 TrimSqlNode 的私有内部类。
private class FilteredDynamicContext extends DynamicContext {
private DynamicContext delegate;
/** 构造方法会将下面两个布尔值置为 false */
private boolean prefixApplied;
private boolean suffixApplied;
private StringBuilder sqlBuffer;
public FilteredDynamicContext(DynamicContext delegate) {
super(configuration, null);
this.delegate = delegate;
this.prefixApplied = false;
this.suffixApplied = false;
this.sqlBuffer = new StringBuilder();
}
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
// 引用前缀和后缀,也就是对 sql 进行过滤操作,移除掉前缀或后缀
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
// 将当前对象的 sqlBuffer 内容添加到代理类中
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
// 设置 prefixApplied 为 true,以下逻辑仅会被执行一次
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
// 检测当前 sql 字符串是否包含前缀,比如 'AND ', 'AND\t'等
if (trimmedUppercaseSql.startsWith(toRemove)) {
// 移除前缀
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// 插入前缀,比如 WHERE
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
// 该方法逻辑与 applyPrefix 大同小异
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
if (!suffixApplied) {
suffixApplied = true;
if (suffixesToOverride != null) {
for (String toRemove : suffixesToOverride) {
if (trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim())) {
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
break;
}
}
}
if (suffix != null) {
sql.append(" ");
sql.append(suffix);
}
}
}
}
applyAll 方法的逻辑比较简单,首先从 sqlBuffer 中获取 SQL 字符串。然后调用 applyPrefix和 applySuffix 进行过滤操作。最后将过滤后的 SQL 字符串添加到被装饰的类中。applyPrefix方法会首先检测 SQL 字符串是不是以"AND",“OR”,或"AND\n","OR\n"等前缀开头,若是则将前缀从 sqlBuffer 中移除。然后将前缀插入到 sqlBuffer 的首部。
- 3、解析#{}占位符
经过前面的解析,我们已经能从 DynamicContext 获取到完整的 SQL 语句了。但这并不意味着解析过程就结束了,因为当前的 SQL 语句中还有一种占位符没有处理,即#{}。与${}占位符的处理方式不同,MyBatis 并不会直接将#{}占位符替换为相应的参数值。
#{}占位符的解析逻辑是包含在 SqlSourceBuilder (位于org.apache.ibatis.builder)的 parse 方法中,该方法最终会将解析后 的 SQL 以及其他的一些数据封装到 StaticSqlSource(位于org.apache.ibatis.builder) 中。
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
// 创建 #{} 占位符处理器
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 创建 #{} 占位符解析器
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
// 解析 #{} 占位符,并返回解析结果
String sql;
if (configuration.isShrinkWhitespacesInSql()) {
sql = parser.parse(removeExtraWhitespaces(originalSql));
} else {
sql = parser.parse(originalSql);
}
// 封装解析结果到 StaticSqlSource 中,并返回
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
重点关注#{}占位符处理器 ParameterMappingTokenHandler(是SqlSourceBuilder的静态内部类) 的逻辑。
private static class ParameterMappingTokenHandler extends BaseBuilder implements TokenHandler {
public String handleToken(String content) {
// 获取 content 的对应的 ParameterMapping
parameterMappings.add(buildParameterMapping(content));
return "?";
}
}
ParameterMappingTokenHandler 的 handleToken 方法看起来比较简单,但实际上并非如此。GenericTokenParser 负责将#{}占位符中的内容抽取出来,并将抽取出的内容传给handleToken 方法。handleToken 方法负责将传入的参数解析成对应的 ParameterMapping 对象,这步操作由 buildParameterMapping 方法完成。
private ParameterMapping buildParameterMapping(String content) {
/*
* 将 #{xxx} 占位符中的内容解析成 Map。大家可能很好奇一个普通的字符串是怎么解析成 Map 的,举例说明一下。如下:
* #{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
* 上面占位符中的内容最终会被解析成如下的结果:
* {
* "property": "age",
* "typeHandler": "MyTypeHandler",
* "jdbcType": "NUMERIC",
* "javaType": "int"
* }
* parseParameterMapping 内部依赖 ParameterExpression 对字符串进行解析
*/
Map<String, String> propertiesMap = parseParameterMapping(content);
String property = propertiesMap.get("property");
Class<?> propertyType;
// metaParameters 为 DynamicContext 成员变量 bindings 的元信息对象
if (metaParameters.hasGetter(property)) {
// issue #448 get type from additional params
propertyType = metaParameters.getGetterType(property);
/*
* parameterType 是运行时参数的类型。如果用户传入的是单个参数,比如 Article
* 对象,此时 parameterType 为 Article.class。如果用户传入的多个参数,比如
* [id = 1, author = "coolblog"],MyBatis 会使用 ParamMap 封装这些参数,
* 此时 parameterType 为 ParamMap.class。如果 parameterType 有相应的
* TypeHandler,这里则把 parameterType 设为 propertyType
*/
} else if (typeHandlerRegistry.hasTypeHandler(parameterType)) {
propertyType = parameterType;
} else if (JdbcType.CURSOR.name().equals(propertiesMap.get("jdbcType"))) {
propertyType = java.sql.ResultSet.class;
} else if (property == null || Map.class.isAssignableFrom(parameterType)) {
// 如果 property 为空,或 parameterType 是 Map 类型,
// 则将 propertyType 设为 Object.class
propertyType = Object.class;
} else {
// 代码逻辑走到此分支中,表明 parameterType 是一个自定义的类,
// 比如 Article,此时为该类创建一个元信息对象
MetaClass metaClass = MetaClass.forClass(parameterType, configuration.getReflectorFactory());
// 检测参数对象有没有与 property 想对应的 getter 方法
if (metaClass.hasGetter(property)) {
// 获取成员变量的类型
propertyType = metaClass.getGetterType(property);
} else {
propertyType = Object.class;
}
}
// -------------------------- 分割线 ---------------------------
ParameterMapping.Builder builder = new ParameterMapping.Builder(configuration, property, propertyType);
// 将 propertyType 赋值给 javaType
Class<?> javaType = propertyType;
String typeHandlerAlias = null;
// 遍历 propertiesMap
for (Map.Entry<String, String> entry : propertiesMap.entrySet()) {
String name = entry.getKey();
String value = entry.getValue();
if ("javaType".equals(name)) {
// 如果用户明确配置了 javaType,则以用户的配置为准
javaType = resolveClass(value);
builder.javaType(javaType);
} else if ("jdbcType".equals(name)) {
// 解析 jdbcType
builder.jdbcType(resolveJdbcType(value));
} else if ("mode".equals(name)) {
builder.mode(resolveParameterMode(value));
} else if ("numericScale".equals(name)) {
builder.numericScale(Integer.valueOf(value));
} else if ("resultMap".equals(name)) {
builder.resultMapId(value);
} else if ("typeHandler".equals(name)) {
typeHandlerAlias = value;
} else if ("jdbcTypeName".equals(name)) {
builder.jdbcTypeName(value);
} else if ("property".equals(name)) {
// Do Nothing
} else if ("expression".equals(name)) {
throw new BuilderException("Expression based parameters are not supported yet");
} else {
throw new BuilderException("An invalid property '" + name + "' was found in mapping #{" + content + "}. Valid properties are " + PARAMETER_PROPERTIES);
}
}
if (typeHandlerAlias != null) {
// 解析 TypeHandler
builder.typeHandler(resolveTypeHandler(javaType, typeHandlerAlias));
}
// 构建 ParameterMapping 对象
return builder.build();
}
buildParameterMapping 代码很多,只有 3 件事情。
- 解析 content
- 解析 propertyType,对应分割线之上的代码
- 构建 ParameterMapping 对象,对应分割线之下的代码
再来看一下 StaticSqlSource 的创建过程。
public class StaticSqlSource implements SqlSource {
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Configuration configuration;
public StaticSqlSource(Configuration configuration, String sql) {
this(configuration, sql, null);
}
public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.configuration = configuration;
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
// 创建 BoundSql 对象
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
}
1.2.3 创建 StatementHandler
StatementHandler 是一个非常核心接口,从代码分层的角度来说,StatementHandler 是 MyBatis 源码的边界,再往下层就是 JDBC 层面的接口了。在执行 SQL 之前,StatementHandler 需要创建合适的 Statement 对象,然后填充参数值到Statement 对象中,最后通过 Statement 对象执行 SQL。这还不算完,待 SQL 执行完毕,还要去处理查询结果等。
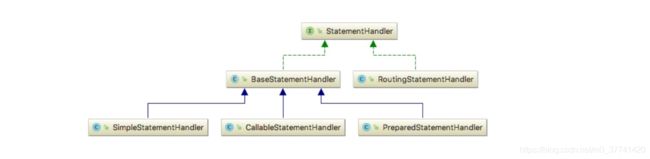 最下层的三种 StatementHandler 实现类与三种不同的 Statement 进行交互,这个不难看出来。但 RoutingStatementHandler 则是一个奇怪的存在,因为 JDBC 中并不存在RoutingStatement。
最下层的三种 StatementHandler 实现类与三种不同的 Statement 进行交互,这个不难看出来。但 RoutingStatementHandler 则是一个奇怪的存在,因为 JDBC 中并不存在RoutingStatement。
看一下Configuration:
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 创建具有路由功能的 StatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件到 StatementHandler 上
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
下面分析 RoutingStatementHandler (位于org.apache.ibatis.executor.statement)的代码。
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据 StatementType 创建不同的 StatementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
// 其他方法逻辑均由别的 StatementHandler 代理完成
}
RoutingStatementHandler 的构造方法会根据 MappedStatement 中的 statementType 变量创建不同的 StatementHandler 实现类。默认情况下,statementType 值为 PREPARED。关于StatementHandler 创建的过程就先分析到这,StatementHandler 创建完成了,后续要做到事情是创建 Statement,以及将运行时参数和 Statement 进行绑定。
1.2.4 设置运行时参数到 SQL 中
JDBC 提供了三种 Statement 接口,分别是 Statement 、 PreparedStatement 和CallableStatement。
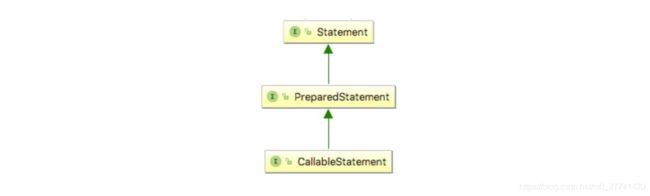
Statement 接口提供了执行 SQL,获取执行结果等基本功能。PreparedStatement 在此基础上,对 IN 类型的参数提供了支持。使得我们可以使用运行时参数替换 SQL 中的问号?占位符,而不用手动拼接 SQL。CallableStatement 则是在PreparedStatement 基础上,对 OUT 类型的参数提供了支持,该种类型的参数用于保存存储过程输出的结果。
本节将分析 PreparedStatement 的创建,以及设置运行时参数到 SQL 中的过程。Statement 的创建入口是在SimpleExecutor (位于org.apache.ibatis.executor)的 prepareStatement 方法中:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取数据库连接
Connection connection = getConnection(statementLog);
// 创建 Statement
stmt = handler.prepare(connection, transaction.getTimeout());
// 为 Statement 设置 IN 参数
handler.parameterize(stmt);
return stmt;
}
上面代码的三个步骤:
- 获取数据库连接
- 创建 Statement
- 为 Statement 设置 IN 参数
接下来,分析 PreparedStatement 的创建,以及 IN 参数设置的过程。按照顺序,先来分析 PreparedStatement 的创建过程,在BaseStatementHandler(位于org.apache.ibatis.executor.statement)中:
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 创建 Statement
statement = instantiateStatement(connection);
// 设置超时和 FetchSize
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
再看PreparedStatementHandler:
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
// 根据条件调用不同的 prepareStatement 方法创建 PreparedStatement
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
下面分析运行时参数是如何被设置到 SQL 中的,在PreparedStatementHandler中:
public void parameterize(Statement statement) throws SQLException {
// 通过参数处理器 ParameterHandler 设置运行时参数到 PreparedStatement 中
parameterHandler.setParameters((PreparedStatement) statement);
}
再看DefaultParameterHandler(位于org.apache.ibatis.scripting.defaults):
public class DefaultParameterHandler implements ParameterHandler {
private final TypeHandlerRegistry typeHandlerRegistry;
private final MappedStatement mappedStatement;
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 从 BoundSql 中获取 ParameterMapping 列表,每个 ParameterMapping
// 与原始 SQL 中的 #{xxx} 占位符一一对应
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 检测参数类型,排除掉 mode 为 OUT 类型的 parameterMapping
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
// 获取属性名
String propertyName = parameterMapping.getProperty();
// 检测 BoundSql 的 additionalParameters 是否包含 propertyName
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
// 检测运行时参数是否有相应的类型解析器
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
// 若运行时参数的类型有相应的类型处理器 TypeHandler,则将
// parameterObject 设为当前属性的值。
value = parameterObject;
} else {
// 为用户传入的参数 parameterObject 创建元信息对象
MetaObject metaObject = configuration.newMetaObject(parameterObject);
// 从用户传入的参数中获取 propertyName 对应的值
value = metaObject.getValue(propertyName);
}
// ---------------------分割线---------------------
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
// 此处 jdbcType = JdbcType.OTHER
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 由类型处理器 typeHandler 向 ParameterHandler 设置参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
}
分割线以上的大段代码用于获取#{xxx}占位符属性所对应的运行时参数。分割线以下的代码则是获取#{xxx}占位符属性对应的 TypeHandler,并在最后通过 TypeHandler将运行时参数值设置到 PreparedStatement 中。
1.2.5 #{}占位符的解析与参数的设置过程梳理
前面两节的内容比较多,本节将对前两节的部分内容进行梳理,以便大家能够更好理解这两节内容之间的联系。假设我们有这样一条 SQL 语句:
SELECT * FROM author WHERE name = #{name} AND age = #{age}
这个 SQL 语句中包含两个#{}占位符,在运行时这两个占位符会被解析成两个ParameterMapping 对象:
ParameterMapping{
property='name', mode=IN,
javaType=class java.lang.String, jdbcType=null, ...}
ParameterMapping{
property='age', mode=IN,
javaType=class java.lang.Integer, jdbcType=null, ...}
#{xxx}占位符解析完毕后,得到的 SQL:
SELECT * FROM Author WHERE name = ? AND age = ?
假设下面这个方法与上面的 SQL 对应:
Author findByNameAndAge(@Param("name")String name, @Param("age")Integer age)
该方法的参数列表会被 ParamNameResolver 解析成一个 map:
{
0: "name",
1: "age"
}
假设该方法在运行时有如下的调用:
findByNameAndAge("zhangsan", 20)
此时,需要再次借助 ParamNameResolver 的力量。这次我们将参数名和运行时的参数值绑定起来,得到如下的映射关系。
{
"name": "zhangsan",
"age": 20,
"param1": "zhangsan",
"param2": 20
}
下一步,我们要将运行时参数设置到 SQL 中。由于原 SQL 经过解析后,占位符信息已经被擦除掉了,我们无法直接将运行时参数 SQL 中。不过好在,这些占位符信息被记录在了 ParameterMapping 中了,MyBatis 会将 ParameterMapping 会按照#{}占位符的解析顺序存入到 List 中。这样我们通过 ParameterMapping 在列表中的位置确定它与 SQL 中的哪一个个?占位符相关联。同时通过 ParameterMapping 中的 property 字段,我们可以到“参数名与参数值”映射表中查找具体的参数值。这样,我们就可以将参数值准确的设置到 SQL 中了,此时SQL 如下:
SELECT * FROM Author WHERE name = "tianxiaobo" AND age = 20
当运行时参数被设置到 SQL 中后,下一步要做的事情是执行 SQL,然后处理 SQL 执行结果。对于更新操作,数据库一般返回一个 int 行数值,表示受影响行数,这个处理起来比较简单。但对于查询操作,返回的结果类型多变,处理方式也很复杂。接下来,我们就来看看 MyBatis 是如何处理查询结果的。
1.2.6 处理查询结果
MyBatis 可以将查询结果,即结果集 ResultSet 自动映射成实体类对象。这样使用者就无需再手动操作结果集,并将数据填充到实体类对象中。
在 MyBatis 中,结果集的处理工作由结果集处理器 ResultSetHandler 执行。ResultSetHandler 是一个接口,它只有一个实现类 DefaultResultSetHandler(位于org.apache.ibatis.executor.resultset)。结果集的处理入口方法是 handleResultSets:
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 获取第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
// 处理结果集
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {
// 获取结果集
ResultSet rs = stmt.getResultSet();
while (rs == null) {
/*
* 移动 ResultSet 指针到下一个上,有些数据库驱动可能需要使用者
* 先调用 getMoreResults 方法,然后才能调用 getResultSet 方法
* 获取到第一个 ResultSet
*/
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
// no more results. Must be no resultset
break;
}
}
}
/*
* 这里并不直接返回 ResultSet,而是将其封装到 ResultSetWrapper 中。
* ResultSetWrapper 中包含了 ResultSet 一些元信息,比如列名称、
* 每列对应的 JdbcType、以及每列对应的 Java 类名(class name,譬如
* java.lang.String)等。
*/
return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}
该方法首先从 Statement 中获取第一个结果集,然后调用 handleResultSet 方法对该结果集进行处理。一般情况下,如果我们不调用存储过程,不会涉及到多结果集的问题。
我们把目光聚焦在单结果集的处理逻辑上。
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
// 多结果集相关逻辑
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
/*
* 检测 resultHandler 是否为空。ResultHandler 是一个接口,使用者可
* 实现该接口,这样我们可以通过 ResultHandler 自定义接收查询结果的
* 动作。比如我们可将结果存储到 List、Map 亦或是 Set,甚至丢弃,
* 这完全取决于大家的实现逻辑。
*/
if (resultHandler == null) {
// 创建默认的结果处理器
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 处理结果集的行数据
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
// 处理结果集的行数据
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
handleRowValues 方法,该方法用于处理结果集中的数据。
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
// 处理嵌套映射
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 处理简单映射
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
handleRowValues 方法中针对两种映射方式进行了处理。一种是嵌套映射,另一种是简单映射。本文所说的嵌套查询是指
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
// 根据 RowBounds 定位到指定行记录
skipRows(resultSet, rowBounds);
// 检测是否还有更多行的数据需要处理
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 获取经过鉴别器处理后的 ResultMap
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 从 resultSet 中获取结果
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
// 存储结果
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
上面方法的逻辑:
- 根据 RowBounds 定位到指定行记录
- 循环处理多行数据
- 使用鉴别器处理 ResultMap
- 映射 ResultSet,得到映射结果 rowValue
- 存储结果
第一个步骤对应的代码逻辑:
private void skipRows(ResultSet rs, RowBounds rowBounds) throws SQLException {
// 检测 rs 的类型,不同的类型行数据定位方式是不同的
if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {
// 直接定位到 rowBounds.getOffset() 位置处
rs.absolute(rowBounds.getOffset());
}
} else {
for (int i = 0; i < rowBounds.getOffset(); i++) {
/*
* 通过多次调用 rs.next() 方法实现行数据定位。
* 当 Offset 数值很大时,这种效率很低下
*/
if (!rs.next()) {
break;
}
}
}
}
MyBatis 默认提供了 RowBounds 用于分页,从上面的代码中可以看出,这并非是一个高效的分页方式。除了使用 RowBounds,还可以使用一些第三方分页插件进行分页。ResultSet 的映射过程:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建实体类对象,比如 Article 对象
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
// 检测是否应该自动映射结果集
if (shouldApplyAutomaticMappings(resultMap, false)) {
// 进行自动映射
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 根据 节点中配置的映射关系进行映射
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
上面的方法中的重要逻辑已经注释出来了,这里再简单总结一下:
- 创建实体类对象
- 检测结果集是否需要自动映射,若需要则进行自动映射
- 按
中配置的映射关系进行映射
来按顺序进行分节说明。首先分析实体类的创建过程。
- 1、创建实体类对象
MyBatis 创建实体类对象的过程在DefaultResultSetHandler(位于org.apache.ibatis.executor.resultset)中:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this.useConstructorMappings = false; // reset previous mapping result
final List<Class<?>> constructorArgTypes = new ArrayList<>();
final List<Object> constructorArgs = new ArrayList<>();
// 调用重载方法创建实体类对象
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
// 检测实体类是否有相应的类型处理器
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// 如果开启了延迟加载,则为 resultObject 生成代理类
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
// 创建代理类,默认使用 Javassist 框架生成代理类。由于实体类通常
// 不会实现接口,所以不能使用 JDK 动态代理 API 为实体类生成代理。
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping result
return resultObject;
}
创建实体类对象的逻辑被封装在了 createResultObject 的重载方法中。创建好实体类对后,还需要对
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix)
throws SQLException {
final Class<?> resultType = resultMap.getType();
final MetaClass metaType = MetaClass.forClass(resultType, reflectorFactory);
// 获取 节点对应的 ResultMapping
final List<ResultMapping> constructorMappings = resultMap.getConstructorResultMappings();
// 检测是否有与返回值类型相对应的 TypeHandler,若有则直接从
// 通过 TypeHandler 从结果集中ᨀ取数据,并生成返回值对象
if (hasTypeHandlerForResultObject(rsw, resultType)) {
// 通过 TypeHandler 获取ᨀ取,并生成返回值对象
return createPrimitiveResultObject(rsw, resultMap, columnPrefix);
} else if (!constructorMappings.isEmpty()) {
// 通过 节点配置的映射信息从 ResultSet 中ᨀ取数据,
// 然后将这些数据传给指定构造方法,即可创建实体类对象
return createParameterizedResultObject(rsw, resultType, constructorMappings, constructorArgTypes, constructorArgs, columnPrefix);
} else if (resultType.isInterface() || metaType.hasDefaultConstructor()) {
// 通过 ObjectFactory 调用目标类的默认构造方法创建实例
return objectFactory.create(resultType);
} else if (shouldApplyAutomaticMappings(resultMap, false)) {
// 通过自动映射查找合适的构造方法创建实例
return createByConstructorSignature(rsw, resultType, constructorArgTypes, constructorArgs);
}
throw new ExecutorException("Do not know how to create an instance of " + resultType);
}
createResultObject 方法中包含了 4 种创建实体类对象的方式。一般情况下,若无特殊要求,MyBatis 会通过 ObjectFactory 调用默认构造方法创建实体类对象。ObjectFactory 是一个接口,大家可以实现这个接口,以按照自己的逻辑控制对象的创建过程。至此,实体类对象创建好了,接下里要做的事情是将结果集中的数据映射到实体类对象中。
- 2、结果集映射
在 MyBatis 中,结果集自动映射有三种等级:
NONE - 禁用自动映射。仅设置手动映射属性
PARTIAL - 将自动映射结果除了那些有内部定义内嵌结果映射的(joins)
FULL - 自动映射所有
除了以上三种等级,我们还可以显示配置
private boolean shouldApplyAutomaticMappings(ResultMap resultMap, boolean isNested) {
// 检测 是否配置了 autoMapping 属性
if (resultMap.getAutoMapping() != null) {
// 返回 autoMapping 属性
return resultMap.getAutoMapping();
} else {
if (isNested) {
// 对于嵌套 resultMap,仅当全局的映射行为为 FULL 时,才进行自动映射
return AutoMappingBehavior.FULL == configuration.getAutoMappingBehavior();
} else {
// 对于普通的 resultMap,只要全局的映射行为不为 NONE,即可进行自动映射
return AutoMappingBehavior.NONE != configuration.getAutoMappingBehavior();
}
}
}
shouldApplyAutomaticMappings 方法用于检测是否应为当前结果集应用自动映射。检测结果取决于
下面来分析 MyBatis 是如何进行自动映射的。
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
// 获取 UnMappedColumnAutoMapping 列表
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
for (UnMappedColumnAutoMapping mapping : autoMapping) {
// 通过 TypeHandler 从结果集中获取指定列的数据
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {
// 通过元信息对象设置 value 到实体类对象的指定字段上
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}
applyAutomaticMappings 方法的逻辑:首先是获取
UnMappedColumnAutoMapping 集合,然后遍历该集合,并通过 TypeHandler 从结果集中获取数据,最后再将获取到的数据设置到实体类对象中。
简单介绍一下 UnMappedColumnAutoMapping 的用途。UnMappedColumnAutoMapping用于记录未配置在节点中的映射关系。该类定义在 DefaultResultSetHandler 内部:
private static class UnMappedColumnAutoMapping {
private final String column;
private final String property;
private final TypeHandler<?> typeHandler;
private final boolean primitive;
public UnMappedColumnAutoMapping(String column, String property, TypeHandler<?> typeHandler, boolean primitive) {
this.column = column;
this.property = property;
this.typeHandler = typeHandler;
this.primitive = primitive;
}
}
UnMappedColumnAutoMapping,仅用于记录映射关系。下面看一下获取 UnMappedColumnAutoMapping 集合的过程。
private List<UnMappedColumnAutoMapping> createAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
final String mapKey = resultMap.getId() + ":" + columnPrefix;
// 从缓存中获取 UnMappedColumnAutoMapping 列表
List<UnMappedColumnAutoMapping> autoMapping = autoMappingsCache.get(mapKey);
// 缓存未命中
if (autoMapping == null) {
autoMapping = new ArrayList<>();
// 从 ResultSetWrapper 中获取未配置在 中的列名
final List<String> unmappedColumnNames = rsw.getUnmappedColumnNames(resultMap, columnPrefix);
for (String columnName : unmappedColumnNames) {
String propertyName = columnName;
if (columnPrefix != null && !columnPrefix.isEmpty()) {
// When columnPrefix is specified,
// ignore columns without the prefix.
if (columnName.toUpperCase(Locale.ENGLISH).startsWith(columnPrefix)) {
// 获取不包含列名前缀的属性名
propertyName = columnName.substring(columnPrefix.length());
} else {
continue;
}
}
// 将下划线形式的列名转成驼峰式,比如 AUTHOR_NAME -> authorName
final String property = metaObject.findProperty(propertyName, configuration.isMapUnderscoreToCamelCase());
if (property != null && metaObject.hasSetter(property)) {
// 检测当前属性是否存在于 resultMap 中
if (resultMap.getMappedProperties().contains(property)) {
continue;
}
// 获取属性对于的类型
final Class<?> propertyType = metaObject.getSetterType(property);
if (typeHandlerRegistry.hasTypeHandler(propertyType, rsw.getJdbcType(columnName))) {
// 获取类型处理器
final TypeHandler<?> typeHandler = rsw.getTypeHandler(propertyType, columnName);
// 封装上面获取到的信息到 UnMappedColumnAutoMapping 对象中
autoMapping.add(new UnMappedColumnAutoMapping(columnName, property, typeHandler, propertyType.isPrimitive()));
} else {
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, property, propertyType);
}
} else {
// 若 property 为空,或实体类中无 property 属性,此时无法完成
// 列名与实体类属性建立映射关系。针对这种情况,有三种处理方式,
// 1. 什么都不做
// 2. 仅打印日志
// 3. 抛出异常
// 默认情况下,是什么都不做
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, (property != null) ? property : propertyName, null);
}
}
// 写入缓存
autoMappingsCache.put(mapKey, autoMapping);
}
return autoMapping;
}
该方法的逻辑:
- 从 ResultSetWrapper 中获取未配置在
中的列名- 遍历上一步获取到的列名列表
- 若列名包含列名前缀,则移除列名前缀,得到属性名
- 将下划线形式的列名转成驼峰式
- 获取属性类型
- 获取类型处理器
- 创建 UnMappedColumnAutoMapping 实例
来分析第一个步骤的逻辑,在ResultSetWrapper(位于org.apache.ibatis.executor.resultset)中:
public List<String> getUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
if (unMappedColumnNames == null) {
// 加载已映射与未映射列名
loadMappedAndUnmappedColumnNames(resultMap, columnPrefix);
// 获取未映射列名
unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
}
return unMappedColumnNames;
}
private void loadMappedAndUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> mappedColumnNames = new ArrayList<>();
List<String> unmappedColumnNames = new ArrayList<>();
final String upperColumnPrefix = columnPrefix == null ? null : columnPrefix.toUpperCase(Locale.ENGLISH);
// 为 中的列名拼接前缀
final Set<String> mappedColumns = prependPrefixes(resultMap.getMappedColumns(), upperColumnPrefix);
// 遍历 columnNames,columnNames 是 ResultSetWrapper 的成员变量,
// 保存了当前结果集中的所有列名
for (String columnName : columnNames) {
final String upperColumnName = columnName.toUpperCase(Locale.ENGLISH);
// 检测已映射列名集合中是否包含当前列名
if (mappedColumns.contains(upperColumnName)) {
mappedColumnNames.add(upperColumnName);
} else {
// 将列名存入 unmappedColumnNames 中
unmappedColumnNames.add(columnName);
}
}
// 缓存列名集合
mappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), mappedColumnNames);
unMappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), unmappedColumnNames);
}
首先是从当前数据集中获取列名集合,然后获取
自动映射的分析就先到这,接下来分析一下 MyBatis 是如何将结果集中的数据填充到已映射的实体类字段中的。依然在DefaultResultSetHandler中:
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 获取已映射的列名
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
// 获取 ResultMapping
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// 拼接列名前缀,得到完整列名
String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
column = null;
}
/*
* 下面的 if 分支由三个或条件组合而成,三个条件的含义如下:
* 条件一:检测 column 是否为 {prop1=col1, prop2=col2} 形式,该
* 种形式的 column 一般用于关联查询
* 条件二:检测当前列名是否被包含在已映射的列名集合中,
* 若包含则可进行数据集映射操作
* 条件三:多结果集相关,暂不分析
*/
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
// 从结果集中获取指定列的数据
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
// issue #541 make property optional
final String property = propertyMapping.getProperty();
if (property == null) {
continue;
// 若获取到的值为 DEFERED,则延迟加载该值
} else if (value == DEFERRED) {
foundValues = true;
continue;
}
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property).isPrimitive())) {
// 将获取到的值设置到实体类对象中
metaObject.setValue(property, value);
}
}
}
return foundValues;
}
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
// 获取关联查询结果
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK?
return DEFERRED;
} else {
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
// 拼接前缀
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
// 从 ResultSet 中获取指定列的值
return typeHandler.getResult(rs, column);
}
}
applyPropertyMappings 方法首先从 ResultSetWrapper 中获取已映射列名集合mappedColumnNames, 从 ResultMap 获取映射对象ResultMapping 集合。然后遍历ResultMapping 集合,在此过程中调用getPropertyMappingValue 获取指定指定列的数据,最后将获取到的数据设置到实体类对象中。到此,基本的结果集映射过程就分析完了。
- 3、关联查询与延迟加载
MyBatis 提供了两个标签用于支持一对一和一对多的使用场
景,分别是
看 MyBatis 是如何实现关联查询的,从 DefaultResultSetHandler中的getNestedQueryMappingValue 方法开始分析:
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 获取关联查询 id,id = 命名空间 + 的 select 属性值
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
// 根据 nestedQueryId 获取 MappedStatement
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
/*
* 生成关联查询语句参数对象,参数类型可能是一些包装类,Map 或是自定义的实体类,
* 具体类型取决于配置信息。以上面的例子为基础,下面分析不同配置对
* 参数类型的影响:
* 1.
* column 属性值仅包含列信息,参数类型为 author_id 列对应的类型,
* 这里为 Integer
* 2.
* column 属性值包含了属性名与列名的复合信息,MyBatis 会根据列名从
* ResultSet 中获取列数据,并将列数据设置到实体类对象的指定属性中,比如:
* Author{id=1, name="MyBatis 源码分析系列文章导读", age=null, …}
* 或是以键值对 <属性, 列数据> 的形式,将两者存入 Map 中。比如:
* {"id": 1, "name": "MyBatis 源码分析系列文章导读"}
*
* 至于参数类型到底为实体类还是 Map,取决于关联查询语句的配置信息。比如:
*
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
// 获取 BoundSql
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
// 检查一级缓存是否保存了关联查询结果
if (executor.isCached(nestedQuery, key)) {
// 从一级缓存中获取关联查询的结果,并通过 metaResultObject
// 将结果设置到相应的实体类对象中
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
value = DEFERRED;
} else {
// 创建结果加载器
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
// 检测当前属性是否需要延迟加载
if (propertyMapping.isLazy()) {
// 添加延迟加载相关的对象到 loaderMap 集合中
lazyLoader.addLoader(property, metaResultObject, resultLoader);
value = DEFERRED;
} else {
// 直接执行关联查询
value = resultLoader.loadResult();
}
}
}
return value;
}
该方法的逻辑:
- 根据 nestedQueryId 获取 MappedStatement
- 生成参数对象
- 获取 BoundSql
- 检测一级缓存中是否有关联查询的结果,若有,则将结果设置到实体类对象中
- 若一级缓存未命中,则创建结果加载器 ResultLoader
- 检测当前属性是否需要进行延迟加载,若需要,则添加延迟加载相关的对象到loaderMap 集合中
- 如不需要延迟加载,则直接通过结果加载器加载结果
getNestedQueryMappingValue 方法中逻辑多是都是和延迟加载有关。除了延迟加载,以上流程中针对一级缓存的检查是十分有必要的,若缓存命中,可直接取用结果,无需再在执行关联查询 SQL。若缓存未命中,接下来就要按部就班执行延迟加载相关逻辑,接下来,分析一下 MyBatis 延迟加载是如何实现的。首先我们来看一下添加延迟加载相关对象到loaderMap 集合中的逻辑,在ResultLoaderMap(位于org.apache.ibatis.executor.loader)中:
public void addLoader(String property, MetaObject metaResultObject, ResultLoader resultLoader) {
// 将属性名转为大写
String upperFirst = getUppercaseFirstProperty(property);
if (!upperFirst.equalsIgnoreCase(property) && loaderMap.containsKey(upperFirst)) {
throw new ExecutorException("Nested lazy loaded result property '" + property
+ "' for query id '" + resultLoader.mappedStatement.getId()
+ " already exists in the result map. The leftmost property of all lazy loaded properties must be unique within a result map.");
}
// 创建 LoadPair,并将 <大写属性名,LoadPair 对象> 键值对添加到 loaderMap 中
loaderMap.put(upperFirst, new LoadPair(property, metaResultObject, resultLoader));
}
addLoader 方法的参数最终都传给了 LoadPair,该类的 load 方法会在内部调用ResultLoader 的 loadResult 方法进行关联查询,并通过 metaResultObject 将查询结果设置到实体类对象中。那 LoadPair 的 load 方法由谁调用呢?答案是实体类的代理对象。
MyBatis 会为需要延迟加载的类生成代理类,代理逻辑会拦截实体类的方法调用。默认情况下,MyBatis 会使用 Javassist为实体类生成代理,代理逻辑封装在 JavassistProxyFactory(位于org.apache.ibatis.executor.loader.javassist) 类中:
public Object invoke(Object enhanced, Method method, Method methodProxy, Object[] args) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (WRITE_REPLACE_METHOD.equals(methodName)) {
// 针对 writeReplace 方法的处理逻辑,与延迟加载无关
} else {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
// 如果 aggressive 为 true,或触发方法(比如 equals,
// hashCode 等)被调用,则加载所有的所有延迟加载的数据
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
} else if (PropertyNamer.isSetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
// 如果使用者显示调用了 setter 方法,则将相应的
// 延迟加载类从 loaderMap 中移除
lazyLoader.remove(property);
// 检测使用者是否调用 getter 方法
} else if (PropertyNamer.isGetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
// 检测该属性是否有相应的 LoadPair 对象
if (lazyLoader.hasLoader(property)) {
// 执行延迟加载逻辑
lazyLoader.load(property);
}
}
}
}
}
// 调用被代理类的方法
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
代理方法首先会检查 aggressive 是否为 true ,如果不满足,再去检查lazyLoadTriggerMethods 是否包含当前方法名。这里两个条件只要一个为 true,当前实体类中所有需要延迟加载。aggressive 和 lazyLoadTriggerMethods 两个变量的值取决于下面的配置。
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="lazyLoadTriggerMethods" value="equals,hashCode"/>
回到上面的代码中。如果执行线程未进入第一个条件分支,那么紧接着,代理逻辑会检查使用者是不是调用了实体类的 setter 方法。如果调用了,就将该属性对应的 LoadPair 从loaderMap 中移除。为什么要这么做呢?答案是:使用者既然手动调用 setter 方法,说明使用者想自定义某个属性的值。此时,延迟加载逻辑不应该再修改该属性的值,所以这里从loaderMap 中移除属性对于的 LoadPair。最后如果使用者调用的是某个属性的 getter 方法,且该属性配置了延迟加载,此时延迟加载逻辑就会被触发。
接下来,我们来看看延迟加载逻辑是怎样实现的,在ResultLoaderMap(位于org.apache.ibatis.executor.loader)。
public boolean load(String property) throws SQLException {
// 从 loaderMap 中移除 property 所对应的 LoadPair
LoadPair pair = loaderMap.remove(property.toUpperCase(Locale.ENGLISH));
if (pair != null) {
// 加载结果
pair.load();
return true;
}
return false;
}
接下来看LoadPair(ResultLoaderMap的静态内部类):
public void load() throws SQLException {
/* These field should not be null unless the loadpair was serialized.
* Yet in that case this method should not be called. */
if (this.metaResultObject == null) {
throw new IllegalArgumentException("metaResultObject is null");
}
if (this.resultLoader == null) {
throw new IllegalArgumentException("resultLoader is null");
}
// 调用重载方法
this.load(null);
}
public void load(final Object userObject) throws SQLException {
// 若 metaResultObject 和 resultLoader 为 null,则创建相关对象。
// 在当前调用情况下,两者均不为 null,条件不成立。
if (this.metaResultObject == null || this.resultLoader == null) {
if (this.mappedParameter == null) {
throw new ExecutorException("Property [" + this.property + "] cannot be loaded because "
+ "required parameter of mapped statement ["
+ this.mappedStatement + "] is not serializable.");
}
final Configuration config = this.getConfiguration();
final MappedStatement ms = config.getMappedStatement(this.mappedStatement);
if (ms == null) {
throw new ExecutorException("Cannot lazy load property [" + this.property
+ "] of deserialized object [" + userObject.getClass()
+ "] because configuration does not contain statement ["
+ this.mappedStatement + "]");
}
this.metaResultObject = config.newMetaObject(userObject);
this.resultLoader = new ResultLoader(config, new ClosedExecutor(), ms, this.mappedParameter,
metaResultObject.getSetterType(this.property), null, null);
}
// 线程安全检测
if (this.serializationCheck == null) {
// 重新创建新的 ResultLoader 和 ClosedExecutor,
// ClosedExecutor 是非线程安全的
final ResultLoader old = this.resultLoader;
this.resultLoader = new ResultLoader(old.configuration, new ClosedExecutor(), old.mappedStatement,
old.parameterObject, old.targetType, old.cacheKey, old.boundSql);
}
// 调用 ResultLoader 的 loadResult 方法加载结果,
// 并通过 metaResultObject 设置结果到实体类对象中
this.metaResultObject.setValue(property, this.resultLoader.loadResult());
}
下面看一下 ResultLoader(位于org.apache.ibatis.executor.loader) 的 loadResult 方法逻辑是怎样的。
public Object loadResult() throws SQLException {
List<Object> list = selectList();
resultObject = resultExtractor.extractObjectFromList(list, targetType);
return resultObject;
}
private <E> List<E> selectList() throws SQLException {
Executor localExecutor = executor;
if (Thread.currentThread().getId() != this.creatorThreadId || localExecutor.isClosed()) {
localExecutor = newExecutor();
}
try {
// 通过 Executor 就行查询,
return localExecutor.query(mappedStatement, parameterObject, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER, cacheKey, boundSql);
} finally {
if (localExecutor != executor) {
localExecutor.close(false);
}
}
}
我们在 ResultLoader 中终于看到了执行关联查询的代码,即 selectList 方法中的逻辑。该方法在内部通过 Executor 进行查询。
- 4、存储映射结果
存储映射结果是“查询结果”处理流程中的最后一环,实际上也是查语句执行过程的最后一环。重新回到DefaultResultSetHandler:
private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
// 多结果集相关
linkToParents(rs, parentMapping, rowValue);
} else {
// 存储结果
callResultHandler(resultHandler, resultContext, rowValue);
}
}
private void callResultHandler(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue) {
// 设置结果到 resultContext 中
resultContext.nextResultObject(rowValue);
// 从 resultContext 获取结果,并存储到 resultHandler 中
((ResultHandler<Object>) resultHandler).handleResult(resultContext);
}
上面方法显示将 rowValue 设置到 ResultContext 中,然后再将 ResultContext 对象作为参数传给 ResultHandler 的 handleResult 方法。
分别看一下 ResultContext 和ResultHandler 的实现类。DefaultResultContext(位于org.apache.ibatis.executor.result):
public class DefaultResultContext<T> implements ResultContext<T> {
private T resultObject;
private int resultCount;
/** 状态字段 */
private boolean stopped;
// 省略部分代码
@Override
public boolean isStopped() {
return stopped;
}
public void nextResultObject(T resultObject) {
resultCount++;
this.resultObject = resultObject;
}
@Override
public void stop() {
this.stopped = true;
}
}
DefaultResultContext 中包含了一个状态字段,表明结果上下文的状态。在处理多行数据时,MyBatis 会检查该字段的值,已决定是否需要进行后续的处理。
下面再来看一下 DefaultResultHandler(位于org.apache.ibatis.executor.result) 的源码。
public class DefaultResultHandler implements ResultHandler<Object> {
private final List<Object> list;
public DefaultResultHandler() {
list = new ArrayList<>();
}
@SuppressWarnings("unchecked")
public DefaultResultHandler(ObjectFactory objectFactory) {
list = objectFactory.create(List.class);
}
@Override
public void handleResult(ResultContext<?> context) {
// 添加结果到 list 中
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
}
}
DefaultResultHandler 默认使用 List 存储结果。除此之外,如果 Mapper(或 Dao)接口方法返回值为 Map 类型,此时则需要另一种 ResultHandler 实现类处理结果,即DefaultMapResultHandler。
1.3 更新语句的执行过程
执行更新语句所需处理的情况较之查询语句要简单不少,两者最大的区别更新语句的执行结果类型单一,处理逻辑要简单不少。除此之外,两者在缓存的处理上也有比较大的区别。更新过程会立即刷新缓存,而查询过程则不会。下面开始分析更新语句的执行过程。
1.3.1 更新语句执行过程全貌
是从 MapperMethod 的 execute 方法开始看起:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
// 执行插入语句
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
// 执行更新语句
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
// 执行删除语句
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
//...
break;
case FLUSH:
//...
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
插入、更新以及删除操作最终都调用了 SqlSession 接口中的方法。这三个方法返回值均是受影响行数,是一个整型值。rowCountResult 方法负责处理这个整型值。下面分析 SqlSession 的实现类 DefaultSqlSession 的代码。
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
public int delete(String statement, Object parameter) {
return update(statement, parameter);
}
public int update(String statement, Object parameter) {
try {
dirty = true;
// 获取 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
// 调用 Executor 的 update 方法
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
insert 和 delete 方法最终都调用了同一个 update 方法。下面分析 Executor 的 update 方法。先看CachingExecutor:
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 刷新二级缓存
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
再看BaseExecutor:
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 刷新一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
Executor 实现类中的方法在进行下一步操作之前,都会先刷新各自的缓存。默认情况下,insert、update 和 delete 操作都会清空一二级缓存。下面分析 doUpdate 方法,该方法是一个抽象方法,因此我们到 BaseExecutor 的子类SimpleExecutor 中看看该方法是如何实现的。
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
// 创建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 调用 StatementHandler 的 update 方法
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
下面分析 PreparedStatementHandler 的 update 方法。
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行 SQL
ps.execute();
// 返回受影响行数
int rows = ps.getUpdateCount();
// 获取用户传入的参数值,参数值类型可能是普通的实体类,也可能是 Map
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
// 获取自增主键的值,并将值填入到参数对象中
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
PreparedStatementHandler 的 update 方法的逻辑比较清晰明了了,更新语句的 SQL 会在此方法中被执行。执行结果为受影响行数,对于 insert 语句,有时候我们还想获取自增主键的值,因此我们需要进行一些额外的操作。这些额外操作的逻辑封装在 KeyGenerator 的实现类中,下面我们一起看一下 KeyGenerator 的实现逻辑。
1.3.2 KeyGenerator
KeyGenerator 是一个接口,目前它有三个实现类:
Jdbc3KeyGenerator
SelectKeyGenerator
NoKeyGenerator
Jdbc3KeyGenerator 用于获取插入数据后的自增主键数值。某些数据库不支持自增主键,需要手动填写主键字段,此时需要借助 SelectKeyGenerator 获取主键值。至于 NoKeyGenerator,这是一个空实现,没什么可说的。
先看Jdbc3KeyGenerator:
public void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
// do nothing
}
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
processBatch(ms, stmt, parameter);
}
public void processBatch(MappedStatement ms, Statement stmt, Object parameter) {
// 获取主键字段
final String[] keyProperties = ms.getKeyProperties();
if (keyProperties == null || keyProperties.length == 0) {
return;
}
try (ResultSet rs = stmt.getGeneratedKeys()) {
// 获取结果集 ResultSet 的元数据
final ResultSetMetaData rsmd = rs.getMetaData();
final Configuration configuration = ms.getConfiguration();
if (rsmd.getColumnCount() < keyProperties.length) {
// Error?
// ResultSet 中数据的列数要大于等于主键的数量
} else {
assignKeys(configuration, rs, rsmd, keyProperties, parameter);
}
} catch (Exception e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e, e);
}
}
private void assignKeys(Configuration configuration, ResultSet rs, ResultSetMetaData rsmd, String[] keyProperties,
Object parameter) throws SQLException {
if (parameter instanceof ParamMap || parameter instanceof StrictMap) {
// Multi-param or single param with @Param
assignKeysToParamMap(configuration, rs, rsmd, keyProperties, (Map<String, ?>) parameter);
} else if (parameter instanceof ArrayList && !((ArrayList<?>) parameter).isEmpty()
&& ((ArrayList<?>) parameter).get(0) instanceof ParamMap) {
// Multi-param or single param with @Param in batch operation
assignKeysToParamMapList(configuration, rs, rsmd, keyProperties, (ArrayList<ParamMap<?>>) parameter);
} else {
// Single param without @Param
assignKeysToParam(configuration, rs, rsmd, keyProperties, parameter);
}
}
Jdbc3KeyGenerator 的 processBefore 方法是一个空方法,processAfter 则是一个空壳方法,只有一行代码。Jdbc3KeyGenerator 的重点在 processBatch 方法中,由于存在批量插入的情况,所以该方法的名字类包含 batch 单词,表示可处理批量插入的结果集。
1.3.3 处理更新结果
更新语句的执行结果是一个整型值,表示本次更新所影响的行数。由于返回值类型简单,因此处理逻辑也很简单。先看MapperMethod:
private Object rowCountResult(int rowCount) {
final Object result;
// 这里的 method 类型为 MethodSignature,即方法签名
if (method.returnsVoid()) {
// 方法返回类型为 void,则不用返回结果,这里将结果置空
result = null;
} else if (Integer.class.equals(method.getReturnType()) || Integer.TYPE.equals(method.getReturnType())) {
// 方法返回类型为 Integer 或 int,直接赋值返回即可
result = rowCount;
} else if (Long.class.equals(method.getReturnType()) || Long.TYPE.equals(method.getReturnType())) {
// 如果返回值类型为 Long 或者 long,这里强转一下即可
result = (long) rowCount;
} else if (Boolean.class.equals(method.getReturnType()) || Boolean.TYPE.equals(method.getReturnType())) {
// 方法返回类型为布尔类型,若 rowCount > 0,则返回 ture,否则返回 false
result = rowCount > 0;
} else {
throw new BindingException("Mapper method '" + command.getName() + "' has an unsupported return type: " + method.getReturnType());
}
return result;
}
1.4 SQL 执行过程总结
在 MyBatis 中,SQL 执行过程的实现代码是有层次的,每层都有相应的功能。比如,SqlSession 是对外接口的接口,因此它提供了各种语义清晰的方法,供使用者调用。Executor层做的事情较多,比如一二级缓存功能就是嵌入在该层内的。StatementHandler 层主要是与JDBC 层面的接口打交道。至于 ParameterHandler 和 ResultSetHandler,一个负责向 SQL 中设置运行时参数,另一个负责处理 SQL 执行结果,它们俩可以看做是 StatementHandler 辅助类。最后看一下右边横跨数层的类,Configuration 是一个全局配置类,很多地方都依赖它。MappedStatement 对应 SQL 配置,包含了 SQL 配置的相关信息。BoundSql 中包含了已完成解析的 SQL 语句,以及运行时参数等。
二、内置数据源
MyBatis 支持三种数据源配置,分别为 UNPOOLED、POOLED 和 JNDI。并提供了两种数据源实现,分别是UnpooledDataSource 和 PooledDataSource 。 在这三种数据源配置中, UNPOOLED 和POOLED 是我们最常用的两种配置,JNDI 数据源在日常开发中使用甚少。
2.1 内置数据源初始化过程
先来看一下数据源配置方法:
<dataSource type="UNPOOLED|POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql..."/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
dataSource>
数据源的配置是内嵌在
public class UnpooledDataSourceFactory implements DataSourceFactory {
private static final String DRIVER_PROPERTY_PREFIX = "driver.";
private static final int DRIVER_PROPERTY_PREFIX_LENGTH = DRIVER_PROPERTY_PREFIX.length();
protected DataSource dataSource;
public UnpooledDataSourceFactory() {
// 创建 UnpooledDataSource 对象
this.dataSource = new UnpooledDataSource();
}
@Override
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 为 dataSource 创建元信息对象
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
// 遍历 properties 键列表,properties 由配置文件解析器传入
for (Object key : properties.keySet()) {
String propertyName = (String) key;
// 检测 propertyName 是否以 "driver." 开头
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
String value = properties.getProperty(propertyName);
// 存储配置信息到 driverProperties 中
driverProperties.setProperty(propertyName
.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
String value = (String) properties.get(propertyName);
// 按需转换 value 类型
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 设置转换后的值到 UnpooledDataSourceFactory 指定属性中
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
// 设置 driverProperties 到 UnpooledDataSourceFactory 的
// driverProperties 属性中
metaDataSource.setValue("driverProperties", driverProperties);
}
}
@Override
public DataSource getDataSource() {
return dataSource;
}
private Object convertValue(MetaObject metaDataSource, String propertyName, String value) {
Object convertedValue = value;
// 获取属性对应的 setter 方法的参数类型
Class<?> targetType = metaDataSource.getSetterType(propertyName);
// 按照 setter 方法的参数类型进行类型转换
if (targetType == Integer.class || targetType == int.class) {
convertedValue = Integer.valueOf(value);
} else if (targetType == Long.class || targetType == long.class) {
convertedValue = Long.valueOf(value);
} else if (targetType == Boolean.class || targetType == boolean.class) {
convertedValue = Boolean.valueOf(value);
}
return convertedValue;
}
}
下面看看 PooledDataSourceFactory(位于org.apache.ibatis.datasource.pooled) 的源码。
public class PooledDataSourceFactory extends UnpooledDataSourceFactory {
public PooledDataSourceFactory() {
// 创建 PooledDataSource
this.dataSource = new PooledDataSource();
}
}
PooledDataSourceFactory 继承自UnpooledDataSourceFactory,复用了父类的逻辑,因此它的实现很简单。关于两种数据源的创建过程就先分析到这,接下来,我们去探究一下两种数据源是怎样实现的。
2.2 UnpooledDataSource
UnpooledDataSource,该种数据源不具有池化特性。该种数据源每次会返回一个新的数据库连接,而非复用旧的连接。由于 UnpooledDataSource 无需提供连接池功能,因此它的实现非常简单。核心的方法有三个:
- initializeDriver - 初始化数据库驱动
- doGetConnection - 获取数据连接
- configureConnection - 配置数据库连接
- 1、 初始化数据库驱动
UnpooledDataSource(位于org.apache.ibatis.datasource.unpooled) 也是使用 JDBC 访问数据库的,因此它获取数据库连接的过程也大致如此,只不过会稍有不同。
private synchronized void initializeDriver() throws SQLException {
// 检测缓存中是否包含了与 driver 对应的驱动实例
if (!registeredDrivers.containsKey(driver)) {
Class<?> driverType;
try {
// 加载驱动类型
if (driverClassLoader != null) {
// 使用 driverClassLoader 加载驱动
driverType = Class.forName(driver, true, driverClassLoader);
} else {
// 通过其他 ClassLoader 加载驱动
driverType = Resources.classForName(driver);
}
// 通过反射创建驱动实例
Driver driverInstance = (Driver) driverType.getDeclaredConstructor().newInstance();
// 注册驱动,注意这里是将 Driver 代理类 DriverProxy 对象注册到
// 而非 Driver 对象本身。
DriverManager.registerDriver(new DriverProxy(driverInstance));
// 缓存驱动类名和实例
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
initializeDriver 方法主要包含三步操作:
- 加载驱动
- 通过反射创建驱动实例
- 注册驱动实例
上面代码中出现了缓存相关的逻辑,这个是用于避免重复注册驱动。因为 initializeDriver 方法并不是在 UnpooledDataSource 初始化时被调用的,而是在获取数据库连接时被调用的。因此这里需要做个检测,避免每次获取数据库连接时都重新注册驱动。
- 2、 获取数据库连接
看一下UnpooledDataSource:
public Connection getConnection() throws SQLException {
return doGetConnection(username, password);
}
private Connection doGetConnection(String username, String password) throws SQLException {
Properties props = new Properties();
if (driverProperties != null) {
props.putAll(driverProperties);
}
if (username != null) {
// 存储 user 配置
props.setProperty("user", username);
}
if (password != null) {
// 存储 password 配置
props.setProperty("password", password);
}
// 调用重载方法
return doGetConnection(props);
}
private Connection doGetConnection(Properties properties) throws SQLException {
// 初始化驱动
initializeDriver();
// 获取连接
Connection connection = DriverManager.getConnection(url, properties);
// 配置连接,包括自动ᨀ交以及事务等级
configureConnection(connection);
return connection;
}
private void configureConnection(Connection conn) throws SQLException {
if (defaultNetworkTimeout != null) {
conn.setNetworkTimeout(Executors.newSingleThreadExecutor(), defaultNetworkTimeout);
}
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
// 设置自动ᨀ交
conn.setAutoCommit(autoCommit);
}
if (defaultTransactionIsolationLevel != null) {
// 设置事务隔离级别
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
上面方法将一些配置信息放入到 Properties 对象中,然后将数据库连接和Properties 对象传给 DriverManager 的 getConnection 方法即可获取到数据库连接。
2.3 PooledDataSource
PooledDataSource 内部实现了连接池功能,用于复用数据库连接。因此,从效率上来说,PooledDataSource 要高于 UnpooledDataSource。PooledDataSource 需要借助一些辅助类帮助它完成连接池的功能。
2.3.1 辅助类
PooledDataSource 需要借助两个辅助类帮其完成功能,这两个辅助类分别是 PoolState和 PooledConnection。PoolState 用于记录连接池运行时的状态,比如连接获取次数,无效连接数量等。同时PoolState 内部定义了两个 PooledConnection 集合,用于存储空闲连接和活跃连接。PooledConnection 内部定义了一个 Connection 类型的变量,用于指向真实的数据库连接。以及一个 Connection 的代理类,用于对部分方法调用进行拦截。除此之外,PooledConnection 内部也定义了一些字段,用于记录数据库连接的一些运行时状态。
先看PooledConnection(位于org.apache.ibatis.datasource.pooled):
class PooledConnection implements InvocationHandler {
private static final String CLOSE = "close";
private static final Class<?>[] IFACES = new Class<?>[] {
Connection.class };
private final int hashCode;
private final PooledDataSource dataSource;
// 真实的数据库连接
private final Connection realConnection;
// 数据库连接代理
private final Connection proxyConnection;
// 从连接池中取出连接时的时间戳
private long checkoutTimestamp;
// 数据库连接创建时间
private long createdTimestamp;
// 数据库连接最后使用时间
private long lastUsedTimestamp;
// connectionTypeCode = (url + username + password).hashCode()
private int connectionTypeCode;
// 表示连接是否有效
private boolean valid;
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
this.realConnection = connection;
this.dataSource = dataSource;
this.createdTimestamp = System.currentTimeMillis();
this.lastUsedTimestamp = System.currentTimeMillis();
this.valid = true;
// 创建 Connection 的代理类对象
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
...}
}
再看PoolState(位于org.apache.ibatis.datasource.pooled):
public class PoolState {
protected PooledDataSource dataSource;
// 空闲连接列表
protected final List<PooledConnection> idleConnections = new ArrayList<>();
// 活跃连接列表
protected final List<PooledConnection> activeConnections = new ArrayList<>();
// 从连接池中获取连接的次数
protected long requestCount = 0;
// 请求连接总耗时(单位:毫秒)
protected long accumulatedRequestTime = 0;
// 连接执行时间总耗时
protected long accumulatedCheckoutTime = 0;
// 执行时间超时的连接数
protected long claimedOverdueConnectionCount = 0;
// 超时时间累加值
protected long accumulatedCheckoutTimeOfOverdueConnections = 0;
// 等待时间累加值
protected long accumulatedWaitTime = 0;
// 等待次数
protected long hadToWaitCount = 0;
// 无效连接数
protected long badConnectionCount = 0;
}
2.3.2 获取连接
PooledDataSource 会将用过的连接进行回收,以便可以复用连接。因此从 PooledDataSource 获取连接时,如果空闲链接列表里有连接时,可直接取用。那如果没有空闲连接怎么办呢?此时有两种解决办法,要么创建新连接,要么等待其他连接完成任务。具体怎么做,需视情况而定。
看PooledDataSource:
public Connection getConnection() throws SQLException {
// 返回 Connection 的代理对象
return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
synchronized (state) {
// 检测空闲连接集合(idleConnections)是否为空
if (!state.idleConnections.isEmpty()) {
// idleConnections 不为空,表示有空闲连接可以使用
conn = state.idleConnections.remove(0);
} else {
// 暂无空闲连接可用,但如果活跃连接数还未超出限制
//(poolMaximumActiveConnections),则可创建新的连接
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 创建新连接
conn = new PooledConnection(dataSource.getConnection(), this);
} else {
// 连接池已满,不能创建新连接
// 取出运行时间最长的连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
// 获取运行时长
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
// 检测运行时长是否超出限制,即超时
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// 累加超时相关的统计字段
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 从活跃连接集合中移除超时连接
state.activeConnections.remove(oldestActiveConnection);
// 若连接未设置自动ᨀ交,此处进行回滚操作
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
log.debug("Bad connection. Could not roll back");
}
}
// 创建一个新的 PooledConnection,注意,此处复用
// oldestActiveConnection 的 realConnection 变量
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
// 复用 oldestActiveConnection 的一些信息,注意
// PooledConnection 中的 createdTimestamp 用于记录
// Connection 的创建时间,而非 PooledConnection
// 的创建时间。所以这里要复用原连接的时间信息。
conn.setCreatedTimestamp(oldestActiveConnection
.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection
.getLastUsedTimestamp());
// 设置连接为无效状态
oldestActiveConnection.invalidate();
} else {
// 运行时间最长的连接并未超时
// Must wait
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
long wt = System.currentTimeMillis();
// 当前线程进入等待状态
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// 检测连接是否有效,isValid 方法除了会检测 valid 是否为 true,
// 还会通过 PooledConnection 的 pingConnection 方法执行 SQL 语句,
// 检测连接是否可用。
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
// 进行回滚操作
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(
dataSource.getUrl(), username, password));
// 设置统计字段
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
// 连接无效,此时累加无效连接相关的统计字段
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
从连接池中获取连接首先会遇到两种情况: . 连接池中有空闲连接、连接池中无空闲连接。
对于第一种情况,处理措施就很简单了,把连接取出返回即可。对于第二种情况,则要进行细分,会有如下的情况:
- 活跃连接数没有超出最大活跃连接数
- 活跃连接数超出最大活跃连接数
对于上面两种情况,第一种情况比较好处理,直接创建新的连接即可。至于第二种情况,需要再次进行细分:
- 活跃连接的运行时间超出限制,即超时了
- 活跃连接未超时
对于第一种情况,直接将超时连接强行中断,并进行回滚,然后复用部分字段重新创建 PooledConnection 即可。对于第二种情况,目前没有更好的处理方式了,只能等待了。
流程图:
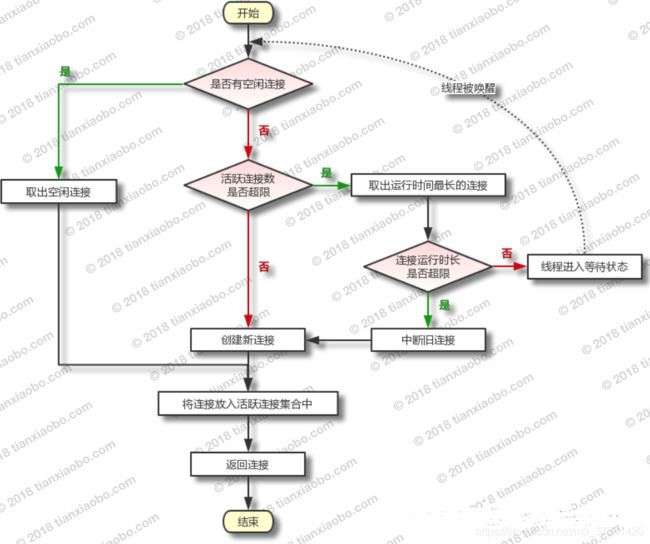
2.3.3 回收连接
回收连接成功与否只取决于空闲连接集合的状态,所需处理情况很少,因此比较简单。
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 从活跃连接池中移除连接
state.activeConnections.remove(conn);
if (conn.isValid()) {
// 空闲连接集合未满
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
// 回滚未提交的事务
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 创建新的 PooledConnection
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
state.idleConnections.add(newConn);
// 复用时间信息
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 将原连接置为无效状态
conn.invalidate();
// 通知等待的线程
state.notifyAll();
} else {
// 空闲连接集合已满
state.accumulatedCheckoutTime += conn.getCheckoutTime();
// 回滚未提交的事务
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 关闭数据库连接
conn.getRealConnection().close();
conn.invalidate();
}
} else {
state.badConnectionCount++;
}
}
}
上面代码首先将连接从活跃连接集合中移除,然后再根据空闲集合是否有空闲空间进行后续处理。如果空闲集合未满,此时复用原连接的字段信息创建新的连接,并将其放入空闲集合中即可。若空闲集合已满,此时无需回收连接,直接关闭即可。
获取连接的方法 popConnection 是由 getConnection 方法调用的,那回收连接的方法 pushConnection 是由谁调用的呢?答案是 PooledConnection(位于org.apache.ibatis.datasource.pooled) 中的代理逻辑。
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
// 检测 close 方法是否被调用,若被调用则拦截之
if (CLOSE.equals(methodName)) {
// 将回收连接中,而不是直接将连接关闭
dataSource.pushConnection(this);
return null;
}
try {
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection();
}
// 调用真实连接的目标方法
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
在上一节中,getConnection 方法返回的是 Connection 代理对象。代理对象中的方法被调用时,会被上面的代理逻辑所拦截。如果代理对象的 close 方法被调用,MyBatis 并不会直接调用真实连接的 close 方法关闭连接,而是调用pushConnection 方法回收连接。同时会唤醒处于睡眠中的线程,使其恢复运行。