译者按:
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
word2vec词向量 是NLP自然语言处理领域当前的主力方法,本文是 word2vec 原始论文,由google的 Mikolov 在2013年发表, Mikolov于2013,2014,2015 连续发表了3篇Word2vec 的 文章,本文是第1篇,作者Mikolov 是
bengio的高徒
原文链接:https://arxiv.org/abs/1301.3781v3
作者:
Tomas Mikolov Google Inc., Mountain View, CA [email protected]
Kai Chen Google Inc., Mountain View, CA [email protected]
Greg Corrado Google Inc., Mountain View, CA [email protected]
Jeffrey Dean Google Inc., Mountain View, CA [email protected]
摘要:
我们提出了两种新的模型结构,用于计算非常大数据集中单词的连续矢量表示。这些表示的质量是在一个词相似性任务中测量的,并将结果与以前基于不同类型神经网络的最佳表现技术进行比较。我们观察到,在低得多的计算成本下,精度有了很大的提高,也就是说,从16亿字的数据集中学习高质量的字向量只需不到一天的时间。此外,我们还表明,这些向量在测试集上提供了最先进的性能,用于测量句法和语义词的相似性。
1 引言:
许多当前的NLP系统和技术都将单词视为原子单位——没有单词之间的相似性概念,因为它们在词汇表中表示为索引。这种选择有几个很好的原因——简单、健壮,并且观察到简单的模型在大量数据上的训练比在较少数据上训练的复杂系统的训练效果更好。一个例子是流行的用于统计语言建模的n-gram模型——今天,可以对几乎所有可用的数据(万亿字[3])培训n-gram。然而,在许多任务中,简单的技术都是有限的。例如,用于自动语音识别的相关域内数据的数量是有限的——性能通常由高质量的转录语音数据(通常只有数百万个字)的大小决定。在机器翻译中,许多语言的现有语料库只包含几十亿个单词或更少的单词。因此,在某些情况下,简单地扩展基本技术不会导致任何显著的进步,我们必须关注更先进的技术。随着近年来机器学习技术的进步,在更大的数据集上训练更复杂的模型已经成为可能,而且它们通常优于简单模型。可能最成功的概念是使用分布式的单词表示[10]。例如,基于神经网络的语言模型明显优于N-gram模型[1,27,17]。
1.1 论文的目标
本论文的主要目的是介绍从海量的数亿字和数亿字的数据集中学习高质量的词汇向量的技术。据我们所知,之前提出的架构中没有一个在2013年9月7日的1301.3781v3[cs.cl]7上成功地训练了数亿个单词,单词向量的适度维数在50-100之间。我们使用最近提出的技术来测量产生的向量表示的质量,期望不仅相似的词彼此接近,而且这些词可以具有多个相似度[20]。这一点在之前的屈折语言中已经被观察到了,例如,名词可以有多个词尾,如果我们在原始向量空间的子空间中搜索相似的词,就可以找到具有相似词尾的词[13,14]。令人惊讶的是,人们发现词语表达的相似性超出了简单的句法规则。使用字偏移技术,在字向量上执行简单的代数运算,例如,矢量(“king”)-矢量(“man”)+矢量(“woman”)产生的矢量最接近于单词queen的矢量表示[20]。
在本文中,我们试图通过开发新的模型体系结构来最大限度地提高这些向量运算的准确性,这种模型体系结构可以保持单词之间的线性规律。我们设计了一个新的综合测试集来测量句法规则和语义规则1,并表明许多这样的规则都可以被高精度地学习。此外,我们还讨论了训练时间和准确性如何取决于单词向量的维数和训练数据的数量。
1.2 前期工作
将单词表示为连续向量有很长的历史[10,26,8]。在[1]中,提出了一种非常流行的神经网络语言模型(NNLM)估计模型体系结构,该模型采用线性投影层和非线性隐层的前馈神经网络共同学习字向量表示和统计语言模型。这项工作已被许多其他人跟踪。NNLM的另一个有趣的体系结构出现在[13,14]中,在这里,首先使用具有单个隐藏层的神经网络学习单词vectors。然后使用vectors这个词来训练nnlm。因此,即使不构建完整的nnlm,也可以学习单词向量。在这项工作中,我们直接扩展了这个体系结构,并且只关注使用简单模型学习向量这个词的第一步。后来发现,vectors一词可用于显著改进和简化许多NLP应用程序[4、5、29]。单词向量本身的估计是使用不同的模型结构进行的,并在不同的语料库[4、29、23、19、9]上进行训练,得到的一些单词向量可用于未来的研究和比较2。然而,据我们所知,这些体系结构在训练方面的计算成本明显高于[13]中提出的体系结构,但使用对角权重矩阵的对数双线性模型的某些版本除外[23]。
2 模型体系结构
提出了多种不同类型的词汇连续表示模型,包括众所周知的潜在语义分析(LSA)和潜在dirichlet分配(LDA)。在本文中,我们重点研究了神经网络学习的单词的分布式表示,如前所述,在保持单词之间的线性规律方面,它们的性能明显优于LSA[20,31];此外,在大型数据集上,LDA在计算上变得非常昂贵。与[18]类似,为了比较不同的模型架构,我们首先将模型的计算复杂性定义为需要访问的参数数量,以完全训练模型。接下来,我们将尝试最大化精度,同时最小化计算复杂性。
对于以下所有模型,训练复杂度为
o=e×t×q (1)
其中e是训练周期的个数,t是训练集中的单词个数,q是为每个模型体系结构进一步定义的。常见的选择是E=3-50,T高达10亿。所有模型都使用随机梯度下降和反向传播进行训练[26]。
2.1 前馈神经网络语言模型(NNLM)
在[1]中提出了概率前馈神经网络语言模型。它由输入层、投影层、隐藏层和输出层组成。在输入层,前n个单词使用1/v编码( 即 one hot :译者按),其中v是词汇表的大小。然后使用共享投影矩阵将输入层投影到尺寸为N×D的投影层P上。由于只有n个输入是每个给定时间的活动,因此项目部分的组合是相对的堆操作。由于投影层中的值很密集,NNLM结构在投影层和隐藏层之间的计算变得复杂。对于n=10的常见选择,投影层(p)的大小可能为500到2000,而隐藏层大小h通常为500到1000个单位。此外,隐藏层用于计算词汇表中所有单词的概率分布,从而生成具有维数V的输出层。因此,每个训练示例的计算复杂性是
Q = N × D + N × D × H + H × V (2)
其中主项为h×v。但是,为了避免出现这种情况,我们提出了几种实用的解决方案:要么使用SoftMax的分层版本[25、23、18],要么使用培训期间未标准化的模型完全避免标准化模型[4、9]。使用词汇表的二叉树表示,需要评估的输出单元的数量可以下降到大约log2(v)。因此,大多数复杂性是由术语n×d×h引起的。在我们的模型中,我们使用层次结构的SoftMax,其中词汇表表示为一个哈夫曼二叉树。这是根据之前的观察得出的,单词的频率对于在神经网络语言模型中获取类很有效[16]。哈夫曼树将短二进制代码分配给频繁使用的字,这进一步减少了需要评估的输出单元的数量:虽然平衡二进制树需要评估log2(v)输出,但是基于哈夫曼树的分层Softmax只需要大约log2(unigram困惑y(v))。例如,当词汇大小为一百万个单词时,这会导致评估速度加快两倍。虽然这对于神经网络LMS来说不是关键的加速,因为计算瓶颈在n×d×h项中,我们稍后将提出不具有隐藏层的架构,从而严重依赖于SoftMax规范化的效率。
2.2 递归神经网络语言模型(RNNLM)
为了克服前馈神经网络的某些局限性,提出了基于递归神经网络的语言模型,例如需要指定上下文长度(模型n的阶数),因为理论上,RNN比浅层神经网络能有效地表示更复杂的模式[15,2]。RNN模型没有投影层,只有输入层、隐藏层和输出层。这种模型的特殊之处在于使用延时连接将隐藏层连接到自身的循环矩阵。这允许循环模型形成某种短期内存,因为来自过去的信息可以由隐藏层状态表示,隐藏层状态根据当前输入和上一时间步骤中隐藏层的状态进行更新。RNN模型的每个训练示例的复杂性是
Q = H × H + H × V, (3)
当表示词d的维数与隐藏层h的维数相同时,使用层次SoftMax可以有效地将术语h×v简化为h×log2(v)。大部分的复杂性来自h×h。
2.3 神经网络并行训练
为了在大型数据集上训练模型,我们在一个称为DistBelief [6]的大型分布式框架之上实现了几个模型,包括前馈nnlm和本文提出的新模型。框架允许我们并行运行同一模型的多个副本,并且每个副本通过一个保留所有参数的集中服务器同步其渐变更新。对于这种并行训练,我们使用小批量异步梯度下降和自适应学习速率过程称为Adagrad [7]。在这个框架下,通常使用100个或更多的模型副本,每个副本在数据中心的不同机器上使用多个CPU核心。
3 新的对数线性模型
在本节中,我们提出了两种新的模型体系结构,用于学习分布式单词表示,以尽量减少计算复杂性。前一节的主要观察结果是,模型中的非线性隐藏层导致了大部分复杂性。虽然这正是神经网络如此具有吸引力的原因,但我们决定探索更简单的模型,这些模型可能无法像神经网络那样精确地表示数据,但可能会更有效地训练数据。新的体系结构直接遵循我们之前的工作[13,14]中提出的那些,发现神经网络语言模型可以通过两个步骤成功地训练:首先,使用简单的模型学习连续的词向量,然后在这些分布式的词表示的基础上训练n-gram
nnlm。虽然后来有大量的工作专注于学习单词向量,但我们认为[13]中提出的方法是最简单的方法。请注意,相关模型也早就提出了[26,8]。
3.1连续词袋模型CBOW
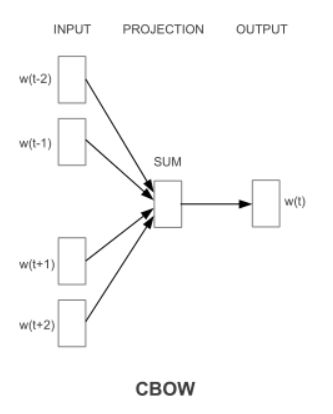
第一个提议的架构类似于前馈nnlm,其中非线性隐藏层被移除,投影层被所有单词共享(不仅仅是投影矩阵);因此,所有单词被投影到相同的位置(它们的向量被平均)。我们称这种架构为一袋文字模型,因为历史上的文字顺序不影响投射。此外,我们还使用了来自未来的单词,通过在输入端建立一个包含四个未来和四个历史单词的对数线性分类器,我们在下一节介绍的任务中获得了最佳的性能,其中训练标准是正确地对当前(中间)单词进行分类。训练的复杂性是
Q = N × D + D × log2(V ) . (4)
我们将此模型进一步表示为cbow,因为与标准的单词袋模型不同,它使用连续分布的上下文表示。模型架构如图1所示。请注意,输入层和投影层之间的权重矩阵对于所有单词位置的共享方式与NNLM中的相同。
3.2 连续Skip-gram 模型
第二种体系结构类似于cbow,但它不是根据上下文预测当前单词,而是根据同一句话中的另一个单词最大限度地分类一个单词。更准确地说,我们使用每个当前单词作为一个具有连续投影层的对数线性分类器的输入,并在当前单词前后的一定范围内预测单词。我们发现,增加范围可以提高结果字向量的质量,但同时也增加了计算的复杂性。由于距离较远的单词通常与当前单词的关联性比与当前单词的关联性小,因此我们通过从训练示例中的单词中抽取较少的样本来减少对距离较远的单词的权重。这种体系结构的训练复杂性如下:
Q = C × (D + D × log2(V )) (5)
其中c是单词的最大距离。因此,如果我们选择c=5,对于每个训练单词,我们将随机选择范围<1;c>内的数字r,然后使用历史和未来的R字作为当前字的正确标签。这将要求我们进行r×2字分类,输入当前字,输出每个r+r字。在下面的实验中,我们使用c=10。

4 结果
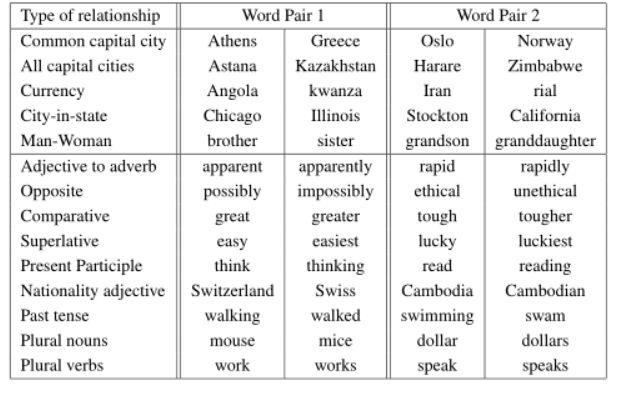
为了比较不同版本的词向量的质量,以前的论文通常使用一个表格来显示示例词及其最相似的词,并直观地理解它们。虽然很容易看出“法国”这个词与意大利和其他一些国家很相似,但当把这些向量放到一个更复杂的相似任务中时,它的挑战性要大得多,如下所示。我们根据前面的观察,单词之间可以有许多不同类型的相似性,例如,单词big和biger在相同的意义上相似,单词small和small相似。另一种关系类型的例子可以是单词对大-大和小-小[20]。我们进一步表示两对与问题关系相同的词,正如我们可以问的那样:“什么词与“小”相似,与“大”相同,与“大”相似?“有些令人惊讶的是,这些问题可以通过用词的矢量表示执行简单的代数运算来回答。要找到一个与“大”和“大”在同一意义上类似于“小”的词,我们可以简单地计算向量x=向量(“最大”)—向量(“大”)+向量(“小”)。然后,我们在向量空间中搜索余弦距离测量的最接近x的单词,并将其作为问题的答案(我们在搜索过程中丢弃输入的问题单词)。当单词向量经过良好的训练后,使用这种方法可以找到正确的答案(单词最小)。最后,我们发现,当我们在大量数据上训练高维的词向量时,所得到的向量可以用来回答词之间非常微妙的语义关系,例如城市和它所属的国家,例如法国对巴黎,德国对柏林。具有这种语义关系的词向量可用于改进现有的许多NLP应用程序,如机器翻译、信息检索和问答系统,并可使其他未来的应用程序得以发明。
4.1任务描述
为了度量词向量的质量,我们定义了一个综合测试集,包含五种语义问题和九种句法问题。表1显示了每类中的两个示例。总的来说,有8869个语义问题和10675个句法问题。每个类别中的问题都是通过两个步骤创建的:首先,手动创建类似单词对的列表。然后,通过连接两个词对形成一个大的问题列表。例如,我们列出了68个美国大城市及其所属的州,并通过随机选择两个词对,形成了大约2.5公里的问题。我们在测试集中只包含单个标记词,因此不存在多词实体(如纽约)。我们评估所有问题类型和每个问题类型(语义、句法)的整体准确性。只有当使用上述方法计算出的向量最接近的词与问题中的正确词完全相同时,才能假定问题得到正确回答;因此,同义词被视为错误。这也意味着要达到100%的准确度是不可能的,因为当前的模型没有任何有关词形的输入信息。然而,我们相信向量这个词在某些应用中的有用性应该与这个精度度量正相关。通过整合单词结构的信息,特别是在句法问题上,可以取得进一步的进展。
4.2最大限度地提高准确性
我们使用了谷歌新闻语料库来训练单词向量。这个语料库包含大约6B个标记。我们已经将词汇量限制在一百万个最常见的词。显然,我们正面临时间约束的优化问题,因为可以预期,使用更多的数据和更高的维字向量都将提高精度。为了快速评估模型体系结构的最佳选择以获得尽可能好的结果,我们首先对训练数据子集上训练的模型进行了评估,词汇限制在最频繁的30K单词。表2显示了使用CBOW体系结构的结果,该体系结构具有不同的词向量维数选择和不断增加的训练数据。可以看出,在某一点之后,添加更多维度或添加更多培训数据会减少改进。因此,我们必须同时增加向量维数和训练数据的数量。虽然这种观察可能看起来微不足道,但必须注意的是,目前流行的方法是在相对大量的数据上训练字向量,但大小不够。
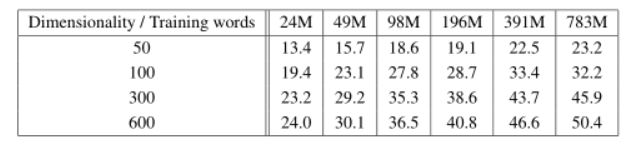
(例如50-100)。在等式4中,两次增加训练数据的数量会导致计算复杂性的增加,与两次增加向量大小的结果大致相同。对于表2和表4中报告的实验,我们使用了三个具有随机梯度下降和反向传播的训练时段。我们选择起始学习率0.025,并将其线性降低,使其在最后一个训练阶段结束时接近零。
4.3模型体系结构比较:
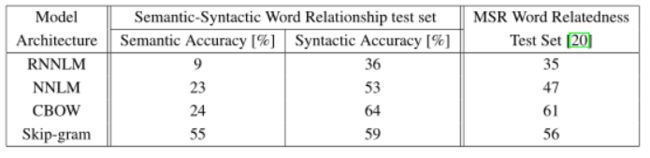
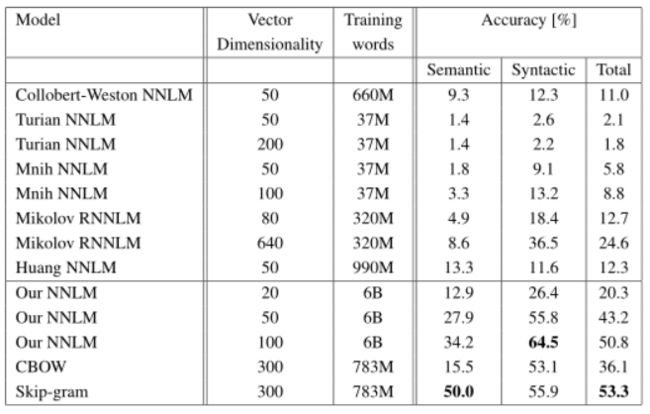
首先,我们比较不同的模型体系结构,以使用相同的训练数据和640个词向量的相同维数推导词向量。在进一步的实验中,我们在新的语义句法词汇关系测试集中使用了全套问题,即对30K词汇不受限制。我们还包括了[20]中介绍的一个测试集的结果,该测试集中于单词3之间的语法相似性。训练数据由几个LDC语料库组成,并在[18]中详细描述(320M单词,82K词汇)。我们使用这些数据提供了一个比较以前训练的重复神经网络语言模型,该模型在一个CPU上训练大约需要8周。我们使用距离信念并行训练[6]对640个隐藏单元的前馈nnlm进行了训练,使用之前8个单词的历史记录(因此,nnlm的参数比rnnlm多,因为投影层的大小为640×8)。在表3中,可以看到来自RNN的单词向量(如[20]中所用)在句法问题上表现良好。nnlm向量的性能明显优于rnn—这并不奇怪,因为rnnlm中的字向量直接连接到非线性隐藏层。CBOW体系结构在句法任务上比NNLM工作得更好,在语义任务上也差不多。最后,与cbow模型相比,skip-gram架构在句法任务上的效果稍差(但仍优于nnlm),在测试的语义部分比所有其他模型都要好得多。下一步,我们评估了我们的模型,使其在必要时应变,并对结果进行了比较,这些结果仍然是公开可用的词向量。比较见表4。CBOW模型是训练的子集
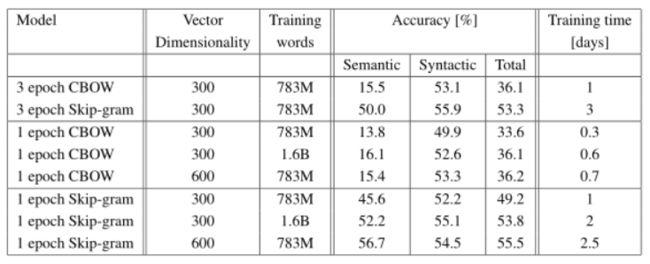
谷歌新闻的数据大约在一天内,而SkipGram模型的培训时间大约是三天。对于进一步报告的实验,我们只使用了一个训练阶段(同样,我们线性降低学习速度,使其在训练结束时接近零)。如表5所示,使用一个epoch对模型进行两倍于两倍于两倍的数据的训练,比对三个epoch的相同数据进行迭代得到的结果更具可比性或更好的结果,并提供了额外的小加速。
4.4前面提到的模型的大规模并行训练
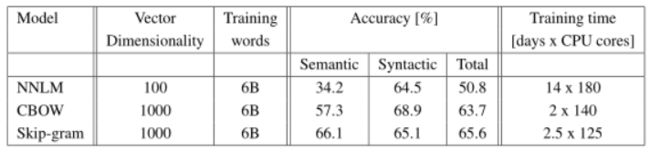
我们已经在一个称为distclience的分布式框架中实现了各种模型。下面我们报告了在Google News
6B数据集上训练的几个模型的结果,这些模型具有小批量异步梯度下降和自适应学习速率过程adagrad[7]。我们在培训期间使用了50到100个模型副本 , CPU核心数量是一个估计,因为数据中心机器与其他生产任务共享,并且使用情况可以波动很大。 请注意,由于分布式框架的开销,CBOW模型和Skip-gram模型的CPU使用率比单机器更接近实现。 结果报告在表6中。
4.5 Microsoft研究句子完成挑战赛
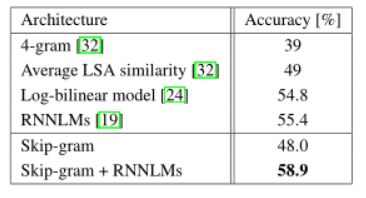
Microsoft句子完成挑战最近作为推进语言建模和其他NLP技术的任务引入[32]。这个任务由1040个句子组成,每个句子中有一个单词丢失,目标是选择与句子其余部分最连贯的单词,给出五个合理的选择列表。已经报告了这组技术的性能,包括n-gram模型、基于LSA的模型[32]、对数双线性模型[24]以及目前在这一基准上保持55.4%精确度的最先进性能的复发神经网络组合[19]。我们研究了Skip-Gram体系结构在这项任务中的性能。首先,我们在[32]中提供的50米单词上训练640维模型。然后,我们用输入的未知词来计算测试集中每个句子的分数,并预测句子中所有周围的单词。最后一句话的得分就是这些个别预测的总和。根据句子得分,我们选择最可能的句子。表7简要总结了一些以前的结果以及新的结果。虽然skip-gram模型本身在这项任务上的表现并不比lsa相似性更好,但该模型的分数与用rnnlms获得的分数是互补的,加权组合导致了一个新的最新结果,准确率为58.9%(集的开发部分为59.2%,集的测试部分为58.7%)。
5 学习关系的例子
表8显示了各种关系后面的单词。我们按照上面描述的方法:通过减去两个词向量来定义关系,结果被添加到另一个词。例如,巴黎-法国+意大利=罗马。可以看出,精度是相当好的,尽管显然还有很大的改进空间(请注意,使用我们的精度度量
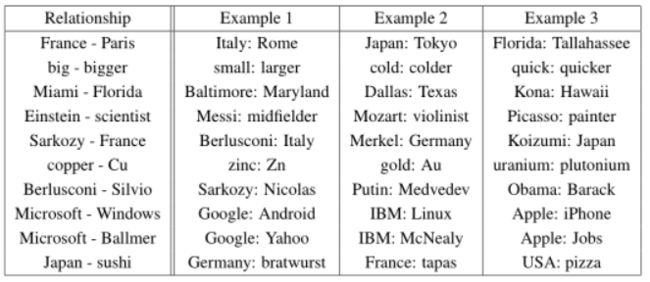
假设完全匹配,表8中的结果仅得分约60%。我们相信,在更大维度的数据集上训练的字向量将表现得更好,并将促进新的创新应用程序的开发。另一种方法是提高准确性,以提供关系的多个示例。通过使用十个例子而不是一个来形成关系向量(我们将单个向量平均在一起),我们观察到在语义句法测试中,我们的最佳模型的准确性提高了10%左右。也可以应用向量运算来解决不同的任务。例如,通过计算单词列表的平均向量,并找到最远的单词向量,我们观察到从列表中选择单词的准确性很好。这是某些人类智力测试中常见的一类问题。很明显,使用这些技术仍有很多发现要做
6 结论:
本文在一组句法和语义语言任务上,研究了不同模型派生词的矢量表示质量。我们观察到,与流行的神经网络模型(前馈和循环)相比,使用非常简单的模型结构来训练高质量的字向量是可能的。由于计算复杂度低得多,从大得多的数据集中计算高维字向量是可能的。使用distisfience分布式框架,应该可以训练cbow和skip-gram模型,甚至在拥有一万亿个单词的语料库上,基本上不限制词汇的大小。这比之前公布的同类模型的最佳结果大几个数量级。Semeval-2012任务2[11]是一项有趣的任务,其中矢量一词最近被证明显著优于先前的技术水平。公共可用的RNN向量与其他技术一起使用,以使Spearman的秩相关比之前的最佳结果提高50%以上[31]。基于神经网络的词向量以前应用于许多其他NLP任务,例如情感分析[12]和释义检测[28]。可以预期,这些应用程序可以从本文描述的模型体系结构中获益。我们正在进行的工作表明,矢量词可以成功地应用于知识库中事实的自动扩展,也可以用于验证现有事实的正确性。机器翻译实验的结果也很有希望。在未来,将我们的技术与潜在关系分析[30]和其他技术进行比较也会很有趣。我们相信,我们的综合测试集将有助于研究界改进现有的词汇向量估计技术。我们还期望高质量的字向量将成为未来NLP应用的重要组成部分。
7 后续工作
本文的初始版本被写入,我们出版了单机多线程C++代码计算字向量,同时使用连续的单词袋和跳过克架构4。训练速度明显高于本文前面的报道,即对于典型的超参数选择,它是以每小时数十亿字的顺序排列的。我们还发布了超过140万个矢量代表命名实体,训练了超过1000亿个单词。我们的一些后续工作将发表在即将发表的NIPS 2013年论文[21]中。
References
[1] Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model. Journal of Ma-
chine Learning Research, 3:1137-1155, 2003.
[2] Y. Bengio, Y. LeCun. Scaling learning algorithms towards AI. In: Large-Scale Kernel Ma-
chines, MIT Press, 2007.
[3] T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean. Large language models in machine
translation. In Proceedings of the Joint Conference on Empirical Methods in Natural Language
Processing and Computational Language Learning, 2007.
[4] R. Collobert and J. Weston. A Unified Architecture for Natural Language Processing: Deep
Neural Networks with Multitask Learning. In International Conference on Machine Learning,
ICML, 2008.
[5] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu and P. Kuksa. Natural Lan-
guage Processing (Almost) from Scratch. Journal of Machine Learning Research, 12:2493-
2537, 2011.
[6] J. Dean, G.S. Corrado, R. Monga, K. Chen, M. Devin, Q.V. Le, M.Z. Mao, M.A. Ranzato, A.
Senior, P. Tucker, K. Yang, A. Y. Ng., Large Scale Distributed Deep Networks, NIPS, 2012.
[7] J.C. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and
stochastic optimization. Journal of Machine Learning Research, 2011.
[8] J. Elman. Finding Structure in Time. Cognitive Science, 14, 179-211, 1990.
[9] Eric H. Huang, R. Socher, C. D. Manning and Andrew Y. Ng. Improving Word Representations
via Global Context and Multiple Word Prototypes. In: Proc. Association for Computational
Linguistics, 2012.
[10] G.E. Hinton, J.L. McClelland, D.E. Rumelhart. Distributed representations. In: Parallel dis-
tributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations,
MIT Press, 1986.
[11] D.A. Jurgens, S.M. Mohammad, P.D. Turney, K.J. Holyoak. Semeval-2012 task 2: Measuring
degrees of relational similarity. In: Proceedings of the 6th International Workshop on Semantic
Evaluation (SemEval 2012), 2012.
[12] A.L. Maas, R.E. Daly, P.T. Pham, D. Huang, A.Y. Ng, and C. Potts. Learning word vectors for
sentiment analysis. In Proceedings of ACL, 2011.
[13] T. Mikolov. Language Modeling for Speech Recognition in Czech, Masters thesis, Brno Uni-
versity of Technology, 2007.
[14] T. Mikolov, J. Kopeck´ y, L. Burget, O. Glembek and J.ˇCernock´ y. Neural network based lan-
guage models for higly inflective languages, In: Proc. ICASSP 2009.
[15] T. Mikolov, M. Karafiát, L. Burget, J.ˇCernock´ y, S. Khudanpur. Recurrent neural network
based language model, In: Proceedings of Interspeech, 2010.
[16] T. Mikolov, S.Kombrink, L. Burget, J.ˇCernock´ y, S.Khudanpur. Extensions of recurrentneural
network language model, In: Proceedings of ICASSP 2011.
[17] T. Mikolov, A. Deoras, S. Kombrink, L. Burget, J.ˇCernock´ y. Empirical Evaluation and Com-
bination of Advanced Language Modeling Techniques, In: Proceedings of Interspeech, 2011.
4The code is available at https://code.google.com/p/word2vec/
11
[18] T. Mikolov, A. Deoras, D. Povey, L. Burget, J.ˇCernock´ y. Strategies for Training Large Scale
Neural Network Language Models, In: Proc. Automatic Speech Recognition and Understand-
ing, 2011.
[19] T. Mikolov. Statistical Language Models based on Neural Networks. PhD thesis, Brno Univer-
sity of Technology, 2012.
[20] T. Mikolov, W.T. Yih, G. Zweig. Linguistic Regularities in Continuous Space Word Represen-
tations. NAACL HLT 2013.
[21] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean. Distributed Representations of
Words and Phrases and their Compositionality. Accepted to NIPS 2013.
[22] A. Mnih, G. Hinton. Three new graphical models for statistical language modelling. ICML,
2007.
[23] A. Mnih, G. Hinton. A Scalable Hierarchical Distributed Language Model. Advances in Neural
Information Processing Systems 21, MIT Press, 2009.
[24] A. Mnih, Y.W. Teh. A fast and simple algorithm for training neural probabilistic language
models. ICML, 2012.
[25] F. Morin, Y. Bengio. Hierarchical Probabilistic Neural Network Language Model. AISTATS,
2005.
[26] D. E. Rumelhart, G. E. Hinton, R. J. Williams. Learning internal representations by back-
propagating errors. Nature, 323:533.536, 1986.
[27] H. Schwenk. Continuous space language models. Computer Speech and Language, vol. 21,
2007.
[28] R. Socher, E.H. Huang, J. Pennington, A.Y. Ng, and C.D. Manning. Dynamic Pooling and
Unfolding Recursive Autoencoders for Paraphrase Detection. In NIPS, 2011.
[29] J. Turian, L. Ratinov, Y. Bengio. Word Representations: A Simple and General Method for
Semi-Supervised Learning. In: Proc. Association for Computational Linguistics, 2010.
[30] P. D. Turney. Measuring Semantic Similarity by Latent Relational Analysis. In: Proc. Interna-
tional Joint Conference on Artificial Intelligence, 2005.
[31] A. Zhila, W.T. Yih, C. Meek, G. Zweig, T. Mikolov. Combining Heterogeneous Models for
Measuring Relational Similarity. NAACL HLT 2013.
[32] G. Zweig, C.J.C. Burges. The Microsoft Research Sentence Completion Challenge, Microsoft
Research Technical Report MSR-TR-2011-129, 2011