官方文档:https://clickhouse.yandex
ClickHouse是什么?有什么?能做什么? 为什么用? 如何使用? 寻找一堆黑人问号的答案
一、ClickHouse介绍
ClickHouse(开源)是一个面向列的数据库管理系统(DBMS),用于在线分析处理查询(OLAP)。
关键词:开源、面向列、联机分析处理(OLAP)
ClickHouse不仅查询速度快(相较于hive等类似的分析型DBMS),而且硬件使用效率、容错性、可靠性、易用性、线性扩展性等高。
1.1 ClickHouse的独特功能
- 真正的列式DBMS
除了数据本身外不应该存在其他额外的数据。这意味着为了避免在值旁边存储它们的长度“number”,你必须支持固定长度数值类型。 - 数据压缩
数据压缩存储在性能方面发挥着关键作用 - 数据的磁盘存储
工作在传统磁盘上的系统 - 多核心并行处理
大型查询以一种自然的方式并行化,占用当前服务器上可用的所有必要资源 - 多服务器分布式处理
在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行的在所有shard上进行处理 - 支持SQL
ClickHouse支持基于SQL的查询语言,该语言大部分情况下是与SQL标准兼容的。 支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。 不支持窗口函数和相关子查询 - 向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理 - 实时的数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断高效的写入到表中,并且写入的过程中不会存在任何加锁的行为 - 索引
按照主键对数据进行排序,使能够以几十毫秒的低延迟对数据进行特定值查找或范围查找 - 适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中 - 支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
1、用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
2、 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
3、 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
1.2 OLAP场景特征(适用场景)
- 绝大多数都是读请求
- 数据以相当大的批量写入(> 1000行),而不是单行。
- 不再修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外,其他都是小表
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合后能够被存放在单台服务器的内存中
1.3 缺点(不适用场景)
- 没有完整的事物支持
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询
1.4 官方性能对比
ClickHouse的性能超过了市场上现有的类似的面向列的DBMS。它每秒处理数亿到10亿行,每台服务器每秒处理数百亿字节的数据。单个查询(解压缩后,仅使用列)的处理性能峰值为每秒2 tb以上。
我们来看看官网提供的对比数据:分析型DBMS的性能比较
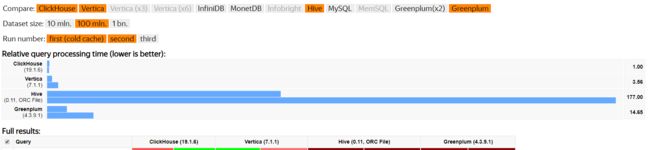
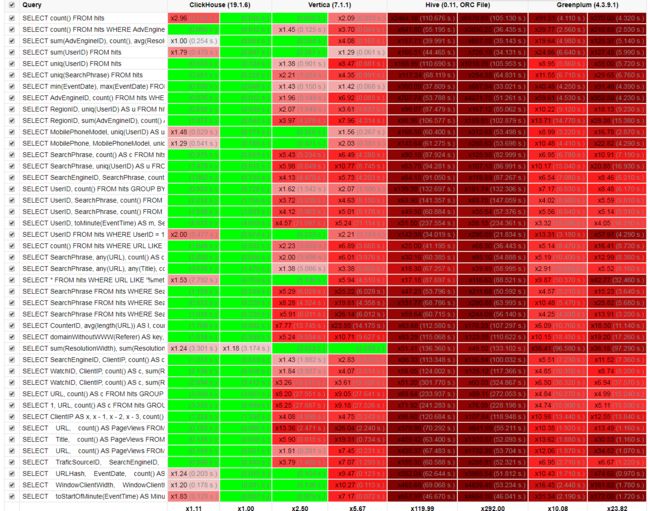
由上图看出,ClickHouse比传统的分析型数据库快100-1000倍。
毕竟是官方自己提供的数据,为了更加真实的性能测试,后面会在实际环境中和GreenPlum等做测试对比。
1.5 数据类型支持
- UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64 分别对应mysql数据类型smallint,tinyint,int,bigint/long
- Float32, Float64分别对应mysql数据类型 float,double
- Decimal
- Boolean
- String
- FixedString(N)
- UUID
- Date
- DateTime 分别对应mysql数据类型datetime/timestamp
- Enum
- Array(T)
- AggregateFunction(name, types_of_arguments...)
- Tuple(T1, T2, ...)
- Nullable
嵌套数据类型 - Nested(Name1 Type1, Name2 Type2, ...)
特殊数据类型 - Expression
- Set
- Nothing
二、安装部署(Centos7)
2.1 环境准备
参考hadoop集群搭建中的一、安装环境准备和二、安装zookeeper
2.2 安装CLickHouse(每台集群)
在此只介绍脚本安装方式,手动及其他可参考:
https://github.com/Altinity/clickhouse-rpm-install/blob/master/README.md
https://clickhouse.yandex/docs/zh/getting_started/
Step1: 如果从官方仓库安装,需要确保您使用的是x86_64处理器构架的Linux并且支持SSE 4.2指令集
检查是否支持SSE 4.2:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
返回结果应为:“SSE 4.2 supported”
Step2: 基于脚本安装
- 安装依赖
sudo yum install -y curl
- 下载运行脚本
centos7显式指定os=centos dist=7两个参数
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo os=centos dist=7 bash
- 查看clickhouse可用安装包
sudo yum list 'clickhouse*'
结果如下列表:有多个可用的包(包括新版本和旧工具),其中一些已经被弃用,因此不需要安装所有可用的rpm。

Step3: 安装ClickHouse的主要部分——服务器和客户端应用程序
sudo yum install -y clickhouse-server clickhouse-client
查看校验已安装列表
sudo yum list installed 'clickhouse*'
Step4: 配置目录查看及修改
安装完后默认的配置文件路径在
/etc/clickhouse-server/下:config.xml(默认系统配置) 、users.xml(用户相关配置)
通过查看配置文件config.xml,定了默认的数据目录、临时目录、日志目录等;
/var/lib/clickhouse
/var/lib/clickhouse/tmp/
/var/log/clickhouse-server
实际生产环境中,这些数据目录通常放在数据盘而不是系统盘,所以会做相应调整。默认启动脚本:
/etc/rc.d/init.d/clickhouse-server最大打开文件数:
/etc/security/limits.d/clickhouse.conf
clickhouse soft nofile 262144
clickhouse hard nofile 262144定时任务文件:
/etc/cron.d/clickhouse-server(看看就好了。cron进程执行时,就会自动扫描该目录下的所有文件,按照文件中的时间设定执行后面的命令),文件内容如下:
*/10 * * * * root (which service > /dev/null 2>&1 && (service clickhouse-server condstart ||:)) || /etc/init.d/clickhouse-server condstart > /dev/null 2>&1
- 安装二进制文件目录:
/usr/bin/clickhouse*,共享文件目录:/usr/share/clickhouse/
大都软链接到了clickhouse这个二进制文件
更多服务端配置(/etc/clickhouse-server/config.xml )及说明文档
Step5: 确保ClickHouse服务器正在运行
sudo /etc/init.d/clickhouse-server restart
Step6: 客户端连接命令
clickhouse-client
至此单机安装完毕。
2.3 集群配置
这一部分官方文档整理的不够清晰条理,个人觉得。
首先查看配置文件的文档,里面大致介绍了服务端配置的覆盖(替代)文件和用户配置文件的创建和配置。然后找到分布式文档参考配置新的内容。具体整理如下步骤。
2.3.1 创建扩展配置文件(metrika.xml)
- 配置对应config.xml的中的标签进行复制扩展,新的标签名应和config.xml中
incl="替换的标签名"一致。 - 每个clickhouse-server实例默认配置下对应只能被配置为某个数据分片(shard)的唯一副本(replica)。或添加内部复制端口配置。
默认本节点实例1:
8123
9000
9009
添加本节点实例2 :
8124
9001
9010
参考:https://www.cnblogs.com/freeweb/p/9352947.html
- 添加zookeeper配置需要重启集群服务,此时会在zk客户端查看生产/clickhouse目录
- 配置需添加在
完整配置示例如下:
1
true
hdc-data4
9000
default
Hdc2019
1
true
hdc-data5
9000
default
Hdc2019
1
true
hdc-data6
9000
default
Hdc2019
01
03
hdc-data6
::/0
hdc-data4
2181
hdc-data5
2181
hdc-data6
2181
10000000000
0.01
lz4
补充说明:
| 标签名 | 描述 |
|---|---|
| clickhouse_remote_servers | 配置分布式表中使用的集群。 |
| hdc_3s1r_cluster | 自定义的标签名,也就是集群名称。群集名称不能包含“.”(点)符号。 |
| shard | 数据分片标签,一个shard标签组代表一个数据分片。 |
| weight | 定义数据分片的数据权重。比如有两个分片,第一个权重为9,第二个权重为10,则该批次的行将会有9/19的数据被发送到第一个分片,10/19的数据被发送到第二分片。 |
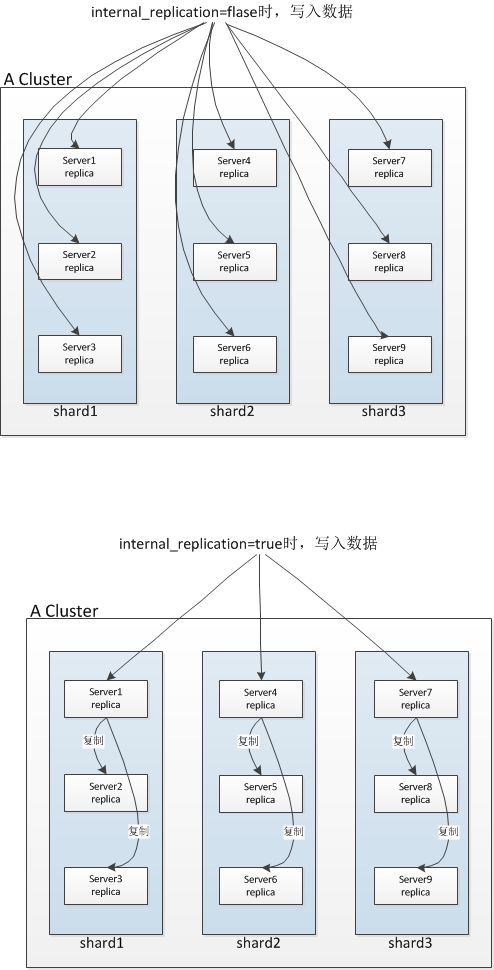
| internal_replication | 是否启用内部复制。true 代表写入数据时选择第一个健康的副本进行写入,其余副本以该表本身进行复制,保证复制表的一致性。false(默认) 代表将数据直接写入所有副本,因为没有检查复制表的一致性,而且随着时间的推移,它们将包含略微不同的数据。 |
| replica | 指定分片数据副本,可为每个服务器指定参数主机、端口和可选的用户、密码、安全、压缩等 |
| host | 数据分片远程服务地址(支持IPv6 )。如果指定了域名(domain),服务器在启动时发出DNS请求并且只要服务器在运行就能一直保存结果。如果DNS请求失败,服务器不会启动。如果更改DNS记录,请重新启动服务器。 |
| port | TCP端口(对应config.xml的"tcp_port",通常设置为9000)。不要将其与http_port混淆。 |
| user | 连接到远程服务器的用户的名称。默认值:"default"。此用户必须具有连接到指定服务器的权限。对应的用户名和密码是在user.xml定义。 |
| password | 连接到远程服务器的密码。默认值:空字符串。根据实际在user.xml中对应用户的密码明文。 |
| secure | 使用ssl进行连接,通常还应该定义端口= 9440。服务器应该监听9440并且有正确的证书,对应config.xml中“tcp_port_secure”。(示例中无) |
| compression | 开启数据压缩,默认True(示例中无) |
| macros | 宏定义。{layer} - ClickHouse集群的昵称,用于区分不同集群之间的数据。{shard} - 分片编号或符号引用。{replica} - 副本的名称(唯一),通常与主机名匹配macros为可选定义。配置文件中定义了在创建表时每台服务器就可以使用相同的建表DDL。否则要ReplicatedMergeTree指定zk路径和replica值。(后面复制表细讲) |
| networks | 监听网络,::/0代表监听所有ip |
| zookeeper-servers | ClickHouse在使用复制表时使用ZooKeeper存储复制元数据。和config.xml文件中 |
| clickhouse_compression | ClickHouse检查{min_part_size}和{min_part_size_ratio},并处理与这些条件匹配的{case}块。如果 |
2.3.2 修改config.xml配置
在/etc/clickhouse-server/config.xml中放开远程主机监听
::1
0.0.0.0
遇到问题:
- 登录时报异常 Code: 210. DB::NetException: Connection refused (localhost:9000, ::1)
解决:需要开放。另外zookeeper集群没有正常启动也会造成建表时报此类错误。::1
默认路径为/etc/metrika.xml。若想改变路径或文件名则需要在/etc/clickhouse-server/config.xml中添加例如下配置:
/etc/clickhouse-server/metrica.xml
2.3.3 修改用户配置(user.xml)
出于安全性考虑,将明文密码配置
。
加密密码生成方式1(随机生成):
PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
加密密码生成方式2(指定密码):
echo -n "your password" | sha256sum | tr -d '-'-
在profiles标签下的readonly标签添加如下配置:
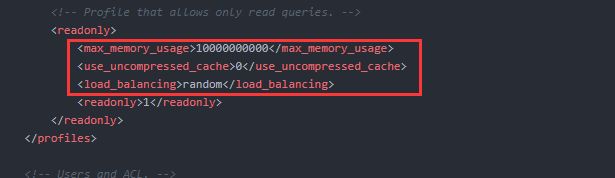
示例,添加一个只读用户
8545f4dc3fe83224980663ebc2540d6a68288c8afcbaf4da3b22e72212e256e1
::/0
readonly
default
default
2.3.4 重启集群及查看状态
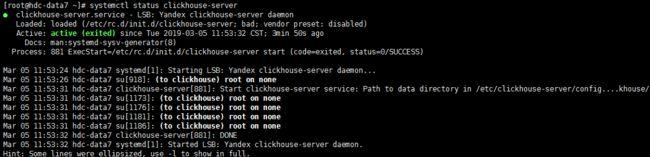
2.3.5 登录验证
clickhouse-client -u 'ckh_readonly' --password 'ck10086'
更多参数帮助:clickhouse-client --help

改用默认用户登录,创建分布式表(建表语句需要在每台数据分片的服务器上都执行一遍,大规模集群通常通过脚本维护)。为何要这样创建,后面讲解。
CREATE TABLE ontime_local (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(hdc_3s1r_cluster, default, ontime_local, rand());
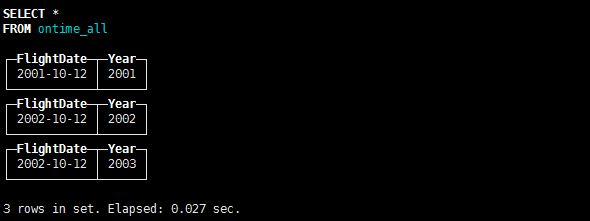
插入测试数据
insert into ontime_all (FlightDate,Year)values('2001-10-12',2001);
insert into ontime_all (FlightDate,Year)values('2002-10-12',2002);
insert into ontime_all (FlightDate,Year)values('2002-10-12',2003);
在任何一台服务器客户端查询结果:
三、表的基本理解和使用
在分布式集群中,我们通常需要先创建本地表(分片表/复制表)再创建分布式表。因为分布式表只是作为一个查询引擎,本身不存储任何数据,查询时将sql发送到所有集群分片,然后进行进行处理和聚合后将结果返回给客户端。创建什么样的表,需要根据实际的使用场景决定在创建表指定什么样的表引擎。
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。
对于大多数正式的任务,应该使用MergeTree族中的引擎。
首先了解一下建表的几种方式
Way 1: 常规语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
Way 2: 具有相同结构的表,同时可以对其指定不同的表引擎声明。
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
Way 3: 使用指定的引擎创建一个与SELECT子句的结果具有相同结构的表,并使用SELECT子句的结果填充。
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...
由上可知,ENGINE = ?需要我们对表引擎的了解才能做出选择。
根据个人的理解以分片表、复制表和分布式表来展开介绍部分表引擎。这里更多的是介绍引擎的特性以便更好地对相应的场景做出选择。更多可以参考官网。
3.1 分片表 & 表引擎
每个节点都有一个数据子集。重申一遍,每个clickhouse-server实例下对应只能被配置为某个数据分片(shard)的唯一副本(replica)。
分布式高可用方案:分片表+分布式表+集群复制(即一个数据分片(shard)下配置多个副本主机(replica))
3.1.1 MergeTree引擎
MergeTree引擎及其家族(*MergeTree)的其他引擎是ClickHouse健壮性最强的表引擎。
MergeTree主要特性:
- 存储按住键排序的数据
允许创建一个小的稀疏索引来帮助快速查询数据 - 允许在指定分区键时使用分区
- 支持数据复制
- 支持数据采样
使用方式1 示例:
ENGINE MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity=8192
说明:
ENGINE ——指定引擎类型
PARTITION BY——指点分区字段(可选)。对于按月分区的表,日期字段需格式化为“YYYYMM”,转换函数:toYYYYMM(date_column)。通常该字段需为Date类型。
ORDER BY——指定排序字段(可选),tuple类型。例如:ORDER BY (CounterID, EventDate)
PRIMARY KEY——指定主键字段(可选)。通常主键默认和排序(ORDER BY)字段相同,不需另外指定。
SAMPLE BY——抽样的表达式(可选),表达式(列)必须被主键包含,例如:SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))
SETTINGS——控制合并树的其他参数设置(可选)。index_granularity——索引的粒度。索引“标记”之间的数据行数。默认值:8192。
使用方式2 示例:
ENGINE = MergeTree(PARTITION column, (ORDER BY column), 8192);
MergeTree家族的引擎需要使用Date类型的列来指定分区。
3.1.2 ReplacingMergeTree引擎
继承自MergeTree。ReplacingMergeTree与MergeTree的不同之处在于,它删除具有相同主键值的重复条目。重复数据删除仅在合并期间发生,并且合并发生在一个未知的时间。因此,ReplacingMergeTree适合清除后台的重复数据以节省空间,但并不保证没有重复数据。
ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
说明:ver——列版本,输入类型UInt*、Date或DateTime,可选参数。其他参照MergeTree参数说明。
3.1.3 SummingMergeTree引擎
继承自MergeTree。不同之处在于,当合并SummingMergeTree表的数据部分时,ClickHouse将所有具有相同主键的行替换为一行,该行包含数字数据类型的列的汇总值。如果主键的组合方式是单个键值对应于大量行,这将显著减少存储容量并加快数据选择。
ENGINE = SummingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
体现在select的时候使用sum(columns )和group by 。columns 必须是数字类型,并且不能在主键中。如果不指定columns,ClickHouse用非主键的数字数据类型总结了所有列中的值。
3.1.4 AggregatingMergeTree引擎
继承自MergeTree,改变了数据部件合并的逻辑。ClickHouse用存储聚合函数状态组合的单个行(在一个数据部分内)替换所有具有相同主键的行。
ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
物化视图示例:
CREATE MATERIALIZED VIEW test.basic
ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(StartDate) ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM test.visits
GROUP BY CounterID, StartDate;
说明:写入数据到test.visits表 时,同时生产聚合写入到视图。可以通过如下语句查询聚合结果:
SELECT
StartDate,
sumMerge(Visits) AS Visits,
uniqMerge(Users) AS Users
FROM test.basic
GROUP BY StartDate
ORDER BY StartDate;
3.1.5 CollapsingMergeTree引擎
承自MergeTree,将行瓦解/折叠的逻辑添加到数据部件合并算法中。如果一行中的所有字段都是等效的,除具有1和-1值的特定字段符号外,则会异步删除(瓦解/折叠)行等效字段。该引擎可以显著减少存储容量,提高SELECT查询的效率。
ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
说明:sign——如果Sign = 1表示行是对象的状态,我们称之为“state”行。如果符号= -1表示取消具有相同属性的对象的状态,我们称之为“cancel”行。列数据类型- Int8。
例如数据:
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 5 │ 146 │ 1 │
│ 4324182021466249494 │ 5 │ 146 │ -1 │
│ 4324182021466249494 │ 6 │ 185 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘
- 表结构如下:
CREATE TABLE UAct
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY UserID- 我们可以通过聚合获取结果:
SELECT
UserID,
sum(PageViews * Sign) AS PageViews,
sum(Duration * Sign) AS Duration
FROM UAct
GROUP BY UserID
HAVING sum(Sign) > 0
┌──────────────UserID─┬─PageViews─┬─Duration─┐
│ 4324182021466249494 │ 6 │ 185 │
└─────────────────────┴───────────┴──────────┘- 如果不需要聚合并希望强制折叠,可以FINAL修饰符。
SELECT * FROM UAct FINAL
┌──────────────UserID─┬─PageViews─┬─Duration─┬─Sign─┐
│ 4324182021466249494 │ 6 │ 185 │ 1 │
└─────────────────────┴───────────┴──────────┴──────┘
3.1.6 VersionedCollapsingMergeTree引擎
承自MergeTree,并将行折叠的逻辑添加到数据部件合并算法中。VersionedCollapsingMergeTree解决了与CollapsingMergeTree相同的问题,但是使用了另一种折叠算法。它允许使用多个线程以任意顺序插入数据。特定的Version列有助于正确地折叠行,即使它们以错误的顺序插入。折叠合并树只允许严格连续的插入。
- 允许快速写入不断变化的对象状态。
- 删除后台对象的旧状态。它会导致存储容量的显著减少。
3.1.7 Log引擎家族
这些引擎是为需要使用少量数据(少于100万行)编写许多表的场景而开发的。
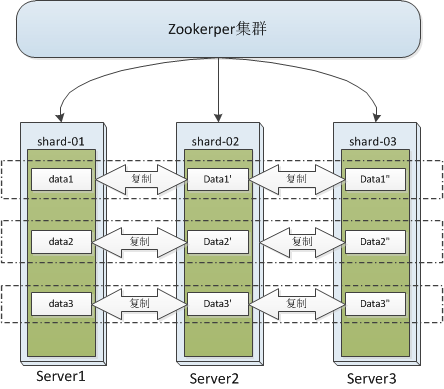
3.2 复制表 & 复制表引擎
复制表用于在不同服务器上存储数据的多个副本, 严重依赖Zookeeper(ZooKeeper 3.4.5+),不同的Zookeeper路径允许支持不同的复制拓扑。由于很难为每个节点的每个表创建自定义路径,因此ClickHouse提供了宏替换机制。宏在每个节点的配置文件中定义(为此目的使用单独的文件是有意义的,例如/etc/clickhouseserver/macros.xml)并在大括号中引用。对于复制表,宏参与两个地方:
- Zookeeper中表的znode的路径
- 副本名称具有相同ZooKeeper路径的表将是特定数据分片的副本。插入可以转到任何副本,ClickHouse接管复制以确保所有副本处于一致状态。插入不强制一致性,复制是异步的。可以使用不同的Zookeper路径模拟不同的复制拓扑。
例如宏配置如下所示:
05
02
xxxx
在此示例中定义了3个宏:
{layer} - ClickHouse集群的昵称,用于区分不同集群之间的数据。
{shard} - 分片编号或符号引用
{replica} - 副本的名称,通常与主机名匹配
这样在创建复制表时就可以直接使用宏定义而不用在不同的服务器创建表时都要修改对应的zk路径和副本({replica})标识,例如:
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/
','{replica}', , (sort columns), 8192)
分布式高可用方案:复制表+分布式表
说明:
1、复制表的副本和配置文件中配置shard下的replica无关。换句话说,数据备份与分片没有必然联系。
2、zookeeper与select查询无关,因为查询性能与复制无关。复制表的查询性能和非复制表一样。
3、复制是异步和多主机的。INSERT查询(以及ALTER)可以发送到任何可用的服务器。在运行查询的服务器上插入数据,然后将数据复制到其他服务器。因为它是异步的,所以最近插入的数据会出现在其他副本上,有一些延迟。如果部分副本不可用,则在它们可用时写入数据。如果副本可用,则延迟是通过网络传输压缩数据块所需的时间。
4、数据块作为原子单位,INSERT被划分为max_insert_block_size = 1048576行的块。
5、在复制期间,仅通过网络传输要插入的源数据。进一步的数据转换(合并)以相同的方式在所有副本上协调和执行。
6、系统监视副本上的数据同步性,并能够在失败后恢复。故障转移是自动的(对于数据的微小差异)或半自动的(当数据差异过大时,这可能表明存在配置错误)。
另外,复制表目前只有MergeTree引擎家族中以下引擎支持:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
3.3 分布式表 & Distributed引擎
分布式表用于使用单个表接口访问位于不同服务器的表(数据分片)。分布式表由“分布式”引擎定义,实际上是分片表上的接口。建议进行客户端分割,并将数据插入ClickHouse节点上的本地切分表中。但是,也可以直接插入到分布式表中。
在一个ClickHouse系统中,可以使用不同的集群,例如,有些表可以不复制地分片,有些表可以复制,等等。还可以在“子集群”中存储一些数据,但可以通过全局分布式表访问它们。
将分布式表视为一个接口更容易。建议进行客户端分段并将数据插入到ClickHouse节点上的本地分片表中。但是,也可以直接插入分布式表中,ClickHouse使用分片键顶部的哈希函数分发数据。
集群配置可以动态更新。因此,如果向分布式表中添加新节点,则不需要重新启动服务器。如果需要将单个节点表扩展到多个服务器,则过程如下:
- 在新服务器上创建分片表
- 必要时重新分发数据(手动更好,但ClickHouse也支持重新分片)
- 定义集群配置并将其放在每个ClickHouse节点上
- 创建分布式表以访问多个分片中的数据
ENGINE = Distributed(
, , [, sharding_key])
3.4 其他常用引擎
3.4.1MySQL 引擎
对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。
调用格式:
MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
调用参数
-
host:port— MySQL 服务器地址。 -
database— 数据库的名称。 -
table— 表名称。 -
user— 数据库用户。 -
password— 用户密码。 -
replace_query— 将INSERT INTO查询是否替换为REPLACE INTO的标志。如果replace_query=1,则替换查询 -
'on_duplicate_clause'— 将ON DUPLICATE KEY UPDATE 'on_duplicate_clause'表达式添加到INSERT查询语句中。例如:impression = VALUES(impression) + impression。如果需要指定'on_duplicate_clause',则需要设置replace_query=0。如果同时设置replace_query = 1和'on_duplicate_clause',则会抛出异常。
此时,简单的 WHERE 子句(例如 =, !=, >, >=, <, <=)是在 MySQL 服务器上执行。
其余条件以及 LIMIT 采样约束语句仅在对MySQL的查询完成后才在ClickHouse中执行。
MySQL 引擎不支持 Nullable 数据类型,因此,当从MySQL表中读取数据时,NULL 将转换为指定列类型的默认值(通常为0或空字符串)。
3.4.2 Kafka引擎
ClickHouse结合Kafka使用。
Kafka SETTINGS
kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'topic1,topic2',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_schema = '',
kafka_num_consumers = 2
示例:
CREATE TABLE queue (
timestamp UInt64,
level String,
message String
) ENGINE = Kafka('localhost:9092', 'topic', 'group1', 'JSONEachRow');SELECT * FROM queue LIMIT 5;
CREATE TABLE queue2 (
timestamp UInt64,
level String,
message String
) ENGINE = Kafka SETTINGS kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'topic',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow',
kafka_num_consumers = 4;
五、性能测试
本次测试基于虚拟机搭建的集群。性能方面有影响,只做参考。
你可以使用官网的数据进行测试,具体查看https://clickhouse.yandex/docs/en/single/?query=internal_replication#import-from-raw-data
本次测试示例将从mysql表中导入数据到clickhouse。首先创建本地表和分布式表(使用ON CLUSTER就不用再每一台服务器执行下面的建表DDL),表结构如下(这里只列出部分列,总列数63):
CREATE TABLE demo.elec_meter_data ON CLUSTER hdc_3s1r_cluster(
`id` Int64,
`loc_id` Int64,
`gw_id` Int32,
`meter_id` Int32,
`zxygz` Decimal(20,4),
`dya` Decimal(20,4),
`dyb` Decimal(20,4),
`dyc` Decimal(20,4),
`dla` Decimal(20,4),
`dlb` Decimal(20,4),
`dlc` Decimal(20,4),
`ygglz` Decimal(12,4),
`date_time` DateTime,
`create_time` DateTime
) ENGINE=MergeTree()
ORDER BY (id);
注意:
The MySQL engine does not support the Nullable data type, so when reading data from MySQL tables, NULL is converted to default values for the specified column type (usually 0 or an empty string).
尝试建表时指定默认值对于mysql的null值,依然报:Cannot convert NULL value to non-Nullable type...
创建分布式表(每台集群机器执行)
CREATE TABLE demo.elec_meter_data_all AS demo.elec_meter_data ENGINE = Distributed(hdc_3s1r_cluster, demo, elec_meter_data, rand());
INSERT INTO demo.elec_meter_data_all (
`id`,
`loc_id`,
`gw_id`,
`meter_id`,
`zxygz`,
`dya`,
`dyb`,
`dyc`,
`dla`,
`dlb`,
`dlc`,
`ygglz`,
`date_time`,
`create_time`)
SELECT `id`,
`loc_id`,
`gw_id`,
`meter_id`,
`zxygz`,
`dya`,
`dyb`,
`dyc`,
`dla`,
`dlb`,
`dlc`,
`ygglz`,
`date_time`,
`create_time`
FROM mysql('host:port', 'database_name', 'table_name', 'username', 'password');
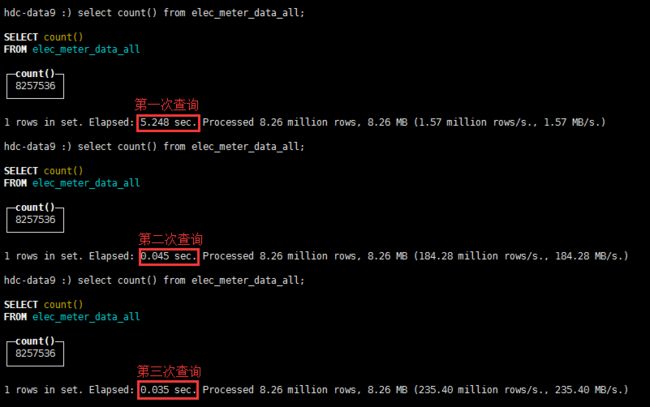

六、常见问题
- 内存不足,调整配置(仅参考)
100000000000
50000000000
80000000000
1