VOC数据集制作
VOC数据集制作
- 1 获取数据
-
- 1.1 获取图片
- 1.2 图片大小重置
- 1.3 图片重命名
- 2 标记图片
- 3 按照PascalVOC数据集的格式整理自己的数据
- 4 划分训练集和测试集
1 获取数据
1.1 获取图片
对于数据的获取,可以是图片形式,也可以是视频形式,但最终将转化成图片的形式进行数据集的制作。如果是图片的话,可以直接略去这一步,如果是视频文件,我们利用下列代码将数据转化成图片。
import cv2
import os
import sys
#参数1包含视频片段的路径
input_path = "./video"
#参数2设定每隔多少帧截取一帧
fram_interval = 7
#列出文件夹下所有的视频文件
filenames = os.listdir(input_path)
#获取文件夹名称
video_prefix = input_path.split(os.sep)[-1]
#建立一个新文件夹,名称为原文件夹名称后加上_frames
frame_path = '{}_frame'.format(input_path)
if not os.path.exists(frame_path):
os.mkdir(frame_path)
#初始化一个VideoCapture对象
cap = cv2.VideoCapture()
#遍历所有文件
for filename in filenames:
filepath = os.sep.join([input_path,filename])
#VideoCapture::open函数可以从文件获取视频
cap.open(filepath)
#获取视频帧数
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 对于一些低画质的摄像头,前面的帧可能不稳定,略过
for i in range(42):
cap.read()
for i in range(n_frames):
ret, frame = cap.read()
#每隔frame_interval帧进行一次截屏操作
if i % fram_interval == 0:
imagename = '{}_{:0>6d}.jpg'.format(filename.split('.')[0],i)
imagepath = os.sep.join([frame_path,imagename])
print('exported {}!'.format(imagepath))
cv2.imwrite(imagepath,frame)
#执行结束释放资源
cap.release()
1.2 图片大小重置
对于我们获取到的图片,有可能大小不一,我们需要先将图片的大小统一,使用下面的代码:
import cv2
import glob
import os
image_path = "./pictures/old/*.jpg" # 原始图片路径
output_path = "./pictures/new/" # 修改后的保存路径
count = 0
for jpgfile in glob.glob(image_path):
count += 1
#img = Image.open(jpgfile)
image = cv2.imread(jpgfile )
image = cv2.resize(image,(1280,720),interpolation=cv2.INTER_CUBIC)
cv2.imwrite(os.path.join(output_path,os.path.basename(jpgfile)), image)
print("save%d"%count)
print("resize finished!")
1.3 图片重命名
对于获取到的图片,最好按照一个统一的格式编号进行命名,以便后续增加新的图片进来,使用如下代码进行图片的重命名:
import os
path=input('请输入文件路径(结尾加上/):')
#获取该目录下所有文件,存入列表中
fileList=os.listdir(path)
n=0
m=0 # 图片编号从m+1开始
for i in fileList:
#设置旧文件名(就是路径+文件名)
oldname=path+ os.sep + fileList[n] # os.sep添加系统分隔符
#设置新文件名
newname=path+os.sep +"train"+str(m+1)+".jpg"
os.rename(oldname,newname) #用os模块中的rename方法对文件改名
print(oldname,'======>',newname)
n+=1
m+=1
2 标记图片
根据PascalVOC数据集的需要,使用Labelimg工具对图片进行标注,标注后会生成XML文件,如下图所示:

第一步:安装Labelimg,打开命令提示符,在其中输入如下命令:(如果是安装在anaconda的某个虚拟环境中,则需要先启动虚拟环境,再输入下面的命令)
pip install labelimg
第二步:打开labelimg,只需在命令提示符中输入命令:
labelimg
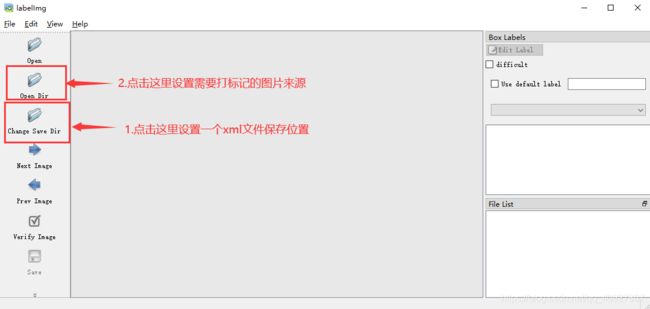
第三步:设置xml文件保存的位置和需要标记的图片位置
第四步:设置软件。点击左上角的“Edit”,取消选中“Draw Squares”,这样我们在对图片进行标注的时候,标注框的长宽比才是可变的,不然只能标记正方形的框。

第五步:开始标注。按一下键盘上的“W”键,鼠标所在的地方会出现十字形,然后按住鼠标左键,拖动鼠标即可画出一个矩形框,松开鼠标左键后,会弹出来一个对话框,在里面输入所标记物体的类别名(只需给类别名第一次出现时进行输入,后续标记该类物体时,可以直接在下面进行双击选择)。重复该操作标记图片中所有的物体。

第六步:图片的保存和切换。一种方法是:当标记完图片中所有物体时,先保存,再切换下一张图片,当然也可以切换上一张图片,通过左边的功能区按钮进行操作。

这样的方法显然很麻烦,因此可以设置自动保存图片,就不用每标记一张图片按一次保存按钮了。具体方法是,点击左上方的“View”,再选中“Auto Save mode”。

另外,还有三个常用的快捷键:
Ctrl+S:保存
D:下一张图片
A:上一张图片
3 按照PascalVOC数据集的格式整理自己的数据
我分别建立了VOCTrainval和VOCTest两个数据文件,分别用于训练和测试,大家也可以不分开,后面进行训练和测试数据划分就行了,两个文件夹都按照PascalVOC的格式建立。PascalVOC数据集包含了5个部分,在实验中我们只需要用到一下三个文件夹:
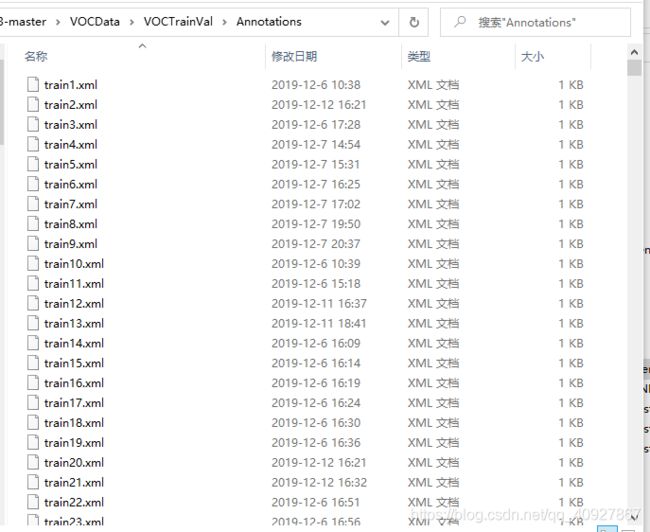
1) Annatations文件夹
文件夹存放的是xml格式的标签文件,每个xml文件都对应于JPEGImages文件夹的一张图片。
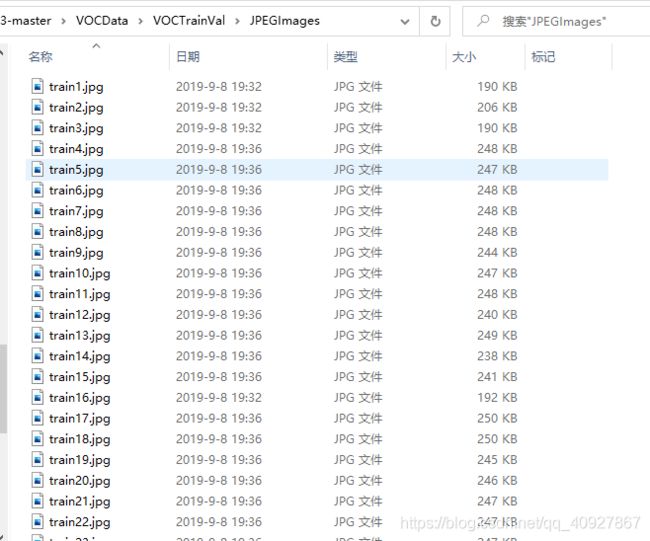
2)JPEGImages文件夹
文件夹里包含了训练图片或测试图片。
3)ImageSets文件夹
该文件夹里原有三个子文件夹,但实验中我们仅需要使用Main文件夹里面的信息,存放的是图像物体识别的数据,有train.txt, val.txt ,trainval.txt.这三个文件(VOCTrainval文件夹下)或者test.txt 文件(VOCTest)。这几个文件我们后面会生成。
按照要求,将自己的图片放入JPEGImages文件夹,将标注信息xml文件放入Annatations文件夹:
4 划分训练集和测试集
训练时要有测试集和训练集,如果在制作数据集的时候没有像我一样进行区分,那么在这里就需要使用代码将数据进行划分,放在ImageSets\Main文件夹下。代码如下,至于训练验证集和测试集的划分比例,以及训练集和验证集的划分比例,根据自己的数据情况决定。使用下面的代码进行划分:
import os
import random
xmlfilepath=r'./VOCData/VOCTrainVal/Annotations/' #xml文件的路径
saveBasePath=r'./VOCData/VOCTrainVal/ImageSets/' #生成的txt文件的保存路径
trainval_percent=0.9 # 训练验证集占整个数据集的比重(划分训练集和测试验证集)
train_percent=0.8 # 训练集占整个训练验证集的比重(划分训练集和验证集)
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
运行后,得到ImageSets\Main\文件下的几个.txt文件。
到此数据集制作完成!