windows10+vs2015+yolov3训练自己的数据集教程
1、制作自己的数据集
首先准备好自己的图片,为了规划自己的数据,减少出错的可能性,最好自己先给自己的图片编一个合理的序号,比如0001~0999。,然后框图打标签,使用方法非常简单。
本文使用windows下使用已经编译好的labelImg1.8.0直接标注得到yolo文件,无需中间的xml
yolo训练只需要图片和对应的txt描述文件,直接标注得到会方便很多,而且不用下载python编辑器进行xml到txt转换,如果已经得到xml参考文末链接
下载得到可执行的labelImg.exe文件。直接将文件放在windows环境下,双击可执行。

data里存的是标注数据的名称,可以自己添加

双击labelImg执行文件图标,会出现操作界面:

出现这样的窗口界面,说明labelImg已经正常开启,背景黑色的窗口是终端界面,不要理会…
在labelImg窗口的左边,有一些操作的功能,其中:“Open”是打开单个图像,“Open Dir” 打开文件夹,"Change Save Dir"
图像保存的路径,“Next Image” 切换到下一张图像,“Prev Image”切换到上一张图像,“Verify Image”校验图像,“Save”
保存图像,“Create RectBox”画标注框一个,“Duplicate RectBox”重复标注框,“Delete RectBox”删除标注框,“Zoom In”
放大图像,“Zoom Out” 缩小图像,“Fit Window”图像适用窗口,“Fit Width”图像适应宽度。
当然,使用操作按钮不是很方便,下面介绍一些快速的快捷键,为无聊的标注工作节省一些时间。
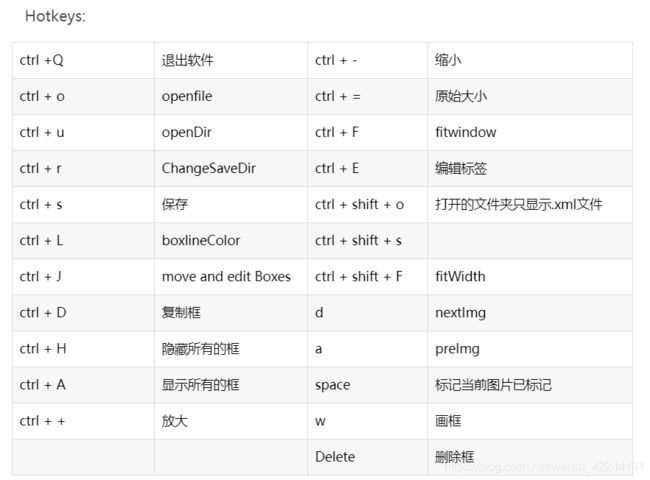
开始图像数据标注:
一般操作的顺序:“open file ” -----"create rectbox " -----"输入类别名称 "-----“change save dir ”-----"Save"


之后next image继续操作,标注得到数据集。

txt文件格式如下

1 标注得到的txt可以直接跟图片放一起,最总所有样本图片和txt文件放到:darknet-master\build\darknet\x64\data\obj
一张图对应一个txt

obj文件夹如果没有,自己建立
2 在darknet-master\build\darknet\x64\data\下新建train.txt
将你的训练图片的路径放入文件,每行一个路径,如下图:

这里生成txt可以使用各种方法,这里提供最简单的脚本方法
在图片所在文件夹(obj)新建一个getname.txt,写入下列代码后,改为getname.bat,双击运行得到train.txt ,复制到
darknet-master\build\darknet\x64\data\即可
@Echo Off
SetLocal EnableDelayedExpansion
For /R %%i In (*.jpg) Do (
Set /A
Echo %%~i>>SVM_DATA.txt
)
Pause>nul

无视背景框中的数字,没影响
3 .将darknet的预训练权重darknet53.conv.74放入
darknet-master\build\darknet\x64,下面是我的网盘链接,网盘里有:
链接:https://pan.baidu.com/s/1VrrvRpWHaGxQD03R3cAA6w
提取码:9729
4 在darknet-master\build\darknet\x64 新建yolo-obj.cfg文件(可以直接复制yolov3.cfg,然后重命名为yolo-obj.cfg)
Yolov3参数解释以及答疑 参考
https://blog.csdn.net/weixin_42244181/article/details/104824920
关键参数
batch=64 # 每个迭代训练的图片数,一个迭代更新一次参数
subdivisions=8 # 将一个迭代的图片分成subdivisions次进行训练,内存不足时可以适当调大
# 这里batch=64,subdivisions=8,则每个subdivision训练的图片数量为64/8=8
...
max_batches=4000 # 最大迭代次数,建议设置为(classes*2000), 比如识别两类物体,则设置为4000
# 如果训练效果不理想,也可以调大,通过测试集的mAP判断模型是否可用或是否过拟合
steps=3200,3600 # 迭代到steps对应的次数时,学习率衰减,衰减系数通过scales设定,
# 建议将steps设置为max_batches的80%和90%
修改这个文件内容:
batch 改成64 :batch=64
subdivisions 改成8 :subdivisions=8
如果你对显卡较差(4G显存以下),训练的时候如果出现内存溢出错误(Out of memory),可以将batch改小些(64,32,16,8),将random改成0关闭多尺度训练。
先考虑改batch,再random

查找每个yolo下(共有3处)的classes改成你自己的类的数量 :classes = N我的是1类 classes = 1
查找每个yolo上面第一个convolutional下的filters(如图)改成你自己的大小,计算方法是: filters=(classes + 5)x3 ,由于我的是1类,所以我的filters=18. (这个也是只有3处)
如图

(可选) 修改训练的最大迭代次数, max_batches = N,作者给出的是500200次,实际中难以实现,根据需要修改。本文因机器和样本问题只迭代不到2000次。

5 在darknet-master\build\darknet\x64\data\下新建obj.names文件,里面写入你的类名,每个类名占一行。

6 .在darknet-master\build\darknet\x64\data\下新建obj.data文件

把类别数改成你自己的数量。其他不变。
7 修改网络配置文件Makefile(在\darknet-master路径下)
下图只是举例,跟实际的不完全一样

我在实际中只修改了前面的几个参数,如图,后面的没修改,也没出问题,应该有自动链接。
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=0
AVX=0
OPENMP=0
LIBSO=0
# set GPU=1 and CUDNN=1 to speedup on GPU
# set CUDNN_HALF=1 to further speedup 3 x times (Mixed-precision using Tensor Cores) on GPU Tesla V100, Titan V, DGX-2
# set AVX=1 and OPENMP=1 to speedup on CPU (if error occurs then set AVX=0)
(如果全部修改后windows下最好用vs重新编译生成一下,直接用VS运行darknet.sln,进行编译下)
全部修改需要进行对照去网盘下载这个makefile
链接:https://pan.baidu.com/s/1NXYe9YxBysRH5b_OFgbwvg
提取码:4dt5
8 打开win10终端,cd进入darknet-master\build\darknet\x64路径,然后输入:darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 开始训练。

9.训练时,每训练100轮,都会生成一个权重文件在build\darknet\x64\backup\ 下,文件名例如:yolo-obj_100.weights(后面的100是训练100轮是的权重)。
中间终止训练,权重会保存在backup文件夹下。如果要从检查点停止并重新启动训练,自行百度
关于训练时打印的日志详解
Region 82 Avg IOU: 0.874546, Class: 0.983519, Obj: 0.984566, No Obj: 0.008776, .5R: 1.000000, .75R: 0.750000, count: 4
Region 94 Avg IOU: 0.686372, Class: 0.878314, Obj: 0.475262, No Obj: 0.000712, .5R: 1.000000, .75R: 0.200000, count: 5
Region 106 Avg IOU: 0.893751, Class: 0.762553, Obj: 0.388385, No Obj: 0.000089, .5R: 1.000000, .75R: 1.000000, count: 1
三个尺度上预测不同大小的框,82卷积层为最大预测尺度,使用较大的mask,可以预测出较小的物体,94卷积层 为中间预测尺度,使用中等的mask, 106卷积层为最小预测尺度,使用较小的mask,可以预测出较大的物体。
下面以其中一个为例:
Region 82 Avg IOU: 0.874546, Class: 0.983519, Obj: 0.984566, No Obj: 0.008776, .5R: 1.000000, .75R: 0.750000, count: 4
详解:
Region Avg IOU: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比。
Class: 标注物体分类的正确率,期望该值趋近于1。
Obj: 越接近1越好。
No Obj: 期望该值越来越小,但不为零。
count: count后的值是所有的当前subdivision图片中包含正样本的图片的数量。
每过一个批次会返回一个输出:
1: 806.396851, 806.396851 avg, 0.000000 rate, 1.457291 seconds, 64 images
1: 指示当前训练的迭代次数
806.396851:是总体的Loss(损失)
806.396851 avg:是平均Loss,这个数值应该越低越好,一般到0.几的时候就可直接退出训练。
0.000000 rate:代表当前的学习率,是在.cfg文件中定义的。
1.843955 seconds:表示当前批次训练花费的总时间。
64 images:这一行最后的这个数值是1*64的大小,表示到目前为止,参与训练的图片的总量。
10.测试训练效果:
将那个backup文件下最后一个权重文件复制到build\darknet\x64\文件下,打开win10终端,cd进入然后运行darknet-master\build\darknet\x64路径,然后输入:darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_100.weights(最后的权重改为你自己的权重)。终端会提醒你输入图片路径,然后你输入测试图片的绝对路径即可看到效果。
我这里直接使用opencv3.4.2+vs2015加载实现
参考另外一篇博客 https://blog.csdn.net/weixin_42244181/article/details/104647579


实现检测,训练成功
xml转txt升级版代码:https://github.com/jiang-congcong/xml-to-txt-update/blob/master/xml-to-txt-update.py
常见错误解决办法:https://github.com/AlexeyAB/darknet/issues/