ELK7.X搭建(一)Elastic Search安装与配置
前提条件,7.x版本的es需要jdk11
官网下载过慢,可以去华为的镜像下载
wget https://mirrors.huaweicloud.com/elasticsearch/7.5.1/elasticsearch-7.5.1-linux-x86_64.tar.gz
1. 解压并移动到指定的目录
tar xf elasticsearch-7.5.1-linux-x86_64.tar.gz
mv elasticsearch /usr/local2. 修改配置文件
cd /usr/local/elasticsearch/config
sudo vi elasticsearch.yml添加如下的配置信息,注意第五项是初始化节点的node name
network.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.initial_master_nodes: ["node-1"]3. 启动elastic search服务,默认不允许root用户启动,新增用户
useradd elk
chown -R elk. /usr/local/elasticsearch
su elk
sh /usr/local/elasticsearch/bin/elasticsearch -d此时会报错,max_map_count数量65530太小
elastic vm.max_map_count [65530] is too low, increase to at least [262144]
修改系统配置文件,sudo vi /etc/sysctl.conf,添加
vm.max_map_count=655360
生效配置
sysctl -p
再次启动es,成功!

默认的es中没有安装中文分词器,可手安装中文分词插件IK,参考文章https://www.jianshu.com/p/1fbfde2aefa5
ik插件地址: https://github.com/medcl/elasticsearch-analysis-ik
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.5.1/elasticsearch-analysis-ik-7.5.1.zip在到es的plugins路径下新建ik,解压完成后重启es
cd /usr/local/elasticsearch/plugins/ik
sudo unzip elasticsearch-analysis-ik-7.5.1.zip验证
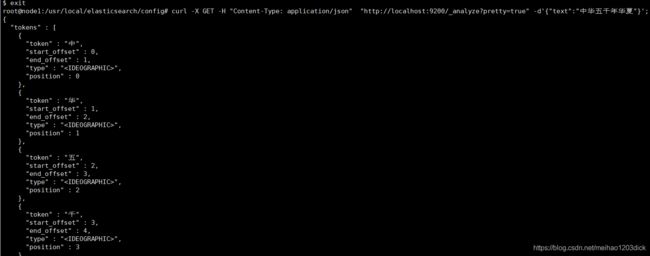
curl -X GET -H "Content-Type: application/json" "http://localhost:9200/_analyze?pretty=true" -d'{"text":"中华五千年华夏"}';