python write 写多行_用Python来解析文本
本篇主要介绍一下如何读写plain text文件,简单理解就是纯文本文件,经过字符编码形成的文档,用一些文本编辑器如UE、记事本可以打开的文件。区别于一些有特定结构的文件,比如word文档、Excel文件、图片文件等等,他们必须借助专门的软件才能打开,没有任何可读性的二进制编码文件。
大家日常其实非常多的时间是与文本打交道的,比如设备配置、各类日志。一般是用一些ue全局搜索,有时候这些工作特别枯燥、重复,我们今天就来讲讲如何用python来处理文本文件,结合函数和字符串的一些操作。可以普适到系统运维工作,或者其他工作领域。
免责声明:针对初学者,本文很多内容都以简单直接可能不太正确的方式表达,各位如果在后续的学习中会发现其中的问题,请不要喷我。
初学者,最重要的是能够获取想要的结果,有继续学习的动力。
函数
开始之前先介绍一下python的函数定义,补充点知识,我们在写程序的时候可以把一些重复使用的代码抽象到一个函数中去,想想我们学数学的函数f(x,y)= |x-y|,计算两个数的差值,f其实就是function的缩写,当然我们也可以把这个函数命名为func,它只是一个代号,但是在一个文件中不要重复。我们在使用函数的时候,按函数的定义放入参数,比如令x=1,y=2 ,这个时候1,2是传入的实际值,而x,y是参数名字。
python的函数其实也类似,只不过,这个数学的函数比较简单是一行数学公式,我们实际的函数可能是非常多行的代码。
python中函数的定义,参数的定义
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和“冒号:“,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
def ssh_dev_exc(dev_ip, port,command,username='user',password='password'): print('正在登录{}设备'.format(dev_ip)) # do something ,ssh device output = 'version is XXXX '```` return '登录成功',output如上,有默认值的函数放到后面,无默认值的函数放到前面。函数内的逻辑块最后返回计算结果。其实可以不return,相当于return None。这个时候看你如何设计函数了,其实我们建议,把结果返回,比如我们处理文本,就返回结果,最好是格式化数据。上面例子返回的是一个tuple。
dev_ip, port,username,password是此函数的参数,其中username='admin',password='admin123' 定义了默认参数,后续调用时可以不写这两个参数,函数会自动补上。默认参数一定要在一堆参数的最后。参数可以为空,即函数可以没有参数。
return 可以不写,默认是返回None;可以返回多个参数,本质是返回了一个tuple
调用函数
像数学公式一样,函数名后面跟括号,传入参数的实际值。
前提是他们在一个python文件中,如果调用其他的,需要通过import 引入,import引入方式多种多样,一会会简单演示。
ssh_dev_exc('127.0.0.1',22,'show version')这个例子会依次赋值dev_ip、port、command三个参数,后面的会用默认值。
我们也可以这样使用
ssh_dev_exc(dev_ip='127.0.0.1',port=22,commnad='show version')指向性更明确,初学者可以多写点,用这种方式,后续熟练后可以上面的方式。
还可以这样
ssh_dev_exc('127.0.0.1',22,'show version',usernmae='root')其实参数的传入很多技巧,后续分享。
文件操作
读写文件是最常见的IO操作。Python内置了读写文件的函数,用法和C是兼容的。
读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
读
>>> f = open('/Users/michael/test.txt', 'r',encoding='utf8')
标示符'r'表示读,这样,我们就成功地打开了一个文件。
第一个参数是文件的路径及名称。windows中涉及到‘\’是转义,简单粗暴一点,你就把文件和代码放一起。
windows中这样写路径,加r在字符串前面,或者两个\\代表一个实际的\

r代表读取的是文本文件(plain text)。
rb代表用二进制方式打开,读取的就都是字节了,或者你简单理解就是乱码。
encoding 代表的是编码格式,它会用这个将字节读取成字符。前者你可以继续理解成乱码(当然这个说法不严谨,为初学者方便理解准备的)
按照文本的实际格式去设置。
默认值会根据系统去定,所以建议显示的赋值。不要让程序代你去赋值。
如果是新手,强烈建议,文本保存成utf8格式,encoding也是utf8
如果文件不存在,open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在:
>>> f=open('/Users/michael/notfound.txt', 'r',encoding='utf8')Traceback (most recent call last): File "", line 1, in FileNotFoundError: [Errno 2] No such file or directory: '/Users/michael/notfound.txt'如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示:
>>> f.read()'Hello, world!'最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
>>> f.close()由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
try: f = open('/path/to/file', 'r',encoding='utf8') print(f.read())finally: if f: f.close()但是每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r',encoding='utf8') as f print(f.read())这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
读取大文件
比较pythonic的方法是:
with open(filename, 'r',encoding='utf8') as flie: for line in file: print(line)以上代码会逐行去读取文本内容,不会出现内存泄露的情况。
或者使用以下代码也可以,readline会逐行读取,不会一次加载。
while True: line = f.readline() if not line: break以下方法针对小文件的时候可以,但是文件比较大的时候会有内存泄露的风险,因为readlines是一次读取所有的行,放到一个list中返回。
for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉写入文件
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
>>> f = open('/Users/michael/test.txt', 'w',encoding='utf8')>>> f.write('Hello, world!')>>> f.close()你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w',encoding='utf8') as f: f.write('Hello, world!')要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码。
file-like Object
像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行。
StringIO就是在内存中创建的file-like Object,常用作临时缓冲。
二进制文件
前面讲的默认都是读取文本文件,并且是UTF-8编码的文本文件。要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件即可:
这个时候不要用encoding了,因为是它已经不是字符了,刚才的编解码是针对字符的。
这块大家看看就好。
>>> f = open('/Users/michael/test.jpg', 'rb')>>> f.read()b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节字符编码
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')>>> f.read()'测试'遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')小结
在Python中,文件读写是通过open()函数打开的文件对象完成的。使用with语句操作文件IO是个好习惯。
实战演示如何读取一段端口并用字符串解析出来
先把文件和脚本放在一起。然后打开文件,encoding指定这个文件的编码格式。
我的是用utf8编码的。虽然有默认参数,但是我们最好全部都统一用utf8读、写。
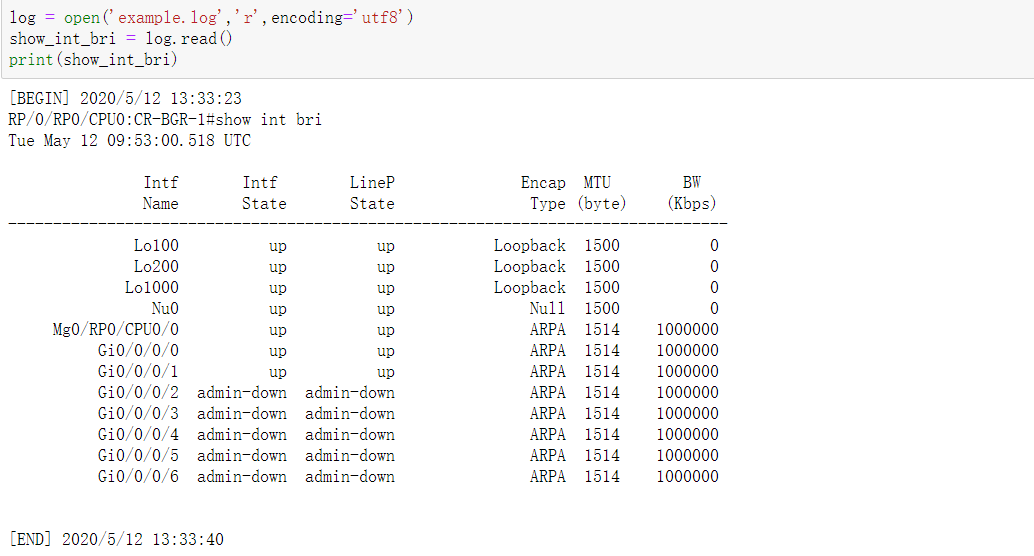
我们逐行读取后,解析端口的一些信息。
def get_intf(line): # 注意这行,下划线 _ 也可以是变量 # 这是一个语法糖,可以快速赋值,前提是左边和右边的数量一致。 # name,*others,bw = line.split() 如果数量不定,可以把不确定的用这种方式,others里就是可变长的数组 # 上面这句是超纲的。 name,intf_state,line_state,_,mtu,bw = line.split() # 强加一段逻辑 find其实非常常用,返回的是匹配的字符串第一次出现的索引值(计算机世界,从0开始数数) # 我们可以结合find后的下标进一步去做一些字符串的截取。这里不演示。 if name.find('Gi')>=0: type = 'gi' elif name.find('Mg')>=0: type ='mg' else: type = 'other' intf_data = {
'name':name, 'intf_state':intf_state, 'mtu':mtu, 'bw':bw, 'type':type } return intf_datadef get_intfs(filename): intfs = [] intf_start_flag = False with open(filename,'r',encoding='utf8') as log_file: lines = log_file.readlines() for line in lines: # 找到---代表下一行是端口信息,我们可以进行解析,但是---这行需要跳过,我们用continue if line.startswith('---'): intf_start_flag = True continue # 我们读到[END]的时候代表可以结束解析,直接跳出循环 if line.startswith('[END]'): break # 如果 if intf_start_flag: # 这行内容不为空我们才解析,否则不执行任何操作 # 我们计算字符串长度来判断有没有内容,简单粗暴 if len(line)>10: intf = get_intf(line) intfs.append(intf) return intfs# 调用函数,可以复用,每次调用只穿文件名即可。intfs = get_intfs('example.log')print(intfs)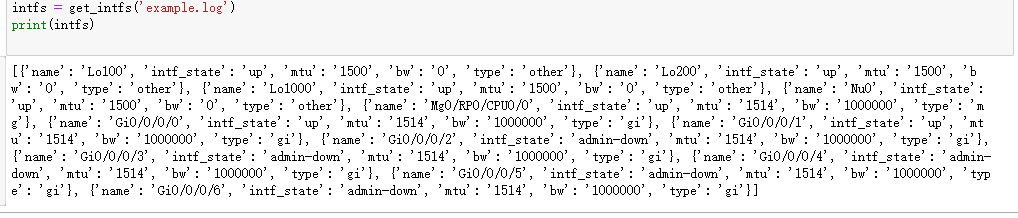
我们一般是从文本读取配置,解析出来后写入表格,下一节我们讲讲如何把这个列表写入Excel表格中去。
这段演示的代码比较简单,有些地方写的比较啰嗦,是希望分享一个初学者易于接受的方式。
这段代码中也传达了,我们尽量拆分自己的函数,可以复用,调试也会方便。什么项目都是由成千上万个几十行的函数组成的,写几百行的函数其实很少见。分而治之,大问题拆解后一个个解决。
其实对于解析文本有很多更好的方法(正则表达式以及TextFSM),我们后续会继续分享,欢迎大家关注!