【python】TXT文本拆分和合并实例
TXT文本拆分和合并
- 目的
- 代码实现:(1)拆分
- 代码实现:(2)处理
目的
有一批断层数据,大概长这个样子:
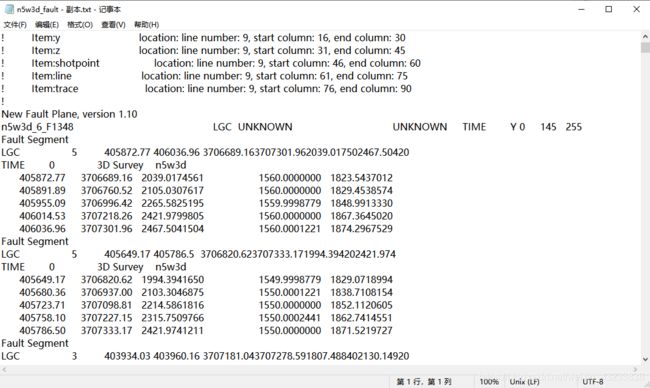
前面有很多表头,后面的数据排列很规则,每一个“n5w3d_6F”都是一条断层的名字,每个断层又分为很多歌segment,数据一共有数万行,现在需要对这些数据进行处理,要讲每一个断层单独命名并保存,删掉后两列,在每个segment的每行数据后面添加数据位置(断层起始点记为1、中间点记为2、终止点记为3)和断层名字(每个segment单独排序)。
代码实现:(1)拆分
先对断层数据拆分,以“n5w3d_6F”为关键词检索并切割。
# -*- coding: utf-8 -*-
# Author: Wuy
# Python 3.6
# 主要实现目的:
# 拆分地层数据,以关键词“n5w3d_6_F”切分txt文件,并将每一个分段单独保存为以特定名字命名的txt文本中
# 第一个关键词之前的内容不用保存
target_dir = 'Y:/断层拆分/'
key = 'n5w3d_6_F'
def Fun():
line_num = 0
output_num = 0
key_line_list = []
get_key_list = []
f = open('Y:/n5w3d_fault - 副本.txt','r')
data = f.readlines()
f.close()
find_list = []
for eachline in data:
if key in eachline:
key_line_list.append(line_num)
text = eachline[eachline.rfind(key):15]
get_key_list.append(text)
print('第%s行:%s' % (line_num + 1,text))
find_list.append('第%s行:%s' % (line_num + 1,text))
n = len(key_line_list)
if n >= 2:
output_num += 1
output_lines = data[key_line_list[n-2]:key_line_list[n-1]]
output_path = target_dir + get_key_list[n-2] + '-' + str(output_num) + '.txt'
with open(output_path,'w') as v:
for line in output_lines:
v.write(line)
print('---------------------------------------------')
print('保存文件:%s' % (get_key_list[n-2] + '-' + str(output_num) + '.txt'))
print('---------------------------------------------')
line_num += 1
output_num += 1
output_lines = data[key_line_list[n-1]:]
output_path = target_dir + get_key_list[n-1] + '-' + str(output_num) + '.txt'
with open(output_path,'w') as v:
for line in output_lines:
v.write(line)
print('---------------------------------------------')
print('保存文件:%s' % (get_key_list[n-1] + '-' + str(output_num) + '.txt'))
print('---------------------------------------------')
with open('Y:/关键词出现行数.txt','w') as v:
for line in find_list:
v.write(line + '\n')
# 记录关键词出现行数,仅用于后期检验数据
print('---------------------------------------------')
print('保存文件:%s' % (target_dir + '关键词出现行数.txt'))
print('---------------------------------------------')
if __name__ == "__main__":
Fun()
代码实现:(2)处理
上一步,将每个断层单独保存为txt文件之后,需要分别对数据做删除和添加数据的处理。
思路是,先对每个segment进行拆分,处理完毕在合并输出,遍历文件夹中所有断层的txt文件。
# -*- coding: utf-8 -*-
# Author: Wuy
# Python 3.6
# 实现目标:
# 对每一个提前拆分好的文档进行处理,每一个文档代表一个断层数据
# 保留每个断层数据的前三列,删除不是数据的表头内容
# 对每个fault segment添加开始点(1)、中间点(2)和终止点(3)标记,对每个segment单独命名,规则断层名+序号
import os
from datetime import datetime
file_dir = 'Y:/断层拆分/'
output_dir = 'Y:/已处理/'
key = 'Fault Segment'
def split_file(file_path):
print('拆分开始')
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
f = open(file_path,'r')
lines = f.readlines()
f.close()
fault_name = lines[0].split(' ')[0] # 获取断层名字
key_line_list = [] # 用于记录检索到关键词的行号
output_list = [] # 用于记录拆分好的数据段
line_num = 0 # 用于记录行号
segment_num = 0 # 记录数据段数目
n = 0
for eachline in lines:
if key in eachline:
key_line_list.append(line_num)
n = len(key_line_list) # n为检索到关键词的数目
if n >= 2:
k3 = [] # 用于记录每一个数据段
# segment_num += 1
# 获取最后两个关键词之间的内容,k1实际为list(),每个元素每行数据,格式为str()
k1 = lines[key_line_list[n-2] + 3:key_line_list[n-1]]
# +3是因为包括关键词所在行还有三行表头
for each_line in k1:
k2 = each_line[:48] # 保留前三列数据,48之后的字符删去
k3.append(k2)
output_list.append(k3)
line_num += 1
# 还有最后一部分数据需要提取
if n >= 1:
segment_num += 1
k3 = []
k1 = lines[key_line_list[n-1] + 3:-1] # -1是因为需要删除最后一行
for each_line in k1:
k2 = each_line[:48] # 保留前三列数据,48之后的字符删去
k3.append(k2)
output_list.append(k3)
# output为一个文件中所有fault segment的数据集合
# 为K3里每一行添加1/2/3标注和断层名字标注,尤其注意需要添加\n(回车)
for each_segment in output_list:
if len(each_segment) >= 3:
for i in range(len(each_segment)):
if i == 0:
each_segment[0] = each_segment[0] + ' 1' + ' ' + fault_name + '-' + str(output_list.index(each_segment) + 1) + '\n'
elif i == len(each_segment) - 1:
each_segment[-1] = each_segment[-1] + ' 3' + ' ' + fault_name + '-' + str(output_list.index(each_segment) + 1) + '\n'
if i in range(1, len(each_segment) - 1):
each_segment[i] = each_segment[i] + ' 2' + ' ' + fault_name + '-' + str(output_list.index(each_segment) + 1) + '\n'
elif len(each_segment) == 2:
each_segment[0] = each_segment[0] + ' 1' + ' ' + fault_name + '-' + str(output_list.index(each_segment) + 1) + '\n'
each_segment[-1] = each_segment[-1] + ' 3' + ' ' + fault_name + '-' + str(output_list.index(each_segment) + 1) + '\n'
else:
print('%s断层出错,数据行数小于2' % (fault_name))
# 写入文本
save_path = output_dir + fault_name +'.dat'
with open(save_path,'w') as v:
for each_list in output_list:
for each_line in each_list:
if output_list.index(each_list) == len(output_list) - 1 and each_list.index(each_line) == len(each_list) - 1:
v.write(each_line.split('\n')[0])
else:
v.write(each_line)
print('---------------------------------------------')
print('保存文件:%s' % (fault_name + '.dat'))
print('---------------------------------------------')
print('完成:%s' % (fault_name))
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
def all_files_path(rootDir):
filepaths = []
for root, dirs, files in os.walk(rootDir): # 分别代表根目录、文件夹、文件
for file in files: # 遍历文件
file_path = os.path.join(root, file) # 获取文件绝对路径
filepaths.append(file_path) # 将文件路径添加进列表
return filepaths
if __name__ == "__main__":
filepaths_list = all_files_path(file_dir)
for each_path in filepaths_list:
split_file(each_path)
注意,代码中的文件路径是否正确。