【深度学习前沿】一文回顾深度学习十年发展
关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!

转自 | 大数据文摘出品
来源 | leogao.dev
随着21世纪第二个十年行将结束,我们有必要回顾一下这十年来在深度学习领域所取得的巨大进步。在性能日益强大的计算机及大数据可用性的推动下,深度学习已经成功攻克了曾经棘手的难题,特别是在计算机视觉和自然语言处理方面。深度学习在我们的日常生活中已无处不在,从自动驾驶到医学影像分析,从虚拟助理到深度伪装。
这篇文章概述了过去十年来最有影响力的一些论文。我希望通过简洁明了的摘要来提供深度学习领域不同方向的起点,并且提供了相当多的参考资料。
考虑到这项研究的性质,可以说是一千个人心中有一千个哈姆雷特。最有影响力的论文通常既不是第一篇论文也不是最好的那篇论文。我努力在它们之间找到平衡,并将最有影响力的论文作为主要条目,而将相关论文作为荣誉奖予以列出。当然,鉴于主观性的存在,这份列表并不是什么权威榜单云云。如果你觉得这份榜单有所遗漏,顺序或描述存在错误,请告诉我一声,以便加以改进,让这份榜单更加完整准确。
2010
理解深度前馈神经网络训练的难点(7446次引用)
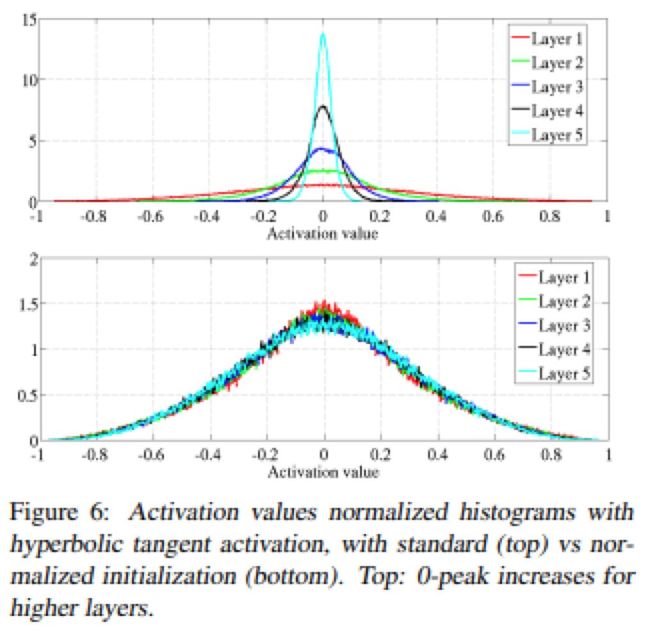
Xavier初始化后的激活(上)和不进行初始化的激活(下)
本文探讨了深度网络的一些问题,特别是权值的初始随机化。本文还注意到了S型曲线和双曲正切激活问题,并提出了替代方案SoftSign,它是一种具有更加平滑的渐近线的S型激活函数。但是,本文最主要的贡献在于初始化。当使用正态分布的权重进行初始化时,数值很可能会急剧增大或者减小,从而无法进行训练。假设前一层的值是正态分布的独立同分布,则将它们相加会增大其方差,因此应按输入数量成比例地缩小方差,以保持输出值服从标准正态分布。将这个逻辑反过来(即按输出数量进行处理)则可以处理梯度的问题。本文介绍的Xavier初始化是两者之间的折衷,是利用方差为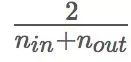 的正态分布初始化权重,
的正态分布初始化权重,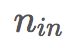 和
和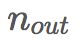 分别是前一层神经元和后一层神经元的数量。2015年的一篇论文《深入研究整流函数:在ImageNet分类上超越人类水平》介绍了Kaiming初始化,它是在Xavier初始化的基础上考虑了ReLU激活函数的一个改进版本。
分别是前一层神经元和后一层神经元的数量。2015年的一篇论文《深入研究整流函数:在ImageNet分类上超越人类水平》介绍了Kaiming初始化,它是在Xavier初始化的基础上考虑了ReLU激活函数的一个改进版本。
2011
深度稀疏整流神经网络 (4071 次引用)
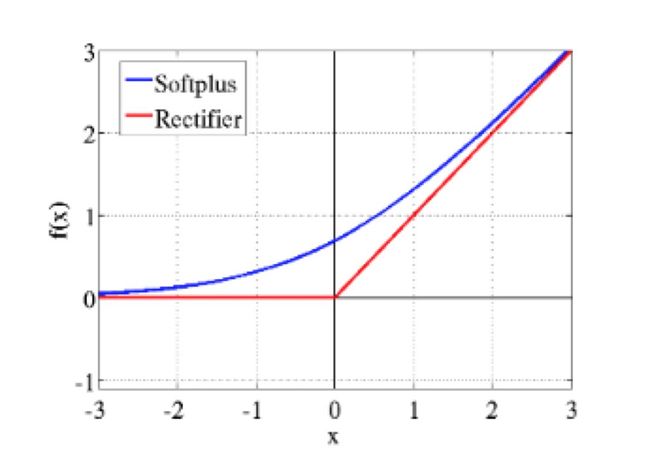
从最早的MLP到2015年左右的许多神经网络都是用S型函数作为激活函数。S型函数具有处处可微和输出有界的特点,常用的有Logistic函数和双曲正切函数。而且它与神经生物学中的全或无定律相吻合。(注:全或无定律是神经传导的一项基本特性。即当刺激达到神经元的反应阈限时,它便以最大的脉冲振幅加以反应,但刺激强度达不到某种阈限时,神经元便不发生反应。详情参考https://en.wikipedia.org/wiki/All-or-none_law)然而,由于S型函数的导数从零开始迅速衰减,因此随着神经网络层数的增加,梯度通常会迅速减小。这就是我们常说的梯度消失问题,这也正是当时神经网络难以深度扩展的原因之一。该论文提出,使用ReLU激活函数来解决梯度消失问题,从而为神经网络的深度发展奠定了基础。(注:ReLU,Rectified Linear Unit,一种常用的激活函数,称为线性整流函数或修正线性单元)
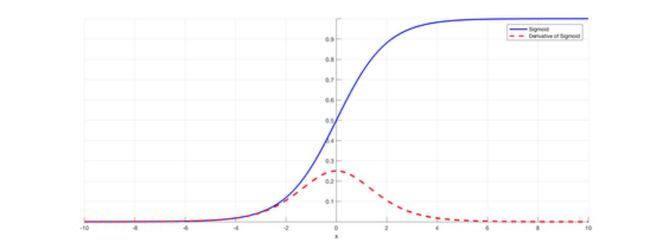
S型函数及其导数
尽管如此,ReLU函数还是存在一些缺陷:它们在0处不可微,它们能够无限增长,并且当一半节点激活并饱和后,剩下的节点就成了“死亡”节点。2011年以来,人们提出了许多改进方法来解决这个问题,但其功效大多不如vanilla ReLUs。
《Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit》(2000)一文被普遍认为是建立ReLU的生物学合理性的第一篇论文,而《What is the Best Multi-Stage Architecture for Object Recognition?》一文则是我能找到的将ReLU函数(在本文中其被称为积极部分)用于神经网络的最早的论文。
著名文章对其的引用:
整流非线性改进神经网络声学模型:该论文介绍了带泄露线性整流函数(Leaky ReLU),由于在负半部分上存在较小的梯度“泄露”,因此其输出不为零。这也防止了ReLU激活函数中部分神经元死亡现象的出现。然而,Leaky ReLU在0处的导数是不连续的。
指数线性单元快速准确的深度网络学习:指数线性单元(ELUs,Exponential Linear Units)和 Leaky ReLU相似,但在负侧更平滑且饱和值为-1。
Self-Normalizing神经网络:自归一化神经网络(SELUs,Self-Normalizing Neural Networks)旨在缩放ELU来创建固定点,并将其分布修改为标准正态分布,从而解决数据批量归一化的需求。
高斯误差线性单位:高斯误差线性单元(GELU,Gaussian Error Linear Units (GELUs):)作为一种常用的激活函数,其激活是基于高斯分布及对应的随机正则器dropout。具体来说,一个特定的值被保留的概率是标准正态分布的累积分布函数
 。因此,这个变量的期望值在随机正则化后就变成了。GELU在许多SOTA模型中有所应用,如BERT和GPT/GPT2。
。因此,这个变量的期望值在随机正则化后就变成了。GELU在许多SOTA模型中有所应用,如BERT和GPT/GPT2。
2012
深度卷积神经网络的ImageNet分类(52025次引用)
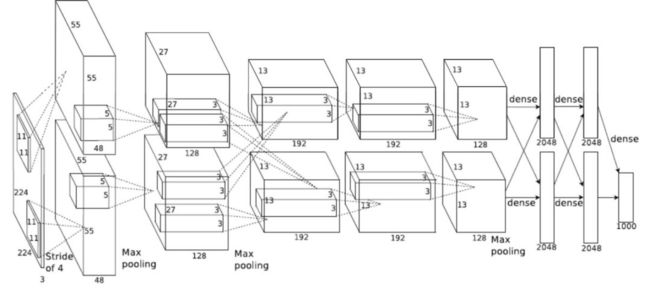
AlexNet 结构
AlexNet是一个使用ReLU激活函数,包含6千万参数的卷积神经网络。其最主要的贡献在于展示了深层网络的强大性能,因为就其本质而言,它的架构是过去的神经网络的更深版本。
这篇论文通常被认为是深度学习的发端。AlexNet也最早地利用GPU的大规模并行处理能力来训练比以前更深的神经网络。结果是惊人的,它将ImageNet的识别错误率从26.2%降到了15.3%,在2012年的ILSVRC脱颖而出。其强大的性能也使得深度学习受到广泛关注,同时该论文也成为深度学习领域被引量最高的存在。
著名文章对其的引用:

ImageNet层次结构中的图像示例
ImageNet:一个大型的分级图像数据库 :ImageNet数据集也为深度学习的兴起做了相当大的贡献。它也是深度学习领域被引量最高的论文之一,有着大约15050次引用(因为它于2009年发表,所以我决定将它列为荣誉奖)。该数据集是使用Amazon Mechanical Turk将分类任务外包给工人来构建的,这也使得这个天文级别的数据集成为可能。ImageNet大型视觉识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge)是以ImageNet数据库为对象的图像分类算法竞赛,同时它也推动了计算机视觉领域其他许多创新的发展。
灵活、高性能的卷积神经网络用于图像分类 :这篇论文早于AlexNet发表并与AlexNet有着许多共同点:这两篇论文都利用GPU加速训练神经网络,都利用ReLU激活函数来解决梯度消失问题。一些人认为这篇文章被冷落是很不公正的,它的被引量远少于AlexNet。
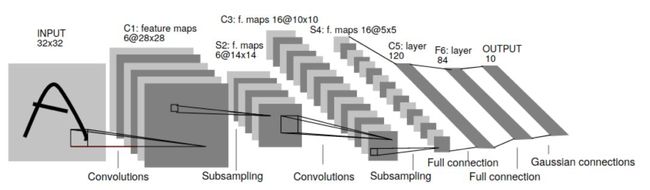
LeNet 结构
梯度学习在文档识别中的应用:发表于1998年,有着23110被引量,是将卷积神经网络用于图像识别的先驱。事实上,当下的卷积神经网络几乎完全是该早期工作的放大版。甚至于更早的论文,如LeCun在1989年发表的《Backpropagation Applied to Handwritten Zip Codes》可以说是第一例梯度下降的卷积神经网络。
2013
单词和短语的分布式表示及其组合性(16923次引用)
本文(以及同一作者之前的论文《Efficient Estimation of Word Representations in Vector Space》)介绍了word2vec,现在它已然成为深度学习的NLP模型中文本编码的主要方法。它基于出现在相似上下文中的单词可能具有相似的含义这一思想,而将单词嵌入向量中,从而应用于其他模型。Word2vec训练了这样一个网络,可以用来预测一个给定单词的上下文,然后提取出网络中潜在的向量。
著名文章对其的引用:
GloVe: 单词表示的全局向量 :GloVe的核心思想与word2vec相同,是其改进版本,但是实现方式略有不同。关于这两个模型哪一个更好,人们至今没有定论。
利用深度强化学习玩Atari(3251次引用)

DeepMind的Atari DQN的研究结果开启了深度强化学习领域的大门。强化学习之前常用在诸如网格世界之类的低维环境,很难在复杂环境中有所应用。Atari是强化学习在高纬度环境下的第一例成功应用,这使得强化学习从籍籍无名而转身称为AI领域的香饽饽。
本文特别使用了深度Q学习,这是一种基于价值的强化学习方式。基于价值就是说目标是通过遵循由Q值函数隐式定义的策略来了解在每种状态下获得的奖励的期望值。本文所使用的策略是 —它根据Q函数及概率的估计结果而采取最贪婪(即得分最高)的行动。这样也是为了探索整个状态空间。训练Q值函数的目标是从贝尔曼方程(Bellman equation)推导出来的,它将Q值分解为当前奖励值与加权后的下一期的最大Q值之和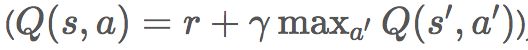 ,从而可以实现参数的自更新。这种基于当前值和未来价值函数之和来更新价值函数的方式通常被称为时差学习(Temporal Difference Learning)。
,从而可以实现参数的自更新。这种基于当前值和未来价值函数之和来更新价值函数的方式通常被称为时差学习(Temporal Difference Learning)。
著名文章对其的引用:
Learning from Delayed Rewards:Christopher Watkins发表于1989年的博士毕业论文介绍了Q学习。
2014
生成对抗网络(被引用13917次)

因其绝妙的可视化功能,生成对抗网络怎么称其成功也不为过。依托于生成器(Generator)和鉴别器(Discriminator)之间的极大极小博弈,GANs能够对复杂、多维度分布进行建模,其对象通常是图片。生成器的目标就是最小化鉴别器正确甄别错误样本的对数概率,也即log(1 - D(G(\bold)))log(1−D(G(z))) ;而鉴别器的目标则是最大化对于正确和错误样本的分类误差,也即log D(x) + log(1 - D(G(\bold)))logD(x)+log(1−D(G(z))) 。
“极大极小博弈中对生成器的投入对于理论研究十分有益,但在实际操作中用处不大——Goodfellow, 2016”
实际应用中,生成器常被训练用作最大化鉴别器判别出错的对数概率,即D(G(\bold))D(G(z)) , (相关阅读:NIPS2016指南:生成对抗网络,章节3.2.3)。这一小小的改变减小了梯度饱和(gradient saturating)且提高了模型训练的稳定性。
著名文章对其的引用:
Wassertein GAN及改进的Wassertein GAN:原版生成对抗网络(Vanilla GANs)存在种种问题,特别是训练的稳定性问题。即使经过轻微调整,原版GANs也常常训练失败,或者出现模式崩溃(也即,生成器生成只生成几张图片)的情况。调整梯度的Wassertein GAN提高了训练稳定性,因此也成为如今事实上默认使用GAN。原版GANs使用Jensen-Shannon距离法,导致分布之间因不正常的梯度饱和几乎不相交;WGAN与之不同,采用的是Earth Mover距离法。WGAN原稿论文通过限制权重的方式,强加了一个要求梯度小于任何一个常量的Lipschitz连续性限制,从而通过调整梯度的方式改善了一些存在的问题。

StyleGAN:StyleGAN能够生成令人惊叹的、几乎无法区分于真实图片的高清图片。生成如此高清图片的GANs之中所运用的最重要的技术就是渐进地增大图片大小,而StyleGAN内置了这项技术。StyleGAN还能修改不同大小规模的图片的隐空间,从而只对生成图片的特定细节进行操作。
通过联合学习对齐和翻译的神经机器翻译(被引用9882次)

这篇文章引入了attention的概念,即,我们可以不选择压缩信息进一个RNN的隐空间里,而是在内存中保留全部的内容,通过“\mathcal(nm)O(nm)”这一操作,使输出的所有要素处理输入的所有要素。即使attention要求递增二阶收敛,它依然比固定状态的RNNs表现更优秀,不仅在类似于翻译和语言建模的文本处理领域不可或缺,其身影也穿梭在与之相去甚远的GANs领域的模型中。
Adam:随机优化的一个方法(被引用34082次)
Adam因其易于微调在自适应优化中被广泛运用,它基于为每个参数适配单独的学习率的理念。虽然最新的一些文章对Adam的表现提出了质疑,但它依然是深度学习领域中最为流行的优化算法。
著名文章对其的引用:
无耦合权重衰减正则化:这篇文章声称发现了在通常实施中使用带权重衰减的Adam运用的一个错误,并提出替代方案AdamW优化来解决上述问题。
RMSProp:另一个流行的自适应优化方法(特别是RNNs领域,虽然这个方法与Adam相比究竟孰优孰劣还在争论中)。RMSProp因其可能是机器学习领域的课程ppt中被引用最多而“臭名昭著”。
2015
针对图像识别的深度残差学习(被引用34635次)
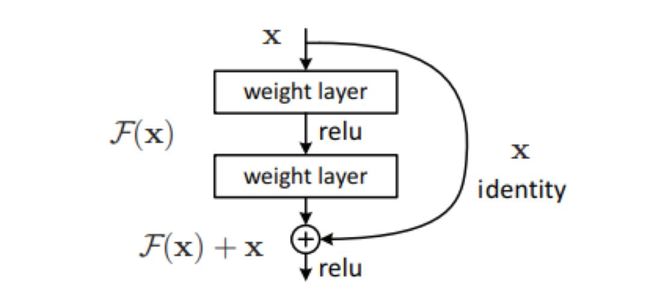
最初被设计为解决深度CNNs中的坡度消失/爆炸问题而产生的残差块(residual block),如今已成为几乎所有CNNs的构建基石。概念其实非常简单:在每个卷积层块前的输入加进输出中。残差网络的灵感源自于神经网络理论上不应以更多层来降维,因为最坏的情况下,多余的层会被粗暴地设为恒等映射(identity mapping)。然而实际操作中,更深度网络训练中常遇到各种困难;残差网络使各层更容易学习恒等映射,同时减少了梯度消失的问题。虽然方法十分简单,但从效果上看,特别是在更深度网络中,残差网络比常规CNNs出色得多。
著名文章对其的引用:
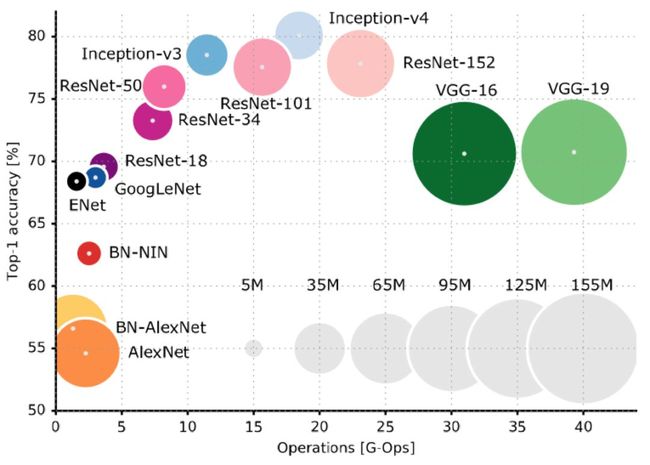
许多不同CNNs之间的对比
(其它许多更复杂得CNN基础理论文章也非常优秀,这里只列举了一小部分历史上重要的网络理论)
• 高速网络:残差网络是早期高速网络的一个特例。早期的高速网络通过一个类似但更复杂的封闭式设计,来在更深度网络中处理梯度。
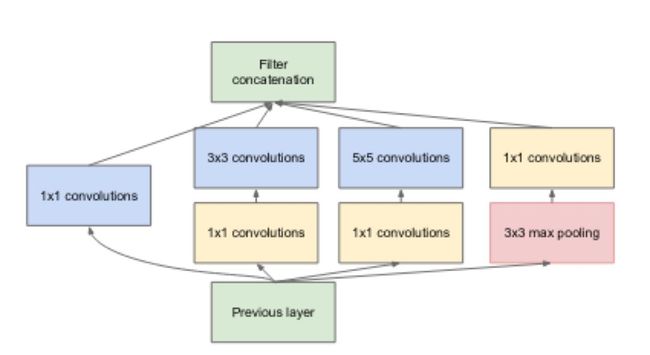
更深度的卷积:Inception模块理论源于把卷积化为因子来减少参数数量,以及减少激活次数。它能容下更深度的层嵌套,对这篇文章中提到的GoogleNet十分有益;文中的GoogleNet后来改名为SOTA网络(ILSVRC2014)。之后的许多再次介绍Inception模块的文章也相继发表了,Inception模块最终以Inception版本4嵌入于ResNets中,详情参考:Inception-ResNet及残差关系在机器学习上的影响。
针对大比例图像识别的超深度卷积网络:这是又一个在CNNs历史上非常重要的作品,这篇文章引入了VGG网络的概念。这篇文章的重大意义在于,它探索了只使用3*3卷积的可能性,而不是像其它大部分网络中更大的卷积,因而大幅降低了参数数量。
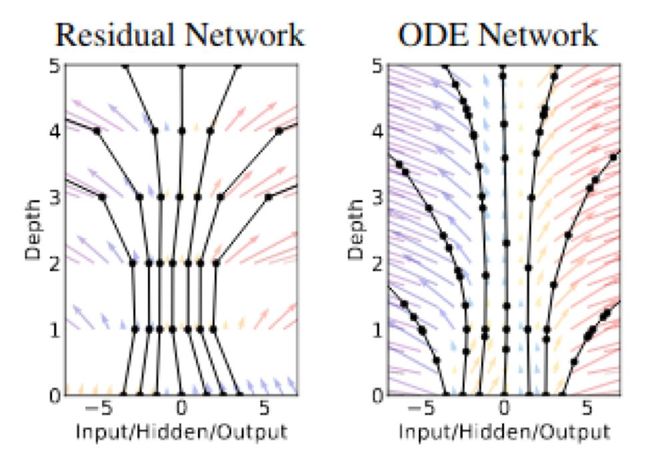
神经常微分方程:神经常微分方程这篇文章曾获2018年NIPS最佳论文奖,划分开了残差和微分方程。其核心观点就是讲残差网络视作连续转换的一个离散化,从而可定义残差网络为一个常微分方程的参数设定,也就可以用现成的求解器来求解。
Batch正则化:通过内部变量转化加速深度网络训练(被引用14384次)
Batch正则化是如今几乎所有神经网络的又一支柱。Batch正则基于另一个简单而强有效的概念:训练中保留均值和方差数据,运用它们将原分布正则化至均值为0和方差为1。Batch正则化有效的确切原因仍存疑,但它们在实操中的有效性却母庸置疑。
著名文章的引用:
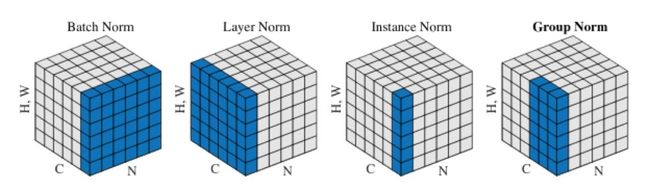
不同正则化手段的可视化
层正则化,实例正则化,以及群正则化:许多其它基于不同方法加总数据的可选方法如雨后春笋般出现,分别是同批处理,批处理和通道,或者批处理和多通道。这些技术在不希望同批处理和/或通道中的不同样本互相干扰的时候十分有效,关于这点最好的例子就是GANs中的应用。
2016
运用深度神经网络和树形搜索精通围棋(被引用6310次)
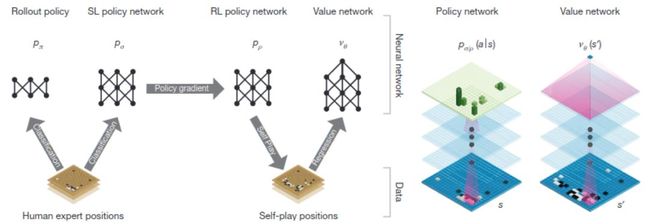
有监督学习和强化学习传递途径;策略/价值网络架构
在深蓝打败Kasparov后,AI社区向围棋届称霸进军。相对国际象棋,围棋有更广阔的游戏阵地,也更依赖于人类玩家的直觉。在AlphaGo之前类似于Crazy Stone和Zen等最优秀的围棋AI系统,基本都是带有许多手工探索引导树形搜索的蒙特卡洛树形搜索组合。从这些AI系统的进展来看,打败最优秀的围棋选手还需要很多年。虽说之前已有将深度学习应用于围棋的尝试,还没有哪个AI系统达到了AlphaGo的成就,而AlphaGo也用巨型算力集成了不少这些尝试中的技术成果。具体来说,AlphaGo包含一个策略网络和一个价值网络,分别可以缩小树形搜索,和对树形搜索舍项。这些网络最开始由标准有监督学习训练,之后再接受强化机器学习。
在以上列举的进展中,AlphaGo的AlphaGo对Lee Sedol比赛,大概对公众思想影响最为深刻,受众约由1亿人口,尤其是在围棋十分流行的中日韩三国。这场比赛和之后的AlphaGo Zero对战甚至对人类的围棋策略都产生了影响。举个例子,AlphaGo在第2场比赛37手下的棋非常反传统,惊异到了许多分析者。这一手后来成为AlphaGo战胜的至关重要的一步。
著名论文对其的引用:
不用人类经验而精通围棋:这篇介绍AlphaGo Zero的文章,移除了受监督学习过程,通过对战自己来训练策略和价值网络。虽然未受人类围棋策略的影响,AlphaGo Zero却能自己走出许多人类围棋手的策略,此外还能独创自己更优的围棋策略;这些策略甚至与传统围棋思路中的假定是相悖的。
2017
注意力机制即你所需(5059次引用)
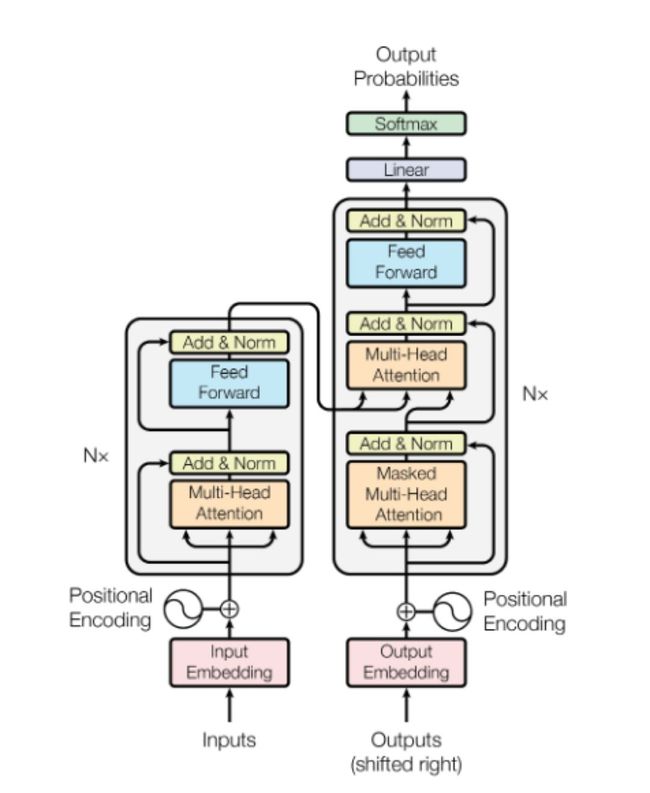
转换器架构是利用注意力机制的一个例证,已经发展成为几乎今天所有最先进的自然语言处理模型的基础。转换器模型击败RNNs,很大程度上是由于它在巨型网络中的计算优势。在RNNs中,梯度需要在整个“展开”的图形中传播, 这使得内存访问成为很大瓶颈。这也恶化了梯度消失/爆炸(exploding/vanishing gradients)问题,从而需要更复杂(计算成本更高)的LSTM和GRU模型。相反,转换器模型对高度平行处理进行了优化。计算成本最高的部分位于注意层(能平行使用)之后的前馈网络和注意层本身(巨大的矩阵乘法表,易于优化)。
使用增强学习的神经架构搜索(引用1186次)
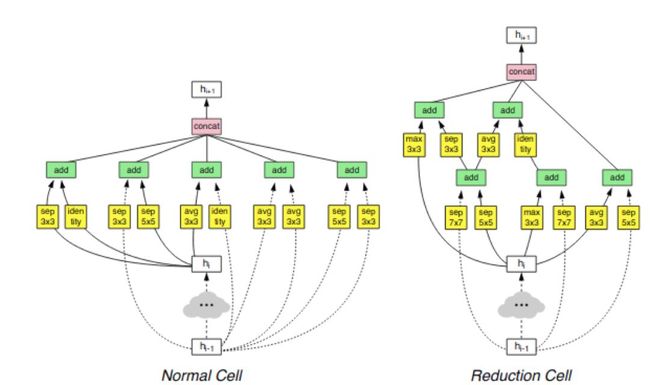
神经架构搜索(NAS)已成为网络性能压缩领域的普遍做法。NAS能实现架构设计自动化,而非令人痛苦的人工设计。在这篇论文中,利用RL训练一个控制器网络,从而生产性能网络架构,而这个架构能创建许多SOTA网络。相反,其他方法,例如Regularized Evolution for Image Classifier Architecture Search (AmoebaNet),使用了演化算法。
2018
BERT:语言理解的深度双向转换器的预训练
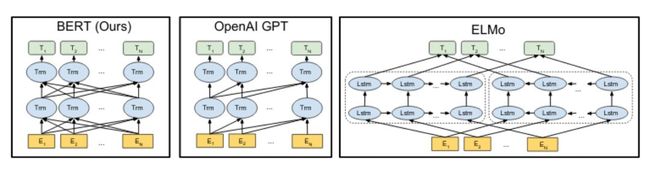
BERT与GPT、ELMo的比较
BERT是一种双向语境文本嵌入模型。与word2vec相似,它的基础是给每个单词(or, rather, sub-word token)赋予一个向量。但BERT里的这些向量是语境化的,能正确区别同形异义词。另外,BERT是深度双向的,每层中的每个潜在向量依赖于前一层中的所有潜在向量,这是与GPT(仅包含前向)和ELMo(包括了独立的前向和后向语言模型,两者到最后才结合)等早期工作不同之处。如在类似GPT的单向语言模型中,训练模型在每个时间步骤(time step)去预测下一个标记(token),这种模型行得通是因为每个时间步骤的状态仅依赖于上一个状态。(在ELMo中,前向和后向模型用这种方法独立训练,共同优化。)但在深度双向网络中,步骤tt 和层LL的状态S^L_tStL 必须依赖于所有 S^{L-1}_{t'}St′L−1的状态, 而这些状态中的任意一个反过来依赖于S^{L-2}_{t}StL−2的状态,从而使得网络能欺骗语言模型。为了解决这个问题,BERT运用重构任务去恢复隐藏标记(masked tokens),而网络看不到这些隐藏标记。
著名文章对其的引用:
自BERT发表以来,其他基于转换器的语言模型层出不穷。由于这些模型较为相似,我仅列举其中一些。当然,这个领域发展迅猛,无法做到全面;而且,很多论文还有待时间验证,哪些论文影响最大尚难定论。
深度语境化词语表征:即前文提到的ELMo论文。ELMo是不是首个语境文本嵌入模型(contextual text embedding model)存在争议,但在实践中BERT更为流行。
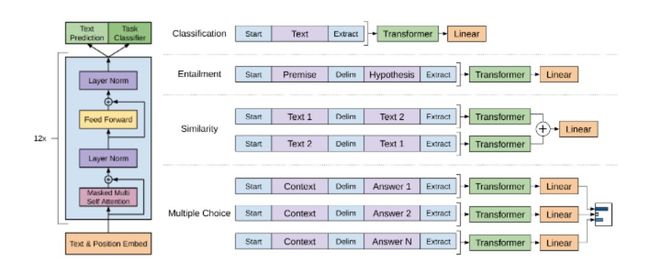
使用生成式预训练提高语言理解力:即前文OpenAI发表的GPT论文。这篇文章深入研究了在多个不同类型问题中,使用相同预训练参数(仅简单微调)在下游任务中进行训练的想法。考虑到从头训练现代语言模型的高昂代价,这个方法非常具有说服力。
语言模型是无监督多任务学习者:GPT2,OpenAI的GPT模型后继者,很大程度上是GPT的扩展版本。它具有更多参数(高达15亿个),更多训练数据,更好的跨国测试困惑度。它的跨数据集泛化水平令人印象深刻,为超大网络泛化能力提供了进一步证据。但是,它的声望来自于强大的文本生成能力。我对文本生成有更深入的讨论,希望它有趣。GPT2的发布策略招致了一些批评,据称该策略的设计目的是为了最大化炒作。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context:基于转换器的模型有固定的注意力长度,阻碍了对长文本语境的关注。通过关注来自于上一个注意力范围内的某些语境文本(为了计算可行没有传播梯度),来实现更长的有效注意力范围,Transformer-XL试图采用这种方式来解决这些问题。
XLNet:语言理解的广义自回归预训练方法:XLNet以多种方式解决了BERT面临的“欺骗”难题。XLNet是单向的,但是利用转换器对输入顺序的内在不变性,令牌能按任意顺序变换。这使得网络能有效地双向工作,同时保持单向性的计算优势。XLNet也集成了Transformer-XL思想。
具有子词单元的罕见词的神经机器翻译:更好的标记技术被认为是最近兴起的语言模型的核心内容。通过分段标记所有单词,这些技术消除了未登录词标记的可能性。
2019
深度双波谷:更大的模型和更多的数据伤害了谁
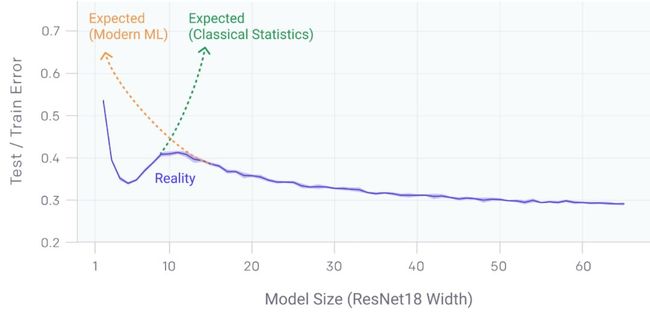
这篇文章所探讨的深度双波谷( (Deep) Double Descent)现象与经典机器学习和现代深度学习的流行观点背道而驰。在经典机器学习中,模型复杂性伴随着偏差-方差权衡。模型太弱,则不能充分捕捉数据结构,而模型太强,则会导致过拟合,涵盖了无法泛化的虚假模式。正因为如此,在经典机器学习中,随着模型变大,测试误差预期会下降,而一旦模型开始过拟合,那么测试误差又开始增加。实践中,在深度学习中,模型通常过度参数化,但看上去对较大模型的测试性能有所改进。这种冲突是隐藏在深度双波谷( (deep) double descent)背后的动机。深度双波谷扩展了Belkin 等人Double Descent论文, 通过实证证明了Double Descent对更广泛类型的深度学习模型的效果,以及它对模型大小、训练时间和数据集大小的适用性。
如果考虑了更多的函数类,这些函数类包含更多与数据适配的候选预测因子,我们可以发现具有更小范式因而也更简单的插值函数。因此,增加函数类容量将改进分类器的性能。
当模型容量接近于“插值阈值(interpolation threshold)”,即经典机器学习和深度学习的分界线,梯度下降法可能会发现接近于零误差的模型,很可能导致过拟合。但是,当模型容量进一步提高,可实现零训练误差的不同模型的数量增加,一些模型平滑拟合数据(也就是,不发生过拟合)的可能性增加。Double Descent假设,梯度下降法更可能发现这些更平滑的零训练误差网络,尽管这些网络过度参数化,但泛化性确很好。
彩票假说:发现稀疏可训练的神经网络
另一篇关于深度神经网络训练特征的论文就是彩票假说论文。彩票假说认为,网络性能大部分来自于某些幸运初始化的特定子网络(也就是说,“彩票”,特指这些子网络),而且更大的网络彩票发生的概率更高,因而性能也更好。这不仅允许我们剪除不相关的权重(文献中已很好地论证),而且还允许我们仅使用“彩票权重”重新训练,令人惊讶的是,这种方式结果与原始结果较为接近。
任何密集、随机初始化的神经网络都包含一个子网络。这个子网络能通过初始化,使得隔离训练时,该子网络在经过不多于原密集网络学习迭代次数的前提下达到与原网络相当的训练效果。
结论与未来展望
过去的十年由深度学习革命(梯度网络的复兴)的肇始而驱动,标志着人工智能历史上一个令人难以置信的快速发展和创新时期。很大程度上得益于可用算力的不断提高,神经网络规模变得越来越大,能力也越来越强,在全球范围内从计算机视觉到自然语言处理,全面代替了传统的人工智能技术。但神经网络也有缺点:他们需要海量数据进行训练、失败模式无法解释、无法实现超越个体任务的泛化。由于人工智能领域的巨大进步,深度学习在提高人工智能方面的局限性已经开始显现,人们的注意力开始转向对深度学习的更深入理解。在未来十年里,人们可能会越来越了解今天所观察到的神经网络的许多经验特征。就我个人而言,我对人工智能的前景持乐观态度;深度学习是人工智能工具箱中非常宝贵的工具,它让我们对智能的理解又近了一步。
向成果丰硕的21世纪20年代致敬!
相关报道:
https://leogao.dev/2019/12/31/The-Decade-of-Deep-Learning/

???? 更多精彩咨讯,长按识别,即可关注