Java并发学习之阻塞队列
一.阻塞队列理论
1.认识阻塞队列
阻塞队列是可以在某种情况下自动阻塞的队列,它提供了可阻塞的put和take方法,以及支持定时的offer和poll方法。
如果队列满了,那么put方法将阻塞,不能被执行,直到有空间可以用put方法才可以被执行。
如果队列为空,那么take方法将会阻塞不能被执行,直到有元素可以用take方法才会被执行。
boolean offerLast(E e, long timeout, TimeUnit unit)方法
在此阻塞队列的末尾插入指定的元素,如果需要空间可用,等待指定的等待时间。
E poll(long timeout, TimeUnit unit)方法
检索并删除由此阻塞队列(换句话说,该阻塞队列第一个元素)表示的队列的头部,等待到指定的等待时间(如有必要)使元素变为可用。
注意:队列可以是有界的,也可以是无界的,无界队列永远都不会充满,因此无界队列上的put方法永远不会被阻塞。
2.认识生产者-消费者模式
阻塞队列支持生产者-消费者这一设计模式。
那么什么是生产者-消费者模式呢?
该模式将“找出需要完成的工作(生产者)” 与 “执行工作(消费者)” 的过程分离开来。
那么它们是如何分离的呢?
在这个过程中就用到阻塞队列了,当数据生成时,生产者把数据放到队列中,而当消费者想要处理数据时,就直接从队列中取即可。这种方式从某种程度上实现了生产者和消费者的松耦合。
在java中BlockingQueue简化了生产者-消费者的实现过程,它支持任意数量的生产者和消费者。
3.阻塞队列队生产者-消费者模式的影响
阻塞队列简化了消费者程序的编码,因为take操作会一直阻塞直到有可用的数据,如果生产者不能尽快地产生工作项使消费者保持忙碌,那么消费者就一直等待,直到有工作可以做。
1)在一些情况下,我们需要调整生产者线程数量和消费者数量之间地比例,从而实现更高的资源利用率。
2)有界队列的好处:如果生产者生成工作的速率比消费者处理工作的速率快,那么工作项就会在队列中积累起来,最终耗尽内存。但如果我们有界队列的话,当队列充满时生产者将阻塞不能继续生成工作,而消费者就有时间来赶上工作进度了。
原则:在构建高可靠的应用程序时,有界队列是一种强大的资源管理工具,它们能抑制并防止产生过多的工作项,使应用程序在负荷过载的情况下变得更加健壮。
3)有些时候开发人员总会假设消费者处理工作的速度能赶上消费者,因此通常不会为工作队列的大小设置边界,但这将导致在之后需要重新设计系统架构,所以,我们应该尽早地通过阻塞队列在设计中构建资源管理机制。
4)如果阻塞队列并不完全符合设计需求,那么还可以通过信号量来创建其他的阻塞数据结构。
二.Java中的阻塞队列
1.在java.util.concurrent包中包含了BlockingQueue的多种实现:
1)LinkedBlockingQueue类:

2)ArrayBlockingQueue类:
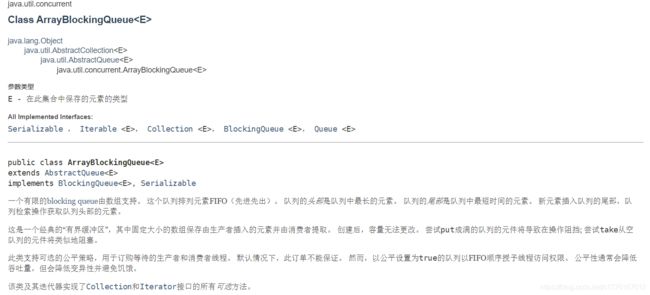
上面两种都是FIFO的队列。
3)PriorityBlockingQueue类:
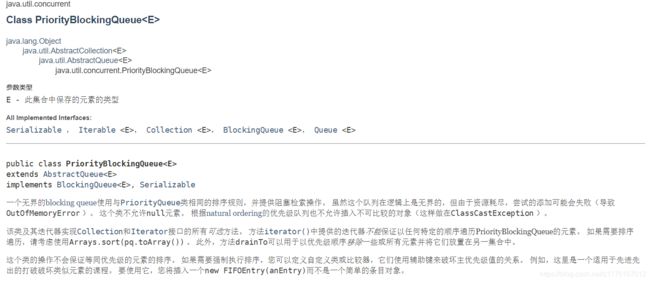
这是个按优先级排序的队列。
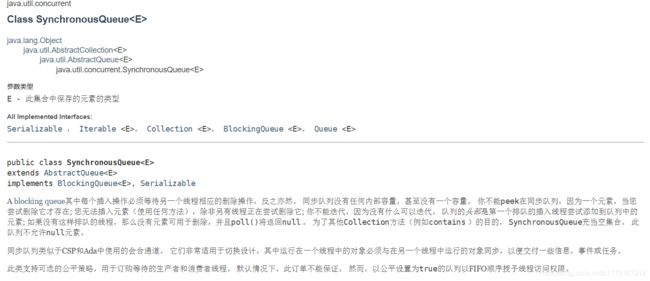
SynchronousQueue类:
实际上它不是一个真正的队列,因为它不会为队列中元素维护存储空间,与其他队列不同的是它维护一组线程,这些线程在等待这把元素加入或移出队列。因为SynchronousQueue没有存储功能,因此put和take会一直阻塞,直到有另一个线程已经准备好参与到交付过程中。
仅当有足够多的消费者,并且总是有一个消费者准备好获取交付的工作时,才适合使用同步队列。
2.实战案例:
有一种类型的程序适合被分解为生产者和消费者。
例如代理程序:它将扫描本地驱动器上的文件并建立索引以便随后进行搜索,类似于某些桌面搜索程序:
FileCrawler.java 这个类是个生产者类。
public class FileCrawler implements Runnable{
private final BlockingQueue<File> fileQueue;
private final FileFilter fileFilter;
private final File root;
public void run(){
try{
crawl(root);
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
public void crawl(File root) throws InterruptedException{
File [] entries=root.listFiles(fileFilter);//返回一个抽象路径名数组,表示由此抽象路径名表示的满足指定过滤器的目录中的文件和目录。
if(entries != null){
for(File entry:entries)
if(entry.isDirectory())//isDirectory()测试此抽象路径名表示的文件是否为目录。
crawl(entry);
else if(!alreadyIndexed(entry))
fileQueue.put(entry);//将文件对象存入阻塞队列中
}
}
}
Indexer.java 这个类是个消费者类
public class Indexer implements Runnable{
private final BlockingQueue<File> queue;
public Indexer(BlockingQueue<File> queue){
this.queue=queue;
}
public void run(){
try{
while(true) indexFile(queue.take()); //不断从阻塞队列中获取文件对象
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
}
生产者-消费者模式提供了一种适合线程的方法将桌面所有问题分解为更简单的组件。将文件遍历和建立索引分解为独立的操作,这样提高了代码的可重用性,每个操作只需完成一个任务,并且阻塞队列将负责所有的控制流,因此每个功能都更加简单和清晰。
生产者消费者模式为我们带来了许多性能优势:
1)生产者和消费者可以并发的执行。
2)如果一个是I/O密集型,另一个是CPU密集型,那么并发执行的吞吐率要高于串行执行的吞吐率。
3.串行线程封闭
1)什么是串行线程封闭?
我们知道线程封闭的对象只能由单个线程拥有,但我们其实有一种方式让一个对象被多个线程拥有,那就是通过安全地发布该对象来 “ 转移 ” 所有权,在转移所有权后,也只有另一个线程能获得这个对象地访问权,原线程不会再访问它,因此对象将被封闭在新地线程中。 这就是串行线程封闭
2)在java中,对象池利用了串行线程封闭,将对象“借给” 一个请求线程,只要对象池包含足够地内部同步来安全地发布池中的对象,并且客户代码本身不会发布池中的对象,或者在将对象返回给对象池后就不再使用它,那么就可以安全地在线程之间传递所有权。
4.双端队列与工作密取
在java 6 中增加了两种容器类型,Deque 和 BlockingDeque, 它们分别队Queue,BlockingQueue进行了扩展。
Deque是一个双端队列,它实现了在队列头和队列尾地高效插入和移除。 其具体的实现有:
ArrayDeque:
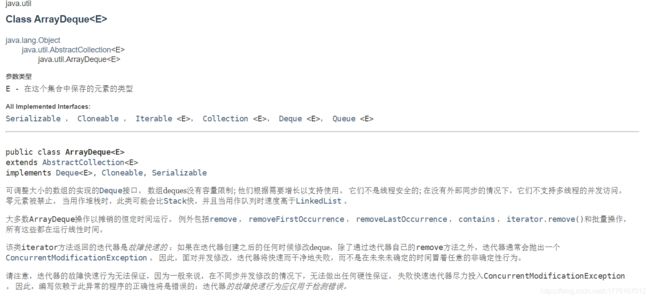
LinkedBlockingDeque:
正如阻塞队列适用于生产者-消费者模式一样,双端队列也适用于另一种模式:工作密取(Work Stealing)
1)什么是工作密取(Work Stealing)?
a.在生产者-消费者模式中,所有的消费者,有一个共享的工作队列,而在工作密取中,每个消费者都有各自的双端队列。
b.在工作密取中,如果一个消费者完成了自己双端队列中的全部工作,那么它可以从其他消费者的双端队列的尾部秘密的获取工作。
优点:密取工作模式比传统的生产者-消费者具有更高的可伸缩性。 这是因为工作者线程不会在单个共享的任务队列上发生竞争,在大多数时候,它们都只是访问自己的双端队列,从而极大的减少了竞争,当工作者线程需要访问另一个队列时,它会从队列的尾部获取工作(进一步降低了队列上的竞争程度)
2)工作密取模式的应用场景
工作密取非常适合既是消费者也是生产者的问题(当执行某个工作时可能导致更多的工作出现)。
例如:在网页爬虫程序中处理一个页面时,通常会发现有更多的页面需要处理。
还有图搜索算法问题,例如在垃圾回收阶段对堆进行标记,都可以通过工作密取机制来实现高效并行。
当一个工作线程找到新的任务单元时,它会将其放到自己队列的末尾,当双端队列为空时,它会在另一个线程的队列队尾查找新的任务,从而确保每个线程都保持忙碌状态。
学习总结:重点关注两种模式及其使用的数据结构