dbscan算法中 参数的意义_第十四章:利用Python实现DBSCAN与层次聚类分析
免责声明:本文是通过网络收集并结合自身学习等途径合法获取,仅作为学习交流使用,其版权归出版社或者原创作者所有,并不对涉及的版权问题负责。若原创作者或者出版社认为侵权,请联系及时联系,我将立即删除文章,十分感谢!
注:来源刘顺祥《从零开始学Python数据分析与挖掘》,版权归原作者或出版社所有,仅供学习使用,不用于商业用途,如有侵权请留言联系删除,感谢合作。
14.1 密度聚类简介
如前文所说,密度聚类算法可以发现任何形状的样本簇,而且该算法具有很强的抗噪声能力。算法具有这些优点的背后是需要用户设定合理的半径ε和对应领域内最少的样本数量MinPts,在学习密度聚类之前,介绍几个与密度聚类紧密相关的概念。
14.1.1 密度聚类相关的概念
点的ε领域:在某点p处,给定其半径ε后,所得到的覆盖区域。核心对象:对于给定的最少样本量MinPts而言,如果某点p的ε领域内至少包含MinPts个样本点,则点p就为核心对象。
直接密度可达:假设点p为核心对象,且在点p的ε领域内存在点q,则从点p出发到点q是直接密度可达的。
密度可达:假设存在一系列的对象链p1,p2,…,pn,如果pi是关于半径ε和最少样本点MinPts的直接密度可达pi+1(i=1,2,…,n),则p1 密度可达pn。
密度相连:假设点o为核心对象,从点o出发得到两个密度可达点p和点q,则称点p和点q是密度相连的。
聚类的簇:簇包含了最大的密度相连所构成的样本点。
边界点:假设点p为核心对象,在其领域内包含了点b,如果点b 为非核心对象,则称其为点p的边界点。
异常点:不属于任何簇的样本点。
在密度聚类过程中会不断地使用上面的几个概念,为了使读者能够清晰地理解这几个概念之间的区别,可以参考图14-1。

图14-1 密度聚类概念解释1
如图14-1所示,如果ε为3、MinPts为7,则点p为核心对象(因为在其领域内至少包含了7个样本点);点p为非核心对象;点m为点p的直接密度可达(因为它在点p的ε领域内)。

图14-2 密度聚类概念解释2
如图14-2所示,如果ε为3、MinPts为7,则点p1、p2和p3为核心对 象,点p4为非核心对象。点p1直接密度可达点p2、点p2直接密度可达点p3、点p3直接密度可达点p4,所以点p1密度可达点p4。点p4为核心点p3的边界点。
如图14-3所示,如果ε为3、MinPts为7,则点op1和q1为核心对象, 点p2和q2为非核心对象。由于点o密度可达点p2,并且点o密度可达点q2,则称点p2和点q2是密度相连的,如果点p2和点q2是最大的密度相连, 则图中的所有样本点构成一个簇;由于点N不属于图中呈现的簇,故将其判断为异常点。
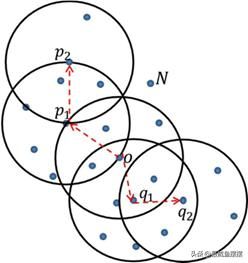
图14-3 密度聚类概念解释3
14.1.2 密度聚类的步骤
在了解上述几个概念含义之后,再来掌握密度聚类的具体操作步骤会相对轻松一些。密度聚类的过程有点像“贪吃蛇”,从某个点出发,不停地向外扩张,直到获得一个最大的密度相连,进而形成一个样本簇。为了使读者理解DBSCAN的聚类过程,将其执行步骤详细地写在下方:
(1) 为密度聚类算法设置一个合理的半径ε以及ε领域内所包含的最少样本量MinPts。
(2) 从数据集中随机挑选一个样本点p,检验其在ε领域内是否包含指定的最少样本量,如果包含就将其定性为核心对象,并构成一个簇C;否则,重新挑选一个样本点。
(3) 对于核心对象p所覆盖的其他样本点q,如果点q对应的ε领域内仍然包含最少样本量MinPts,就将其覆盖的样本点统统归于簇C。
(4) 重复步骤(3),将最大的密度相连所包含的样本点聚为一类,形成一个大簇。
(5) 完成步骤(4)后,重新回到步骤(2),并重复步骤(3)和
(4),直到没有新的样本点可以生成新簇时算法结束。
如上步骤中的文字可能理解起来不够形象,下面结合图形的方式来描述密度聚类的具体过程。如图14-4所示,如果密度聚类算法中的半径ε为1、最少样本量MinPts为4,假设初始选择的样本点为C1,则在其对应的ε领域内一共包含6个样本点,故点C1为核心对象,同时点p1到p5都是点C1直接密度可达的。继续以点p1至p5为中心,计算各自ε领域内的最少样本量,发现它们仍然为核心对象。再以点p4所覆盖的ε领域为例, 绘制点p6的ε领域,发现其不满足最小样本量为4的条件,故点p6不属于核心对象。从图可知,以点C1为核心的点,都可以密度可达簇中的所有点,故这些点之间也是密度相连的。以此类推,不断地向外“扩长”,直到获得最大的密度相连,便形成最终的一个簇。同理,再以被重新选择的样本点C2为例,利用“贪吃蛇”的思路不停地迭代,寻找其他的核心对象,直到能够构成簇的最大密度相连。从图中的结果来看,通过密度聚类算法,会将样本点聚为两个簇,并且点N为离群点,因为它不属于任何一个簇。

图14-4 密度聚类过程的示意图
在Python中可以非常方便地实现密度聚类算法的落地,读者只需要调用sklearn子模块cluster中的DBSCAN类就可以了,关于该“类”的语法和参数含义如下:
cluster.DBSCAN(eps=0.5, min_samples=5, metric='euclidean', m algorithm='auto', leaf_size=30, p=None, n_jobs=1eps:用于设置密度聚类中的ε领域,即半径,默认为0.5。min_samples:用于设置ε领域内最少的样本量,默认为5。metric:用于指定计算点之间距离的方法,默认为欧氏距离。metric_params:用于指定metric所对应的其他参数值。algorithm:在计算点之间距离的过程中,用于指定搜寻最近邻样本点的算法。默认为'auto',表示密度聚类会自动选择一个合适的搜寻方法。如果为'ball_tree',则表示使用球树搜寻最近邻。如果为'kd_tree',则表示使用K-D树搜寻最近邻。如果为'brute',则表示使用暴力法搜寻最近邻。有关这几种最近邻搜寻方法,可以参考第11章的内容。
leaf_size:当参数algorithm为'ball_tree'或'kd_tree'时,用于指定树的叶子节点中所包含的最多样本量,默认为30;该参数会影响搜寻树的构建和搜寻最近邻的速度。
p:当参数metric为闵可夫斯基('minkowski')距离时,p=1,表示计算点之间的曼哈顿距离;p=2,表示计算点之间的欧氏距离;该参数的默认值为2。
n_jobs:用于设置密度聚类算法并行计算所需的CPU数量,默认为1,表示仅使用1个CPU运行算法,即不使用并行运算功能。
需要说明的是,在DBSCAN类中,参数eps和min_samples需要同时调参,即通常会指定几个候选值,并从候选值中挑选出合理的阈值。在参数eps固定的情况下,参数min_samples越大,所形成的核心对象就越少,往往会误判出许多异常点,聚成的簇数目也会增加。反之,会产生大量的核心对象,导致聚成的簇数目减少。在参数min_samples固定的情况下,参数eps越大,就会导致越多的点落入到ε领域内,进而使核心对象增多,最终使聚成的簇数目减少;反之,会导致核心对象大量减 少、最终聚成的簇数目增多。在参数eps和min_samples不合理的情况 下,簇数目的增加或减少往往都是错误的。例如,应该聚为一类的样本由于簇数目的增加而聚为多类,不该聚为一类的样本由于簇数目的减少而聚为一类。
14.2 密度聚类与Kmeans的比较
Kmeans聚类的短板是无法对非球形的簇进行聚类,同时也非常容易受到极端值的影响,而密度聚类则可以弥补它的缺点。如果用于聚类的原始数据集为类球形,那么密度聚类和Kmeans聚类的效果基本一致。接下来通过图形的方式对比两种算法的聚类效果。首先通过随机抽样的方式形成两个球形簇的样本集,然后对比密度聚类和Kmeans聚类算法的聚类结构,代码如下:

见图14-5。
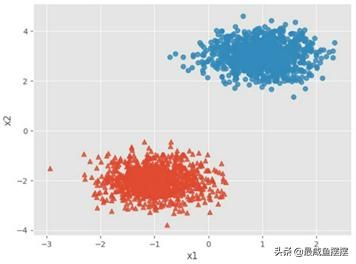
图14-5 生成两个球形簇的样本点
如图14-5所示,模拟两个类球形的样本簇,接下来使用密度聚类和Kmeans聚类两种算法对如上样本集进行聚类,查看两种算法的聚类效果:

见图14-6。

图14-6 Kmeans聚类与密度聚类效果图
如图14-6所示,对于两个球形簇的样本点而言,不管是Kmeans聚类(左图)还是密度聚类(右图)都能够很好地将样本聚为两个簇。所不同的是,密度聚类发现了一个异常点(如图中虚线圈内的点),它不属于任何一个簇。所以,密度聚类算法既可以在球形簇得到很好的效果, 又可以发现远离簇的异常点。
对于非球形簇的样本点而言,再来看看两个算法在聚类过程中的差异,样本数据仍然采用随机抽样的方式,代码如下:

见图14-7。

图14-7 生成球形簇和非球形簇的样本点
如图14-7所示,通过随机数生成的方式构造了三个簇的样本点,其中左下角的两个月亮形样本点代表两个非球形簇,右上角的样本点为球形簇。对于这样的数据集,通过密度聚类和Kmeans聚类算法,是否可以得到与原始样本点一致的簇特征?执行代码如下:

见图14-8。

图14-8 Kmeans聚类与密度聚类效果图
如图14-8所示,对于原始三个簇的样本点而言,当其中的样本簇不满足球形时,Kmeans聚类效果就非常不理想,会将原本不属于一类的样本点聚为一类(如左图所示),而对应的密度聚类就可以非常轻松地将非球形簇准确地划分开来(如右图所示)。在上面的图形中,再次验证了Kmeans聚类和密度聚类在对待球形簇的时候,聚类效果都比较出色。右图中的四个点仍然是通过密度聚类算法得到的异常点,但对于Kmeans聚类来说,并不会直接给出异常数据。
14.3 层次聚类
层次聚类的实质是计算各簇内样本点之间的相似度,并通过相似度的结果构建凝聚或分裂的层次树。凝聚树是一种自底向上的造树过程, 起初将每一个样本当作一个类,然后通过计算样本间或簇间的距离进行样本合并,最终形成一个包含所有样本的大簇;分裂树与凝聚树恰好相反,它是自顶向下的造树过程,起初将所有样本点聚为一个类,然后利用相似度的方法将大簇进行分割,直到所有样本为一个类为止。有关凝聚树和分裂树的生长过程可以参考图14-9加以理解。

图14-9 层次聚类过程的示意图
如图14-9所示,假设有6个样本点需要聚类,既可以使用层次聚类中的凝聚过程,又可以使用分裂过程。从图中来看,凝聚过程是从左到右的聚类过程,即从每个样本一个类别到所有样本一个类别的过程,而分裂过程则完全相反。相比于分裂过程,凝聚过程的聚类更容易理解和实现,所以本章将介绍凝聚过程的聚类算法。
不管是凝聚过程还是分裂过程,都需要回答两个问题,一个是样本点之间通过什么指标衡量它们之间的相似性,另一个是如何衡量簇与簇之间的距离。对于第一个问题来说,与Kmeans算法一致,就是通过样本点之间的欧氏距离或曼哈顿距离来衡量它们的相似性,距离越近,相似性越高。第二个问题会稍微复杂一些,簇与簇之间的距离不像点与点之间的距离那样可以直接计算,而是要计算所有簇间样本点之间的距 离,然后从中挑选出一个具有代表性的距离值表示簇间距离。接下来将详细介绍有关簇间距离的几种度量方法。
14.3.1 簇间的距离度量
假设在聚类的第一步过程中将两个距离最近的样本点聚为一个簇C1,对于其他数据点而言,如何计算点与簇之间的距离?同理,假设在某步中生成了另一个簇C2,又该如何度量簇C1和C2之间的距离?在sklearn模块中,为层次聚类所涉及的簇间距离提供了三种度量方法,分别是最小距离法、最大距离法和平均距离法。
1. 最小距离法
最小距离法是指以所有簇间样本点距离的最小值作为簇间距离的度量,但是该方法非常容易受到极端值的影响。例如,对于两个不太相似的簇而言,可能由于某个极端点的存在,会使簇间距离大大缩小,进而导致两个簇合并到一起。如果将最小距离法形象地展现出来,可以参考图14-10所示的内容。

图14-10 最小距离法度量簇间距离的示意图
如图14-10所示,在两个簇内均有各自的样本点,簇间距离的度量需要计算簇C1和簇C2间任意两点之间的距离,然后以最小距离值代表簇间距离。最小距离法可能导致聚类的不合理,如第二幅图中,簇C1和 簇C2内的绝大多数样本点相离都比较远,但由于个别异常点的存在,导致两个不该聚为一个类的样本点聚到了一起。
2. 最大距离法
最大距离法是指以所有簇间样本点距离的最大值作为簇间距离的度量,同样,该方法也容易受到极端值的影响。例如,对于两个比较相似的簇而言,可能由于某个极端点的存在,会使簇间距离过分放大,进而导致两个簇无法聚到一起。如果将最大距离法形象地展现出来,可以参考图14-11所示的内容。

图14-11 最大距离法度量簇间距离的示意图
如图14-11所示,如果以最大距离法度量两个簇之间的距离,则需要使用簇C1和簇C2间任意两点之间距离的最大值代表簇间距离。同样该方法也易受到极端值的影响,如第二幅图中,簇C1和簇C2内的绝大多数样本点相离都比较近,可能需要聚为一类,但由于个别异常点的存在, 拉大了两个簇之间的距离,导致两个簇无法聚为一类。
3. 平均距离法
最小距离法和最大距离法都容易受到极端值的影响,可以使用平均距离法对如上两种方法做折中处理,即以所有簇间样本点距离的平均值作为簇间距离的度量。如果将平均距离法形象地展现出来,可以参考图14-12所示的内容。
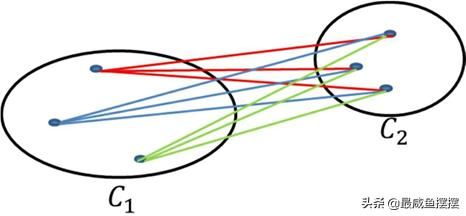
图14-12 平均距离法度量簇间距离的示意图
如图14-12所示,通过计算簇间样本点之间的距离,然后以综合的均值代替簇之间的距离,从而得到一个相对于最大距离法和最小距离法更加合理的聚类效果。当然,并非说平均距离法就一定很好,如果簇内样本点的分布都比较均匀,那么这三种方法的效果几乎是一样的。
14.3.2 层次聚类的步骤
在理解有关点与点、点与簇和簇与簇之间的距离度量标准之后,就需要进一步掌握层次聚类算法是如何实现样本点聚类的。本小节将详细介绍有关层次聚类算法的操作步骤,并通过举例说明的方式加强对聚类步骤的理解。层次聚类的步骤如下:
(1) 将数据集中的每个样本点当作一个类别。
(2) 计算所有样本点之间的两两距离,并从中挑选出最小距离的两个点构成一个簇。
(3) 继续计算剩余样本点之间的两两距离和点与簇之间的距离, 然后将最小距离的点或簇合并到一起。
(4) 重复步骤(2)和(3),直到满足聚类的个数或其他设定的条件,便结束算法的运行。
如上的4个步骤光用文字说明可能理解起来比较困难,接下来通过一个简单的例子形象地说明层次聚类法的整个聚类过程。
假设有5个样本点,分别是p1(1,3)、p2(2,2)、p3(0,0)、p4(5,1)和p5(5,2),接下来按照上述步骤对这5个点进行聚类。首先需要计算这5个样本点之间的两两距离,如表14-1所示。

表14-1 两两样本点之间的欧氏距离
如表14-1所示,通过样本点两两之间距离的计算,发现p4和p5之间的距离最近,故首先将这两个样本点聚为一类C1。接下来需要计算剩余点p1、p2和p3之间的两两距离以及点和簇C1之间的距离,假设使用最小距离法度量点和簇以及簇和簇之间的距离,如表14-2所示。

表14-2 第一轮聚类结果
如表14-2所示,经过计算,发现点p1与点p2之间的距离最近,故将点p1和p2聚为一类C2。以此类推,需要继续计算样本点p3与簇C1、C2之间的距离以及簇C1与簇C2之间的距离,如表14-3所示。

表14-3 第二轮聚类结果
如表14-3所示,在所有距离中,发现点p3与簇C2之间的距离最近, 距离为。所以,可以将点p3与簇C2进行合并,构成更大的簇C3。
假设将5个样本点聚为两类的话,如上的聚类过程就结束了,最终形成由点p1、p2和p3构成的类以及包含p4和p5两个样本点的类。按照聚类过程,可以将其可视化为如图14-13所示。
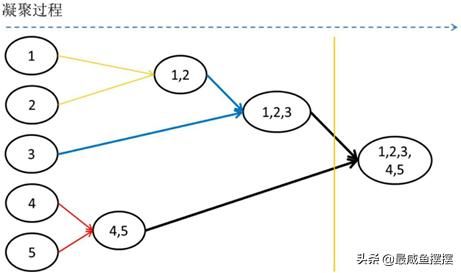
图14-13 层次聚类过程
如图14-13所示,起初的5个样本点各代表一个类,然后在聚类过程中将样本点p4和p5聚为一类、p1和p2聚为一类,再将样本点p3与样本点 p1、p2聚为一类,最后将两个簇归为一个大簇。如果需要将所有样本点聚为两类,只需要在最右侧的分支切一刀,得到左侧的两个根节点就是对应的两个簇。
如上利用的是最小距离法度量点与簇之间以及簇与簇之间的距离, 读者还可以尝试最大距离法或者平均距离法对上面的5个样本点进行聚类。
14.3.3 三种层次聚类的比较
运用Python可以非常方便地将层次聚类算法落地到实际工作中,读者只需导入sklearn中的cluster子模块,并从中调用AgglomerativeClustering类即可。有关该“类”的语法和参数含义如下:
cluster.AgglomerativeClustering(n_clusters=2, affinity='euclconnectivity=None, compute_full_tree=n_clusters:用于指定样本点聚类的个数,默认为2。
affinity:用于指定样本间距离的衡量指标,可以是欧氏距离、曼哈顿距离、余弦相似度等,默认为'euclidean';如果参数linkage 为'ward',该参数只能设置为欧氏距离。
memory:是否指定缓存结果的输出,默认为否;如果该参数设置为一个路径,最终将把计算过程的缓存输出到指定的路径中。connectivity:用于指定一个连接矩阵。
compute_full_tree:通常情况下,当聚类过程达到n_clusters时, 算法就会停止,如果该参数设置为True,则表示算法将生成一棵完整的凝聚树。
linkage:用于指定簇间距离的衡量指标,默认为'ward',表示最小距离法;如果为'complete',则表示使用最大距离法;如果 为'average',则表示使用平均距离法。
如前文所说,层次聚类法对于球形簇的样本点会有更佳的聚类效果,接下来将随机生成两个球形簇的样本点,并利用层次聚类算法对它们进行聚类,比较三种簇间的距离指标所形成聚类差异。

见图14-14。

图14-14 生成两个球形簇
如图14-14所示,两种不同形状的点代表了两个不同的簇。需要注意的是,三角形的样本点相对更加集中。下面采用层次聚类法对生成好的随机样本点进行聚类,代码如下:

见图14-15。

图14-15 三种层次聚类的效果图
如图14-15所示,左图为最小距离法形成的聚类效果;中图为最大距离法构成的聚类效果;右图为平均距离法完成的聚类效果。很显然, 最小距离法与平均距离法的聚类效果完全一样,并且相比于原始样本 点,只有三个样本点被错误聚类,即图中虚线框内所包含的三个点。但是利用最大距离法所产生的聚类效果要明显差很多,主要是由于模糊地带(原始数据中两个簇交界的区域)的异常点夸大了簇之间的距离。
14.4 密度聚类与层次聚类的应用
为了方便对比密度聚类与层次聚类的效果图,这里以我国31个省份的人口出生率和死亡率两个维度的数据为例,对其进行聚类分析。首 先,将数据读入Python中,并绘制出生率和死亡率数据的散点图,代码如下:
# 读取外部数据Province = pd.read_excel(r'C:甥敳獲AdministratorDesktopPr Province.head()# 绘制出生率与死亡率散点图plt.scatter(Province.Birth_Rate, Province.Death_Rate) # 添加轴标签plt.xlabel('Birth_Rate') plt.ylabel('Death_Rate') # 显示图形plt.show()见图14-16。

图14-16 各省份出生率与死亡率之间的散点图
如图14-16所示,31个点分别代表了各省份人口的出生率和死亡率,通过肉眼就能够快速发现三个簇,即图中的虚线框,其他不在圈内的点可能就是异常点了。接下来利用密度聚类对该数据集进行验证,代码如下:

见表14-4。

表14-4 通过迭代方法选择合理的eps和min_samples
针对如上代码做两点解释:一方面,不管是Kmeans聚类、密度聚类还是层次聚类,读者都需要养成一个好习惯,即对用于聚类的原始数据做标准化处理,这样可以避免不同量纲的影响;另一方面,对于密度聚类而言,通常都需要不停地调试参数eps和min_samples,因为该算法的聚类效果在不同的参数组合下会有很大的差异。如表14-4所示,如果需要将数据聚为3类,则得到如上几种参数组合,这里不妨选择eps为0.801、min_samples为3的参数值(因为该参数组合下的异常点个数比较合理)。这里还有一个问题需要解决,那就是将样本点聚为几类比较合理。一般建议选择两种解决方案:一种是借助于第15章所介绍的轮廓系数 法,即初步使用Kmeans算法对聚类个数做探索性分析;另一种是采用统计学中的主成分分析法,对原始的多变量数据进行降维,绝大多数情况下,两个主成分基本可以覆盖原始数据80%左右的信息,从而可以根据主成分绘制对应的散点图,并通过肉眼发现数据点的分布块。
接下来,利用如上所得的参数组合,构造密度聚类模型,实现原始数据集的聚类,代码如下:

见图14-17。

图14-17 密度聚类效果图
如图14-17所示,三角形、菱形和圆形所代表的点即为三个不同的簇,五角星所代表的点即为异常点,这个聚类效果还是非常不错的,对比建模之前的结论非常吻合。从图14-17可知,以北京、天津、上海为代表的省份,属于低出生率和低死亡率类型;广东、宁夏和新疆三个省份属于高出生率和低死亡率类型;江苏、四川、湖北为代表的省份属于高出生率和高死亡率类型。四个异常点中,黑龙江与辽宁比较相似,属于低出生率和高死亡率类型;山东省属于极高出生率和高死亡率的省 份;西藏属于高出生率和低死亡率的省份,但它与广东、宁夏和新疆更为相似。
同理,再使用层次聚类算法,对该数据集进行聚类,并比较其与密度聚类之间的差异,代码如下:

见图14-18。

图14-18 基于最小距离法形成的层次聚类效果
如图14-18所示,由于层次聚类不会返回异常点的结果,故图中的所有散点聚成了三个簇。与密度聚类相比,除了将异常点划分到对应的簇中,其他点均被正确地聚类。
为了对比第15章的内容,这里利用Kmeans算法对该数据集进行聚类,聚类之前利用轮廓系数法判断合理的聚类个数,代码如下:

见图14-19。
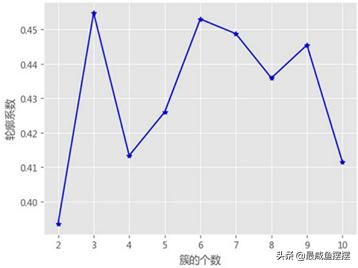
图14-19 轮廓系数法选择合理的K值
如图14-19所示,当簇的个数为3时,轮廓系数达到最大,说明将各省份出生率与死亡率数据集聚为3类比较合理,这也恰好验证了之前肉眼所观察得到的结论。Kmeans聚类代码如下:

见图14-20。

图14-20 Kmeans聚类效果
如图14-20所示,Kmeans聚类与层次聚类的效果完全一致。从上面的分析结果可知,该数据集仍然为球形分布的数据,因为密度聚类、层次聚类和Kmeans聚类的效果几乎一致,所不同的是密度聚类可以非常方便地发现数据中的异常点。
14.5 本章小结
本章介绍了另外两种常用的无监督学习算法,即密度聚类和层次聚类。密度聚类的最大优点在于它可以发现任意形状的样本簇,它是利用ε领域内的最少样本量定义点的密度,读者在利用该算法对样本聚类时需要不断地调整参数eps和min_samples。层次聚类采用“凝聚树”的思想对样本点进行划分,在sklearn中可以使用最小距离法、最大距离法和平均距离法衡量簇之间的距离,该算法的操作思想非常简单,但是不太适合大样本的聚类,而且当数据量非常大时,它的运算效率会非常低,同时结果不一定准确。
本章详细讲述了有关密度聚类和层次聚类的实现思想和步骤,同时对比了密度聚类与Kmeans聚类在球形与非球形样本点上的聚类效果; 在层次聚类中,也对比了最小距离法、最大距离法和平均距离法这三种度量簇间距离的聚类差异;最后将密度聚类和层次聚类算法应用在各省份出生率与死亡率的数据集中,进而发现它们之间的一些细微差异。通过本章内容的学习,读者可以掌握有关密度聚类和层次聚类的知识点, 进而将其应用到实际的工作中,解决非监督型的数据问题。
为了使读者掌握有关本章内容所涉及的函数和“方法”,这里将其重新梳理一下,以便读者查阅和记忆:
