mybatis查询in数组没有查出数据_Mybatis框架从入门到精通(五)

☞Mybatis框架从入门到精通视频实战教程☜
>>> 学习交流群 < < <
三、动态SQL
经常遇到很多按照很多查询条件进行查询的情况,比如智联招聘的职位搜索,比如OA系统中的支出查询等。其中经常出现很多条件不取值的情况,在后台应该如何完成最终的SQL语句呢?

如果采用JDBC进行处理,需要根据条件是否取值进行SQL语句的拼接,一般情况下是使用StringBuilder类及其append方法实现,还是有些繁琐的。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
MyBatis在简化操作方法提出了动态SQL功能,将使用Java代码拼接SQL语句,改变为在XML映射文件中截止标签拼接SQL语句。相比而言,大大减少了代码量,更灵活、高度可配置、利于后期维护。
MyBatis中动态SQL是编写在mapper.xml中的,其语法和JSTL类似,但是却是基于强大的OGNL表达式实现的。
MyBatis也可以在注解中配置SQL,但是由于注解功能受限,尤其是对于复杂的SQL语句,可读性很差,所以较少使用。
定义如下接口及其功能来练习动态SQL语句。
public interface EmployeeMapper {
public List findEmp(@Param("job") String job,
@Param("deptno") int deptno,
@Param("sal") double sal);
public List findEmp2(@Param("job") String job,
@Param("deptno") int deptno,
@Param("sal") double sal);
public List findEmp3(@Param("ename") String ename,
@Param("job") String job);
public List findEmp4(@Param("ename") String ename,
@Param("job") String job);
public int updateEmp(String job,double sal,int empno);
public List findEmp5(List deptNoList);
public List findEmp6(@Param("deptnoList") List deptNoList);
public List findEmp7(int [] arr);
} 3.1 if
每一个if相当于一个if单分支语句。一般添加一个where 1=1 的查询所有数据的条件,作为第一个条件。这样可以让后面每个if语句的SQL语句都以and开始。
3.2 where
使用where元素,就不需要提供where 1=1 这样的条件了。如果标签内容不为空字符串则自动添加where关键字,并且会自动去掉第一个条件前面的and或or。
3.3 bind
bind主要的一个重要场合是模糊查询,通过bind通配符和查询值,可以避免使用数据库的具体语法来进行拼接。比如MySQL中通过concat来进行拼接,而Oracle中使用||来进行拼接。
3.4 set
set元素用在update语句中给字段赋值。借助if的配置,可以只对有具体值的字段进行更新。set元素会自动帮助添加set关键字,自动去掉最后一个if语句的多余的逗号。
update emp
job = #{param1},
sal = #{param2}
where empno = #{param3}
3.5 foreach
foreach 元素是非常强大的,它允许你指定一个集合或者数组,声明集合项和索引变量,它们可以用在元素体内。它也允许你指定开放和关闭的字符串,在迭代之间放置分隔符。这个元素是很智能的,它不会偶然地附加多余的分隔符。
注意 你可以传递一个 List 实例或者数组作为参数对象传给 MyBatis。当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中,用名称在作为键。List 实例将会以“list” 作为键,而数组实例将会以“array”作为键。
在进行SQL优化是有一点就是建议少使用in语句,因为对性能有影响。如果in中元素很多的话,会对性能有较大影响,此时就不建议使用foreach语句了。
四、缓存
缓存的重要性是不言而喻的。将相同查询条件的SQL语句执行一遍后所得到的结果存在内存或者某种缓存介质当中,当下次遇到一模一样的查询SQL时候不在执行SQL与数据库交互,而是直接从缓存中获取结果,减少服务器的压力;尤其是在查询越多、缓存命中率越高的情况下, 使用缓存对性能的提高更明显。
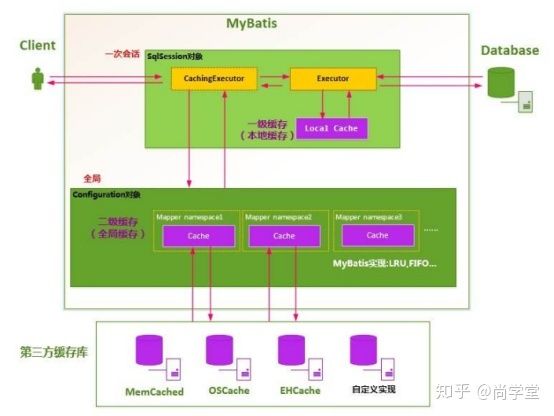
MyBatis允许使用缓存,缓存一般放置在高速读/写的存储器上,比如服务器的内存,能够有效的提供系统性能。MyBatis分为一级缓存和二级缓存,同时也可配置关于缓存设置。
一级存储是SqlSession上的缓存,二级缓存是在SqlSessionFactory上的缓存。默认情况下,MyBatis开启一级缓存,没有开启二级缓存。当数据量大的时候可以借助一些第三方缓存框架或Redis缓存来协助保存Mybatis的二级缓存数据。
4.1 一级缓存
一级存储是SqlSession上的缓存,默认开启,不要求实体类对象实现Serializable接口。下面在没有任何配置的情况下,测试一级缓存。
public class TestCache{
@Test
public void testCacheLevel1() throws IOException {
//创建SqlSessionFactory
InputStream is = Resources.getResourceAsStream("mybatis.cfg.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(is);
//创建SqlSession
SqlSession session = factory.openSession();
//创建Mapper(使用代理模式创建一个EmployeeMapper的实现类)
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
mapper.findEmp3("A", "CLERK");
mapper.findEmp3("C", "CLERK");
mapper.findEmp3("C", "CLERK");
session.close();
}
}
从输出结果可以看出,两次执行mapper.findEmp3("C", "CLERK");语句,只访问了一次数据库。第一次执行该SQL语句,结果缓存到一级缓存中,后续执行相同语句,会使用缓存中缓存的数据,而不是对数据库再次执行SQL,从而提高了查询效率。
4.2 二级缓存
二级缓存是SqlSessionFactory上的缓存,可以是由一个SqlSessionFactory创建的SqlSession之间共享缓存数据。默认并不开启。下面的代码中创建了两个SqlSession,执行相同的SQL语句,尝试让第二个SqlSession使用第一个SqlSession查询后缓存的数据。
public class TestCache{
@Test
public void testCacheLevel2() throws IOException {
//创建SqlSessionFactory
InputStream is = Resources.getResourceAsStream("mybatis.cfg.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(is);
//创建SqlSession
SqlSession session = factory.openSession();
SqlSession session2 = factory.openSession();
//创建Mapper(使用代理模式创建一个EmployeeMapper的实现类)
EmployeeMapper mapper = session.getMapper(EmployeeMapper.class);
EmployeeMapper mapper2 = session2.getMapper(EmployeeMapper.class);
mapper.findEmp3("A", "CLERK");
session.commit();
mapper2.findEmp3("A", "CLERK");
session2.commit();
session.close();
session2.close();
}
}注意其中的commit(),执行该命令后才会将该SqlSession的查询结果从一级缓存中放入二级缓存,供其他SqlSession使用。另外执行SqlSession的close()也会将该SqlSession的查询结果从一级缓存中放入二级缓存。两种方式区别在当前SqlSession是否关闭了。

执行结果显示进行了两次对数据库的SQL查询,说明二级缓存并没有开启。需要进行如下步骤完成开启。
1) 全局开关:在mybatis-config.xml文件中的
cacheEnabled的默认值就是true,所以这步的设置可以省略。
2) 分开关:在要开启二级缓存的mapper文件中开启缓存:
3) 缓存中存储的JavaBean对象必须实现序列化接口
public class Employee implements Serializable {
}经过设置后,查询结果如图所示。发现第一个SqlSession会首先去二级缓存中查找,如果不存在,就查询数据库,在commit()或者close()的时候将数据放入到二级缓存。第二个SqlSession执行相同SQL语句查询时就直接从二级缓存中获取了。

注意:
- MyBatis的二级缓存的缓存介质有多种多样,而并不一定是在内存中,所以需要对JavaBean对象实现序列化接口。
- 二级缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响
- 加入Cache元素后,会对相应命名空间所有的select元素查询结果进行缓存,而其中的insert、update、delete在操作是会清空整个namespace的缓存。
- 如果在加入Cache元素的前提下让个别select 元素不使用缓存,可以使用useCache属性,设置为false。
5. cache 有一些可选的属性 type, eviction, flushInterval, size, readOnly, blocking。

6. 缓存相关API
- 缓存的功能由根接口org.apache.ibatis.cache.Cache定义。整个体系采用装饰器设计模式
- 数据存储和缓存的基本功能由org.apache.ibatis.cache.impl.PerpetualCache永久缓存实现,其底层采用了HashMap结构来存储缓存信息。
- 通过一系列的装饰器来对PerpetualCache永久缓存进行缓存策略等方便的控制,

7. 查询数据顺序
- 二级缓存
- 一级缓存
- 数据库
- 把数据保存到一级
- 当SqlSession关闭或者提交的时候,把数据刷入到二级缓存中