
前言
在很多项目,特别是互联网项目,在使用MySQL时都会采用主从复制、读写分离的架构。
为什么要采用主从复制读写分离的架构?如何实现?有什么缺点?让我们带着这些问题开始这段学习之旅吧!
为什么使用主从复制、读写分离
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
主从复制的原理
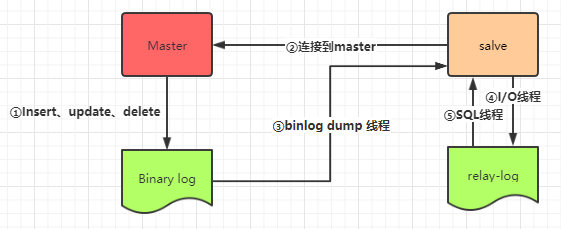
①当Master节点进行insert、update、delete操作时,会按顺序写入到binlog中。
②salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。
③当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。
④I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log。
⑤SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。
如何实现主从复制
我这里用三台虚拟机(Linux)演示,IP分别是104(Master),106(Slave),107(Slave)。
预期的效果是一主二从,如下图所示:

Master配置
使用命令行进入mysql:
mysql-u root -p
接着输入root用户的密码(密码忘记的话就网上查一下重置密码吧~),然后创建用户:
//192.168.0.106是slave从机的IP
GRANTREPLICATIONSLAVEON*.* to'root'@'192.168.0.106'identifiedby'Java@1234';
//192.168.0.107是slave从机的IP
GRANTREPLICATIONSLAVEON*.* to'root'@'192.168.0.107'identifiedby'Java@1234';
//刷新系统权限表的配置
FLUSHPRIVILEGES;
创建的这两个用户在配置slave从机时要用到。
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置:
# 开启binlog
log-bin=mysql-bin
server-id=104
# 需要同步的数据库,如果不配置则同步全部数据库
binlog-do-db=test_db
# binlog日志保留的天数,清除超过10天的日志
# 防止日志文件过大,导致磁盘空间不足
expire-logs-days=10
配置完成后,重启mysql:
service mysql restart
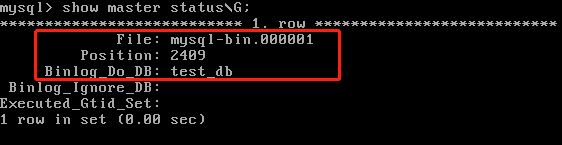
可以通过命令行show master status\G;查看当前binlog日志的信息(后面有用):
Slave配置
Slave配置相对简单一点。从机肯定也是一台MySQL服务器,所以和Master一样,找到/etc/my.cnf配置文件,增加以下配置:
# 不要和其他mysql服务id重复即可
server-id=106
接着使用命令行登录到mysql服务器:
mysql-u root -p
然后输入密码登录进去。
进入到mysql后,再输入以下命令:
CHANGEMASTERTO
MASTER_HOST='192.168.0.104',//主机IP
MASTER_USER='root',//之前创建的用户账号
MASTER_PASSWORD='Java@1234',//之前创建的用户密码
MASTER_LOG_FILE='mysql-bin.000001',//master主机的binlog日志名称
MASTER_LOG_POS=862,//binlog日志偏移量
master_port=3306;//端口
还没完,设置完之后需要启动:
#启动slave服务
start slave;
启动完之后怎么校验是否启动成功呢?使用以下命令:
showslavestatus\G;
可以看到如下信息(摘取部分关键信息):
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.104
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 619
Relay_Log_File: mysqld-relay-bin.000001
Relay_Log_Pos: 782
Relay_Master_Log_File: mysql-bin.000001 //binlog日志文件名称
Slave_IO_Running: Yes //Slave_IO线程、SQL线程都在运行
Slave_SQL_Running: Yes
Master_Server_Id: 104 //master主机的服务id
Master_UUID: 0ab6b3a6-e21d-11ea-aaa3-080027f8d623
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Auto_Position: 0
另一台slave从机配置一样,不再赘述。
测试主从复制
在master主机执行sql:
CREATETABLE`tb_commodity_info`(
`id`varchar(32) NOTNULL,
`commodity_name`varchar(512) DEFAULTNULLCOMMENT'商品名称',
`commodity_price`varchar(36) DEFAULT'0'COMMENT'商品价格',
`number`int(10) DEFAULT'0'COMMENT'商品数量',
`description`varchar(2048) DEFAULT''COMMENT'商品描述',
PRIMARY KEY(`id`)
) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COMMENT='商品信息表';
接着我们可以看到两台slave从机同步也创建了商品信息表:

主从复制就完成了!java技术爱好者有点东西哦~
读写分离
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
实现的方式有很多,以前我公司是采用AOP的方式,通过方法名判断,方法名中有get、select、query开头的则连接slave,其他的则连接master数据库。
但是通过AOP的方式实现起来代码有点繁琐,有没有什么现成的框架呢,答案是有的。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy两部分组成。
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
读写分离就可以使用ShardingSphere-JDBC实现。

下面演示一下SpringBoot+Mybatis+Mybatis-plus+druid+ShardingSphere-JDBC代码实现。
项目配置
版本说明:
SpringBoot:2.0.1.RELEASE
druid:1.1.22
mybatis-spring-boot-starter:1.3.2
mybatis-plus-boot-starter:3.0.7
sharding-jdbc-spring-boot-starter:4.1.1
添加sharding-jdbc的maven配置:
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
然后在application.yml添加配置:
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
spring:
shardingsphere:
datasource:
names:master,slave0,slave1
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url:jdbc:mysql://192.168.0.108:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url:jdbc:mysql://192.168.0.109:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url:jdbc:mysql://192.168.0.110:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
props:
sql.show:true
masterslave:
load-balance-algorithm-type: round_robin
sharding:
master-slave-rules:
master:
master-data-source-name: master
slave-data-source-names:slave0,slave1
sharding.master-slave-rules是标明主库和从库,一定不要写错,否则写入数据到从库,就会导致无法同步。
load-balance-algorithm-type是路由策略,round_robin表示轮询策略。
启动项目,可以看到以下信息,代表配置成功:

编写Controller接口:
/**
* 添加商品
*
* @param commodityName 商品名称
* @param commodityPrice 商品价格
* @param description 商品价格
* @param number 商品数量
* @return boolean 是否添加成功
* @author java技术爱好者
*/
@PostMapping("/insert")
public boolean insertCommodityInfo(@RequestParam(name = "commodityName") String commodityName,
@RequestParam(name = "commodityPrice") String commodityPrice,
@RequestParam(name = "description") String description,
@RequestParam(name = "number") Integer number) throws Exception {
returncommodityInfoService.insertCommodityInfo(commodityName, commodityPrice, description, number);
}
准备就绪,开始测试!
测试
打开POSTMAN,添加商品:
控制台可以看到如下信息:

查询数据的话则通过slave进行:

就是这么简单!
缺点
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
可能有人会问,有没有事务问题呢?
实际上这个框架已经想到了,我们看回之前的那个截图,有一句话是这样的:

以上文章来源于java技术爱好者 ,作者牛九木