目录:

001_ICML 2015 : Siamese neural networks for one-shot image recognition

这篇文章的主要目的是为了监测铁轨上的异常情况。
Benchmarks Database全都是包含铁轨的图片,Training data是不包含铁轨的图片。两幅图片首先由CNN映射成feature vector,然后计算这两个向量之间的距离,我们就可以得到它们之间的相似度,这样的话如果image 2有异常,就可以被监测出来:

三幅图片分别是道路的交叉、switch、路基松散。
002_CVPR 2018 : Learning to compare: Relation network for few-shot learning

和Siamese Network类似,Relation Network也是先通过一个embedding module将support image和query image映射成vector,但是与Siamese Network不同的是,Relation Network在得到这些向量之后,并没有直接计算它们的距离,而是先将它们的feature map concatenate起来,然后再经过一个relation module得到它们的relation score,最后根据这个relation score进行分类。
这样做的好处是可以增强模型的表达能力:Siamese Network中用到的是fixed linear comparator,而Relation Network是learnable non-linear comparator。
整个模块的具体架构如下:

最终取得的结果如下:
在Omniglot上:

在miniImageNet上:


003_NIPS 2016 : Matching networks for one shot learning

与普通metric learning 方法不同的是,matching network直接map a small labeled support set and an unlabeled example to its label.
这篇文章的novelty主要在两个方面:
- at the modeling level :
- use recent advances in attention and memory that enable rapid learning.
- at the training procedure:
- we train the network by showing only a few examples per class, switching the task from minibatch to minibatch, much like how it will be tested when presented with a few examples of a new task.
对整个网络结构的理解如下:
假设 和 是support set 中的sample和相应label, 是一个input unseen example (即test example),那么它的标签将由以下方式得到:
其中,按照论文中的说法, 是一个attention mechanism或者说是一个kernel (本质上就是一个 的矩阵)。这样一来,对于一个新的类,它的预测标签 就相当于是support set中已有标签的一个线性组合。或者说,可以把support set当成是一个memory,当我们需要预测新样本的标签时,我们就去这个memory中检索新样本的标签(检索的方式就是以上的运算公式)。因此在这个网络结构中, 的选取至关重要,如何选择 呢?论文中提供了如下方法:
一个最简单的形式是利用基于cos距离的softmax函数:
这里 和 是embedding functions,它们就对应于Figure 1中的两个神经网络结构。
这篇文章的另一个贡献是提出了episodic training的概念:

这里一个episode就是一个小样本学习的子任务,包含训练集(few-shot support set)和测试集(unlabeled query set)。
episodic training的目的是为了模仿真实的测试环境,使得训练环境和测试环境更加一致,从而减小它们的distribution gap,并且提高泛化性能。这种episodic training的方法被后来的很多论文借鉴。如Model-agnostic meta-learning for fast adaptation of deep networks (ICML 2017)通过学习一个好的初始化,使网络可以快速地泛化到target task。再如Prototypical Network (NIPS 2017)通过episodic training来训练一个好的representation,并通过计算到class prototype之间的欧氏距离来预测classes。
这种episodic training的方法对小样本学习非常有效,但是它并没有从根本上解决小样本学习数据量少的核心问题。
004_NIPS 2017 : Prototypical networks for few-shot learning

Prototypical Networks 认为,对于每一个类的集合,都存在一个它的原型(prototype)。这个原型是先通过CNN把input映射到embedding space,然后再取每个类的平均得到的。然后在分类的时候就可以通过找到离query point最近的类别来进行分类。
这篇论文中没有提供具体的网络架构。
005_ICLR 2019 : LEARNING TO PROPAGATE LABELS: TRANSDUCTIVE PROPAGATION NETWORK FOR FEW-SHOT LEARNING
参考资料:
- http://www.jintiankansha.me/t/CJcO1Vvu6a
传统的基于深度模型的fine-tune方法在小样本学习的任务上会产生严重的过拟合,原因是数据太少,不足以代表真实的数据分布。
Episodic training的方法非常有效,但是它并未从根本上解决数据量少的问题。如何在此基础上进一步提高当前方法的性能?这篇文章提出可以考虑instance之间的relationship并且把它们作为一个整体来预测,也就是所谓的transductive inference。作者之所以会想到这种方法,是借鉴了以下文章:
- 第一次提出transductive inference:
- Transductive inference for text classification using support vector machines (ICML 1999)
- An overview of statistical learning theory (IEEE transactions on neural networks 1999)
- 基于图的transduction method:
- Learning with local and global consistency (NIPS 2004)
- Label propagation through linear neighborhoods (ICML 2006)
- Transfer learning in a transductive setting (NIPS 2013)
- Transductive multi-view zero-shot learning (TPAMI 2015)
- Label propagation:
- Learning with local and global consistency (NIPS 2004)
- 如何解决label propagation中的variance parameter:
- Label propagation through linear neighborhoods (ICML 2006)
- Learning from labeled and unlabeled data with label propagation (CMU Technical Report 2002)
- 尝试在test example上做转导推理:
- On first-order meta-learning algorithms (arXiv 2018)
其中2018年的文章提出在test example上做转导推理,而这篇文章是在support sample和test sample上同时做转导推理。
这篇文章可以看做是第一篇在few-shot learning上做转导推理的文章。
Transductive inference和inductive inference的区别是:inductive methods predict test examples one by one,而transductive methods consider all the samples as a whole.
在这篇文章中,作者是通过construct a network on both the labeled and unlabeled data并且propogate labels between them for joint prediction来实现它们的transductive method的。
作者指出,通过这种转导推理的方式进行标签传播有一个弊端,即转导传播网络的建立并没有考虑main task,因为在测试的时候网络已经定型了,不可能在测试的时候再学一个新的转导网络。因此,从理论上讲,转导标签传播似乎是不可行的。
但是,episodic training提供了一种模拟真实数据分布的训练方法,即使无法得到真实的数据分布,但是我们可以以episode的方式去模拟它。这样一来,转导标签传播似乎又变得可行了。因此,作者在这一想法的基础上,提出了转导传播网络(Transductive Propagation Network, TPN)。
网络架构如下:


结果:



006_ICLR 2019 : A Closer Look at Few-shot Classification
参考资料:
- 腾讯云社区:https://cloud.tencent.com/developer/article/1446081
- https://cloud.tencent.com/developer/user/1638669
这篇文章没有提出什么先进的模型,只是指出了小样本学习中存在的几个问题,并进行了一些有意义的实验。
这篇文章展示了a baseline method with a distance-based classifier就可以达到和sota meta-learning methods相当的性能(数据集是mini-ImageNet和CUB)。
作者还探究了domain shift对模型性能的影响。所谓domain shift,就是说base and novel classes are sampled from different domains。作者通过实验表明,当前的few-shot learning方法无法很好地应对这一domain shift问题,强调learn to adapt to domain differences in FSL的重要性。
Baseline和Baseline++的架构如下:
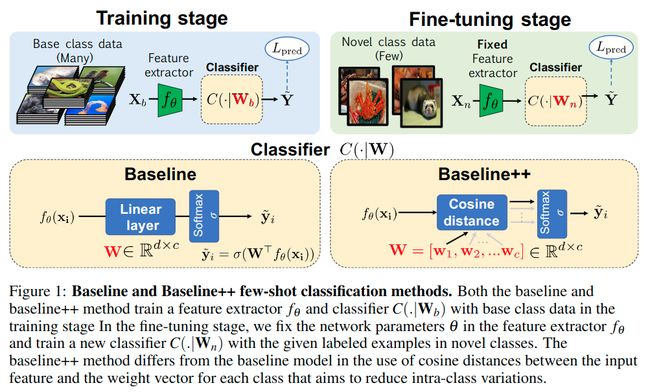
它们的不同之处是baseline是用线性层作为分类器而baseline++是基于cos距离来进行分类(按作者的说法,这样可以reduce intra-class variation among features during training)。训练这两个分类器的时候是先train再fine-tune。
作者拿这两个分类器和以下四种方法进行比较:

Matching networks for one shot learning (NIPS 2016) 这篇文章将meta-learning定义为:
The prediction is conditioned on a small support set S, because it makes the training procedure explicitly learn to learn from a given small support set.
Meta-learning方法的大体操作过程如下:

Matching Net、ProtoNet、Relation Net以及MAML之间的联系和区别如下:

实验结果:
Baseline++就可以达到媲美sota model的性能:(backbone:conv-4)

而且从baseline和baseline++的对比中可以看到,减小intra-class variation是当前FSL方法中值得注意的一个重要因素。
随着网络深度的加深,不同模型的性能变化:

注意CUB数据集和mini-ImageNet数据集的区别:mini-ImageNet的domain difference in base and novel classes比CUB的更大。而上述实验结果表明,随着网络深度的加深,在CUB数据集上各个模型的性能差异会越来越小,而在mini-ImageNet上则有变大的趋势。
为此,作者设计了一个cross-domain的实验:base class是来自mini-ImageNet的,而validation和novel class来自CUB。作者用ResNet-18作为feature backbone。实验结果如下:

可以看到当当source domain和target domain的差异非常大时,baseline方法的性能反而是最好的(超过所有meta-learning methods),甚至超过了baseline++,对这种现象一种可能的解释是reducing intra-class variation compromises adaptability。
其它meta-learning方法之所以比不过baseline,可能是因为没有做adaptation(固定feature并且训练一个新的softmax classifier),结果如下:

结果表明,经过adaptation之后,meta-learning方法的性能确实会得到改善。
007_CVPR 2019 (ORAL) : Finding Task-Relevant Features for Few-Shot Learning by Category Traversal
Hongyang Li (CUHK), Xiaogang Wang (SenseTime)
参考资料:
- 雷锋网:https://www.leiphone.com/news/201907/4wc0990rNQf43mss.html
(从大的方面来讲,这篇文章有点类似于TCDCN的想法:Not individual, but joint.)
作者指出,现在的metric-learning方法learn a feature similarity comparison between a query (test) example and the few support (training) examples. 然而,这些方法都是一个一个地考虑单个的support class,从来都没有从整体的角度去审视这些task。这样就会存在一个弊端:每次由embedding模块得到的feature都只是从一个小的support set中提取出来的,漏掉了不同support set之间可能存在的一些关联信息。如果我们能够把这些关联信息也考虑进去,或许能够得到更好的分类效果。基于这个想法,作者提出了Category Traversal Module (CTM)。这个模块没有对现有的网络架构进行更改,它更像是一个“插件”——在现有网络的基础上充当一个辅助模块,它可以一次性纵览整个support set,识别出类间的task-relevant feature和类内的unique feature,然后再将这些收集到的feature并入support set和query set的feature embedding中,这样就能为后续的分类模块提供更充足的信息,从而获得更好的性能。这个结构的简单图示如下:
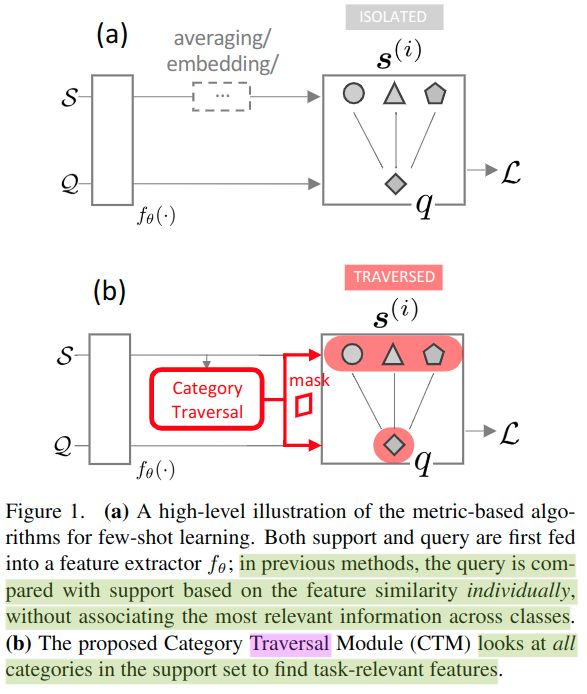
使用这个模块之后,baseline system (如Matching Net、Relation Net)在mini-ImageNet和tieredImageNet数据集上的性能会提升 左右。
PyTorch implementation: https://github.com/Clarifai/few-shot-ctm
这篇文章对小样本学习的定义是:给定一个包含N类的small support set(这N类是之前没有见过的),每类K个样本。然后给一个query sample,小样本学习的目标就是要把它分到这N个support 类别中的某一类中去。训练时给定一个很大的training set,然后通过episodic training的方式从中挑出support set和query set(也就是说,训练时的support set和query set都是来自training set的。
小样本学习的通用训练过程如下:

通用测试(推断)过程如下:

本文提出的CTM的结构如下所示:

整个CTM以support set的feature作为输入,通过一个Concentrator和一个Projector得到一个mask p,然后再将p加到原有的support set和query set的feature上,形成新的support set feature和query set feature。之后的过程就和普通的FSL方法一样了。
这里Concentrator的作用主要是为了得到universal features shared by all instances for one class。它的具体实现是先通过一个CNN模块进行降维,然后再对每个类中所有的样本取平均,这样就得到了最终的输出 。这个CNN模块可以用一个简单的CNN层或一个ResNet block,它的主要目的是通过降采样的方式移除同一个类中不同instance之间的差异并提取它们的commonality。
与此相反,Projector主要是为了发现这些feature之间的差异,它可以同时查看所有support category中的concentrator feature,然后选择一些对于当前task来说最具有判别力的feature。然后再通过一系列的变换最终得到p。
Reshaper的目的是为了使不同模块的feature shape匹配,从而使p最终能够成功地影响到原有的feature embedding 。
测试结果:


值得注意的是,CTM使用的backbone是ResNet-18 (作为feature extractor)。表中最后一列的data augment是做了pretrianing以及一些基本的数据增强方法(random crop,color jittering以及horizontal flip)。
008_CVPR 2019 : Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning
这篇文章把关注点放在了由backbone提取出的feature上,认为最终分类结果的好坏是受这些weight vectors的影响的:要想最终得到好的分类效果,这些weight vector必须是appropriate的。
如何将原始的classification weights变成想要的new classification weights?这篇文章提出了利用DAE (Denoising Autoencoder Network) 来达到这一目的。除此之外,为了能够捕捉到不同类之间的相互依赖关系,在去噪模块,作者用到了GNN (Graph Neural Network)。
经过整个这一结构,最终便可以输出一个reconstructed classification weights,从而为后续的classification模块提供更好的输入。


关于ImageNet-FS、miniImageNet和TieredImageNet数据集的介绍:


在ImageNet-FS上的测试结果:(backbone: ResNet-10)

在miniImageNet和tieredImageNet上的测试结果:(backbone: 2-layer Wide Residual Network (WRN-28-10))

这个结果也进一步说明了用GNN的效果比MLP更好。

009_CVPR 2019 : Spot and Learn: A Maximum-Entropy Patch Sampler for Few-Shot Image Classification

这里面用到了强化学习的手段。
这篇文章是从图片上的一个小patch出发,通过网络不断地对原始图片进行采样从而得到不同的patch,同时输出不同的state,这些由网络采样得到的不同的小patch可以认为是“learned”data augmentation。最终由得到的final state 预测最终的分类结果。如下图所示:

测试结果:(backbone:conv-4)
Baseline-FC是用一个标准的全连接层加一个softmax激活函数来输出预测的标签。
Baseline-CS是用cosine similarity替换掉了标准全连接层中的dot product。
这篇文章指出,cosine similarity的结果要优于fully connected classifier。

010_CVPR 2019 : LaSO: Label-Set Operations networks for multi-label few-shot learning
参考资料:
- https://baijiahao.baidu.com/s?id=1639682732244958776&wfr=spider&for=pc
- https://www.jiqizhixin.com/articles/2019-06-14-5
这篇文章考虑的是多标签小样本分类问题。从整体来看,这篇文章的思路是利用data augmentation:在feature space中对输入的两张图片进行运算,从而产生一些具有新标签的图片(等价于对两张图片中的标签进行交、并、补运算,从而产生一些新样本,以此来扩充样本数量,从而向大样本学习靠拢,以此来提高分类性能。)。注意,由于这里是在feature space中做运算的,因此得到的是synthesized feature vector,只不过它们对应的标签已经变了(变成了原标签经过相应的运算后产生的标签)。这种方法对应的图示如下:

这是第一个对多标签小样本分类任务的一个尝试。(也是第一个提出multi-label few-shot classification的概念。)
网络架构如下:

通过联合、减法和交叉运算,合成具有不同标签的新样本。
输入是两个多标签的图片X、Y以及它们对应的标签集合L(X)、L(Y),在经过一个backbone之后得到对应的feature: 和 。然后将 和 concatenate起来,送入三个不同的LaSO网络: 、 和 ,并由这些不同的LaSO网络合成新的feature vector。这三个不同LaSO网络的功能如下:
- 交网络 :
- 生成的feature vector为:
- 生成的label为:
- 并网络 :
- 生成的feature vector为:
- 生成的label为:
- 差网络 :
- 生成的feature vector为:
- 生成的label为:
值得注意的是,LaSO网络是可能会产生出原本不存在的标签的——因为我们并没有指明输入图片的标签是什么,有点类似于让LaSO网络自己去猜输入图片都包含哪些标签(LaSO网络的输入仅仅是两个feature vector 和 ,没有明确的标签信息),然后迫使网络去学习如何得到我们想要的标签。
最终,原始的两个feature vector 和 ,以及由LaSO网络产生的三个feature vector 、以及被一起送入一个分类器 。我们用BCE loss (Binary Cross-Entropy loss)来训练分类器 和LaSO网络。此外,还用了一系列的reconstruction loss来改善LaSO网络的运算结果。
这篇文章用到了两个backbone:Inception V3和ResNet-34。
011_CVPR 2019 : Few-Shot Learning with Localization in Realistic Settings
首先指出了传统深度学习数据集和FSL数据集是两个极端:一个太多,一个太少。现实世界中的数据集分布应该是heavy-tailed distribution:

因此作者提出了一个具有类似数据分布的数据集:meta-iNat。
这篇文章没有提出新的网络架构,而是对Prototypical network做了三个改进:
- batch folding : improves gradients during training and help the learner generalize to large classes.
- few-shot localization : teaches the learner to localize an object before classifying it.
- covariance pooling : greatly increases the expressive power of prototype vectors without affecting the underlying network architecture.




- PN : Prototypical Network
- BF : Batch Folding
- fsL : few-shot Localization
- CP : Covariance Pooling
012_CVPR 2019 : Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy
这篇文章考虑的是large-scale FSL (i. e., the number of source classes is large), 针对的数据集是ImageNet, 有1000类。
This paper suggests to learn transferrable visual features with the class hierachy which encodes the semantic relations between source and target classes.

The semantic relations between source classes and target classes are used as the prior knowledge to help learn a more transferrable feature embedding.
The semantic relations are explicitly encoded to a tree-like class hierachy.
In the class hierachy, semantic similar classes are grouped, and each cluster then forms a parent node in the upper layer of the tree.
During the training stage, only the source classes samples are fed into a CNN followed by the proposed hierachical prediction net.
During the test stage, we extract visual features of test samples and the few training samples (both from target classes) using the proposed feature learning model. The test samples are then recognized by a simple nearest neighbor search using the visual features of few-shot samples (from target classes ) as references.

This net consists of two steps for predicting the superclass labels. The first is to predict the labels at different class/superclass layers. The second is to encode the hierachical structure of class/superclass layers into superclass label prediction by combine the prediction results of the same and lower class/superclass layers obtained by the first step.
(The FC layers are all unshared.)
013_CVPR 2019 : Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning

这篇文章是借鉴了十年前的一篇文章:Naive-Bayes Nearest-Neighbor (NBNN), 它把其他FSL 方法最后一层的image-level feature measure 换成了local descriptor based image-to-classs measure. 同时,和NBNN不同的是these local descriptors are now trained deeply via convolutional neural networks.
由local descriptor计算出最终的measure是通过k-nearest neighbor search的方法得到的。
值得一提的是,由于小样本学习的样本数较少,因此这对于KNN方法正好是一个有点:计算量可以大大减小。

014_CVPR 2019 : Edge-Labeling Graph Neural Network for Few-shot Learning
参考资料:
- https://www.jiqizhixin.com/articles/2019-06-14-5
Other GNN-based FSL methods :
- Victor Garcia and Joan Bruna. Few-shot learning with graph neural networks. In ICLR, 2018.
- Transductive propagation network for few-shot learning. In ICLR, 2019

015_CVPR 2019 : Meta-learning with differentiable convex optimization

常规的meta-learning 方法是由一个embedding model和一个base learner组成的。embedding module负责map the input domain into a feature space,base learner 负责map the feature space to task variables. meta-learning的目的就是学一个embedding model以使base learner 能够泛化得更好。
base learner可以选择nearest-neighbor classifiers或者他们的变种,因为它们概念比较简单而且适合这种数据量较少的情况。但是, idscriminatively trained linear classifiers often outperform NN classifiers,因为它们可以额外地利用negative examples,从而有更丰富的信息。
在这篇文章中,作者investigate linear classifiers as base learner (如SVM)。因为线性模型涉及到的问题通常是凸优化问题(这样就可以用一些off-the-shelf convex optimizers)而且通常是低阶的(这样需要优化的变量就很少)。
016_ICCV 2019 : Few-Shot Learning with Global Class Representations


和传统meta-learning方法最大的不同是从一开始就把novel class 拿去训练了。然后通过产生并利用global class representation使得base embeding 和 novel embeding 更具有区分度。
017_ICCV 2019 : Memory-Based Neighbourhood Embedding for Visual Recognition



这篇文章主要着眼于feature embedding层面。这篇文章主要利用了input image 的neighborhood 的信息(有点类似于GNN),借助neiborhood information,解决了两个问题:
- how to acquire more relevant neighbors in the network;
- how to aggregate the neighborhood information for a more discriminative embedding.
Some novel ideas
-
Forgetting:
遗忘现象对人类来说是很常见的,当我们要学很多东西的时候,很容易就学了后面的忘了前面的。那么小样本学习存不存在这个问题呢?例如,当泛化的类别比较多的时候(比如在Imagenet上有1000个类),要泛化这么多的类,会不会学了后面的类就忘了前面的类?如果确实存在这个问题,要如何解决?目前好像对这个问题的研究还比较少。
现在的方法好像更多的是去关注sample和sample之间的联系(如利用图的方法或其它联合考虑所有类之间关系的方法,而不再是单独地考虑单个的个体)。
-
基于现有的论文可以得到的一些结论:
- cosine similarity比fully connected classifier的效果更好;
- backbone使用ResNet的比使用conv-4的效果更好;
- 使用GNN结构的效果更好;
- 考虑到不同类之间相互依赖关系的比只考虑单个类的效果更好。