其实很多编程语言都可以做爬虫,例如java、c#、php等等甚至excel都可以抓网页的图表,那么为什么我们要用Python呢?它简单、便捷,而且有好多库可以选择,可以说python是写爬虫的首选了!
今天就来带大家写一个简单而又完整的爬虫,我们来抓取整站的图片的,并且保存到电脑上!

准备工作
工具:Python3.6、pycharm
库:requests、re、time、random、os
目标网站:妹子图(具体url大家自己去代码里看。。。)

在写代码之前
在我们开始写代码之前,要先对网站进行分析,重点有这个几个地方:
1、先判断网页是否静态网页,这个关系我们采用的爬虫手段!
简单的说,网页中的内容,在网页源代码中都可以找到,那么就可以断定,这个网站是静态的了;如果没有找到,就需要去开发者工具中查找,看看是抓包呢还是分析js结构或者其他的方式。
2、看看网页的结构,大致清楚抓取目标数据,需要几层循环,每次循环的方式,以及是否保证没有遗漏!
3、根据网页源代码来决定采用的匹配方式
一般来说,正则表达式是处理字符串最快的方式,但是在爬虫中它的效率并不是很高,因为它需要遍历整个html来匹配相关内容,如果网页源代码比较规整的话,建议采用bs4或者xpath等等解析网页结构的方式比较好!
当然,今天我们是基础向的爬虫,就用正则表达式了,毕竟正则是必须掌握的内容!
那么,具体怎么写爬虫代码呢~?简单的举例给大家说下:
如果是手工操作的话,大概是这个流程
打开主页==>选择一个分类==>选择一个图集==>依次选择图片==>右键保存==>重复以上保存其他图片
那么这个过程放到代码中呢,它的结构大概是这样:
访问主页url==>找到并循环所有分类==>创建分类文件夹==>访问分类url==>找到页码构建循环分类所有页==>循环页面所有图集==>创建图集文件夹==>找到图集内所有图片url==>保存到对应文件夹
好了,思路也有了,那就废话不多说了,我们来写代码吧~!

开始写代码
首先是导入上述的各种库,没有的需要安装一下!然后写入以下几行代码获取网页源代码看看是否有反爬:

如果能顺利打印出源代码且和网页右键查看的源代码一致,那么可以判定该网站基本没有反爬了!
第16行代码的含义是给html设定编码格式。因为Python3默认是utf-8,如果网站不是这个编码格式的话,会出现乱码,所以我们直接指定一下。
接下来呢,就是找到所有分类的名字和url了,来看看网页中和源代码中,它的位置在哪

全部在a标签的属性中,那么我们可以用一行代码获取了
infos = re.findall(r'a href="(http://www.meizitu.com/.*?html)" target="_blank" title="(.*?)" ',html.text)
这里用正则匹配,2个括号中的内容就是我们需要的url和名字了,然后开始构建循环遍历所有的分类
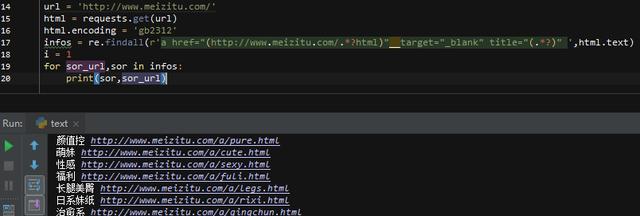
上一步取出的infos是列表,而且每一个元素都是一个元组,格式为(url,名字),所有我们用2个元素去遍历infos,来获取我们需要的内容,先打印下看看结果是否正确!
这里先不创建文件夹,先进行下一步,访问分类的url,然后开始构建分类中的页码吧!分析网页发现,所有的页码都在下方,但是还是稍有不同:没有当前页、多了下一页和末页


由于存在图集不足一页的情况(上述源代码就不会出现),所以我们这么处理循环

19-21行获取分类的源代码,22行获取所有页码的url,然后用set()函数去重,再新建一个空列表,将分类的url加进去,注意,元组是不能用append()方法添加到列表中的,所以要先将set元组转化为列表然后分别重新拼接列表内所有的url,在将2个列表相加的方式合并为一个列表!这样我们就得到了分类下所有翻页页面的url
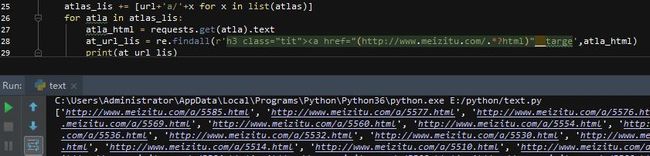
循环所有的url,获取所有图集的url列表,27行没有用encoding指定编码是因为这里我不需要取到中文的内容,所以简写了一下!终于该取图片了!

图集的title和图集内所有图片的url都取到了!其实到这里就已经完成了爬虫的80%了!剩下的20%就是保存图片到本地,这里就不多说了,给大家提供2个代码片段,一个是新建文件夹并判断是否存在,一个是剔除字符串内不符合命名要求的字符


最终完整代码和运行效果

在请求中加入了时间模块的暂停功能,不加入的话可能会被网页拒绝访问!
在最后请求图片地址的时候,需要加入UA来告诉服务器你是浏览器而不是脚本,这个是最常用的反爬手段了

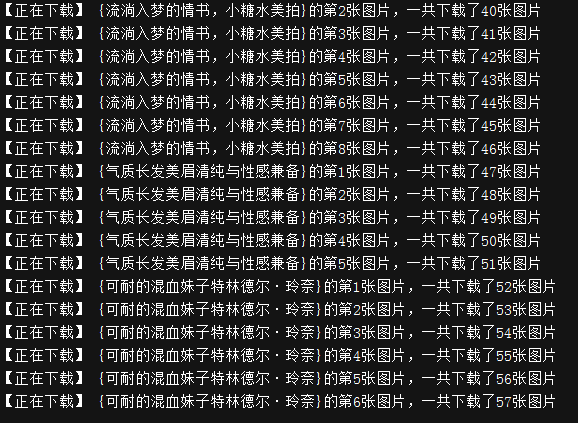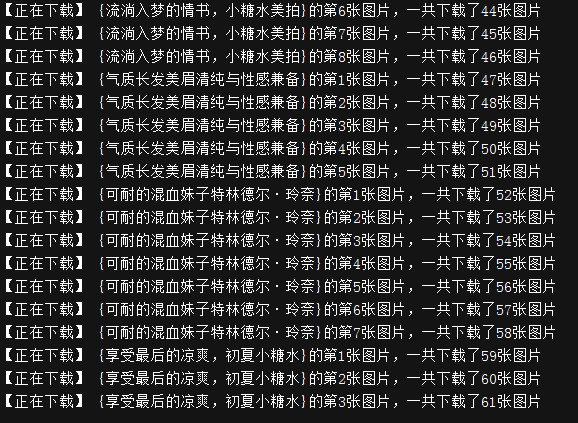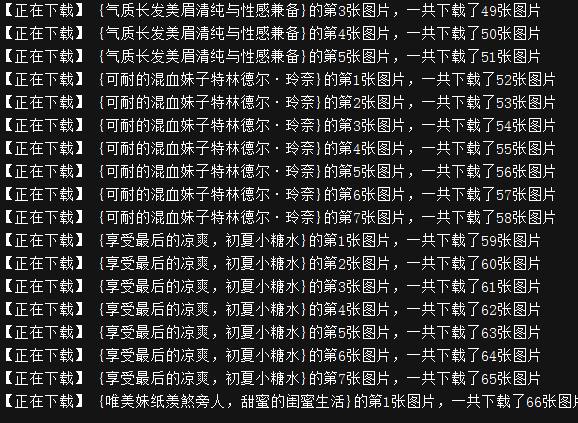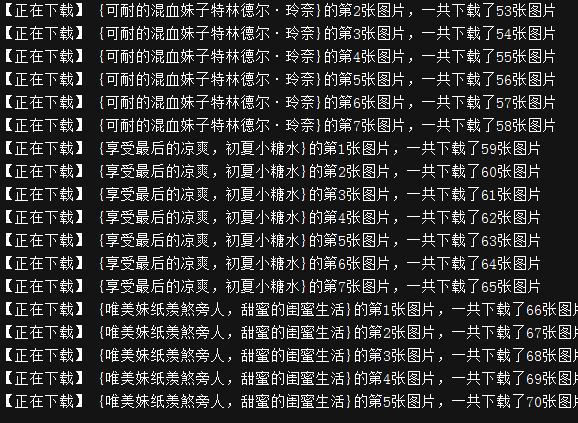
下载一段时间后的效果
