《Matching User with Item Set: Collaborative Bundle Recommendation with Deep Attention Network》论文笔记
《Matching User with Item Set: Collaborative Bundle Recommendation with Deep Attention Network》论文笔记

背景:
大多数推荐系统研究致力于推荐单一商品给用户。然而在现实中,平台需要给用户展示的是一些列的商品(捆绑销售策略,bundle:捆绑)。
之前大部分是an item to a user,这篇论文的是 a set of items(a bundle) to a user
这篇论文的主要工作就是关注于对用户和捆绑的商品集合的交互进行建模。

问题:
直观来说,我们第一想法是将这个bundle看成是一个“items”,然后采用传统的协同过滤方法进行用户和bundle交互的建模。从技术上来讲,嗯好像可以。但是如此直接的方式用于预测user-bundle的交互效果并不好,主要问题有如下2点:
1.Bundles are not atomic units.
因为一个bundle里包含了很多item(至少2个),不像传统的协同过滤一样只有一个item。直观来讲,包含多个item的bundle应该展示出相似的吸引用户的模式。所以呢,将bundle中的各个item与user的交互表示作为user-bundle matrix的各列向量,然后执行协同过滤(如矩阵分解方法),这种方法是不合适的。
2.User-bundle interaction are more sparse.
可想而知,用于表示user-bundle的交互向量是非常稀疏的,比user-item还要稀疏。比如说一个用户只有对这个bundle里的商品都满意时,才会选择这个bundle。再比如说,一个用户非常喜欢这个bundle里的所有商品,然而可能他不喜欢这个bundle,因为他认为将这些商品组合起来并不是一个很好的组合方式,哈哈哈。且冷启动问题在user-bundle中更为常见(比如:如何给用户推荐新的捆绑促销商品)。
主要贡献:
论文里提出了一个神经网络叫:Deep Attention Multi-Task model,用以解决上述提到的两个问题。
它包含2个特殊的设计:
1.Handling non-atomic bundles:
设计了一个分解注意力网络来聚合一个bundle里的item embedding以获得bundle的embedding表示。其很好的具备处理冷启动bundle的自然能力。
2.Handling sparse user-bundle interactions:
以多任务学习的方式结合了user-bundle的交互和user-item的交互(具体的结合方式看后面就知道咯),引入user-item交互是为了减缓只用user-bundle交互的稀疏性问题,同时可以引入附加的在用户兴趣和商品属性上的协同过滤信息,以允许一个任务(user-item modeling)的好处转移到另一个任务上(user-bundle modeling)
在公开数据集上,DAM达到了SOTA,证明了论文提出的这种注意力设计和多任务学习的方式的有效性。
这里介绍一下论文中的符号定义,以便更好的看懂公式:
大写粗体字母:矩阵
小写粗体字母:向量
非粗体字母:标量或索引
这里直接截取论文里的图,也就是一些符号的定义:

定义这个捆绑推荐任务的输入和输出如下:

因冷启动问题在捆绑推荐中很常见,(比如:如何给用户推荐新的捆绑促销商品)。所以输入上面那个个性化评分函数的bundle不一定要在集合B(上面符号定义有写)中,因为B中包含的是训练集中的bundle,即新的bundle可以随意构造,不局限于训练集中的bundle。所以这要求模型根据bundle的组成的items而不是bundle的ID进行编码。
论文的方法:
1.Bundle Representation Learning
Bundle的表示即编码,是基于它的items的而不是ID
来一句论文里的话:
![]()
在得到一个bundle里的各个item的embedding(即latent space里的隐向量)之后,我们利用DAM融合这些item embedding,从而获得bundle embedding。
直觉上来说,一个bundle里的不同item起着不同的作用,所以论文设计了一个自适应加权和操作(此灵感源自神经网络中的注意力机制,论文有附参考文献)用于权衡一个bundle里不同item的重要程度。
具体表达如下:
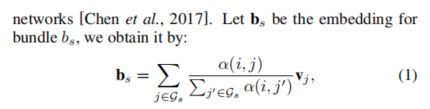

上截图中说的L1范数(L1范数指向量中各个元素绝对值之和)就是指上式的分母,即相当于一个归一化操作,用来抵消不同bundle的大小不同的影响(因为不同bundle可能有不同的数量的item)。公式里的粗体vj就是item的embedding。所以上式表示:bundle embedding等于bundle里的所有item embedding 的加权求和。
Factorized Attention Network
论文里说,然而用上面MLP来计算权重,不足以学习user和item之间的这种低秩关系(因为交互向量矩阵非常的稀疏,学过线代的我们知道哈哈哈,它的秩很低),(论文里有附参考文献关于这方面的研究证明)。所以为了更好地遵循这种低秩结构,论文采用了一个
低秩模型去计算上面的权重α(i,j)。
![]()

论文称这中加权求和设计位可以表示为:分解注意力权重矩阵(由低秩模型后接softmax层计算得到)。由于其和现有的神经网络不同,因此论文称其为分解注意力网络factorized attention network。
2.Joint Modeling of User-Bundle and User-Item Interactions
通过上面,我们得到了bundle embedding,然后将其与user embedding 输入以下匹配函数,就轻松实现了一个user-bundle预测模型:
![]()

对于上面这个匹配函数,有很多方法,论文采用的是NCF网络(何向南大神的2017年的一篇推荐系统论文《Neural collaborative filtering》)。原因有以下2点:
1.NCF是一个基于神经网络的架构,非常适合于集成bundle representation learning module 去建立一个端到端的模型。
2.NCF很灵活,在它的NCF层,可以自己堆叠不同数量的全连接层,从而提高其非线性能力,以学习更为复杂的匹配函数。这样的灵活性使我们能够很好的结合user-item交互和user-bundle交互。
Joint User-Bundle and User-Item Model
为了能够传输更多的user-item交互信息,我们将在2个任务:user-bundle预测任务和user-item任务中共享user embedding 和 item embedding。因此,user-item预测模型可抽象成如下形式(即user-item预测的匹配函数):
![]()
下面将通过关联上面提到的2个任务去设计这两个匹配函数。
一个最为直接的办法就是按NCF里方法一样,这里分别构建两个单独的MLP去设计这2个匹配函数:
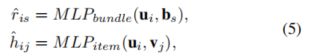

但是,我们很容易的知道,建立的2个MLP的参数是没有任何联系的,所以这种方法不能够很好地结合这2个任务的之间的有益关系。
考虑到这2个任务共享输入的user embedding ,所以我们推测这2个MLP的浅层可能在做相同的事,即提取的特征可能差不多。基于此,论文提出了一个联合建模的体系结构(如下):
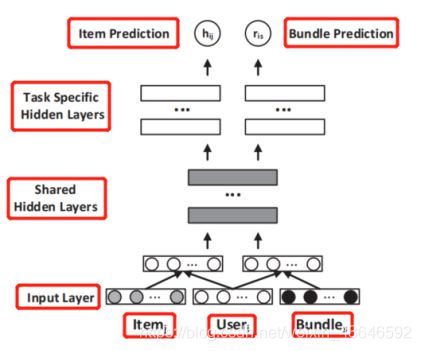
从图可知,这2个MLP的浅层是共享的,高层是分开去执行各自的任务的。可用公式描述如下:
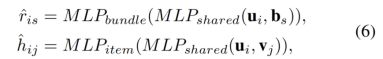

这种灵感源于CV领域的一篇论文(论文有附参考文献)。但论文是第一个将这种结构引入推荐系统去联合两个相关的任务。同时作者也提到了:近期有人提出了一个联合模型去结合user-iten预测任务和group-item预测任务。然而它们只有共享层,不像论文的模型一样浅层共享,高层分离预测。
Multi-Task Learning
通过user与bundle的交互(如点击、购买、评论),我们可以知道user是对这个bundle感兴趣的。但是,如果user和bundle没有交互,我们并不能确定这个user是否喜欢这个bundle。因此,一个较为合理的方法是假设用户选择的bundle比未选择的bundle更为可取。因此,论文采用了pairwise learning framework(关于pairwise loss的解释:推荐系统中的pointwise和pairwise区别),loss采用的是BPR loss(Bayesian Personalized Ranking):
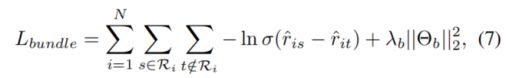

(L2范数:向量x的2范数是x中各个元素平方之和再开根号)
从上面公式,我们可以看到,最小化损失函数,会使ris比rit越来越大。这就是pairwise loss,不像pointwise loss,是最大小化输出与目标之间的平方损失。
上面是user-bundle预测任务的loss。同理呢,对于user-item预测任务,loss定义为:
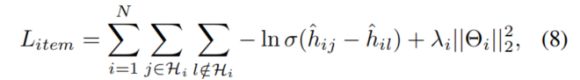

所以,最终的整个模型的loss为上面两个loss的和:
![]()
在模型训练的每一步迭代中,我们先采样一个用户。然后,对于bundle:采样一个正样本(即与该用户有交互的)和一配对负样本(没有交互的)。对于item:采样一个正样本和一配对的负样本。然后模型的训练目标就是就是最小化上面的loss函数,从而依据此去更新模型的参数。同时我们可以一次采样多个用户,采用mini-batch的训练方式。
实验部分:
在2个真实世界的数据集上进行实验,个是用户喜爱音乐方面的,另一个是用户喜爱书籍方面的。数据集描述如下:
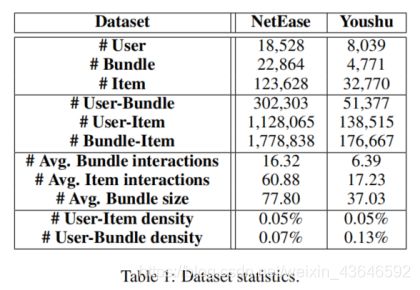
整个实验围绕以下3个问题展开:
Q1:论文提出的DAM模型在所有bundle recommednation models中达到来SOTA?
Q2:factorized attention network 有效吗?它的表现是否比其它融合策略优秀?
Q3:Multi-task learning framework 是否有益于DAM的表现?共享层层数是否会影响模型的表现?
关于实验的一些设置:
评估指标:
论文采用leave-on-out(留一法)评估手段。对于每个用户,随机选出他的一个交互作为测试。为评估模型的Top-K推荐性能,采用了2个评估指标:
1.基于相关性度量的指标:Recall@K。它反映的是top-K推荐列表中positive item的数量。
2.基于排序度量的指标:MAP@K。它考虑来在top-K推荐列表中positive item的排名位置。
由于排序所有用户的bundle非常耗时,所以随机选取99个与用户没有交互的bundle作为负样本。
Baselines基准:
论文将DAM与以下4个模型进行了性能对比:
1.BPR
2.NCF
3.BR
4.EFM
超参数的设置:
论文基于Pytorch深度学习框架实现了所有的模型。学习率的变化设置为[0.01, 0.005, 0.001, 0.0005],训练batchsize固定为1024。所有模型均匀Adam优化器。L2正则化系数范围[0.1, 0.01, 0.001, 0.0001]。NCF模型层数设置为2层,各层的embedding size一样。对NCF和DAM引入Dropout机制防止过拟合。DAM采用3层结构,2层共享层,各层embedding size一致。
性能表现对比(针对Q1):
各模型TOP-K性能对比如下:
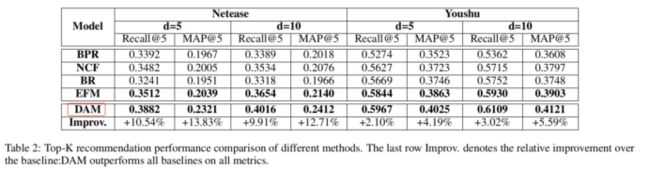
从上表可知,BPR表现最差,这说明了通过内积这种较为直接的方式不足以捕获用户和bundle之间的的交互信息。同时从NCF的表现来看,证明了采用深度神经网络去学习user-bundle的这种非线性交互特征的有效性。同时对比其他模型和DAM的表现,可以看到DAM在所有的情况下达到了SOTA。验证了结合user-item和user-bundle这2中交互信息去训练能够取得更好的表现。论文将这种改善归因于分解注意力网络和多任务学习框架。
Factorized Attention Network的影响(针对Q2):
分解注意力网络是DAM的一个重要组件。为了验证其有效性,实验与如下融合策略进行了对比:
1.min-pooling
2.max-pooling
3.mean-pooling
4.neural attention
对比结果如图:
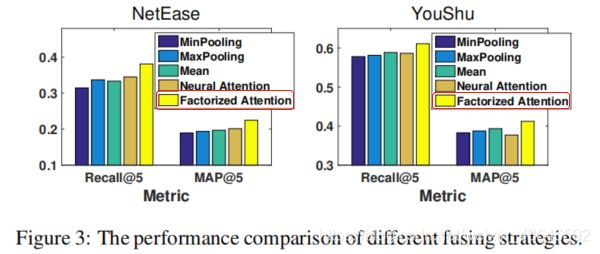
可以看到以上4种表现的差不多,说明了这些方法不足以捕获items之间复杂的关系。
虽然neural attention和factorized attention都是为items采用了可训练的权值,但factorized attention表现更好,说明其具有更好的泛化性能。
共享层层数的影响(针对Q3):
DAM-k表示有k层共享层,隐藏层都固定为3。DAM-0可被视为没有使用multi-task learning framework。实验测试结果如下:
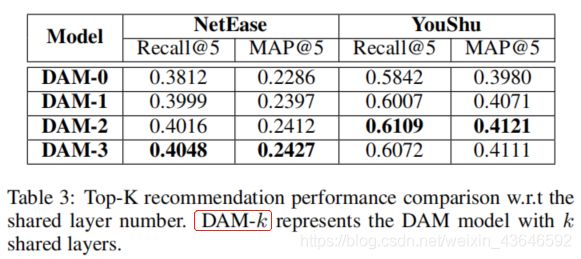
通过对比DAM-0和其它几种,可以知道multi-task learning模型比single-task learning模型牛,同时也进一步验证了结合user-item和user-bundle交互信息能够提高模型的性能。同时我们可以看到随着共享层数的增加,模型性能有所提高。但是在YouShu数据集中看到,增加到3层共享层,模型性能有所降低,原因是过多的增加共享层有可能会引入与bundle推荐任务无关的噪声。
Future Work:
1.对item co-occurrence信息进行建模。因为我们知道,有些产品是存在互补关系的,如你买网球拍,一般会买个网球。嘿嘿。
2.结合时间因素实现bundle的动态推荐。因为我们知道用户的兴趣很容易随着时间变化。如以往人们喜欢听古典歌曲,现代人们偏向于听流行歌曲。
论文下载地址:https://www.ijcai.org/Proceedings/2019/0290.pdf