有趣的python实践案例(三)---PubMed搜索小工具二创
wo们出python基础啦系列(一)—数据类型
wo们出python基础啦系列(二)—条件判断
wo们出python基础啦(三)—if循环语句
wo们出python基础啦(四)—while循环语句
有趣的python实践案例(一)—获取WiFi密码+动态二维码
有趣的python实践案例(二)—turtle库绘画案例
有趣的python实践案例(三)—PubMed搜索小工具二创

看到上图大家有没有心动?没有错,这是佩奇的又一大作 (所以鸽了这么久都不发推送) 在一次偶然的机会下我了解到了一个开源的PubMed搜索小工具的框架,于是充分发挥了奇趣多多的创造精神,站在巨人的肩膀上完成了此次开发!
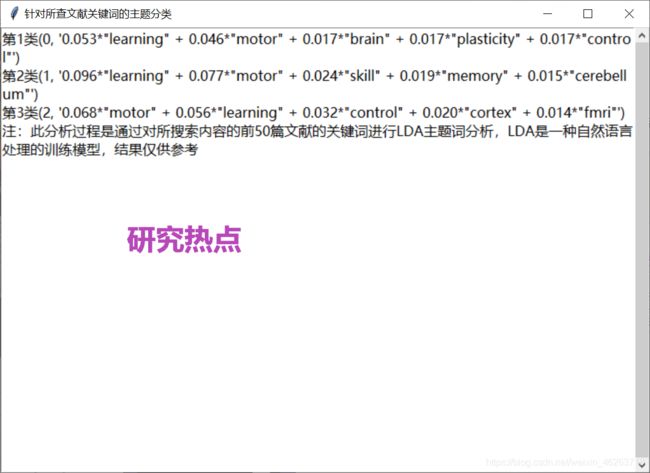
此次开发的PubMed搜索小工具集摘要及标题作者信息提取,翻译,以及研究热点分析为一体,涉及python库内容较多,这篇推送不能一一涉及,所以佩奇给大家挑选了最为常用的python自然语言处理库nltk以及LDA主题提取训练模型给大家介绍图二研究热点的具体实现过程 。
PS:如果有感兴趣的朋友想使用这个软件以及获取源码,请关注奇趣多多回复PubMed即可获取
分词-nltk库
文本是由段落(Paragraph)构成的,段落是由句子(Sentence)构成的,句子是由单词构成的。切词是文本分析的第一步,它把文本段落分解为较小的实体(如单词或句子)。NLTK能够实现句子切分和单词切分两种功能。
import nltk
sent = "I am almost dead this time"
token = nltk.word_tokenize(sent)
结果:token['I','am','almost','dead','this','time']
文本规范化处理-nltk库
分词只是把句子简单切分,为了方便之后处理我们还需移除标点符号和类似is, am, are, this, a, an, the这样的噪声词使得文本更加规范化。
nltk.download('stopwords')
# Downloading package stopwords to C:\Users\Administrator\AppData\Roaming\nltk_data...Unzipping corpora\stopwords.zip.
from nltk.corpus import stopwords
stop_words = stopwords.words("english")
text="""Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome."""
word_tokens = nltk.tokenize.word_tokenize(text.strip())
filtered_word = [w for w in word_tokens if not w in stop_words]
'''
word_tokens:['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?',
'The', 'weather', 'is', 'great', ',', 'and', 'city', 'is', 'awesome', '.']
filtered_word:['Hello', 'Mr.', 'Smith', ',', 'today', '?', 'The', 'weather', 'great', ',', 'city', 'awesome', '.']
'''
除此之外,我们还需要将类似flying这样的根据上下文语境出现的派生词进行词性还原,进而生成fly这个真实的单词。
from nltk.stem.wordnet import WordNetLemmatizer # from nltk.stem import WordNetLemmatizer
lem = WordNetLemmatizer() # 词形还原
word = "flying"
print("Lemmatized Word:",lem.lemmatize(word,"v"))
'''
Lemmatized Word: fly
'''
准备 Document - Term 矩阵-LDA主题模型
LDA是一种文本挖掘的方法:LDA主题模型(Topic Model)能够识别在文档里的主题,并且挖掘语料里隐藏信息。
作为一种数学模型,我们就需要将处理好的语料转化为数学语言也就是矩阵来表达。下面的代码演示如何运用genism库将语料转换为 Document - Term 矩阵:
import genism
from gensim import corpora
# 创建语料的词语词典,每个单独的词语都会被赋予一个索引
dictionary = corpora.Dictionary(doc_clean)
# 使用上面的词典,将转换文档列表(语料)变成 DT 矩阵
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean]
构建 LDA 模型
LDA 假设文档是由多个主题的混合来产生的,并且通过随机采样的方法不断试错主题分类,最终得到主题分布和字分布都比较稳定的一个分类结果。下面的代码演示如何构建LDA模型及查看结果:
每一行包含了主题词和主题词的权重,Topic 1 可以看作为“不良健康习惯”,Topic 3 可以看作 “家庭”。
# 使用 gensim 来创建 LDA 模型对象
Lda = genism.models.ldamodel.LdaModel
# 在 DT 矩阵上运行和训练 LDA 模型
ldamodel = Lda(doc_term_matrix, num_topics=3, id2word = dictionary, passes=50)
# 输出结果
print(ldamodel.print_topics(num_topics=3, num_words=3))
[
'0.168*health + 0.083*sugar + 0.072*bad,
'0.061*consume + 0.050*drive + 0.050*sister,
'0.049*pressur + 0.049*father + 0.049*sister
]
你们的关注给了我们继续的动力!

以下为引用:
python爬虫——打造个人专属pubmed文献搜索工具