Linux System Programming 学习笔记(三) 标准缓冲I/O
1. partial block operations are inefficient.
The operating system has to “fix up” your I/O by ensuring that everything occurs on block-aligned boundaries and rounding up to the next largest block
用户级程序可能在某一时刻仅仅读写一个字节,这是极大的浪费。Each of those one-byte writes is actually writing a whole block
user-buffered I/O:a way for applications to read and write data in whatever amounts feel natural but have the actual I/O occur in units of the filesystem
block size
2. User-buffered I/O
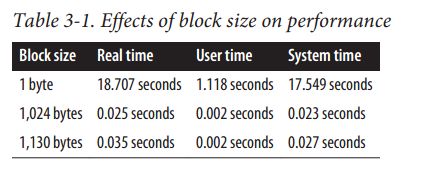
上如表明,只要将执行I/O操作的请求数设置为物理I/O块大小的整数倍 就可以获得很大的性能提升。
Larger multiples will simply result in fewer system calls
使用stat系统调用可以获知文件I/O块大小
1 #include <stdio.h> 2 3 int main(int argc, char* argv[]) 4 { 5 struct private { 6 char name[100]; /* real name */ 7 unsigned long booty; /* in pounds sterling */ 8 unsigned int beard_len; /* in inches */ 9 }; 10 struct private p; 11 struct private blackbeard = {"Edward Teach", 950, 48}; 12 13 FILE* out = fopen("data", "r"); 14 if (out == NULL) { 15 fpiintf(stderr, "fopen error\n"); 16 return 1; 17 } 18 19 if (fwrite(&blackbeard, sizeof(struct private), 1, out) == 0) { 20 fprintf(stderr, "fwrite error\n"); 21 return 1; 22 } 23 24 if (fclose(out)) { 25 fprintf(stderr, "fclose error\n"); 26 return 1; 27 } 28 29 FILE* in = fopen("data", "r"); 30 if (in == NULL) { 31 fprintf(stderr, "fopen error\n"); 32 return 1; 33 } 34 if (fread(&p, sizeof(struct private), 1, in) == 0) { 35 fprintf(stderr, "fread error\n"); 36 return 1; 37 } 38 39 if (fclose(in)) { 40 fprintf(stderr, "fclose error\n"); 41 return 1; 42 } 43 44 fprintf(stdout, "name = \"%s\" booty = %lu beard_len = %u\n", p.name, p.booty, p.beard_len); 45 return 0; 46 }
it's important to bear in mind that because of differences in variable sizes, alignment, and so on, binary data written with one application may not be readable by other applications. These things are guaranteed to remain constant only on a particular machine type with a particular ABI
fflush() merely writes the user-buffered data out to the kernel buffer. Calling fflush(), followed immediately by fsync(): that is, first ensure that
the user buffer is written out to the kernel and then ensure that the kernel's buffer is written out to disk.
int fileno (FILE *stream); //返回文件流(C标准I/O库)对应的文件描述符(Unix系统调用)
绝不能混用Unix系统调用I/O和C语言标准I/O
You should almost never intermix file descriptor and stream-based I/O operations
3. 控制缓冲
标准I/O提供三种类型缓冲:
(1) 无缓冲:Data is submitted directly to the kernel. 无性能优势,基本不用。标准错误默认是无缓冲
(2) 行缓冲: With each newline character, the buffer is submitted to the kernel. 终端文件(标准输入输出)默认是行缓冲
(3) 块缓冲:Buffering is performed on a per-block basis. By default, all streams associated with files are block-buffered
4. 线程安全
标准I/O函数本身是线程安全的。标准I/O函数使用锁机制来确保进程内的多个线程可以并发执行标准I/O操作。(注意:
确保线程安全的原子区域仅限于单一函数,多个I/O函数之间并不保证)
Any given thread must acquire the lock and become the owning thread before issuing any I/O requests,within the context of single function calls,
standard I/O operations are atomic
void flockfile (FILE *stream); void funlockfile (FILE *stream);
5.标准I/O的缺陷
The biggest complaint with standard I/O is the performance impact from the double copy
reading data: kernel ==> standard I/O buffer ==> application buffer
writing data: application data ==> standard I/O buffer ==> kernel