Designing algorithms for Map Reduce
Since the emerging of Hadoop implementation, I have been trying to morph existing algorithms from various areas into the map/reduce model. The result is pretty encouraging and I've found Map/Reduce is applicable in a wide spectrum of application scenarios.
So I want to write down my findings but then found the scope is too broad and also I haven't spent enough time to explore different problem domains. Finally, I realize that there is no way for me to completely cover what Map/Reduce can do in all areas, so I just dump out what I know at this moment over the long weekend when I have an extra day.
Notice that Map/Reduce is good for "data parallelism", which is different from "task parallelism". Here is a description about their difference and a general parallel processing design methodology.
I'll cover the abstract Map/Reduce processing model below. For a detail description of the implementation of Hadoop framework, please refer to my earlier blog here.
Abstract Processing Model
There are no formal definition of the Map/reduce model. Basic on the Hadoop implementation, we can think of it as a "distributed merge-sort engine". The general processing flow is as follows.
- Input data is "split" into multiple mapper process which executes in parallel
- The result of the mapper is partitioned by key and locally sorted
- Result of mapper of the same key will land on the same reducer and consolidated there
- Merge sorted happens at the reducer so all keys arriving the same reducer is sorted
{kind=link}
Within the processing flow, user defined functions can be plugged-in to the framework.
- map(key1, value1) -> emit(key2, value2)
- reduce(key2, value2_list) -> emit(key2, aggregated_value2)
- combine(key2, value2_list) -> emit(key2, combined_value2)
- partition(key2) return reducerNo
To analyze the complexity of the algorithm, we need to understand the processing cost, especially the cost of network communication in such a highly distributed system.
Lets first consider the communication between Input data split and Mapper. To minimize this overhead, we need to run the mapper logic at the data split (without moving the data). How well we do this depends on how the input data is stored and whether we can run the mapper code there. For HDFS and Cassandra, we can the mapper at the storage node and the scheduler algorithm of JobTracker will assign the mapper to the data split that it collocates with and hence significantly reduce the data movement. Other data store such as Amazon S3 doesn't allow execution of mapper logic at the storage node and therefore incur more data traffic.
The communication between Mapper and Reducer cannot be collocated because it depends on the emit key. The only mechanism available is the combine() function which can perform a local consolidation and hence can reduce the data sent to the reducer.
Finally the communication between the reducer and the output data store depends on the store's implementation. For HDFS, the data is triply replicated and hence the cost of writing can be high. Cassandra (a NOSQL data store) allows configurable latency with various degree of data consistency trade-off. Fortunately, in most case the volume of result data after a Map/Reduce processing is not high.
Now, we see how to fit various different kinds of algorithms into the Map/Reduce model ...
Map-Only
"Embarrassing parallel" problems are those that the same processing is applied in each data element in a pretty independent way, in other words, there is no need to consolidate or aggregate individual results.
These kinds of problem can be expressed as a Map-only job (by specifying the number of reducers to zero). In this case, Mapper's emitted result will directly go to the output format.
Some examples of map-only examples are ...
- Distributed grep
- Document format conversion
- ETL
- Input data sampling
Sorting
As we described above, Hadoop is fundamentally a distributed sorting engine, so using it for sorting is a natural fit.
For example, we can use an Identity function for both map() and reduce(), then the output is equivalent to sorting the input data. Notice that we are using a single reducer here. So the merge is still sequential although the sorting is done at the mapper in parallel.
We can perform the merge in parallel by using multiple reducers. In this case, output of each reducer are sorted. We may need to do a final merge on all the reducer's output. Another way is to use a customized partition() function such that the keys are partitioned by range. In this case, each reducer is sorting a particular range and the final result is just to concatenate the each reducer's sorted result.
partition(key) {
range = (KEY_MAX - KEY_MIN) / NUM_OF_REDUCERS
reducer_no = (key - KEY_MIN) / range
return reducer_no
}
Inverted Indexes
The map reduce model is originated from Google which has a lot of scenarios of building large scale inverted index. Building an inverted index is about parsing different documents to build a word -> document index for keyword search.
In fact, inverted index is pretty general and can be applied in many scenarios. To build an inverted index, we can feed the mapper each document (or lines within a document). The Mapper will parse the words in the document to emit [word, doc] pairs along with other metadata such as where in the document this word occurs ... etc. The reducer can simply be an identity function that just dump out the list, or it can perform some statistic aggregation per word.
In a more general form of Inverted index, there is a "container" and "element" concept. The Map and Reduce function will be organized in the following patterns.
map(key, container) {
for each element in container {
element_meta =
extract_metadata(element, container)
emit(element, [container_id, element_meta])
}
}
reduce(element, container_ids) {
element_stat =
compute_stat(container_ids)
emit(element, [element_stat, container_ids])
}
In Text index, we are not just counting the actual frequency of the terms but also adjust its weighting based on its frequency distribution so common words will have less significance when they appears in the document. The final value after normalization is called TF-IDF (term frequency times inverse document frequency) and can be computed using Map Reduce as well.
Simple Statistics Computation
Computing max, min, count is very straightforward since this operation is commutative and associative. Each mapper will perform the local computation and send the result to a single reducer to do the final computation.
Combine function is typically used to reduce the network traffic. Notice that the input to the combine function must look the same as the input to the reducer function and the output of the combine function must look the same as the output of the map function. There is also no guarantee that the combiner function will be invoked at all.
Computing avg is done in a similar way except that instead of computing the local avg, we compute the local sum and local count. The reducer will do the final sum divided by the final count to come up with the final avg.class Mapper {
buffer
map(key, number) {
buffer.append(number)
if (buffer.is_full) {
max = compute_max(buffer)
emit(1, max)
}
}
}
class Reducer {
reduce(key, list_of_local_max) {
global_max = 0
for local_max in list_of_local_max {
if local_max > global_max {
global_max = local_max
}
}emit(1, global_max)
}}
class Combiner {
combine(key, list_of_local_max) {
local_max = maximum(list_of_local_max)
emit(1, local_max)
}
}
Computing a histogram is pretty common in statistics and can give a quick idea about the data distribution. A typical approach is to divide the number into different intervals. The mapper will compute the count per interval, and emit that per interval and the reducer will compute the sum of that interval.
class Mapper {
interval_start = [0, 20, 40, 60, 80]
map(key, number) {
i = 0;
while (i < NO_OF_INTERVALS) {
if (number < interval_start[i]) {
emit(i, 1)
break
}
}
}
}
class Reducer {
reduce(interval, counts) {
total_counts = 0
for each count in counts {
total_counts += count
}
emit(interval, total_counts)
}
}
class Combiner {
combine(interval, occurrence) {
emit(interval, occurrence.size)
}
}
In-Mapper Combine
Jimmy Lin, in his excellent book, talks about a technique call "in-mapper combine" which regains control at the application level when the combine takes place. The general idea is to maintain a HashMap to buffer the intermediate result and has a separate logic to determine when to actually emit the data from the buffer. The general code structure is as follows ...
class Mapper {
buffer
init() {
buffer = HashMap.new
}
map(key, data) {
elements = process(data)
for each element {
....
check_and_put(buffer, k2, v2)
}
}
check_and_put(buffer, k2, v2) {
if buffer.full {
for each k2 in buffer.keys {
emit(k2, buffer[k2])
}
}
}
close() {for each k2 in buffer.keys {
emit(k2, buffer[k2])
}}
}
SQL Model
The SQL model can be used to extract data from the data source. It contains a number of primitives.
Projection / Filter
This logic is typically implemented in the Mapper
- result = SELECT c1, c2, c3, c4 FROM source WHERE conditions
This logic is typically implemented in the Reducer
- SELECT sum(c3) as s1, avg(c4) as s2 ... FROM result GROUP BY c1, c2 HAVING conditions
class Mapper {
map(k, rec) {
select_fields =
[rec.c1, rec.c2, rec.c3, rec.c4]
group_fields =
[rec.c1, rec.c2]
if (filter_condition == true) {
emit(group_fields, select_fields)
}
}
}
class Reducer {
reduce(group_fields, list_of_rec) {
s1 = 0
s2 = 0
for each rec in list_of_rec {
s1 += rec.c3
s2 += rec.c4
}
s2 = s2 / rec.size
if (having_condition == true) {
emit(group_fields, [s1, s2])
}
}
}
Data Joins
Joining 2 data set is a very common operation in Relational Data Model and has been very mature in RDBMS implementation. The common join mechanism in a centralized DB architecture is as follows
- Nested loop join -- This is the most basic and naive mechanism and is organized as two loops. The outer loop reads from data set1, the inner loop scan through the whole data set2 and compare with the records just read from data set1.
- Indexed join -- An index (e.g. B-Tree index) is built for one of the data sets (say data set2 which is the smaller one). The join will scan through data set1 and lookup the index to find the matched records of data set2.
- Merge join -- Pre-sort both data sets so they are arranged physically in increasing order. The join is realized by just merging the two data sets. a) Locate the first record in both data set1 & set2, which is their corresponding minimum key b) In the one with a smaller minimum key (say data set1), keep scanning until finding the next key which is bigger than the minimum key of the other data set (ie. data set2), call this the next minimum key of data set1. c) Switch position and repeat the whole thing until one of the data set is exhausted.
- Hash / Partition join -- Partition the data set1 and data set2 into smaller size and apply other join algorithm in a smaller data set size. A linear scan with a hash() function is typically performed to partition the data sets such that data in set1 and data in set2 with the same key will land on the same partition.
- Semi join -- This is mainly used to join two sets of data that is stored at different locations and the goal is to reduce the amount of data transfer such that only the full records appears in the final joint result will be send through. a) Data set2 will send its key set to machine holding Data set1. b) Machine holding Data set1 will do a join and send back the records in Data set1 that matches one of the send-over keys. c) The machine holding data set2 will do a final join to the data send back.
General reducer-side join
This is the most basic one, records from data set1 and set2 with the same key will land on the same reducer, which will then do a cartesian product. The downside of this model is that the reducer need to have enough memory to hold all records of each key.
map(k1, rec) {
emit(rec.key, [rec.type, rec])
}
reduce(k2, list_of_rec) {
list_of_typeA = []
list_of_typeB = []
for each rec in list_of_rec {
if (rec.type == 'A') {
list_of_typeA.append(rec)
} else {
list_of_typeB.append(rec)
}
}
# Compute the catesian product
products = []
for recA in list_of_typeA {
for recB in list_of_typeB {
emit(k2, [recA, recB])
}
}
}
Optimized reducer-side join
You can "secondary sort" the data type for each key by defining a customized partition function. In this model, you arrange the data type (which has less records per key to arrive first) and you only need to store these types.
map(k1, rec) {
emit([rec.key, rec.type], rec])
}
partition(key_pair) {
super.partition(key_pair[0])
}
reduce(k2, list_of_rec) {
list_of_typeA = []
for each rec in list_of_rec {
if (rec.type == 'A') {
list_of_typeA.append(rec)
} else { # receive records of typeA
for recA in list_of_typeA {
emit(k2, [recA, rec])
}
}
}
}
While being very flexible, the downside of Reducer side join is that all data need to be transfer from the mapper to the reducer and then result write to HDFS. Map-side join explore some special arrangement of the input file such that the join is being perform at the mapper. The advantage of doing in the mapper is that we can exploit the collocation of the Map reduce framework such that the mapper will be allocated an input split in its local machine, hence reduce the data transfer from the disk to the mapper. After the map-side join, the result is written directly to the output HDFS files and hence eliminate the data transfer between the mapper and the reducer.
Map-side partition join
In this model, it requires the 2 data sets to be partitioned into 2 sets of partition files (same number of partitions for each set). The size of the partition is such that it can fit into the memory of the Mapper machine. We also need to configure the Map/Reduce job such that there is no split in the partition file, in other words, the whole partition is assigned to a mapper task.
The mapper will detect the partition of the input file and then read the corresponding partition file of the other data set into an in-memory hashtable. After that, the mapper will lookup the Hashtable to do the join.
class Mapper {
map = Hashtable.new
init() {
partition = detect_input_filename()
map = load("hdfs://dataset2/" + partition)
}
map(k1, rec1) {
rec2 = map[rec1.key]
if (rec2 != nil) {
emit(rec1.key, [rec1, rec2])
}
}
}
Map-side partition merge join
In additional, if the partition file is also sorted, then the mapper can use a merge join, which has an even smaller memory footprint.
class Mapper {
rec2_key = nil
next_rec2 = nil
list_of_rec2 = []
file = nil
init() {
partition = detect_input_filename()
file = open("hdfs://dataset2/" + partition, "r")
next_rec2 = file.read()
fill_rec2_list()
}
# Fill up the list of rec2 list which has the same key
fill_rec2_list() {
rec2_key = next_rec2.key
list_of_rec2.append(next_rec2)
next_rec2 = file.read
while(next_rec2.key == key) {
list_of_rec2.append(next_rec2)
}
}
map(k1, rec1) {
while (rec1.key > rec2_key) {
fill_rec2_list()
}while (rec1.key == rec2.key) {
for rec2 in list_of_rec2 {
emit(rec1.key, [rec1, rec2])
}
}}
}
Memcache join
The model is very straightforward, the second data set is loaded into a distributed hash table (like memcache) which has effectively unlimited size. The mapper will receive input split from the first data set and then lookup the memcache for the corresponding record of the other data set.
There are also some other more sophisticated join mechanism such as semi-join described in this paper.
Graph Algorithms
Many problems can be modeled as a graph of Node and Edges. In the Search engine environment, computing the rank of a document using Page Rank or Hits can be model as a sequence of iterations of Map/Reduce jobs.
In the past, I have been blog a number of very basic graph algorithms in map reduce including doing topological sort, finding shortest path, minimum spanning tree etc. and also how to recommend people connection using Map/Reduce.
Due to the fact that graph traversal is inherently sequential, I am not sure Map/Reduce is the best parallel processing model for graph processing. Another problem is that due to the "stateless nature" of map() and reduce() functions, the whole graph need to be transferred between mapper and reducer which incur significant communication costs. Jimmy Lin has described a clever technique called Shimmy which exploit using a special partitioning function which let the reducer to retain the ownership of nodes across map/reduce jobs. I have described this technique as well as a general model of Map/Reduce graph processing in a previous blog.
I think a parallel programming model specific for Graph processing will perform much better. Google's Pregel model is a good example of that.
Machine Learning
Many of the machine learning algorithm involve multiple iterations of parallel processing that fits very well into Map/Reduce model.
For example, we can use map reduce to calculate the statistics for probabilistic methods such as naive Bayes.
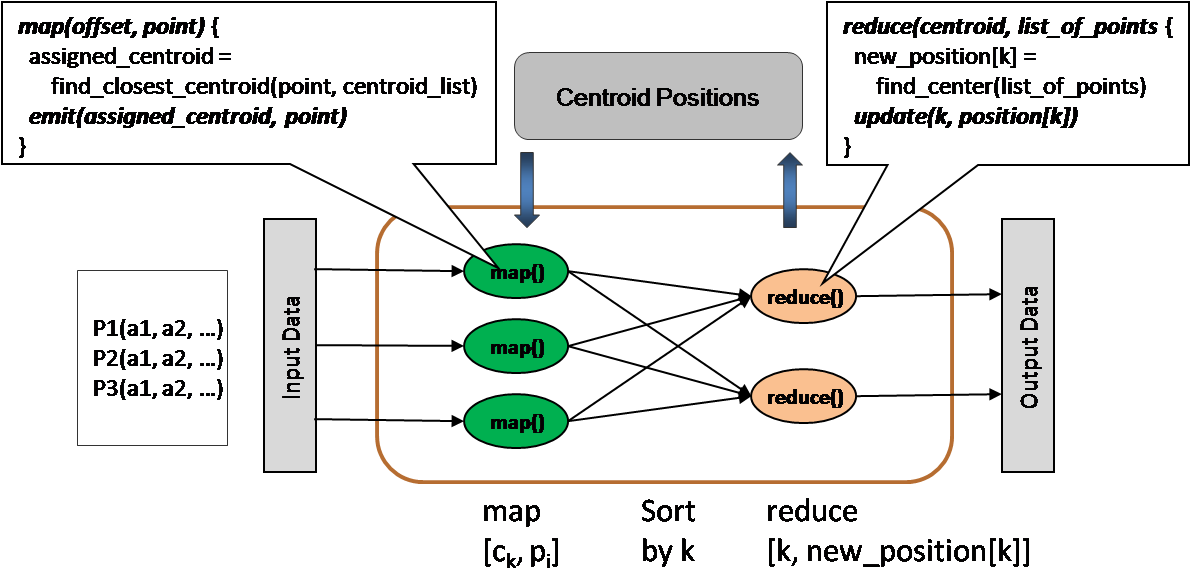
A simple example of computing K-Means cluster can also be done in the following way.
- Input: A set of points, with k initial centrods
- Output: K final centroids
- For each point, assign it to be the member of closest centroid
- Re-compute the centroid from the assigned point members
{kind=link}
For a complete list of Machine learning algorithms and how they can be implemented using the Map/Reduce model, here is a very good paper.
Matrix arithmetic
A lot of real-life relationships can be represented as a Matrix. One example is the vector space model of Information Retrieval where the column represents docs and the row represents terms. Another example is the social network graph where the column as well as the row representing people and a binary value of each cell to represent a "friend" relationship. In this case, M + M.M represents all the people that I can reach within 2 degree.
Processing for dense matrix is very easy to parallelized. But since the sequential version is O(N^3), it is not that interesting for Matrix with large size (millions range in rows and columns).
A lot of real-world graph problem can be represented as sparse matrix. So my interests is to focus more in the processing of sparse matrix. I don't have much to share at this moment but I hope this is something I will blog about in future.