y值开始浮动了,那么loss现在是什么情况呢?
单输出loss,似乎看不出来。
在tensorboard中观察一下
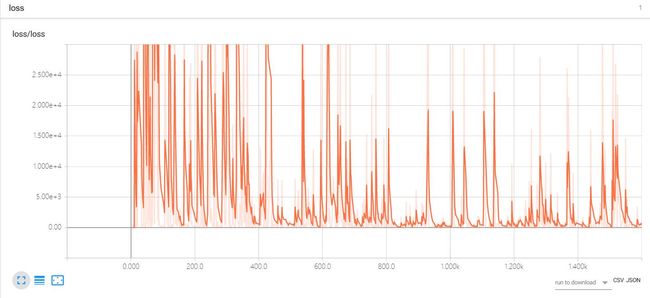
看来基本面是向好的,权重开始学习到东西了。
在修改了GradientDescentOptimizer学习率后发现,loss仅仅也只能下降到那种程度了,batch的增加对loss都没有帮助,还加大了loss的波动。又陷入的困境。
在尝试了tf.nn.sigmoid和tf.nn.tanh之后,发现tf.nn.relu仍是最好的激活函数。
因为追求loss下降,在最开始的测试过程中尝试过小批量梯度下降法(5个)和随机梯度下降法,在这两种梯度下降法中,发现随机梯度下降法能看到比较显著的梯度变化,于是后续的优化中,一直使用了随机梯度下降。当我看到下面一段话后,意识到之前出了loss不下降之外,还存在着loss方差过大的问题。在实现了loss基本面下降后,终于loss在趋于正常的下降了。
随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是 、小批量梯度下降法。
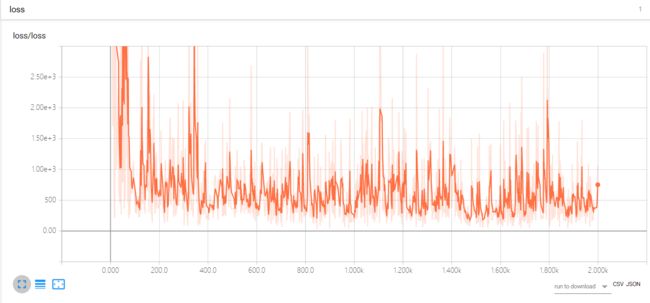
目前代码
import numpy as np
import pandas as pd
import tensorflow as tf
#转为onehot编码
def turn_onehot(df):
for key in df.columns:
oneHot = pd.get_dummies(df[key])
for oneHotKey in oneHot.columns: #防止重名
oneHot = oneHot.rename(columns={oneHotKey : key+'_'+str(oneHotKey)})
df = df.drop(key, axis=1)
df = df.join(oneHot)
return df
#获取一批次的数据
def get_batch(x_date, y_date, batch):
global pointer
x_date_batch = x_date[pointer:pointer+batch]
y_date_batch = y_date[pointer:pointer+batch]
pointer = pointer + batch
return x_date_batch, y_date_batch
#生成layer
def add_layer(input_num, output_num, x, layer, active=None):
with tf.name_scope('layer'+layer+'/W'+layer):
W = tf.Variable(tf.random_normal([input_num, output_num]), name='W'+layer)
tf.summary.histogram('layer'+layer+'/W'+layer, W)
with tf.name_scope('layer'+layer+'/b'+layer):
b = tf.Variable(tf.zeros([1, output_num])+0.1, name='b'+layer)
tf.summary.histogram('layer'+layer+'/b'+layer, b)
with tf.name_scope('layer'+layer+'/l'+layer):
l = active(tf.matmul(x, W)+b) #使用sigmoid激活函数,备用函数还有relu
tf.summary.histogram('layer'+layer+'/l'+layer, l)
return l
hiddenDim = 1000 #隐藏层神经元数
save_file = './train_model.ckpt'
istrain = True
istensorborad = True
pointer = 0
if istrain:
samples = 2000
batch = 10 #每批次的数据输入数量
else:
samples = 550
batch = 1 #每批次的数据输入数量
with tf.name_scope('inputdate-x-y'):
#导入
df = pd.DataFrame(pd.read_csv('GHMX.CSV',header=0))
#产生 y_data 值 (1, n)
y_date = df['number'].values
y_date = y_date.reshape((-1,1))
#产生 x_data 值 (n, 4+12+31+24)
df = df.drop('number', axis=1)
df = turn_onehot(df)
x_data = df.values
###生成神经网络模型
#占位符
with tf.name_scope('inputs'):
x = tf.placeholder("float", shape=[None, 71], name='x_input')
y_ = tf.placeholder("float", shape=[None, 1], name='y_input')
#生成神经网络
l1 = add_layer(71, hiddenDim, x, '1', tf.nn.relu)
#l2 = add_layer(hiddenDim, hiddenDim, l1, '2', tf.nn.relu)
#l3 = add_layer(hiddenDim, hiddenDim, l2, '3', tf.nn.relu)
#l4 = add_layer(hiddenDim, hiddenDim, l3, '4', tf.nn.relu)
#l5 = add_layer(hiddenDim, hiddenDim, l4, '5', tf.nn.relu)
#l6 = add_layer(hiddenDim, hiddenDim, l5, '6', tf.nn.relu)
#l7 = add_layer(hiddenDim, hiddenDim, l6, '7', tf.nn.relu)
#l8 = add_layer(hiddenDim, hiddenDim, l7, '8', tf.nn.relu)
#l9 = add_layer(hiddenDim, hiddenDim, l8, '9', tf.nn.relu)
y = add_layer(hiddenDim, 1, l1, '10', tf.nn.relu)
#计算loss
with tf.name_scope('loss'):
#loss = tf.reduce_mean(tf.reduce_sum(tf.square(y - y_), name='square'), name='loss') #损失函数,损失不下降,换用别的函数
#loss = -tf.reduce_sum(y_*tf.log(y)) #损失仍然不下降
#loss = -tf.reduce_sum(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)) , name='loss')
loss = tf.losses.mean_squared_error(labels=y_, predictions=y)
tf.summary.scalar('loss', loss)
#梯度下降
with tf.name_scope('train_step'):
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) #有效的学习率0.000005
#初始化
init = tf.global_variables_initializer()
sess = tf.Session()
if istensorborad:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('logs/', sess.graph)
sess.run(init)
#保存/读取模型
saver = tf.train.Saver()
if not istrain:
saver.restore(sess, save_file)
for i in range(samples):
x_date_batch, y_date_batch = get_batch(x_data, y_date, batch)
feed_dict = {x: x_date_batch, y_: y_date_batch}
if istrain:
_, loss_value, y_value, y__value = sess.run((train_step, loss, y, y_), feed_dict=feed_dict)
print('y=', y_value, '----ture=', y__value)
print(loss_value)
else:
_, test_assess_value = sess.run((loss, test_assess), feed_dict=feed_dict)
print(test_assess_value)
if istensorborad:
result = sess.run(merged, feed_dict=feed_dict)
writer.add_summary(result,i)
#保存模型
if istrain:
saver.save(sess, save_file)