用户标签(二):增量版ID_Mapping、Oneid图计算打通数据孤岛实现
增量版ID_Mapping、Oneid图计算打通数据孤岛实现
- 1、与上篇文章的区别
-
- 2、主要输入数据样例
- 3、实现代码
- 4、程序运行后输入输出数据样例
- 启动命令
- 辛苦码字如有转载请标明出处谢谢!——拜耳法
- PS:我要在下一章在我心中不完美的你打一个淋漓尽致的标签
-
- 参考链接
1、与上篇文章的区别
单就实现上其实与上篇文章差距不大,主要在业务上本文解决了上篇文
章每次运行都会生成新的oneid的问题,如果每次运行都生成新的oneid那我们给标签做整理标记的时候会找不到人的!

上一篇互联网民工讨债的艰辛旅程,打通数据孤岛第一版
例如:在上篇文中
1月1日 姓名:小白 手机号:9527 生成onid 1111
1月2日 姓名:小白 手机号:9527 生成onid 2222
1月2日 姓名:小黑 手机号:7896 生成onid aaaa
1月3日 姓名:小白 手机号:9527 生成onid 3333
1月3日 姓名:小黑 手机号:7896 生成onid bbbb
本文中
1月1日 姓名:小白 手机号:9527 生成onid 1111
1月2日 姓名:小白 手机号:9527 生成onid 1111
1月2日 姓名:小黑 手机号:7896 生成onid aaaa
1月3日 姓名:小白 手机号:9527 生成onid 1111
1月3日 姓名:小黑 手机号:7896 生成onid aaaa
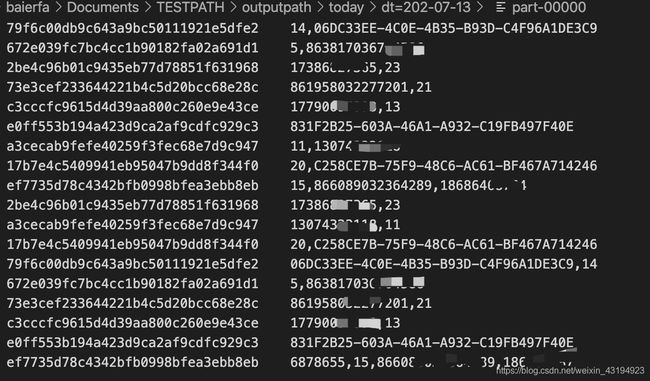
2、主要输入数据样例
前一天输入数据样例

前一天数据输出今日作为数据输入样例
3、实现代码
对于本章没有读懂的建议看一下上一篇
图计算实现ID_Mapping、Oneid打通数据孤岛
import java.util.UUID
import cn.scfl.ebt.util.UtilTool
import org.apache.spark.SparkContext
import org.apache.spark.graphx._
import org.apache.spark.sql.SparkSession
import org.spark_project.jetty.util.StringUtil
/**
* @Author: baierfa
* @version: v1.0
* @description: id_mapping 单天实现暂时不加入多天滚动计算 多天计算需要看另一文件YeAndTodayGraphx
* @Date: 2020-07-05 10:24
*/
object YeAndTodayGraphx {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName(s"${this.getClass.getName}")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
// 昨天数据加载
val todayPath = "D:\\TESTPATH\\inputpath\\today\\dt=202-07-13"
val outPutPath="D:\\TESTPATH\\outtpath\\today\\dt=202-07-13"
val edgeoutPutPath="D:\\TESTPATH\\edgepath\\today\\dt=202-07-13"
val yePath = "D:\\TESTPATH\\inputpath\\today\\dt=202-07-12"
yeAndtodayIdMapping(spark,sc,todayPath,yePath,outPutPath,edgeoutPutPath)
spark.close()
}
/**
* 功能描述: <输入今天数据路径 按照文件形式输出到指定路径中 并推出今日图计算点与边集合总个数>
* 将昨日生成完成图计算后的数据再次按照点 边集合的方式重新录入数据中进行二次图计算关联
* 〈使用今日输入数据转换成唯一数字值 图计算之后再将数值转换回明文 生成唯一uuid〉
* 转换时候防止昨日的数据再次发生uuid重新编辑状况 对已存在的使用昨日的值 对新生成的增量用户使用新增uuid
* @Param: [spark, sc, todayPath, outPutPath, edgeoutPutPath]
* @Return: void
* @Author: baierfa
* @Date: 2020-08-05 10:18
*/
def yeAndtodayIdMapping(spark:SparkSession,sc: SparkContext,todayPath: String,yePath:String,outPutPath:String
,edgeoutPutPath:String )={
// 一、数据加载
// 今天数据加载
val todaydf = spark.read.textFile(todayPath)
val yedf = spark.read.textFile(yePath)
// 二、汇总数据集合并生成点集合
// 生成昨日数据的点集合
val ye_veritx = yedf.rdd.flatMap(line => {
val field = line.split("\t")(1).split(",")
for (ele <- field if StringUtil.isNotBlank(ele)&&(!"\\N".equals(ele))) yield (UtilTool.getMD5(ele), ele)
})
// 生成昨日数据的边集合
val ye_edges = yedf.rdd.flatMap(line => {
val field = line.split("\t")(1).split(",")
for (i <- 0 to field.length - 2 if StringUtil.isNotBlank(field(i))&&(!"\\N".equals(field(i)))
; j <- i + 1 to field.length - 1 if StringUtil.isNotBlank(field(j))&&(!"\\N".equals(field(j)))) yield Edge(UtilTool.getMD5(field(i)), UtilTool.getMD5(field(j)), "")
})
// 生成今日点集合
val to_veritx = todaydf.rdd.flatMap(line => {
val field = line.split("\t")
for (ele <- field if StringUtil.isNotBlank(ele)&&(!"\\N".equals(ele))) yield (UtilTool.getMD5(ele), ele)
})
// 生成今日边集合
val to_edges = todaydf.rdd.flatMap(line => {
val field = line.split("\t")
for (i <- 0 to field.length - 2 if StringUtil.isNotBlank(field(i))&&(!"\\N".equals(field(i)))
; j <- i + 1 to field.length - 1 if StringUtil.isNotBlank(field(j))&&(!"\\N".equals(field(j)))) yield Edge(UtilTool.getMD5(field(i)), UtilTool.getMD5(field(j)), "")
})
// .map(edge => (edge, 1))
// .reduceByKey(_ + _)
// .filter(tp => tp._2 > 2)
// .map(tp => tp._1)
// 三、汇总各个节点使用图计算生成图
val veritx = ye_veritx.union(to_veritx)
val edges = ye_edges.union(to_edges)
val uu = veritx.map(lin=>("vertices",1)).union(edges.map(lin=>("edges",1))).reduceByKey(_ + _)
.map(tp=>tp._1+"\t"+tp._2)
val graph = Graph(veritx, edges)
// 四、生成最大连通图
val graph2 = graph.connectedComponents()
val vertices = graph2.vertices
// 五、将最小guid替换成uuid
val uidRdd = vertices.map(tp => (tp._2, tp._1))
.groupByKey()
.map(tp => (StringUtil.replace(UUID.randomUUID().toString, "-", ""), tp._2))
// 对比昨天已经存在的Guid数据进行替换
val ye_veritx_map = yedf.rdd.flatMap(line => {
val field = line.split("\t")(1).split(",")
for (ele <- field if StringUtil.isNotBlank(ele)&&(!"\\N".equals(ele))) yield (UtilTool.getMD5(ele), line.split("\t")(0))
})
// 汇总到到一起后按照广播变量广播出去
val bc_yeguid_uidmap = sc.broadcast(ye_veritx_map.collectAsMap())
// 区别=============================================
// 对比昨天存在的数据 今天需要继续使用昨天的guid 也就是uuid
val rep_uid_rdd = uidRdd.mapPartitions(itemap => {
val vertbc_yeguid_uidmap = bc_yeguid_uidmap.value
itemap.map(tp => {
var tmpguid = tp._1
var mayiste = false
// 需要先遍历今天出现的value集合 与昨天的对比
for (ele <- tp._2 if !mayiste) {
// 如果昨天出现过当前值得集合 出现一个后立即替换掉今天生成
if (vertbc_yeguid_uidmap.get(ele).isDefined) {
tmpguid = vertbc_yeguid_uidmap.get(ele).get
mayiste = true
}
}
// 返回昨天存在过得Guid
(tmpguid, tp._2)
})
})
// 区别=====================================
// 将现有的数据转换成铭文识别后展示
// 将各个点的数据汇总到driver端
val idmpMap = veritx.collectAsMap()
// 按照map方式广播出去做转换
val bc = sc.broadcast(idmpMap)
val ss = rep_uid_rdd.mapPartitions(itemap => {
val vert_id_map = bc.value
itemap.map(tp => {
val t2 = for (ele <- tp._2) yield vert_id_map.get(ele).get
tp._1+"\t"+t2.mkString(",")
})
})
ss.saveAsTextFile(outPutPath)
uu.saveAsTextFile(edgeoutPutPath)
}
}
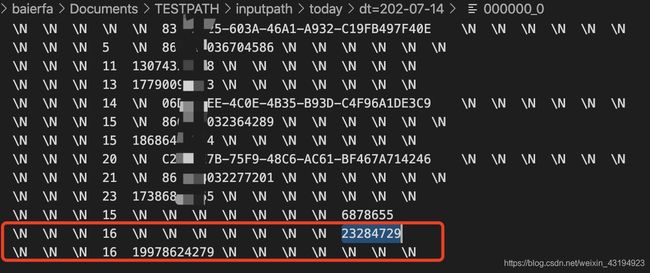
4、程序运行后输入输出数据样例
新输入的当日数据
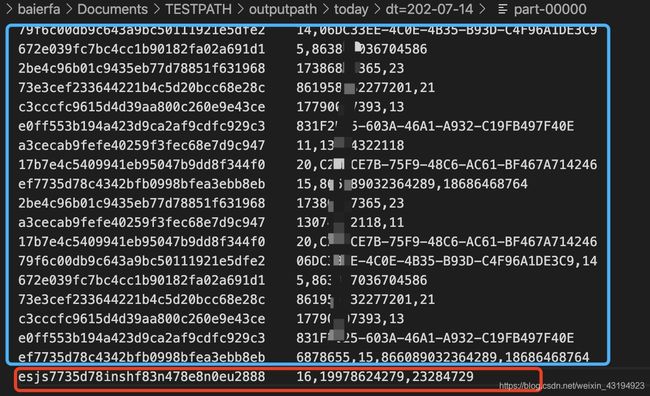
输出新的当日数据历史oneid不更换,新增数据增加oneid
启动命令
spark-submit \
--class classname \
--master yarn \
--deploy-mode cluster \
--num-executors 40 \
--driver-memory 8g \
--executor-memory 6g \
--executor-cores 3 \
--conf spark.default.parallelism=400 \
--conf spark.shuffle.memoryFraction=0.3 \
ID_Mapping_Spark.jar \
hdfs://user/hive/oneid_data_origindata_di/dt=2020-07-06 \
hdfs://user/hive/oneid_data_sink_id_mapping/dt=2020-07-06 \
hdfs://user/hive/oneid_data_sink_edge_vertex/dt=2020-07-06 \
hdfs://user/hive/oneid_data_sink_id_mapping/dt=2020-07-05
辛苦码字如有转载请标明出处谢谢!——拜耳法
都看到这里了非常感谢!
本片章暂未完结 有疑问请+vx :baierfa
PS:我要在下一章在我心中不完美的你打一个淋漓尽致的标签
将大神挂在那片白云下: oneid与用户标签之间的相互打通 实现用户标签
参考链接
链接: 用户标签(一):图计算实现ID_Mapping、Oneid打通数据孤岛.
链接: 用户标签(二):增量版ID_Mapping、Oneid图计算打通数据孤岛实现.
链接: 用户标签(三):oneid与用户标签之间的相互打通 实现用户标签.
链接: 用户标签(四):MD5代替Hashcode生成唯一数字编码.