转载: http://matt33.com/2018/03/18/kafka-server-handle-produce-request/
[TOC]
produce 请求处理整体流程
在 Producer Client 端,Producer 会维护一个 ConcurrentMap
Producer Client 发送请求的方法实现如下:
//NOTE: 发送 produce 请求
private void sendProduceRequest(long now, int destination, short acks, int timeout, List batches) {
Map produceRecordsByPartition = new HashMap<>(batches.size());
final Map recordsByPartition = new HashMap<>(batches.size());
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records());
recordsByPartition.put(tp, batch);
}
ProduceRequest.Builder requestBuilder =
new ProduceRequest.Builder(acks, timeout, produceRecordsByPartition);
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
在发送 Produce 的请求里,Client 是把一个 Map
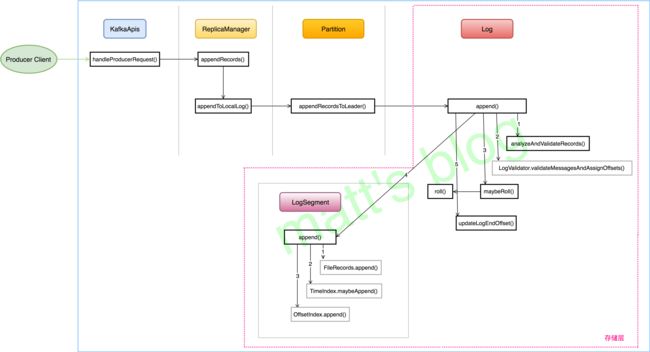
Server 端处理 produce 请求的总体过程
Broker 在收到 Produce 请求后,会有一个 KafkaApis 进行处理,KafkaApis 是 Server 端处理所有请求的入口,它会负责将请求的具体处理交给相应的组件进行处理,从上图可以看到 Produce 请求是交给了 ReplicaManager 对象进行处理了。
Server 端处理
Server 端的处理过程会按照上图的流程一块一块去介绍。
KafkaApis 处理 Produce 请求
KafkaApis 处理 produce 请求是在 handleProducerRequest() 方法中完成,具体实现如下:
/**
* Handle a produce request
*/
def handleProducerRequest(request: RequestChannel.Request) {
val produceRequest = request.body.asInstanceOf[ProduceRequest]
val numBytesAppended = request.header.sizeOf + produceRequest.sizeOf
//note: 按 exist 和有 Describe 权限进行筛选
val (existingAndAuthorizedForDescribeTopics, nonExistingOrUnauthorizedForDescribeTopics) = produceRequest.partitionRecords.asScala.partition {
case (topicPartition, _) => authorize(request.session, Describe, new Resource(auth.Topic, topicPartition.topic)) && metadataCache.contains(topicPartition.topic)
}
//note: 判断有没有 Write 权限
val (authorizedRequestInfo, unauthorizedForWriteRequestInfo) = existingAndAuthorizedForDescribeTopics.partition {
case (topicPartition, _) => authorize(request.session, Write, new Resource(auth.Topic, topicPartition.topic))
}
// the callback for sending a produce response
//note: 回调函数
def sendResponseCallback(responseStatus: Map[TopicPartition, PartitionResponse]) {
val mergedResponseStatus = responseStatus ++
unauthorizedForWriteRequestInfo.mapValues(_ => new PartitionResponse(Errors.TOPIC_AUTHORIZATION_FAILED)) ++
nonExistingOrUnauthorizedForDescribeTopics.mapValues(_ => new PartitionResponse(Errors.UNKNOWN_TOPIC_OR_PARTITION))
var errorInResponse = false
mergedResponseStatus.foreach { case (topicPartition, status) =>
if (status.error != Errors.NONE) {
errorInResponse = true
debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format(
request.header.correlationId,
request.header.clientId,
topicPartition,
status.error.exceptionName))
}
}
def produceResponseCallback(delayTimeMs: Int) {
if (produceRequest.acks == 0) {
// no operation needed if producer request.required.acks = 0; however, if there is any error in handling
// the request, since no response is expected by the producer, the server will close socket server so that
// the producer client will know that some error has happened and will refresh its metadata
//note: 因为设置的 ack=0, 相当于 client 会默认发送成功了,如果 server 在处理的过程出现了错误,那么就会关闭 socket 连接来间接地通知 client
//note: client 会重新刷新 meta,重新建立相应的连接
if (errorInResponse) {
val exceptionsSummary = mergedResponseStatus.map { case (topicPartition, status) =>
topicPartition -> status.error.exceptionName
}.mkString(", ")
info(
s"Closing connection due to error during produce request with correlation id ${request.header.correlationId} " +
s"from client id ${request.header.clientId} with ack=0\n" +
s"Topic and partition to exceptions: $exceptionsSummary"
)
requestChannel.closeConnection(request.processor, request)
} else {
requestChannel.noOperation(request.processor, request)
}
} else {
val respBody = request.header.apiVersion match {
case 0 => new ProduceResponse(mergedResponseStatus.asJava)
case version@(1 | 2) => new ProduceResponse(mergedResponseStatus.asJava, delayTimeMs, version)
// This case shouldn't happen unless a new version of ProducerRequest is added without
// updating this part of the code to handle it properly.
case version => throw new IllegalArgumentException(s"Version `$version` of ProduceRequest is not handled. Code must be updated.")
}
requestChannel.sendResponse(new RequestChannel.Response(request, respBody))
}
}
// When this callback is triggered, the remote API call has completed
request.apiRemoteCompleteTimeMs = time.milliseconds
quotas.produce.recordAndMaybeThrottle(
request.session.sanitizedUser,
request.header.clientId,
numBytesAppended,
produceResponseCallback)
}
if (authorizedRequestInfo.isEmpty)
sendResponseCallback(Map.empty)
else {
val internalTopicsAllowed = request.header.clientId == AdminUtils.AdminClientId
// call the replica manager to append messages to the replicas
//note: 追加 Record
replicaManager.appendRecords(
produceRequest.timeout.toLong,
produceRequest.acks,
internalTopicsAllowed,
authorizedRequestInfo,
sendResponseCallback)
// if the request is put into the purgatory, it will have a held reference
// and hence cannot be garbage collected; hence we clear its data here in
// order to let GC re-claim its memory since it is already appended to log
produceRequest.clearPartitionRecords()
}
}
总体来说,处理过程是(在权限系统的情况下):
- 查看 topic 是否存在,以及 client 是否有相应的 Desribe 权限;
- 对于已经有 Describe 权限的 topic 查看是否有 Write 权限;
- 调用 replicaManager.appendRecords() 方法向有 Write 权限的 topic-partition 追加相应的 record。
ReplicaManager
ReplicaManager 顾名思义,它就是副本管理器,副本管理器的作用是管理这台 broker 上的所有副本(replica)。在 Kafka 中,每个副本(replica)都会跟日志实例(Log 对象)一一对应,一个副本会对应一个 Log 对象。
Kafka Server 在启动的时候,会创建 ReplicaManager 对象,如下所示。在 ReplicaManager 的构造方法中,它需要 LogManager 作为成员变量。
//kafka.server.KafkaServer
def startup() {
try {
info("starting")
/* start replica manager */
replicaManager = new ReplicaManager(config, metrics, time, zkUtils, kafkaScheduler, logManager, isShuttingDown, quotaManagers.follower)
replicaManager.startup()
}catch {
case e: Throwable =>
fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e)
isStartingUp.set(false)
shutdown()
throw e
}
}
ReplicaManager 的并不负责具体的日志创建,它只是管理 Broker 上的所有分区(也就是图中下一步的那个 Partition 对象)。在创建 Partition 对象时,它需要 ReplicaManager 的 logManager 对象,Partition 会通过这个 logManager 对象为每个 replica 创建对应的日志。
/**
* Data structure that represents a topic partition. The leader maintains the AR, ISR, CUR, RAR
*/
class Partition(val topic: String,
val partitionId: Int,
time: Time,
replicaManager: ReplicaManager) extends Logging with KafkaMetricsGroup {
val topicPartition = new TopicPartition(topic, partitionId)
private val localBrokerId = replicaManager.config.brokerId
private val logManager = replicaManager.logManager //note: 日志管理器
}
ReplicaManager 与 LogManger 对比如下:
| 管理对象 | 组成部分 | |
|---|---|---|
| 日志管理器(LogManager) | 日志(Log) | 日志分段(LogSegment) |
| 副本管理器(ReplicaManager) | 分区(Partition) | 副本(Replica) |
appendRecords() 实现
下面我们来看 appendRecords() 方法的具体实现。
//note: 向 partition 的 leader 写入数据
def appendRecords(timeout: Long,
requiredAcks: Short,
internalTopicsAllowed: Boolean,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
responseCallback: Map[TopicPartition, PartitionResponse] => Unit) {
if (isValidRequiredAcks(requiredAcks)) { //note: acks 设置有效
val sTime = time.milliseconds
//note: 向本地的副本 log 追加数据
val localProduceResults = appendToLocalLog(internalTopicsAllowed, entriesPerPartition, requiredAcks)
debug("Produce to local log in %d ms".format(time.milliseconds - sTime))
val produceStatus = localProduceResults.map { case (topicPartition, result) =>
topicPartition ->
ProducePartitionStatus(
result.info.lastOffset + 1, // required offset
new PartitionResponse(result.error, result.info.firstOffset, result.info.logAppendTime)) // response status
}
if (delayedRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)) {
//note: 处理 ack=-1 的情况,需要等到 isr 的 follower 都写入成功的话,才能返回最后结果
// create delayed produce operation
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
//note: 延迟 produce 请求
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback)
// create a list of (topic, partition) pairs to use as keys for this delayed produce operation
val producerRequestKeys = entriesPerPartition.keys.map(new TopicPartitionOperationKey(_)).toSeq
// try to complete the request immediately, otherwise put it into the purgatory
// this is because while the delayed produce operation is being created, new
// requests may arrive and hence make this operation completable.
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
} else {
// we can respond immediately
//note: 通过回调函数直接返回结果
val produceResponseStatus = produceStatus.mapValues(status => status.responseStatus)
responseCallback(produceResponseStatus)
}
} else {
// If required.acks is outside accepted range, something is wrong with the client
// Just return an error and don't handle the request at all
//note: 返回 INVALID_REQUIRED_ACKS 错误
val responseStatus = entriesPerPartition.map { case (topicPartition, _) =>
topicPartition -> new PartitionResponse(Errors.INVALID_REQUIRED_ACKS,
LogAppendInfo.UnknownLogAppendInfo.firstOffset, Record.NO_TIMESTAMP)
}
responseCallback(responseStatus)
}
}
从上面的实现来看,appendRecords() 的实现主要分为以下几步:
- 首先判断 acks 设置是否有效(-1,0,1三个值有效),无效的话直接返回异常,不再处理;
- acks 设置有效的话,调用 appendToLocalLog() 方法将 records 追加到本地对应的 log 对象中;
- appendToLocalLog() 处理完后,如果发现 clients 设置的 acks=-1,即需要 isr 的其他的副本同步完成才能返回 response,那么就会创建一个 DelayedProduce 对象,等待 isr 的其他副本进行同步,否则的话直接返回追加的结果。
appendToLocalLog() 的实现
追加日志的实际操作是在 appendToLocalLog() 中完成的,这里看下它的具体实现:
/**
* Append the messages to the local replica logs
*/
//note: 向本地的 replica 写入数据
private def appendToLocalLog(internalTopicsAllowed: Boolean,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {
trace("Append [%s] to local log ".format(entriesPerPartition))
entriesPerPartition.map { case (topicPartition, records) => //note: 遍历要写的所有 topic-partition
BrokerTopicStats.getBrokerTopicStats(topicPartition.topic).totalProduceRequestRate.mark()
BrokerTopicStats.getBrokerAllTopicsStats().totalProduceRequestRate.mark()
// reject appending to internal topics if it is not allowed
//note: 不能向 kafka 内部使用的 topic 追加数据
if (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {
(topicPartition, LogAppendResult(
LogAppendInfo.UnknownLogAppendInfo,
Some(new InvalidTopicException(s"Cannot append to internal topic ${topicPartition.topic}"))))
} else {
try {
//note: 查找对应的 Partition,并向分区对应的副本写入数据文件
val partitionOpt = getPartition(topicPartition) //note: 获取 topic-partition 的 Partition 对象
val info = partitionOpt match {
case Some(partition) =>
partition.appendRecordsToLeader(records, requiredAcks) //note: 如果找到了这个对象,就开始追加日志
case None => throw new UnknownTopicOrPartitionException("Partition %s doesn't exist on %d"
.format(topicPartition, localBrokerId)) //note: 没有找到的话,返回异常
}
//note: 追加的 msg 数
val numAppendedMessages =
if (info.firstOffset == -1L || info.lastOffset == -1L)
0
else
info.lastOffset - info.firstOffset + 1
// update stats for successfully appended bytes and messages as bytesInRate and messageInRate
//note: 更新 metrics
BrokerTopicStats.getBrokerTopicStats(topicPartition.topic).bytesInRate.mark(records.sizeInBytes)
BrokerTopicStats.getBrokerAllTopicsStats.bytesInRate.mark(records.sizeInBytes)
BrokerTopicStats.getBrokerTopicStats(topicPartition.topic).messagesInRate.mark(numAppendedMessages)
BrokerTopicStats.getBrokerAllTopicsStats.messagesInRate.mark(numAppendedMessages)
trace("%d bytes written to log %s-%d beginning at offset %d and ending at offset %d"
.format(records.sizeInBytes, topicPartition.topic, topicPartition.partition, info.firstOffset, info.lastOffset))
(topicPartition, LogAppendResult(info))
} catch { //note: 处理追加过程中出现的异常
// NOTE: Failed produce requests metric is not incremented for known exceptions
// it is supposed to indicate un-expected failures of a broker in handling a produce request
case e: KafkaStorageException =>
fatal("Halting due to unrecoverable I/O error while handling produce request: ", e)
Runtime.getRuntime.halt(1)
(topicPartition, null)
case e@ (_: UnknownTopicOrPartitionException |
_: NotLeaderForPartitionException |
_: RecordTooLargeException |
_: RecordBatchTooLargeException |
_: CorruptRecordException |
_: InvalidTimestampException) =>
(topicPartition, LogAppendResult(LogAppendInfo.UnknownLogAppendInfo, Some(e)))
case t: Throwable =>
BrokerTopicStats.getBrokerTopicStats(topicPartition.topic).failedProduceRequestRate.mark()
BrokerTopicStats.getBrokerAllTopicsStats.failedProduceRequestRate.mark()
error("Error processing append operation on partition %s".format(topicPartition), t)
(topicPartition, LogAppendResult(LogAppendInfo.UnknownLogAppendInfo, Some(t)))
}
}
}
}
从上面可以看到 appendToLocalLog() 的实现如下:
- 首先判断要写的 topic 是不是 Kafka 内置的 topic,内置的 topic 是不允许 Producer 写入的;
- 先查找 topic-partition 对应的 Partition 对象,如果在 allPartitions 中查找到了对应的 partition,那么直接调用 partition.appendRecordsToLeader() 方法追加相应的 records,否则会向 client 抛出异常。
Partition.appendRecordsToLeader() 方法
ReplicaManager 在追加 records 时,调用的是 Partition 的 appendRecordsToLeader() 方法,其具体的实现如下:
def appendRecordsToLeader(records: MemoryRecords, requiredAcks: Int = 0) = {
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderReplicaIfLocal match {
case Some(leaderReplica) =>
val log = leaderReplica.log.get //note: 获取对应的 Log 对象
val minIsr = log.config.minInSyncReplicas
val inSyncSize = inSyncReplicas.size
// Avoid writing to leader if there are not enough insync replicas to make it safe
//note: 如果 ack 设置为-1, isr 数小于设置的 min.isr 时,就会向 producer 抛出相应的异常
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException("Number of insync replicas for partition %s is [%d], below required minimum [%d]"
.format(topicPartition, inSyncSize, minIsr))
}
//note: 向副本对应的 log 追加响应的数据
val info = log.append(records, assignOffsets = true)
// probably unblock some follower fetch requests since log end offset has been updated
replicaManager.tryCompleteDelayedFetch(TopicPartitionOperationKey(this.topic, this.partitionId))
// we may need to increment high watermark since ISR could be down to 1
//note: 判断是否需要增加 HHW(追加日志后会进行一次判断)
(info, maybeIncrementLeaderHW(leaderReplica))
case None =>
//note: leader 不在本台机器上
throw new NotLeaderForPartitionException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}
// some delayed operations may be unblocked after HW changed
if (leaderHWIncremented)
tryCompleteDelayedRequests()
info
}
在这个方法里,会根据 topic 的 min.isrs 配置以及当前这个 partition 的 isr 情况判断是否可以写入,如果不满足条件,就会抛出 NotEnoughReplicasException 的异常,如果满足条件,就会调用 log.append() 向 replica 追加日志。
存储层
跟着最开始图中的流程及代码分析,走到这里,才算是到了 Kafka 的存储层部分,在这里会详细讲述在存储层 Kafka 如何写入日志。
Log 对象
在上面有过一些介绍,每个 replica 会对应一个 log 对象,log 对象是管理当前分区的一个单位,它会包含这个分区的所有 segment 文件(包括对应的 offset 索引和时间戳索引文件),它会提供一些增删查的方法。
在 Log 对象的初始化时,有三个变量是比较重要的:
- nextOffsetMetadata:可以叫做下一个偏移量元数据,它包括 activeSegment 的下一条消息的偏移量,该 activeSegment 的基准偏移量及日志分段的大小;
- activeSegment:指的是该 Log 管理的 segments 中那个最新的 segment(这里叫做活跃的 segment),一个 Log 中只会有一个活跃的 segment,其他的 segment 都已经被持久化到磁盘了;
- logEndOffset:表示下一条消息的 offset,它取自 nextOffsetMetadata 的 offset,实际上就是活动日志分段的下一个偏移量。
//note: nextOffsetMetadata 声明为 volatile,如果该值被修改,其他使用此变量的线程就可以立刻见到变化后的值,在生产和消费都会使用到这个值
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
/* Calculate the offset of the next message */
//note: 下一个偏移量元数据
//note: 第一个参数:下一条消息的偏移量;第二个参数:日志分段的基准偏移量;第三个参数:日志分段大小
nextOffsetMetadata = new LogOffsetMetadata(activeSegment.nextOffset(), activeSegment.baseOffset, activeSegment.size.toInt)
/**
* The active segment that is currently taking appends
*/
//note: 任何时刻,只会有一个活动的日志分段
def activeSegment = segments.lastEntry.getValue
/**
* The offset of the next message that will be appended to the log
*/
//note: 下一条消息的 offset,从 nextOffsetMetadata 中获取的
def logEndOffset: Long = nextOffsetMetadata.messageOffset
日志写入
在 Log 中一个重要的方法就是日志的写入方法,下面来看下这个方法的实现。
/**
* Append this message set to the active segment of the log, rolling over to a fresh segment if necessary.
*
* This method will generally be responsible for assigning offsets to the messages,
* however if the assignOffsets=false flag is passed we will only check that the existing offsets are valid.
*
* @param records The log records to append
* @param assignOffsets Should the log assign offsets to this message set or blindly apply what it is given
* @throws KafkaStorageException If the append fails due to an I/O error.
* @return Information about the appended messages including the first and last offset.
*/
//note: 向 active segment 追加 log,必要的情况下,滚动创建新的 segment
def append(records: MemoryRecords, assignOffsets: Boolean = true): LogAppendInfo = {
val appendInfo = analyzeAndValidateRecords(records) //note: 返回这批消息的该要信息,并对这批 msg 进行校验
// if we have any valid messages, append them to the log
if (appendInfo.shallowCount == 0)
return appendInfo
// trim any invalid bytes or partial messages before appending it to the on-disk log
//note: 删除这批消息中无效的消息
var validRecords = trimInvalidBytes(records, appendInfo)
try {
// they are valid, insert them in the log
lock synchronized {
if (assignOffsets) {
// assign offsets to the message set
//note: 计算这个消息集起始 offset,对 offset 的操作是一个原子操作
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = offset.value //note: 作为消息集的第一个 offset
val now = time.milliseconds //note: 设置的时间错以 server 收到的时间戳为准
//note: 验证消息,并为没条 record 设置相应的 offset 和 timestrap
val validateAndOffsetAssignResult = try {
LogValidator.validateMessagesAndAssignOffsets(validRecords,
offset,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.messageFormatVersion,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs)
} catch {
case e: IOException => throw new KafkaException("Error in validating messages while appending to log '%s'".format(name), e)
}
//note: 返回已经计算好 offset 和 timestrap 的 MemoryRecords
validRecords = validateAndOffsetAssignResult.validatedRecords
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1 //note: 最后一条消息的 offset
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
appendInfo.logAppendTime = now
// re-validate message sizes if there's a possibility that they have changed (due to re-compression or message
// format conversion)
//note: 更新 metrics 的记录
if (validateAndOffsetAssignResult.messageSizeMaybeChanged) {
for (logEntry <- validRecords.shallowEntries.asScala) {
if (logEntry.sizeInBytes > config.maxMessageSize) {
// we record the original message set size instead of the trimmed size
// to be consistent with pre-compression bytesRejectedRate recording
BrokerTopicStats.getBrokerTopicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
BrokerTopicStats.getBrokerAllTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException("Message size is %d bytes which exceeds the maximum configured message size of %d."
.format(logEntry.sizeInBytes, config.maxMessageSize))
}
}
}
} else {
// we are taking the offsets we are given
if (!appendInfo.offsetsMonotonic || appendInfo.firstOffset < nextOffsetMetadata.messageOffset)
throw new IllegalArgumentException("Out of order offsets found in " + records.deepEntries.asScala.map(_.offset))
}
// check messages set size may be exceed config.segmentSize
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException("Message set size is %d bytes which exceeds the maximum configured segment size of %d."
.format(validRecords.sizeInBytes, config.segmentSize))
}
// maybe roll the log if this segment is full
//note: 如果当前 segment 满了,就需要重新新建一个 segment
val segment = maybeRoll(messagesSize = validRecords.sizeInBytes,
maxTimestampInMessages = appendInfo.maxTimestamp,
maxOffsetInMessages = appendInfo.lastOffset)
// now append to the log
//note: 追加消息到当前 segment
segment.append(firstOffset = appendInfo.firstOffset,
largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// increment the log end offset
//note: 修改最新的 next_offset
updateLogEndOffset(appendInfo.lastOffset + 1)
trace("Appended message set to log %s with first offset: %d, next offset: %d, and messages: %s"
.format(this.name, appendInfo.firstOffset, nextOffsetMetadata.messageOffset, validRecords))
if (unflushedMessages >= config.flushInterval)//note: 满足条件的话,刷新磁盘
flush()
appendInfo
}
} catch {
case e: IOException => throw new KafkaStorageException("I/O exception in append to log '%s'".format(name), e)
}
}
Server 将每个分区的消息追加到日志中时,是以 segment 为单位的,当 segment 的大小到达阈值大小之后,会滚动新建一个日志分段(segment)保存新的消息,而分区的消息总是追加到最新的日志分段(也就是 activeSegment)中。每个日志分段都会有一个基准偏移量(segmentBaseOffset,或者叫做 baseOffset),这个基准偏移量就是分区级别的绝对偏移量,而且这个值在日志分段是固定的。有了这个基准偏移量,就可以计算出来每条消息在分区中的绝对偏移量,最后把数据以及对应的绝对偏移量写到日志文件中。append() 方法的过程可以总结如下:
- analyzeAndValidateRecords():对这批要写入的消息进行检测,主要是检查消息的大小及 crc 校验;
- trimInvalidBytes():会将这批消息中无效的消息删除,返回一个都是有效消息的 MemoryRecords;
- LogValidator.validateMessagesAndAssignOffsets():为每条消息设置相应的 offset(绝对偏移量) 和 timestrap;
- maybeRoll():判断是否需要新建一个 segment 的,如果当前的 segment 放不下这批消息的话,需要新建一个 segment;
- segment.append():向 segment 中添加消息;
- 更新 logEndOffset 和判断是否需要刷新磁盘(如果需要的话,调用 flush() 方法刷到磁盘)。
关于 timestrap 的设置,这里也顺便介绍一下,在新版的 Kafka 中,每条 msg 都会有一个对应的时间戳记录,producer 端可以设置这个字段 message.timestamp.type 来选择 timestrap 的类型,默认是按照创建时间,只能选择从下面的选择中二选一:
- CreateTime,默认值;
- LogAppendTime。
日志分段
在 Log 的 append() 方法中,会调用 maybeRoll() 方法来判断是否需要进行相应日志分段操作,其具体实现如下:
/**
* Roll the log over to a new empty log segment if necessary.
*
* @param messagesSize The messages set size in bytes
* @param maxTimestampInMessages The maximum timestamp in the messages.
* logSegment will be rolled if one of the following conditions met
*
* - The logSegment is full
*
- The maxTime has elapsed since the timestamp of first message in the segment (or since the create time if
* the first message does not have a timestamp)
*
- The index is full
*
* @return The currently active segment after (perhaps) rolling to a new segment
*/
//note: 判断是否需要创建日志分段,如果不需要返回当前分段,需要的话,返回新创建的日志分段
private def maybeRoll(messagesSize: Int, maxTimestampInMessages: Long, maxOffsetInMessages: Long): LogSegment = {
val segment = activeSegment //note: 对活跃的日志分段进行判断,它也是最新的一个日志分段
val now = time.milliseconds
//note: 距离上次日志分段的时间是否达到了设置的阈值(log.roll.hours)
val reachedRollMs = segment.timeWaitedForRoll(now, maxTimestampInMessages) > config.segmentMs - segment.rollJitterMs
//note: 这是五个条件: 1. 文件满了,不足以放心这么大的 messageSet; 2. 文件有数据,并且到分段的时间阈值; 3. 索引文件满了;
//note: 4. 时间索引文件满了; 5. 最大的 offset,其相对偏移量超过了正整数的阈值
if (segment.size > config.segmentSize - messagesSize ||
(segment.size > 0 && reachedRollMs) ||
segment.index.isFull || segment.timeIndex.isFull || !segment.canConvertToRelativeOffset(maxOffsetInMessages)) {
debug(s"Rolling new log segment in $name (log_size = ${segment.size}/${config.segmentSize}}, " +
s"index_size = ${segment.index.entries}/${segment.index.maxEntries}, " +
s"time_index_size = ${segment.timeIndex.entries}/${segment.timeIndex.maxEntries}, " +
s"inactive_time_ms = ${segment.timeWaitedForRoll(now, maxTimestampInMessages)}/${config.segmentMs - segment.rollJitterMs}).")
roll(maxOffsetInMessages - Integer.MAX_VALUE) //note: 创建新的日志分段
} else {
segment //note: 使用当前的日志分段
}
}
从 maybeRoll() 的实现可以看到,是否需要创建新的日志分段,有下面几种情况:
- 当前日志分段的大小加上消息的大小超过了日志分段的阈值(log.segment.bytes);
- 距离上次创建日志分段的时间达到了一定的阈值(log.roll.hours),并且数据文件有数据;
- 索引文件满了;
- 时间索引文件满了;
- 最大的 offset,其相对偏移量超过了正整数的阈值。
如果上面的其中一个条件,就会创建新的 segment 文件,见 roll() 方法实现:
/**
* Roll the log over to a new active segment starting with the current logEndOffset.
* This will trim the index to the exact size of the number of entries it currently contains.
*
* @return The newly rolled segment
*/
//note: 滚动创建日志,并添加到日志管理的映射表中
def roll(expectedNextOffset: Long = 0): LogSegment = {
val start = time.nanoseconds
lock synchronized {
val newOffset = Math.max(expectedNextOffset, logEndOffset) //note: 选择最新的 offset 作为基准偏移量
val logFile = logFilename(dir, newOffset) //note: 创建数据文件
val indexFile = indexFilename(dir, newOffset) //note: 创建 offset 索引文件
val timeIndexFile = timeIndexFilename(dir, newOffset) //note: 创建 time 索引文件
for(file <- List(logFile, indexFile, timeIndexFile); if file.exists) {
warn("Newly rolled segment file " + file.getName + " already exists; deleting it first")
file.delete()
}
segments.lastEntry() match {
case null =>
case entry => {
val seg = entry.getValue
seg.onBecomeInactiveSegment()
seg.index.trimToValidSize()
seg.timeIndex.trimToValidSize()
seg.log.trim()
}
}
//note: 创建一个 segment 对象
val segment = new LogSegment(dir,
startOffset = newOffset,
indexIntervalBytes = config.indexInterval,
maxIndexSize = config.maxIndexSize,
rollJitterMs = config.randomSegmentJitter,
time = time,
fileAlreadyExists = false,
initFileSize = initFileSize,
preallocate = config.preallocate)
val prev = addSegment(segment) //note: 添加到日志管理中
if(prev != null)
throw new KafkaException("Trying to roll a new log segment for topic partition %s with start offset %d while it already exists.".format(name, newOffset))
// We need to update the segment base offset and append position data of the metadata when log rolls.
// The next offset should not change.
updateLogEndOffset(nextOffsetMetadata.messageOffset) //note: 更新 offset
// schedule an asynchronous flush of the old segment
scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)
info("Rolled new log segment for '" + name + "' in %.0f ms.".format((System.nanoTime - start) / (1000.0*1000.0)))
segment
}
}
创建一个 segment 对象,真正的实现是在 Log 的 roll() 方法中,也就是上面的方法中,创建 segment 对象,主要包括三部分:数据文件、offset 索引文件和 time 索引文件。
offset 索引文件
这里顺便讲述一下 offset 索引文件,Kafka 的索引文件有下面一个特点:
- 采用 绝对偏移量+相对偏移量 的方式进行存储的,每个 segment 最开始绝对偏移量也是其基准偏移量;
- 数据文件每隔一定的大小创建一个索引条目,而不是每条消息会创建索引条目,通过 index.interval.bytes 来配置,默认是 4096,也就是4KB;
这样做的好处也非常明显:
- 因为不是每条消息都创建相应的索引条目,所以索引条目是稀疏的;
- 索引的相对偏移量占据4个字节,而绝对偏移量占据8个字节,加上物理位置的4个字节,使用相对索引可以将每条索引条目的大小从12字节减少到8个字节;
- 因为偏移量有序的,再读取数据时,可以按照二分查找的方式去快速定位偏移量的位置;
- 这样的稀疏索引是可以完全放到内存中,加快偏移量的查找。
LogSegment 写入
真正的日志写入,还是在 LogSegment 的 append() 方法中完成的,LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道。
/**
* Append the given messages starting with the given offset. Add
* an entry to the index if needed.
*
* It is assumed this method is being called from within a lock.
*
* @param firstOffset The first offset in the message set.
* @param largestTimestamp The largest timestamp in the message set.
* @param shallowOffsetOfMaxTimestamp The offset of the message that has the largest timestamp in the messages to append.
* @param records The log entries to append.
*/
//note: 在指定的 offset 处追加指定的 msgs, 需要的情况下追加相应的索引
@nonthreadsafe
def append(firstOffset: Long, largestOffset: Long, largestTimestamp: Long, shallowOffsetOfMaxTimestamp: Long, records: MemoryRecords) {
if (records.sizeInBytes > 0) {
trace("Inserting %d bytes at offset %d at position %d with largest timestamp %d at shallow offset %d"
.format(records.sizeInBytes, firstOffset, log.sizeInBytes(), largestTimestamp, shallowOffsetOfMaxTimestamp))
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
// append the messages
require(canConvertToRelativeOffset(largestOffset), "largest offset in message set can not be safely converted to relative offset.")
val appendedBytes = log.append(records) //note: 追加到数据文件中
trace(s"Appended $appendedBytes to ${log.file()} at offset $firstOffset")
// Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp
}
// append an entry to the index (if needed)
//note: 判断是否需要追加索引(数据每次都会添加到数据文件中,但不是每次都会添加索引的,间隔 indexIntervalBytes 大小才会写入一个索引文件)
if(bytesSinceLastIndexEntry > indexIntervalBytes) {
index.append(firstOffset, physicalPosition) //note: 添加索引
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)
bytesSinceLastIndexEntry = 0 //note: 重置为0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
经过上面的分析,一个消息集(MemoryRecords)在 Kafka 存储层的调用情况如下图所示:

最后还是利用底层的 Java NIO 实现。
FAQ
有一点不是很明白,kafka server在接收到producer的请求以后是不是实时持久化的呢?
看到文章的最后说,
LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道。
是不是是说kafka的消息是实时的进行了持久化呢?
但是也看到上面在Log.append() 方法中有这样的介绍
if (unflushedMessages >= config.flushInterval)//note: 满足条件的话,刷新磁盘
flush()
如果是实时持久化的为什么还需要这个判断操作呢
明白了,使用mmap只是写入了页缓存,并没有flush进磁盘,