算法导论之经典算法:索引查找全面解析
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
算法导论之经典算法:索引查找全面解析
本文关键字:算法导论、经典算法、元素查找、索引查找、算法实践
文章目录
- 算法导论之经典算法:索引查找全面解析
-
- 一、什么是算法
-
- 1. 算法的定义
- 2. 补充的概念
- 二、索引查找
-
- 1. 元素查找介绍
- 2. 基本索引查找
- 3. 分块查找
- 三、算法实践
-
- 1. 基本索引查找
- 2. 分块查找
- 3. 时间复杂度
- 4. 空间复杂度
一、什么是算法
本专栏为《手撕算法》栏目的子专栏:《算法导论》,会讲述一些经典算法,并进行分析。在此之前我们要先了解什么是算法,能够解决什么样的问题。
1. 算法的定义
以下为经典教材《Introduction.to.Algorithms》开篇中的内容。
Informally, an algorithm is any well-defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output. An algorithm is thus a sequence of computational steps that transform the input into the output.
可以看到,任何被明确定义的计算过程都可以称作算法,它将某个值或一组值作为输入,并产生某个值或一组值作为输出。所以算法可以被称作将输入转为输出的一系列的计算步骤。
这样的概括是比较标准和抽象的,其实说白了就是步骤明确的解决问题的方法。由于是在计算机中执行,所以通常先用伪代码来表示,清晰的表达出思路和步骤,这样在真正执行的时候,就可以使用不同的语言来实现出相同的效果。
概括的说,算法就是解决问题的工具。在描述一个算法时,我们关注的是输入与输出。也就是说只要把原始数据和结果数据描述清楚了,那么算法所做的事情也就清楚了。我们在设计一个算法时也是需要先明确我们有什么和我们要什么,这一点相信大家在后面的文章中会慢慢体会到。
2. 补充的概念
- 数据结构
算法经常会和数据结构一起出现,这是因为对于同一个问题(如:排序),使用不同的数据结构来存储数据,对应的算法可能千差万别。所以在整个学习过程中,也会涉及到各种数据结构的使用。
常见的数据结构包括:数组、堆、栈、队列、链表、树等等。
- 算法的效率
在一个算法设计完成后,还需要对算法的执行情况做一个评估。一个好的算法,可以大幅度的节省运行的资源消耗和时间。在进行评估时不需要太具体,毕竟数据量是不确定的,通常是以数据量为基准来确定一个量级,通常会使用到时间复杂度和空间复杂度这两个概念。
- 时间复杂度
通常把算法中的基本操作重复执行的频度称为算法的时间复杂度。算法中的基本操作一般是指算法中最深层循环内的语句(赋值、判断、四则运算等基础操作)。我们可以把时间频度记为T(n),它与算法中语句的执行次数成正比。其中的n被称为问题的规模,大多数情况下为输入的数据量。
对于每一段代码,都可以转化为常数或与n相关的函数表达式,记做f(n)。如果我们把每一段代码的花费的时间加起来就能够得到一个刻画时间复杂度的表达式,在合并后保留量级最大的部分即可确定时间复杂度,记做O(f(n)),其中的O就是代表数量级。
常见的时间复杂度有(由低到高):O(1)、O( log 2 n \log _{2} n log2n)、O(n)、O( n log 2 n n\log _{2} n nlog2n)、O( n 2 n^{2} n2)、O( n 3 n^{3} n3)、O( 2 n 2^{n} 2n)、O(n!)。
- 空间复杂度
程序从开始执行到结束所需要的内存容量,也就是整个过程中最大需要占用多少的空间。为了评估算法本身,输入数据所占用的空间不会考虑,通常更关注算法运行时需要额外定义多少临时变量或多少存储结构。如:如果需要借助一个临时变量来进行两个元素的交换,则空间复杂度为O(1)。
- 伪代码约定
伪代码是用来描述算法执行的步骤,不会具体到某一种语言,为了表达清晰和标准化,会有一些约定的含义:
缩进:表示块结构,如循环结构或选择结构,使用缩进来表示这一部分都在该结构中。
循环计数器:对于循环结构,在循环终止时,计数器的值应该为第一个超出界限的值。
to:表示循环计数器的值增加。
downto:表示循环计数器的值减少。
by:循环计数器的值默认变化量为1,当大于1时可以使用by。
变量默认是局部定义的。
数组元素访问:通过"数组名[下标]"形式,在伪代码中,下标从1开始("A[1]“代表数组A的第一个元素)。
子数组:使用”…"来代表数组中的一个范围,如"A[i…j]"代表从第i个到第j个元素组成的子数组。
对象与属性:复合的数据会被组织成对象,如链表包含后继(next)和存储的数据(data),使用“对象名 + 点 + 属性名”。
特殊值NIL:表示指针不指向任何对象,如二叉树节点无子孩子可认为左右子节点信息为NIL。
return:返回到调用过程的调用点,在伪代码中允许返回多个值。
and和or:与运算和或运算默认短路,即如果已经能够确定表达式结果时,其他条件不会去判断或执行。
二、索引查找
1. 元素查找介绍
查找也被称为检索,算法的主要目的是在某种数据结构中找出满足给定条件的元素(以等值匹配为例)。如果找到满足条件的元素则代表查找成功,否则查找失败。
在进行查找时,对于不同的数据结构以及元素集合状态,会有相对匹配的算法,在使用时也需要注意算法的前置条件。在元素查找相关文章中只讨论数据元素只有一个数据项的情况,即关键字(key)就是对应数据元素的值,对应到具体的数据结构,可以理解为一维数组。
- 顺序查找
也称线性查找,是最简单的查找方法。思路也很简单,从数组的一边开始,逐个进行元素的比较,如果与给定的待查找元素相同,则查找成功;如果整个扫描结束后,仍未找到相匹配的元素,则查找失败。
文章传送门:算法导论之经典算法:顺序查找全面解析。
- 折半查找
也称二分查找,是一种效率相对较高的查找方法。使用该算法的前提要求是元素已经有序,因为算法的核心思想是尽快的缩小搜索区间,这就需要保证在缩小范围的同时,不能有元素的遗漏。
文章传送门:算法导论之经典算法:折半查找全面解析。
- 索引查找
索引查找主要分为基本索引查找和分块查找,核心思想是对于无序的数据集合,先建立索引表,使得索引表有序或分块有序,结合顺序查找与索引查找的方法完成查找。
2. 基本索引查找
- 输入
主数据:n个数的序列,通常直接存放在数组中,可以是任何顺序。
基于主数据建立的索引表,索引表中的每个元素存储两个属性:关键字、主数据表中的序号,索引表按关键字有序。
待查找元素key。
- 输出
查找成功:返回元素所在位置的编号。
查找失败:返回-1或自定义失败标识。
- 算法说明
基本索引查找是基于一个有序的索引表进行折半查找,然后再根据索引表与主数据表的关系确定数据所在位置的过程。所以只需要在折半查找后,从索引表中取出该元素在主数据集合中对应的位置即可。
- 算法流程
索引表的结构如下,图片来自《数据结构简明教程》:
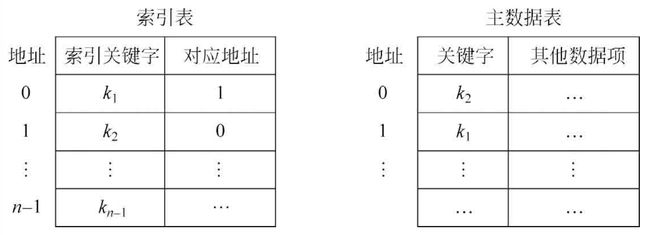
- 索引表中的元素分为关键字和地址两部分。
- 关键字为从主数据表中提取出来的用于排序的属性,地址为主数据表中对应元素的位置。
- 在索引表中使用折半查找快速定位待查关键字位置。
- 根据关联关系,提取出在主数据表中的对应位置。
注:索引表的生成过程并不属于本算法的研究范畴。
- 伪代码
使用T来代表索引表的集合,使用点来取出不同的属性(key为关键字,pos为对应地址)。
left = 1
right = T.length
position = -1
while left <= right
mid = (left + right) / 2
if T[mid].key == key
position = mid
break
else if T[mid] > key
right = mid - 1
else
left = mid + 1
if position != -1
return T[position].pos
else
return -1
3. 分块查找
- 输入
主数据:n个数的序列,通常直接存放在数组中,可以是任何顺序。
基于主数据建立的块索引表,索引表中的每个元素存储三个属性:关键字、块区间左端点、块区间右端点,索引表按关键字有序。
待查找元素key。
- 输出
查找成功:返回元素所在位置的编号。
查找失败:返回-1或自定义失败标识。
- 算法说明
使用分块查找时,主数据表必须满足该规律:按一定的区间长度进行分块后,前一块中的最大关键字小于后一块中的最小值,即后一块中的任一元素都大于前一块中的所有元素,关键字存储的就是这一块中最大的关键字的值。
在进行分块查找时依然是先在索引表上进行折半查找,确定待查找元素所在分块。由于分块内部的元素无序,所以在分块内部(基于块索引表的块区间端点)再使用顺序查找确定元素的最终位置。
注:算法同样适用于按递减排列的索引表,此时索引表中的块关键字应为这一块中最小的关键字的值。
- 算法流程
块索引表的结构如下,图片来自《数据结构简明教程》:

- 基于主数据表建立块索引表,每一块中的元素必须必须满足上述规律。
- 块索引表按关键字有序,可以根据折半查找快速定位待查关键字所在块。
- 在分块中使用顺序查找来确定待查关键字的最终位置。
- 由于在分块中查找时已经基于主数据表在进行操作,只需要从块索引表中提取出区间信息,所以可以直接得到待查元素最终位置。
- 伪代码
使用A来代表主数据表,使用T来代表索引表的集合,使用点来取出不同的属性(key为关键字,low为块区间左端点,high为块区间右端点)。
left = 1
right = T.length
while left <= right
mid = (left + right) / 2
if T[mid].key >= key
right = mid - 1
else
left = mid + 1
i = T[right + 1].low
while i <= T[right + 1].high and A[i] != k
i++
if i <= T[right + 1].high
return i
else
return -1
三、算法实践
1. 基本索引查找
- 输入数据(input)
A = {11,34,20,10,12,35,41,32,43,14}
T = { {10,3},{11,0},{12,4},{14,9},{20,2},{32,7},{34,1},{35,5},{41,6},{43,8}}
key = 41
- Java源代码
需要注意源代码与伪代码的区别,请查看文章开头补充的概念部分,这里不做过多说明。
public class BasicIndexSearch {
public static void main(String[] args) {
// 主数据表
int[] a = {
11,34,20,10,12,35,41,32,43,14};
// 待查关键字
int key = 41;
// 使用排序算法或其他操作得到索引表
BasicTable[] t = {
new BasicTable(10,3),
new BasicTable(11,0),
new BasicTable(12,4),
new BasicTable(14,9),
new BasicTable(20,2),
new BasicTable(32,7),
new BasicTable(34,1),
new BasicTable(35,5),
new BasicTable(41,6),
new BasicTable(43,8)
};
// 调用算法,并输出结果
int result = search(t, key);
System.out.println(result);
}
private static int search(BasicTable[] t,int key){
// 初始化变量
int left = 0;
int right = t.length - 1;
int position = -1;
// 以下为二分查找算法
while (left <= right){
// 取中间元素,以下写法防止数据量较大时发生溢出
int mid = (right - left) / 2 + left;
if (t[mid].key == key){
// 此处直接使用mid
position = mid;
// 找到匹配的key后可提前跳出并结束循环
break;
}else if(t[mid].key > key){
right = mid - 1;
}else {
left = mid + 1;
}
}
if (position != -1){
// 返回对应的主数据表中的逻辑序号
return t[position].pos + 1;
}else {
// 未找到时返回-1
return -1;
}
}
}
// 定义索引表结构
class BasicTable{
public BasicTable(int key, int pos) {
this.key = key;
this.pos = pos;
}
int key;
int pos;
}
- 执行效果

- 输出数据(output):7
2. 分块查找
- 输入数据(input)
A = {9,22,12,14,35,42,44,38,48,60,58,47,78,80,77,82}
T = { {22,0,3},{44,4,7},{60,8,11},{82,12,15}}
key = 48
- Java源代码
public class BlockSearch {
public static void main(String[] args) {
// 主数据表
int[] a = {
9,22,12,14,35,42,44,38,48,60,58,47,78,80,77,82};
// 待查关键字
int key = 48;
// 分块后获得索引表
BlockTable[] t = {
new BlockTable(22,0,3),
new BlockTable(44,4,7),
new BlockTable(60,8,11),
new BlockTable(82,12,15)
};
// 调用算法,并输出结果
int result = search(a, t, key);
System.out.println(result);
}
private static int search(int[] a,BlockTable[] t,int key){
// 初始化变量
int left = 0;
int right = t.length - 1;
// 以下为二分查找算法,用于确定待查元素所在块
while (left <= right){
// 取中间元素,以下写法防止数据量较大时发生溢出
int mid = (right - left) / 2 + left;
if (t[mid].key >= key){
// 此处直接使用mid
right = mid - 1;
}else {
left = mid + 1;
}
}
// 元素所在块为:right + 1,取对应的左端点
int i = t[right + 1].low;
// 使用顺序来扫描整个块
while (i <= t[right + 1].high && a[i] != key){
i++;
}
// 如果i没有超出块的范围,说明找到
if (i <= t[right + 1].high){
// 返回对应的逻辑位置
return i + 1;
}else {
// 未找到时返回-1
return -1;
}
}
}
class BlockTable{
public BlockTable(int key, int low, int high) {
this.key = key;
this.low = low;
this.high = high;
}
int key;
int low;
int high;
}
- 执行效果

- 输出数据(output):16
3. 时间复杂度
- 基本索引查找
对于完整的基本索引查找,整个过程包含索引表的建立和元素的查找两个步骤。对于索引表的建立可以使用不同的排序算法实现,可能有多种情况。由于是先后顺序的关系,所以在此列出查找部分的时间复杂度,完整的运行时间应该是两个步骤之和。
索引表是一个有序的集合,先在此基础之上进行折半查找,然后根据索引表中存储的信息提取出对应的位置,此处开销为常数级O(1)。所以对于查找部分,时间复杂度与折半查找为同一级别:O( log 2 n \log _{2} n log2n)。
- 分块查找
对于分块查找,需要主数据表本身满足一定的规律,在此之上只需要指定一个合理的区间长度,就可以得到一个分块索引表,主要的开销在于存储,所以分块查找可以看做是两次查找:分块的折半查找和分块内的顺序查找。
因此时间复杂度为两者之和,但是由于分块的策略也会影响到两个算法执行的效率,所以我们可以讨论一下最差的情况,如果只分一块,相当于直接进行了一个顺序查找,可以确定的是分块查找的时间复杂度不会超过O(n)。
4. 空间复杂度
- 基本索引查找
对于基本索引表,相当于是对主数据进行排序后完整的存储下来,因此除去一些临时变量外,主要需要对索引表分配额外的存储空间,与输入数据的量级相同:O(n)。
- 分块查找
对于分块索引表,由于选定的区间长度不唯一,所以需要的存储空间也不确定,一般为O( n a \frac{n}{a} an),其中a为常数,最多也不会超过:O(n)。