利用 Python 和 Spacy 尝试过英文的词嵌入模型后,你是不是很想了解如何对中文词语做向量表达,让机器建模时捕捉更多语义信息呢?这份视频教程,会手把手教你操作。
疑问
写过《如何用Python处理自然语言?(Spacy与Word Embedding)》一文后,不少同学留言或私信询问我,如何用 Spacy 处理中文词语,捕捉更多语义信息。
回顾一下, 利用词嵌入预训练模型,Spacy 可以做许多很酷的事情。
例如计算词语之间的相似程度:
这是“狗”和“猫”的相似度:
dog.similarity(cat)
0.80168545
这是“狗”和“橘子”的相似度:
dog.similarity(orange)
0.2742508
还可以利用特征语义,计算结果。
例如做个完形填空:
? - woman = king - queen
你一眼就看出来了,应该填写“man”(男人),对吧?
把式子变换一下:
guess_word = king - queen + woman
输入右侧词序列:
words = ["king", "queen", "woman"]
执行对比函数后,你会看到如下结果:
['MAN', 'Man', 'mAn', 'MAn', 'MaN', 'man', 'mAN', 'WOMAN', 'womAn', 'WOman']
这证明了词嵌入模型捕获到了性别的差异,并且知道“男人”与“女人”、“国王”与“女王”在其他特征维度上的相似性。
另外,我们还可以把词语之间的关系,压缩到一个二维平面查看。
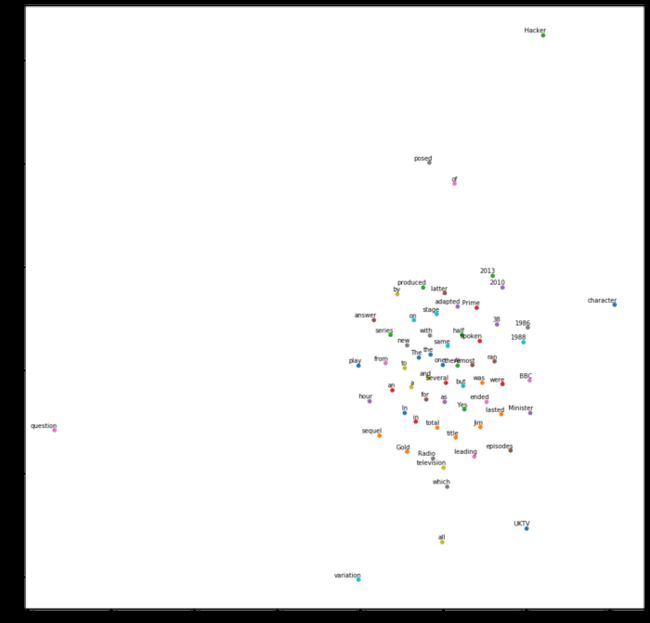
令人略感遗憾的是,以上的例子,都是英文的。
那么中文呢?
中文可不可以也这样做语义计算,和可视化?
答案是:
可以。
可惜 Spacy 这个软件包内置支持的语言列表,暂时还不包括中文。

但谁说用 Python 做词嵌入,就一定得用 Spacy ?
我们可以使用其他工具。
工具
我们这次使用的软件包,是 Gensim 。
它的 slogan 是:
Topic modelling for humans.

如果你读过我的《如何用Python爬数据?(一)网页抓取》和《如何用 pipenv 克隆 Python 教程代码运行环境?(含视频讲解)》,那你应该记得,我非常推崇这些适合于人类使用的软件包。
Gensim 包很强大,甚至可以直接用来做情感分析和主题挖掘(关于主题挖掘的含义,可以参考我的《如何用Python从海量文本抽取主题?》一文)。
而且,实现这些功能, Gensim 用到的语句非常简洁精炼。
这篇教程关注中文词嵌入模型,因而对其他功能就不展开介绍了。
如何使用 Gensim 处理中文词嵌入预训练模型呢?
我做了个视频教程给你。
视频教程
教程中,我们使用的预训练模型来自于 Facebook ,叫做 fasttext 。
它的 github 链接在这里。
视频里,我一步步为你展示语义计算与可视化功能的实现步骤,并且进行了详细的解释说明。
我采用 Jupyter Notebook 撰写了源代码,然后调用 mybinder ,把教程的运行环境扔到了云上。
请点击这个链接(http://t.cn/RBSyEhp),直接进入咱们的实验环境。

你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
如果你对这个代码运行环境的构建过程感兴趣,欢迎阅读我的《如何用iPad运行Python代码?》一文。
浏览器中开启了咱们的环境后,请你观看我给你录制的视频教程。
视频教程的链接在这里。
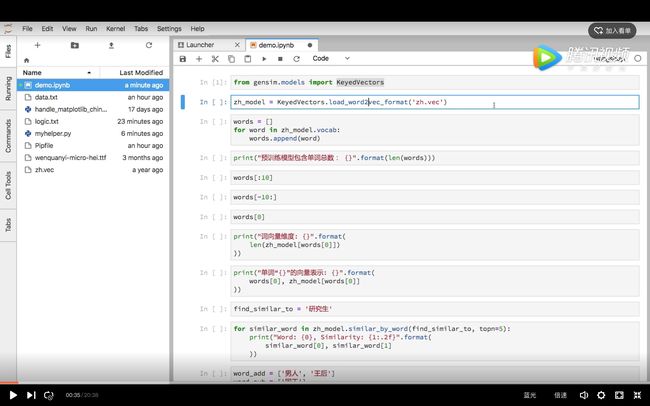
希望你能跟着教程,实际操作一遍。这样收获会比较大。
通过本教程,希望你已经掌握了以下知识:
- 如何用 gensim 建立语言模型;
- 如何把词嵌入预训练模型读入;
- 如何根据语义,查找某单词近似词汇列表;
- 如何利用语义计算,进行查询;
- 如何用字符串替换与结巴分词对中文文本做预处理;
- 如何用 tsne 将高维词向量压缩到低维;
- 如何可视化压缩到低维的词汇集合;
如果你希望在本地,而非云端运行本教程中的样例,请使用这个链接(http://t.cn/R1T4400)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
然后,请你参考《如何用 pipenv 克隆 Python 教程代码运行环境?》一文的说明,利用 Pipenv ,在本地构建代码运行环境。
如果你知道如何使用github,也欢迎用这个链接(http://t.cn/RBS4Ljo)访问对应的github repo,进行clone或者fork等操作。
当然,要是能给我的repo加一颗星,就更好了。
讲解
如果你不满足于只学会操作步骤,还想进一步了解词嵌入预训练模型的原理,我这里刚好有一段研究生组会上录制的视频。
请点击这个链接查看。

因为设备简陋,因此录制结果跟偷拍的差不多,请谅解。
讲解部分录过之后,我的学生们还提出了疑问。
因此我又进行了答疑,也录了视频。
请点击这个链接查看答疑过程。

希望这些讲解与答疑,能对你理解和使用中文词嵌入预训练模型,起到帮助。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。