基于Tensorflow 2.x手动复现BERT
基于Tensorflow 2.x手动复现BERT
What’s I can’t create, I don’t understand. —— Richard Feynman
这次来造一个NLP领域的大轮子——BERT。当然,以我的硬件条件(GTX1660Ti)并不允许完完全全的“复刻”谷歌的模型,所以这边下调了模型和词嵌入的维度。并且使用了网友们喜闻乐见的英雄联盟语料库来训练。所以我给自己复现的模型起名叫:LOL-BERT-Tiny。
代码可见:
https://github.com/cmd23333/BERT-Tensorflow2.x
有问题可以评论或者直接issue。欢迎给星
模型极简介绍
BERT可以理解成一个十分强力的深度词向量编码器。模型可以根据文本的上下文信息学习得到每一个单词的上下文表示,对于一词多义的词语,BERT模型能够做到对多语义的理解。举例来说:"我吃了一个苹果。"和"苹果公司的CEO是库克。"这两个句子中,经过BERT编码的"苹果"的词向量是不同的。而传统的词向量模型,它对词的编码是静态的,两个句子种"苹果"的词向量别无二致。
然后,BERT的全称是Bidirectional Encoder Representations from Transformers,从中我们可以提取到4个关键信息:
- Bidirectional 双向的。语言模型是单向的,给出一句话的前面几个字,然后预测下一个字是什么。比如“菲奥娜出生在德玛西亚王国的劳伦特家族”这句话,语言模型的任务是,预测“菲奥娜出”的下一个字是什么,当然单向的语言模型并不容易预测到“出生”,因为“出现”、“出发”都是这个语境下有意义的词语。这就会有召唤师发问了,为什么不能有双向的语言模型呢?比如我们从左往右给出“菲奥娜出”,再从右往左给出“族家特伦劳的国王亚西玛德在”,用RNN模型,把两个方向的信息(RNN传递给下一步的隐藏状态)拼接起来来预测,不也用到了双向的信息吗?确实。如果每句话我们只预测一个字,确实可以拆成两段来做,但这么做太没有效率了;而如果我们用双向的RNN,用每个时间步的状态向量来预测每个字,又会造成信息泄露(即已经引入这个字的信息了)。而BERT的预训任务之一,却是在给出了“菲奥娜出[MASK]在德玛西亚王国的劳伦特家族”,来预测[MASK]的字是什么。这样就巧妙的利用到了双向的句子信息,并且不会有信息泄露的问题。
- Encoder 编码器。这是相对于Decoder(解码器)来说的,Transformer的原作是用来做翻译任务的,有一个解码器,但BERT只用到了编码器。
- Representations 表示。BERT如果不加入额外的层(解码),那么它的作用就只是把一个句子的每个字/词映射到一个词嵌入空间。
- Transformers 是一种基于注意力的网络结构,相比于传统用于处理序列任务的RNN模型,加入位置编码后的Transformer可以并行地计算每一个时间步,并且通过自注意力机制来吸收之前和之后的信息。不过值得注意的是如果不加位置编码,Transformer就失去了处理有序序列的能力。
所以这就是BERT为什么叫BERT啦。要说BERT的结构其实也简单(如下图),包括了嵌入层、Transformer编码层和输出三个部分,所以接下来我们只要把这三个部分实现,再实现预训练任务的代码,BERT就完成了。

BERT预训练任务
既然是能够动态编码序列的词嵌入模型,那么BERT的参数是怎么训练得到的呢?有两个预训练任务:遮挡语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。
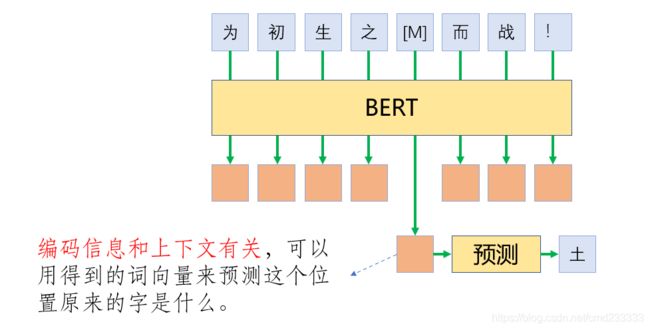
遮挡语言模型不像传统的语言模型一样给出一些已经出现的字去预测下一个字,而是采用了遮挡的方法。具体来讲就是随机地选择句子中的部分词,然后将这些词盖住,再结合整个句子的信息去预测这些位置的词。这种做法类似于初高中英语学习中的“完形填空”。对于被选中的词,会用一个特殊的标记[MASK]来代替,但一般在下游任务中是不会有[MASK]出现的,将其编码进去会导致预训练和下游任务不一致。故,为了减轻这种不一致给模型带来的影响,对于被选中的字,还有三种操作:有80%的概率这个字会直接被替换成[MASK],有10%的概率将这个词用另一个随机采样的词来代替,有10%的概率对这个词不做任何改动。例如对于“为初生之土而战!”,如果要预测“土”这个字,则这句话有80%的概率变成“为初生之[MASK]而战!”,有10%的概率变成“为初生之狗而战!”,“狗”这个字可以是随机采样的任意一个字,有10%的概率原句保持不变,依然是“为初生之土而战!”。编码后,得到每个字的词嵌入,由于因为编码信息和上下文有关,所以可以用得到的字嵌入来预测这个位置原来的字是什么。从而以预测结果的好坏为监督信息让模型学习。

另一项任务是下一句预测。这个任务的目的是取得句子对之间,用语言模型所无法直接得到的信息。在具体操作过程中首先是选择一个句子,这个句子的下一句被设置成正例,然后将两句话的位置颠倒,作为负例。比如"[CLS]艾欧尼亚[SEP]昂扬不灭[SEP]“这是正样本,那么”[CLS]昂扬不灭[SEP]艾欧尼亚[SEP]"这就是负样本。然后再在这一对句子的层级上做一个简单的二分类来判断目标句子是否是当前句子的下一句。具体来说,在预处理过程中,我们把输入转化成“[CLS]+句子1+[SEP]+句子2+[SEP]+填充”的形式,[CLS]的词向量就会融入整个输入中除了填充部分的信息,可以代表整个样本的特征,用于二分类。
语料
语料来源于《英雄联盟》宇宙,感谢github用户@monkey-hjy和他的英雄联盟背景故事爬虫,本来我是打算自己写一个爬虫去爬的,但是他已经都帮我弄好了~
下面看两个示例,这份语料共有约22万字,包含了妮蔻之前的所有英雄和英雄联盟宇宙各个地区的背景故事。
示例1:
名字1:无双剑姬
名字2:菲奥娜
所属地区:德玛西亚
故事:菲奥娜是全瓦洛兰最可怕的决斗家。她以雷厉风行、狡黠聪慧闻名于世,同样著名的还有她舞弄自己蓝钢佩
剑的极速。菲奥娜出生在德玛西亚王国的劳伦特家族,她从父亲的手中接管了家业,并在一场丑闻风波中将家族
拯救于灭亡的边缘。虽然劳伦特家威严不再,但菲奥娜却一直在不懈地努力,希望重振家族荣耀,让劳伦特这个
名字重回德玛西亚名望贵族之列。从很小的时候开始,菲奥娜就不屑于他人寄托在自己身上的期望。她的母亲找
来德玛西亚最优秀的精工巧匠,为她制造了栩栩如生的洋娃娃。菲奥娜却把洋娃娃送给了自己的侍女,转身拿起
了哥哥的佩剑,使他不得不偷偷地传授她剑术。
...
示例2:
地区:艾欧尼亚
地区简介:在凶险海域环绕中,诸多同盟省份在一片被称为“初生之土”的庞大群岛上组成了艾欧尼亚。追寻万物的
平衡是这里长久以来的文化基调,因此物质与精神领域之间的界限也在这里若有若无,在野外的森林和山脉中尤
为如此。虽然这片土地上的魔力可能变幻无常,栖息着的生物也可能危险而神奇,但在过去的几百年中,艾欧尼
亚的居民一直过着富足的生活。
...
构建词表和数据集
这一部分的代码见Data/data.py。
首先我们定义了一个Corpus类,用来读取语料、生成词表和标记化文本(Tokenize)。
generate_vocabulary方法用于生成词表,里面使用了Python内置的Counter(计数器),并使用了Counter类的most_common方法对所有语料中出现过的字按频率从高到低进行了排序,随后我们将频率小于config['Character_Frequency_Threshold'](设置为3,可自己调整)的词过滤掉,剩下的做为词表中的字。最后在词表开头加上['CLS', 'SEP', 'MASK', 'PAD', 'UNK']这五个特殊token,分别代表分类符(classifier),分隔符(separate),掩码符(mask),填充符(padding)和未登录词(unknown)。其中'UNK'就代表了所有不在词表中的,语料中出现次数小于阈值的字。
make_and_parse_passages方法用于解析语料文本,它是一个生成器,每次yield一个关于英雄或者地区的故事,即示例中的“故事”或“地区简介”后的部分。随后,我们将这一大段的故事传递给make_bert_data这一方法,用句号分句,字符串的自带的split方法即可。注意到官方的背景故事中,都是中文的符号,所以不必考虑英文的句号。分句后,我们每次看连续的两个句子,这样第二句必是前一句的下一句,以此构建NSP任务的数据集。以如下的步骤构建BERT的一条输入:
- 用’CLS’对应的token id作为列表的第一个数字。
- 将第一句中的每个文字转化为其在词表中对应的token id,并
append到列表尾端。如果不在词表里,就把’UNK’对应的token id加到列表尾端。 - 因为split之后会把句号一起抹去,所以需要把句号对应的token id加到列表尾端。
- 加入’SEP’对应的token id到列表末尾。
- 将第二句中的每个文字转化为其在词表中对应的token id,并
append到列表尾端。如果不在词表里,就把’UNK’对应的token id加到列表尾端。 - 加入’SEP’对应的token id到列表末尾。
- 如果列表长度小于
config['Max_Sequence_Length'],就用’PAD’补足相应长度,如果太长,就截取前config['Max_Sequence_Length']个数字。
这样我们就生成了一条NSP任务的正样本,随后找到正样本列表中第一个’SEP’的位置,重新排列得到一条负样本。然后将正样本和负样本都append到总的数据上(self.data)。Corpus类还有一个token_id_to_word_list方法,用于将tokenize后的数字列表转化回文本。
接下来,我们还定义了一个DataGenerator类(继承自tf.keras.utils.Sequence),用于生成每个批次的BERT预训练模型的输入和标签。DataGenerator首先会调用上面的make_bert_data以生成输入数据,我们直接看__getitem__(self, idx)方法,这是Python中以双下划线标识的魔法方法,可以允许我们以data[idx]的方式得到第idx批次数据。这个方法会返回6个东西,分别是:mask后的句子,mask的位置,原始句子;分句位置,补零位置,是否是下一句。
return batch_x, batch_mlm_mask, origin_x, batch_segment, batch_padding_mask, batch_y
一个一个来看。origin_x,是前面make_bert_data方法生成的数据,np.array类,形状为batch, max_seq_len,数据类型是int,代表了被tokenize之后的一批文本。我们定义了make_mask_language_model_data方法,首先计算一个批次中每个句子除了’PAD’的长度,乘上15%并且向上取整得到每个句子要被’MASK’替换掉字的个数。然后使用np.choice随机从位置[1,len-1]{也就是我们不’MASK’第一个’CLS’和最后一个’SEP’}选择要’MASK’的位置,得到batch_mlm_mask。将对应位置的token id用’MASK’的token id替换,得到batch_x,就是BERT的输入,代表了MLM任务的输入,被遮挡后的句子。这三者就体现了预训练中的MLM任务,我们输入batch_x,经过BERT编码并作出预测,根据预测结果mlm_pred和origin_x对比计算交叉熵损失,并且我们只计算被’MASK’位置的损失,即batch_mlm_mask=1的位置。
batch_padding_mask代表了’PAD’的位置,因为填充的部分不应该影响编码结果,所以后面在自注意力时要用到这个输入来做一些操作。
另外两个输入主要是用于NSP任务,batch_segment指示一条输入中两个不同的句子,我们后面需要用到segment embedding来区分一条输入的两个句子。batch_y指示了NSP任务的标签,正样本为1,负样本为0。
接下来我们来看一看一个batch的数据到底长什么样子。在我的实现里,batch size = 32,max_seq_len=128。所以我们会看到除了batch_y的形状为32,其他输入的形状都为[32, 128]。另,词表中包括特殊token一共有2367个字。

再来看一下这个batch的第一条数据。

这两句话在语料中是这样的:菲奥娜是全瓦洛兰最可怕的决斗家。她以雷厉风行、狡黠聪慧闻名于世,同样著名的还有她舞弄自己蓝钢佩剑的极速。
编码后最开头是一个’CLS’,两句话之间有一个’SEP’来分割,末尾也有一个’SEP’,并且在最后用’PAD’补足长度为128。然后很显然,这两句话的顺序被颠倒了,所以这个样本在NSP任务的标签是0。
而计算机能看懂的输入是这样的:

batch_x和origin_x的不同就在于,batch_mlm_mask等于1的地方,原始文字对应的token id被替换成了’MASK’对应的token id,在我这里就是被替换成了2。而0是’CLS’的id,1是’SEP’的id。

再看看batch_segment和batch_padding_mask。batch_segment的前半部分是0,后半部分是1,分别代表这是前一个句子和后一个。值得注意的是中间的分割符’SEP’是被算在前一句的,而补零的部分被算在了后一句。而batch_padding_mask同样前半部分是0,后半部分是1,分别代表了真正的输入和’PAD’的输入。
以上,数据部分就讲完咧~
嵌入层
接下来是BERT模型最开始的部分,BERT其实可以理解成一个超级强力的深度编码器。它也需要一般的embedding层,然后再在浅层的编码上通过transformer来加强编码的表示。
BERT的嵌入层有三个,通过相加得到编码层的结果。
- token embedding:将输入的字的信息映射到嵌入空间。
- positional embedding:将输入的位置的信息映射到嵌入空间。
- segment embedding:将输入的分句的信息映射到嵌入空间。
以“艾欧尼亚,昂扬不灭!”这句话为例,略去标点并把它拆分成上下两句,嵌入层的操作如下图所示。对于序列的每个位置,其最浅层的词嵌入就等于这三个嵌入对应元素相加(三个嵌入的维度相同)。至于为什么BERT需要把三种嵌入直接相加,我的理解是:首先三种嵌入并不一定要直接相加,逐元素相乘或者concat起来都是可以的。加法操作相当于是在高维空间上的平移,逐元素相乘可以看成是高维空间上的放缩,拼接操作就是把 N N N维空间扩大到 3 N 3N 3N维。我们希望模型可以在 N N N维空间上同时区分出不同的字、不同的位置、不同的句子,而相加这一操作计算简单(相对于相乘)、减低计算量(相对于拼接)。
程序中我们使用Embedding来实现嵌入层。代码可以在Layer/embedding.py下找到。
class Embedding(tf.keras.layers.Layer):
def __init__(self, ...):
设定参数
def build(self, input_shape):
# 构建三个embedding层
self.token_embedding = tf.keras.layers.Embedding(input_dim=self.vocab_size,
output_dim=self.embedding_size,
name="token_embedding")
self.segment_embedding= tf.keras.layers.Embedding(input_dim=self.segment_size,
output_dim=self.embedding_size,
name="segment_embedding")
self.positional_embedding = self.add_weight(name='positional_embeddings',
shape=(self.max_seq_len,
self.embedding_size))
self.output_layer_norm = tf.keras.layers.LayerNormalization(name="layer_norm")
self.output_dropout = tf.keras.layers.Dropout(rate=self.hidden_dropout_prob)
super(Embedding, self).build(input_shape)
def call(self, inputs):
# 调用这一方法,计算得到嵌入层的输出。
input_ids, segment_ids = inputs
seq_length = input_ids.shape[1]
# [batch_size, seq_len, d]
token_embeddings = self.token_embedding(input_ids)
# [batch_size, seq_len, d]
segment_embeddings = self.segment_embedding(segment_ids)
# [1, seq_len, d]
positional_embeddings = tf.expand_dims(self.positional_embedding, axis=0)
output = token_embeddings + segment_embeddings + positional_embeddings
output = self.output_layer_norm(output)
output = self.output_dropout(output)
return output
代码如上,token_embedding和segment_embedding其实都是简单的tf.keras.layers.Embedding层,前者有vocab_size个可能出现的id,而后者只有2个(segment_size=2,因为出现的segment_ids只可能等于0或者1,代表是样本的第一句和第二句话,如果需要拼接更多的句子,则需要修改这个参数)。
我们写一个demo展示一下助助兴:

前面看到过了,batch_x的形状为[32,128],词嵌入维度设置为256,所以经过token embedding后,得到的输出形状为[32, 128, 256],如上图所示。还可以看到token embedding层的参数,形状为[vocab_size, embedding_size],即词表中的每一个词,都有一个对应维度为embedding_size的嵌入向量:

同样的,batch_segment的形状也是[32, 128],数值上只可能等于0(代表第一个句子)和1(代表第二个句子),词嵌入维度同为256,所以经过segment embedding后,得到输出的形状相同。segment embedding的参数形状为[2, embedding_size],代表第一句话和第二句话的嵌入向量。

而唯一有所不同的便是位置嵌入PositionalEmbedding,按照每一个位置都有一个embedding_size维度的特征向量,位置嵌入的参数量为[max_seq_len, embedding_size],其实我们仍可以使用tf.keras.layers.Embedding层,并新增一个位置输入。但会发现,前两个嵌入之所以那么做是因为每一条样本的batch_x和batch_segment都是不同的,而位置输入batch_position,如果有,那么他将会是形状为[batch_size, max_seq_len]的样子,并且对每一个样本,它都等于
b a t c h _ p o s i t i o n = [ [ 0 1 2 . . . m a x _ s e q _ l e n ] [ 0 1 2 . . . m a x _ s e q _ l e n ] ⋮ ⋮ ⋮ ⋮ ⋮ [ 0 1 2 . . . m a x _ s e q _ l e n ] ] batch\_position= \left[ \begin{matrix} [0 & 1 & 2 & ... & max\_seq\_len]\\ [0 & 1 & 2 & ... & max\_seq\_len] \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ [0 & 1 & 2 & ... & max\_seq\_len] \end{matrix} \right] batch_position=⎣⎢⎢⎢⎡[0[0⋮[011⋮122⋮2......⋮...max_seq_len]max_seq_len]⋮max_seq_len]⎦⎥⎥⎥⎤
这样再这么做就会显得很呆,因此我们直接初始化了一个(使用add_weight()方法)参数矩阵self.position_embedding,每次使用它的时候,利用Python的广播机制,只需要将它的维度扩展为1, max_seq_len, embedding_size,即可和另外两个嵌入直接相加。

如图所示,positional_embeddings和输入无关,因为不管是什么句子,位置嵌入给予相同位置的信息是相同的。最后,将三者相加,并经过归一化和Drop Out操作,即可得到嵌入层的总输出:

做个总结,BERT嵌入层的嵌入,相较于一般的嵌入,它让模型可以在 N N N维空间上同时区分出不同的字、不同的位置、不同的句子。区分出不同的字很好理解。对于后两者,这边举例说一些:
-
BERT的位置编码,通过学习得到的,序列中的每个位置都有一个维度是
embedding_size的位置向量。使用时直接把token embedding和position embedding相加。举个简单的例子,小学做广播体操时,领队会喊“一一,一二一,齐步走!”——不考虑’CLS’和’SEP’,如果只看token_embedding,形状为[11,256],其中第1/2/4/6行都是一样的,因为都是“一”这个字的嵌入表示。但如果我们加上positional embedding,形状同样是[11, 256],通常每行都是不一样的,这样逐元素相加,得到的结果形状仍为[11, 256],但是第1/2/4/6行已经不同了,我们就区分出了不同位置上的“一”。 -
分句嵌入的参数维度是
[2, embedding_size],2代表了我们为第一和第二句话给予了不同的信息向量。使用时,用样会把segment_embedding和token_embedding相加。这样做的结果,比如我们的输入是[‘CLS’,开,打,‘SEP’,开,打,‘SEP’],玩过武器大师的召唤师都知道,这两句“开打”的含义是不一样的,后一句的语气更加强烈,如果不加segment_embedding,模型就无法识别这类不同。
以上就是BERT的嵌入层。
Transformer编码器
Transformer编码器是模型的主干部分,其作用是将浅层的词嵌入映射到深层的词嵌入,并基于自注意力机制实现每个字的动态编码。这部分的代码在layer/transformer.py下。
Multi Head Attention
Transformer的第一个子模块是多头注意力层(MultiHeadAttention),如图所示,它是由多个缩放的点积注意力模块拼接而成的。
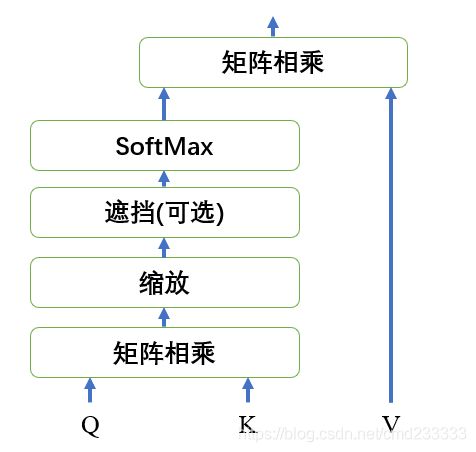
缩放的点积注意力模块的输入为 q u e r y query query, k e y key key和 v a l u e value value,这是一种巧妙的自注意力机制,在BERT的预训练里并没有太多的花样(但scale_dot_product_attention本身可以有很多种变化,体现在传入mask的不同。)
def scaled_dot_product_attention(q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
# 缩放 matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 将 mask 加入到缩放的张量上。
if mask is not None:
scaled_attention_logits + (tf.cast(mask[:, tf.newaxis, tf.newaxis, :], dtype=tf.float32) * -1e9)
# softmax 在最后一个轴seq_len上归一化,因此分数相加等于1。
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
首先,将 Q u e r y Query Query(形状为[batch, num_heads, seq_len, depth])和 K e y Key Key的转置(形状为[batch, num_heads, depth, seq_len])相乘,得到结果的形状为[batch, num_heads, seq_len, seq_len],在数值上缩放 d k \sqrt d_k dk倍,并加上mask后,在最后一个维度上做softmax操作,这样,最后得到一个正方形的矩阵,每行的和都是1。注意到方阵的第 i i i行第 j j j列元素表示输入序列第 i i i个字对第 j j j个字的关注度。最后,再乘上 V a l u e Value Value(形状为[batch, num_heads, seq_len, depth]),这样得到结果的形状仍然是[batch, num_heads, depth, seq_len]。即:
H = s o f t m a x ( Q K T + M a s k d k ) V H=softmax(\dfrac {QK^T+Mask}{\sqrt {d_k}})V H=softmax(dkQKT+Mask)V
至于为什么要除以 d k \sqrt {d_k} dk,原因如下:
记 q ≜ Q i j , k ≜ K i j q\triangleq Q_{ij},k\triangleq K_{ij} q≜Qij,k≜Kij,假设二者互相独立且均服从均值为0,方差为1的正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。则 q , k q,k q,k乘积的均值为 E ( q ⋅ k ) = 0 E(q\cdot k)=0 E(q⋅k)=0,方差为:
D ( q ⋅ k ) = E [ ( q ⋅ k ) 2 ] − [ E ( q ⋅ k ) ] 2 = E [ q 2 ] ⋅ E [ k 2 ] − ( E [ q ] ⋅ E [ k ] ) 2 = ( D [ q ] + ( E [ q ] ) 2 ) ⋅ ( D [ k ] + ( E [ k ] ) 2 ) − ( E [ q ] ⋅ E [ k ] ) 2 = ( 1 + 0 ) × ( 1 + 0 ) − ( 0 × 0 ) 2 = 1 \begin{aligned} D(q\cdot k)&=E[(q\cdot k)^2]-[E(q\cdot k)]^2\\&=E[q^2]\cdot E[k^2] - (E[q]\cdot E[k])^2 \\&=(D[q]+(E[q])^2)\cdot (D[k]+(E[k])^2) - (E[q]\cdot E[k])^2 \\&=(1+0)×(1+0) - (0×0)^2\\&=1 \end{aligned} D(q⋅k)=E[(q⋅k)2]−[E(q⋅k)]2=E[q2]⋅E[k2]−(E[q]⋅E[k])2=(D[q]+(E[q])2)⋅(D[k]+(E[k])2)−(E[q]⋅E[k])2=(1+0)×(1+0)−(0×0)2=1
所以, ( Q K T ) i j = ∑ k = 0 d k q i k ⋅ k k j (QK^T)_{ij}=\sum_{k=0}^{d_k}q_{ik}\cdot k_{kj} (QKT)ij=∑k=0dkqik⋅kkj,服从分布 N ( 0 , d k ) N(0,d_k) N(0,dk)。那么如果作softmax操作之前不除以 d k \sqrt{d_k} dk,则 Q ⋅ K Q\cdot K Q⋅K的元素的值随着 d k d_k dk的增大,可能会很大。我们知道softmax会先进行一个取指数的运算,所以比较 s o f t m a x ( [ − 1 , 0 , 1 ] ) softmax([-1,0,1]) softmax([−1,0,1])和 s o f t m a x ( [ − 5 , 0 , 5 ] ) softmax([-5,0,5]) softmax([−5,0,5]),因为 ( e − 1 , e 0 , e 1 ) = ( 0.37 , 1 , 2.72 ) (e^{-1},e^0,e^1)=(0.37,1,2.72) (e−1,e0,e1)=(0.37,1,2.72)和 ( e − 5 , e 0 , e 5 ) = ( 0.01 , 1 , 147.1 ) (e^{-5},e^{0},e^{5})=(0.01,1,147.1) (e−5,e0,e5)=(0.01,1,147.1)相比,后者三个数的差距要比前者大很多。所以做了 a j ∑ i a i \frac{a_j}{\sum_i a_i} ∑iaiaj之后,后者的结果趋向于某一个位置的概率趋近于1,这样就形成了一种比较硬的 h a r d m a x hardmax hardmax操作。如下图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LcMUJ9m6-1616858142289)(C:\Users\62307\Desktop\BERT-Tensorflow2.x\Img\10.png)]所以我们对其除以 d k \sqrt {d_k} dk,使 ( Q K T ) i j ~ N ( 0 , 1 ) (QK^T)_{ij} ~ N(0,1) (QKT)ij~N(0,1),这样会在数值上更加的稳定。
我们来看看这个注意力机制左边的部分: s o f t m a x ( Q K T + M a s k d k ) softmax(\dfrac {QK^T+Mask}{\sqrt {d_k}}) softmax(dkQKT+Mask),先忽略 d k , M a s k \sqrt {d_k},Mask dk,Mask和 s o f t m a x softmax softmax操作,并且先不考虑batch和num_heads这两个维度,那么 Q , K Q,K Q,K的形状均为[seq_len, depth],即序列的每一个字,都有对应长度为depth的词嵌入。而 ( Q K T ) i j = ∑ k = 1 d k Q i k ⋅ K k j (QK^T)_{ij}=\sum\limits_{k=1}^{d_k}Q_{ik}\cdot K_{kj} (QKT)ij=k=1∑dkQik⋅Kkj,即 Q K T QK^T QKT的第 i i i行第 j j j列的元素等于 Q Q Q矩阵第 i i i行和 K K K矩阵第 j j j行的内积。
在线性代数里,两个向量的内积的大小可近似地来表示二者的相似程度。所以,如果 Q u e r y Query Query矩阵第 i i i行和 K e y Key Key矩阵第 j j j行的词嵌入相似程度越高(亦可理解成相关程度),则内积越大。经过 s o f t m a x softmax softmax操作后,每行的和为1,结果矩阵的第 i i i行第 j j j列,就代表第 i i i个 Q u e r y Query Query和第 j j j个 K e y Key Key的相关程度。最后,我们把形状为[seq_len,seq_len]的注意力矩阵,再乘上 V a l u e Value Value(形状为[seq_len,depth]),得到的结果仍为[seq_len, depth]。这样,我们就对原先的词嵌入做了新的变换,得到了新的词嵌入。新的字嵌入的每一个维度的值,都通过注意力机制包含了这个序列中其他字在这个维度的信息,注意力权重大的,包含那个字的信息就更多(由于是自注意力,新的字嵌入也会注意到这个字本身的信息)。
这样就引出了一个问题:如果序列中后面是被'PAD'填充的怎么办?因为'PAD'只是为了并行化计算而填补的部分,它不应该含有任何信息。所以我们需要加上一个 M a s k Mask Mask。在BERT中, M a s k Mask Mask的形状为[batch, seq_len],补零的地方为1,其余为0。解释一下代码:
scaled_attention_logits + (tf.cast(mask[:, tf.newaxis, tf.newaxis, :], dtype=tf.float32) * -1e9)
scaled_attention_logits就是 Q K T QK^T QKT,形状是[batch, num_heads, seq_len, seq_len],而mask的形状是[batch, seq_len],为了可以和 Q K T QK^T QKT相加,我们使用mask[:, tf.newaxis, tf.newaxis, :]将mask的形状变换为[batch, 1, 1, seq_len],这样,通过广播机制,就可以相加了。乘上-1e9之后,数值上,没有'PAD'的列均为0,'PAD'的列为一个很大的负数。这样,经过softmax之后,被Mask的地方就近似等于0了,这样再乘上 V a l u e Value Value的时候,就不会注意(或者说融合)'PAD'的信息了。
以上就是缩放的点积注意力,可以说是Transformer或者BERT里最重要的部分了。
回到多头注意力层,它的定义如下:
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
这边我们定义了四个全连接层。多头注意力层的输入就是嵌入层的总输出,形状是[batch, seq_len, d_model]。随后,将输入同时喂入wq, wk, wv这三个全连接层,得到 Q u e r y Query Query, K e y Key Key, V a l u e Value Value,形状也都是[batch, seq_len, d_model]。其中d_model=embedding_size。
query = self.wq(x)
key = self.wk(x)
value = self.wv(x)
随后,我们将这三者都变换一下形状,使用定义的split_head方法将他们reshape成[batch_size, num_heads, seq_len, depth]形式。即每个batch,我们都有num_heads个头,每个头的序列长度为seq_len,嵌入维度为depth。因此,depth, num_heads和d_model的关系是: d _ m o d e l = n u m _ h e a d s × d e p t h d\_model = num\_heads × depth d_model=num_heads×depth。这也就说明了程序中的断言assert d_model % self.num_heads == 0,depth一定要是(正)整数。关于多头,我们可以将其理解层多个卷积核,期望每个头都能在缩放的点积注意力模块下学习到不同方面的信息。
scaled_attention, attention_weights = scaled_dot_product_attention(query, key, value, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output
多头注意模块的最后,我们将点积注意力模块计算得到的结果scaled_attention,形状为[batch, num_heads, seq_len, depth]变形成[batch, seq_len, num_heads*depth]=[batch, seq_len, d_model](注意到 d _ m o d e l = s e q _ l e n × d e p t h d\_model = seq\_len × depth d_model=seq_len×depth),然后再经过一个线性层(unit同样等于d_model)做一次变换,得到多头注意力模块的输出,形状为[batch, seq_len, d_model],和输入的形状一致。
Feed Forward Network
Transformer编码器的第二个子模块是前馈神经网络。其实它就是两个连续的全连接层,这里笔者并不是十分理解作者另取一个名字的原因。
tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
其中ddf是第一个全连接层的节点数,一般是4倍的d_model;后一个全连接层的节点数是d_model。这样,输入的形状是[batch, seq_len, d_model],经过第一个全连接层得到[batch, seq_len, 4*d_model],附带一个ReLU激活函数,再经过第二个全连接层,最后的结果仍为[batch, seq_len, d_model]。
Add & Norm
Transformer编码器中另外两个独立部件是相加与归一化(Add & Norm),引入他们的目的是为了更方便的训练和堆叠模型的深度。Add的操作和残差连接一致,归一化与常见的在一批次样本间的BatchNormalization略有不同,是在样本内的层归一化LayerNormalization,不过tf2.0已经帮我们实现好了。
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
BERT中的Transformer
接下来把上面几个模块整合一下,即可构建一个BERT中的Transformer模块。此模块的结构如下图所示:

一定会有饭友发现这张图很熟悉,相比Transformer论文,其缺少了右边的部分(因为不需要解码)。BERT里的Transformer模块就是由上图的结构堆叠多个得到的。结合代码来说:
class Transformer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(Transformer, self).__init__()
#...省略
def call(self, x, mask, training=None):
attn_output = self.mha(x, mask) # (batch_size, seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, seq_len, d_model)
return out2
观察call方法,我们传进去的是输入x和遮挡mask。x来自上一节的嵌入层总输入,即三个embedding的相加,mask在这里就是padding mask,告诉我们序列中哪些位置只是补零而不是真实的字(就是第一节中的batch_padding_mask)。所以x的形状是batch_size, seq_len, d_model,mask的形状是batch_size, seq_len。
首先,我们将x输入进多头注意力层,它先用三个线性变换来计算 Q , K , V Q,K,V Q,K,V,也就是图中三条分支的线。随后,计算scaled dot product attention,得到更深层的词嵌入attn_output,形状仍为batch_size, seq_len, d_model。然后将这个词嵌入输入一个drop out层,形状不变。然后加一个残差连接,即out1 = self.layernorm1(x + attn_output)的x + attn_output,这是为了然梯度更好的传递下来。然后,是一个LN层,这些操作都不改变输入的维度,所以得到的out1的形状仍为batch_size, seq_len, d_model。上面的内容对应图的下半部分。
得到注意力层,并经过drop out、残差连接、LN的输出后,我们将out1传递到图的上半部分。即一个feed forward network,前面也说了,ffn并不是什么新的东西,只是一个两层的全连接层罢了。然后,将ffn的输出,同样的经过drop out层,并残差连接和LN层之后,得到一个transformer block的最终输出out2,形状仍为batch_size, seq_len, d_model。
注意到上面的dropout和LN层是不共享参数的。再注意到一个transformer block的输入和输出维度相同,再加上残差连接的加持,我们就可以一直堆叠这个模块,得到一个输入的越来越深层的词嵌入表示。在官方的BERT版本里,一共堆叠了12层Transformer,官方的Tiny版本堆叠了6次,Large版本堆叠了24次。
BERT层
代码在根目录下的BertLayer.py文件下。这里,我们直接定义了一个BERT层:
class Bert(tf.keras.Model):
"""
可以用过修改transformer的层数,还有输入的最大长度,来调节模型的大小
可以设置segment embedding,对有断句的输入做embedding
可以设置attention mask,在特定任务中可能会对attention做特定的mask
"""
def __init__(self, config, **kwargs):
...
self.embedding = Embedding(vocab_size,embedding_size,max_seq_len,segment_size)
self.transformer_blocks = [Transformer(...)] * self.num_transformer_layers
self.nsp_predictor = tf.keras.layers.Dense(2)
def call(self, inputs, training=None):
batch_x, batch_mask, batch_segment = inputs
x = self.embedding((batch_x, batch_segment))
for i in range(self.num_transformer_layers):
x = self.transformer_blocks[i](x, mask=batch_mask, training=training)
first_token_tensor = x[:, 0, :]
nsp_predict = self.nsp_predictor(first_token_tensor)
mlm_predict = tf.matmul(x, self.embedding.token_embedding.embeddings, transpose_b=True)
sequence_output = x
return nsp_predict, mlm_predict, sequence_output
代码中的__init__方法省略的部分对模型的一些参数进行了定义:比如transformer块的个数(num_transformer_layers)、词嵌入的维度(d_model)等等。随后初始化了嵌入层self.embedding和指定个数的Transformer编码器self.transformer_blocks,是一个长度为self.num_transformer_layers的列表,每个元素都是一个独立的Transformer编码器,其参数互不干扰。还有一个2个节点的全连接层,用于下一句预测任务。
重点看一下调用时的call方法,我们将batch_x和batch_segment,输入embedding层得到嵌入层总输出,随后将浅层的嵌入经过一连串的Transformer模块,每次浅层的词嵌入经过编码后,都会得到更深层的词嵌入,并且embedding层的输出是最浅层的词嵌入。
编码完成后,将BERT编码的每个batch的第一个字(也就是’CLS’)的编码送入用于nsp任务的全连接层。即first_token_tensor = x[:, 0, :],形状是[batch, d_model],输入全连接层后,得到结果的形状是[batch, 2],也就是我们预测这一批次输入,每一条样本是/不是连续的两句话的logits(经过softmax即可转化成概率)。
另一方面,将编码的输出x(形状为[batch, seq_len, d_model])与嵌入层中token_embedding的字对应词嵌入表(.embeddings,形状为[vocab_size, d_model])转置后(transpose_b=True)相乘。得到我们对序列中每一个位置是词表中哪个字的预测mlm_predict,形状为[batch, seq_len, vocab_size]。这也是自然语言处理里很常见的方法了,从数值上看,编码结果与词表中对应词嵌入越相似,则内积越大,经过softmax后,预测为这个字的概率也就越大。
BERT预训练
预训练损失函数
这部分代码在Loss/loss.py下。
class BERT_Loss(tf.keras.layers.Layer):
def __init__(self):
super(BERT_Loss, self).__init__()
def call(self, inputs):
(mlm_predict, batch_mlm_mask, origin_x, nsp_predict, batch_y) = inputs
x_pred = tf.nn.softmax(mlm_predict, axis=-1)
mlm_loss = tf.keras.losses.sparse_categorical_crossentropy(origin_x, x_pred)
mlm_loss = tf.math.reduce_sum(mlm_loss * batch_mlm_mask, axis=-1) / (tf.math.reduce_sum(batch_mlm_mask, axis=-1) + 1)
y_pred = tf.nn.softmax(nsp_predict, axis=-1)
nsp_loss = tf.keras.losses.sparse_categorical_crossentropy(batch_y, y_pred)
return nsp_loss, mlm_loss
我把损失函数也设置成了tf.keras.layers.Layer,其实定义一个普通的函数也是可以的。Loss层的输入一共有五个,分别是:
mlm_predict,形状为[batch, seq_len, vocab_size],代表预测每个token是词表中哪一个字的logitsbatch_mlm_mask,形状为[batch, seq_len],值为1的代表那个位置的字被替换为'MASK'了origin_x,形状为[batch, seq_len],代表每个字的原始token idnsp_predict,形状为[batch, 2],代表预测每一个样本是/不是连续两句话的概率batch_y,形状为[batch,],代表批次中的每一条样本是/不是连续的两句话的真值,1代表是,0代表不是。
接下来看看遮挡语言模型任务的损失计算:
x_pred = tf.nn.softmax(mlm_predict, axis=-1)
mlm_loss = tf.keras.losses.sparse_categorical_crossentropy(origin_x, x_pred)
mlm_loss = tf.math.reduce_sum(mlm_loss * batch_mlm_mask, axis=-1) / (tf.math.reduce_sum(batch_mlm_mask, axis=-1) + 1)
首先用softmax操作将logits转化为概率,再使用tf.keras.losses.sparse_categorical_crossentropy来计算交叉熵损失,相较于通常的交叉熵损失函数,sparse_categorical_crossentropy可以直接传入真实值的index,而不需要将真实值转化成one-hot向量。这么做相当于为每一个token都做了预测,但我们只需要预测被替换为MASK的token,所以使用mlm_loss * batch_mlm_mask,二者的形状都是batch, seq_len,相乘之后,由于只有被替换成MASK的位置batch_mlm_mask的值为1,其余情况为0。这样,没有被替换的位置,其交叉熵损失就等于0,从而不影响我们的参数更新了。最后,我们对单个样本求平均,分母加1是为了避免分母为0的情况(其实不可能)。
而下一句预测任务更加简洁,只需要经过softmax操作,计算一个交叉熵就好了。
y_pred = tf.nn.softmax(nsp_predict, axis=-1)
nsp_loss = tf.keras.losses.sparse_categorical_crossentropy(batch_y, y_pred)
最后返回这两个损失,BERT预训练的总损失就是二者之和。
训练主程序
代码在主目录的pretrain.py下
model = Bert(Config)
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-4)
loss_fn = BERT_Loss()
dataset = DataGenerator(Config)
...
for step in range(len(dataset)):
batch_x, batch_mlm_mask, origin_x, batch_segment, batch_padding_mask, batch_y = dataset[step]
with tf.GradientTape() as t:
nsp_predict, mlm_predict, sequence_output = model((batch_x, batch_padding_mask, batch_segment),
training=True)
nsp_loss, mlm_loss = loss_fn((mlm_predict, batch_mlm_mask, origin_x, nsp_predict, batch_y))
nsp_loss = tf.reduce_mean(nsp_loss)
mlm_loss = tf.reduce_mean(mlm_loss)
loss = nsp_loss + mlm_loss
gradients = t.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
建立模型、损失函数和优化器后。在每一步的训练中:取出输入和真值,将输入句子传入模型编码,总的损失为mlm_loss和nsp_loss的和,使用tf.GradientTape记录梯度信息,t.gradient用来求模型的参数对于loss的梯度,最后使用optimizer的apply_gradients方法,即可完成一次参数的更新。程序里还使用了 T e n s o r B o a r d TensorBoard TensorBoard和tf.train.Checkpoint来记录损失变化和保存模型参数,就不详细展开了。
到这里,BERT就被我们造出来了~
结果展示
训练过程的损失函数变化曲线可以配置好TensorBoard后在代码目录下命令行输入tensorboard --logdir Logs后在对应端口看到。
3层Transformer,词嵌入维度等于256,Batch size=64的情况下,用GTX1660Ti 6G跑了大概一晚上,结果如下。遮挡语言模型的准确率能到11左右,下一句预测的准确率能较快的达到100%附近。





代码可见:
https://github.com/cmd23333/BERT-Tensorflow2.x
有问题可以评论或者直接issue。欢迎给星