基于用户的协同过滤和皮尔逊相关系数
概念:
基于用户的协同过滤算法:就是把和你相似的用户喜欢的东西推荐给你。
协同过滤:利用用户的群体行为来计算用户的相关性。计算用户相关性的时候我们就是通过对比他们对相同物品打分的相关度来计算的
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 5 | 4 | 1 | 5 |
--------+--------+--------+--------+--------+
b | 4 | 3 | 1 | ? |
--------+--------+--------+--------+--------+
c | 2 | 2 | 5 | 1 |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了4分,给Z打了1分
b用户给X物品打了4分,给Y打了3分,给Z打了1分
c用户给X物品打了2分,给Y打了2分,给Z打了5分
那么很容易看到a用户和b用户非常相似,但是b用户没有看过R物品,那么我们就可以把和b用户很相似的a用户打分很高的R物品推荐给b用户,这就是基于用户的协同过滤。
相关性
基于用户的协同过滤需要比较用户间的相关性,那么如何计算这个相关性呢?
我们可以利用两个用户对于相同物品的评分来计算相关性。
对于a,b用户而言,他们都对XYZ物品进行了评价,那么,a我们可以表示为(5,4,1),b可以表示为(4,3,1),经典的算法是把他们看作是两个向量,并计算两个向量间的夹角,或者说计算向量夹角的cosine值来比较,于是a和b的相关性为:

这个值介于-1到1之间,越大,说明相关性越大。
皮尔逊相关系数
到这里似乎cosine还是不错的,但是考虑这么个问题,用于用户间的差异,d用户可能喜欢打高分,e用户喜欢打低分,f用户喜欢乱打分。
--------+--------+--------+--------+
| X | Y | Z |
--------+--------+--------+--------+
d | 4 | 4 | 5 |
--------+--------+--------+--------+
e | 1 | 1 | 2 |
--------+--------+--------+--------+
f | 4 | 1 | 5 |
--------+--------+--------+--------+
很显然用户d和e对于作品评价的趋势是一样的,所以应该认为d和e更相似,但是用cosine计算出来的只能是d和f更相似。于是就有皮尔逊相关系数(pearson correlation coefficient)。
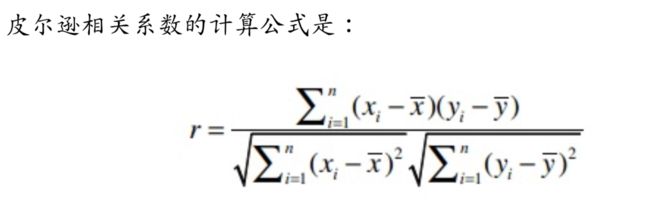
pearson其实做的事情就是先把两个向量都减去他们的平均值,然后再计算cosine值。
等价公式:

其中E是数学期望,N表示变量取值的个数。
代码
代码使用的是等价公式
from math import sqrt
# 比如有5个用户分别给自己看的电影打分,这些都是样本数据
users = {
'用户A': {'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2, '他人笑我太疯癫': 0},
'用户B': {'唐伯虎点秋香': 4, '喜欢你': 2, '暗战': 3.5},
'用户C': {'复仇者联盟1': 4.5, '逃学威龙1': 2, '大黄蜂': 2.5, '蜘蛛侠:平行宇宙': 2, '巴霍巴利王:开端': 4},
'用户D': {'狗十三': 2, '无双': 5},
'用户E': {'无双': 4, '逃学威龙1': 4, '逃学威龙2': 4.5, '他人笑我太疯癫': 3}
}
# 现在要给用户E找相似用户,称E为需求用户
user = '用户E'
userInfo = users[user]
pearson_result = []
for u in users:
# 遍历样本数据
if u != user:
# 对每一个样本与需求用户求皮尔逊距离
sum_x, sum_y, sum_x2, sum_y2, sum_xy, n = 0, 0, 0, 0, 0, 0
for key, value in users[u].items():
# 遍历用户打分的电影数据
if key in userInfo.keys():
# 找出需求用户样本用户观看的相同的电影,称为集合A
x = userInfo[key] # 需求用户对电影打的分
y = value # 样本用户对电影打的分
sum_x += x
sum_y += y
sum_x2 += pow(x, 2) # 求平方和
sum_y2 += pow(y, 2)
sum_xy += x * y
n += 1
if n > 0:
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
result = 0.
if denominator > 0:
result = (sum_xy - (sum_x * sum_y) / n) / denominator
print("{} to {} score => {}".format(user, u, result))
pearson_result.append(result)
print(pearson_result)
输出:
用户E to 用户A score => 0.9999999999999998
[0.9999999999999998]
推荐相关性较高的用户喜欢的商品
recommend_books.py
# -*-coding:utf-8-*-
import os
os.environ["DJANGO_SETTINGS_MODULE"] = "book.settings"
import django
django.setup()
from user.models import *
from math import sqrt, pow
import operator
class UserCf:
# 获得初始化数据
def __init__(self, data):
self.data = data
# 通过用户名获得商品列表,仅调试使用
def getItems(self, username1, username2):
return self.data[username1], self.data[username2]
# 计算两个用户的皮尔逊相关系数
def pearson(self, user1, user2): # 数据格式为:商品id,浏览次数
print("user message", user1)
sumXY = 0.0
n = 0
sumX = 0.0
sumY = 0.0
sumX2 = 0.0
sumY2 = 0.0
for movie1, score1 in user1.items():
if movie1 in user2.keys(): # 计算公共的商品浏览次数
n += 1
sumXY += score1 * user2[movie1]
sumX += score1
sumY += user2[movie1]
sumX2 += pow(score1, 2)
sumY2 += pow(user2[movie1], 2)
if n == 0:
print("p氏距离为0")
return 0
molecule = sumXY - (sumX * sumY) / n
denominator = sqrt((sumX2 - pow(sumX, 2) / n) * (sumY2 - pow(sumY, 2) / n))
if denominator == 0:
print("共同特征为0")
return 0
r = molecule / denominator
print("p氏距离:", r)
return r
# 计算与当前用户的距离,获得最临近的用户
def nearest_user(self, username, n=1):
distances = {}
# 用户,相似度
# 遍历整个数据集
for user, rate_set in self.data.items():
# 非当前的用户
if user != username:
distance = self.pearson(self.data[username], self.data[user])
# 计算两个用户的相似度
distances[user] = distance
closest_distance = sorted(
distances.items(), key=operator.itemgetter(1), reverse=True
)
# 最相似的N个用户
print("closest user:", closest_distance[:n])
return closest_distance[:n]
# 给用户推荐商品
def recommend(self, username, n=1):
recommend = {}
nearest_user = self.nearest_user(username, n)
for user, score in dict(nearest_user).items(): # 最相近的n个用户
for movies, scores in self.data[user].items(): # 推荐的用户的商品列表
if movies not in self.data[username].keys(): # 当前username没有看过
if movies not in recommend.keys(): # 添加到推荐列表中
recommend[movies] = scores
# 对推荐的结果按照商品浏览次数排序
return sorted(recommend.items(), key=operator.itemgetter(1), reverse=True)
def recommend_by_user_id(user_id):
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则按照热度顺序返回
if current_user.rate_set.count() == 0:
book_list = Book.objects.all().order_by("-sump")[:15]
return book_list
users = User.objects.all()
all_user = {}
for user in users:
rates = user.rate_set.all()
rate = {}
# 用户有给图书打分
if rates:
for i in rates:
rate.setdefault(str(i.book.id), i.mark)
all_user.setdefault(user.username, rate)
else:
# 用户没有为书籍打过分,设为0
all_user.setdefault(user.username, {})
print("this is all user:", all_user)
user_cf = UserCf(data=all_user)
recommend_list = user_cf.recommend(current_user.username, 15)
good_list = [each[0] for each in recommend_list]
print('this is the good list', good_list)
book_list = Book.objects.filter(id__in=good_list).order_by("-sump")[:15]
return book_list
# rec(1)