I. 介绍II. 背景A. 开发流程B. 谷歌的程序分析III. 谷歌程序分析理念A. 0误报率B. 授权用户做出贡献C. 改进数据驱动的可用性D. 工作流集成是关键E. 项目级别定制,而不是用户定制IV. 实现A. 架构B. 插件模型C. 分析器D. 修复E. 反馈V. 成果a)可用性:b)代码库影响:c)扩展性:d)可伸缩性:VI.相关工作VII. 探讨VIII. 致谢引用
译者的话
许多公司痛苦于将如何将SDL落地到企业开发流程中,而代码审计的环节相对容易实践起来。在对标学习期间顺手翻译了这篇google的最佳实践,当然Google、Netflix、SAP、salesfore、Amazon这类公司不会称其为SDLC,使用了DevSecOps的方法论这种说法,推行起来对于人员要求也较高,但是面临着行业的痛点是共性。知易行难,大家可以参考指标以避免走弯路,去做正确的事情。
其他关联阅读资料:
* [为什么Google上十亿行代码都放在同一个仓库里?](https://zhuanlan.zhihu.com/p/28524745)
* [Google 如何建立程序分析生态系统](https://wenku.baidu.com/view/067d99eea0c7aa00b52acfc789eb172ded639975.html)
原文链接:
[Tricorder: Building a Program Analysis Ecosystem](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43322.pdf)
以下是正文:
简介-静态分析工具帮助开发人员发现bug,提高代码可读性,并确保整个项目的风格一致。然而当扩展到大型代码库时,这些工具之间很难相互顺利集成进入开发流程中。我们提出了一个程序分析平台TRICORDER,旨在围绕程序分析构建一个数据驱动的生态系统。我们为我们的程序分析工具提供了一套指导原则,并为实现这些原则的分析平台提供了可伸缩的架构。我们对Google开发人员所使用的工具在实际的落地到生产系统进行验证,以显示出该平台的实用性和影响力。
I. 介绍
静态分析工具提供了一种很有前瞻性的方法,可以在程序的bug出现在生产系统之前找到它们。开发者可以在源代码上运行分析程序来发现问题,甚至在合入代码之前也可以。虽然对静态分析工具[3]、[14]、[16]等已有了详尽的研究,但这些工具在实际应用中往往没有得到有效的落地。误报率高、输出混乱、与开发流程的整合性差,这些都导致了在日常开发活动[23]、[27]中缺乏使用。
除了发现bug之外,工具还必须考虑到开发人员对[26]时间的紧迫要求。任何由自动化工具产生的中断输出都会迫使开发人员从主要目标[27]停顿下来。成功的静态分析工具可以增加高价值,同时最大限度地减少对已经很繁忙的软件工程师的干扰。
我们过去使用静态分析工具的经验还表明,其中许多工具无法扩展到谷歌规模的代码库。分析不能假定它们可以访问整个源存储库或所有编译结果;单个机器的数据太多了。 因此,分析必须是可分片的,并且能够作为分布式计算的一部分运行,只包含部分信息。判断分析必须非常快,并在几分钟内提供结果。在我们之前在谷歌的经验中,现有的分析平台无法以这种方式扩展伸缩。
我们还发现现有的平台和工具没有足够的可扩展性。谷歌有许多专门的框架和语言,理想的系统应该为所有这些框架和语言提供静态分析。我们理想的系统将允许领域专家编写自己的分析,而无需承担构建或维护整个端到端环节的成本。例如,编写c++库的团队可以编写检查,以确保开发人员正确使用这些库,而不必担心运行大型生产系统所固有的问题。
在谷歌上试错了各种商业和开源程序分析工具之后(有关更多细节,请参阅第二部分),我们一再遇到工具可伸缩性或可用性方面的问题。基于这些经验教训,我们想创建一个静态分析平台,它将:
•开发人员广泛而积极地使用它来修复代码中的问题,而不需要得到一小群拥护者或管理层的鼓励。
•顺利地集成到现有的软件开发流程中。
•扩展到海量代码库规模。
•使开发人员,甚至非软件分析专家能够编写和部署他们自己的静态分析规则。
在本文中,我们介绍了TRICORDER,一个程序分析平台,旨在围绕静态分析构建数据驱动的生态系统。TRICORDER将静态分析集成到谷歌开发人员的工作流程中,在开发人员和分析器编写人员之间提供反馈循环,并简化了分析工具发现的修复问题。为了实现这一点,TRICORDER利用微服务体系结构来扩展到谷歌的代码库,并且每天生成大约93,000个分析结果。除了开发平台的开源版本之外,一个由2-3人组成的小团队维护着TRICORDER及其周围的生态系统[35]。TRICORDER的插件模型允许整个公司的团队成员加入Google的程序分析社区
本文的贡献包括:
•一套指导原则,使谷歌的程序分析平台获得成功,得到广泛应用。(第三节)
•程序分析平台的可扩展架构。该平台通过工作流程集成,支持贡献者,响应反馈和自动修复来构建程序分析生态系统。(第四节)
•基于开发人员在正常工作流程中对分析的响应,对平台的效用进行实证和现场验证。(第五部分)
II. 背景
A. 开发流程
在谷歌中,大多数工程师都在一个非常大的代码库中工作,在这个代码库中,大多数软件开发都是在head里进行的。在谷歌,每个工作日,工程师执行超过800k构建,运行100万个测试用例,生成2PB的构建输出,并发送30k变更列表快照(patch diffs)供评审。
大型代码库有很多好处,包括代码复用的易用性和以原子粒度地进行大规模重构的能力。由于代码复用很常见,大多数代码依赖于一组核心库,对这些基本库进行更改可能会影响许多项目。为了确保变更不会破坏其他项目,谷歌拥有强大的测试文化,并由持续测试基础设施[43]、[15]为后盾。
谷歌工程师使用标准化的分布式构建系统从源代码[20]生成独立构建。一组专门的工程师集中维护这个基础设施,提供了一个插入分析工具的通用配置。因为谷歌工程师使用相同的分布式构建环境,所以他们可以使用自己选择的编辑器。编辑器的选择包括但不限于Eclipse、IntelliJ、emacs和vim[38]。作为一种强大的代码评审文化的一部分,每一个新的补丁,称为变更列表,在签入之前都会由其他人的人来评审。工程师使用类似Gerrit[19]的内部代码审查工具执行这些审查。此工具提供了对代码行进行注释,回复现有注释,上载正在审阅的代码(作者)的新快照以及批准更改列表(审阅者)的功能。
繁忙的工程师测试(并分析)他们自己的代码,而不是使用单独的QA流程。这意味着分析结果必须以工程师为目标,并且这些工程师必须易于运行和响应分析程序。因为大多数要发布的代码都是服务器代码,所以推出新版本的成本非常低,使得在代码发布后修复bug相对容易。
B. 谷歌的程序分析
为了将程序分析工具集成到谷歌开发工作流中,已经进行了几次尝试。特别是findbugs[18]在谷歌[5]、[3]、[4]以及Coverity[12]、Klocwork[24]、故障预测[28]等分析工具上都有很长的实验历史。由于工作流集成、可伸缩性和误报方面的问题,所有这些工具在很大程度上已经不再使用。有些工具显示结果太迟,使得开发人员在提交代码后不太可能修复问题。另一些人过早地显示结果,而开发人员仍然在编辑器中使用他们的代码。基于编辑器的工具也遇到了扩展问题:它们对交互使用的延迟需求无法跟上代码库的大小。几乎所有的工具都必须作为一个独立的步骤来运行,并且很难与标准编译器工具链集成。我们一再发现,当开发人员必须导航到仪表板或运行独立的命令行工具时,分析使用率就会下降。
即使在开发人员运行这些工具时,它们也常常产生很高的误报率和无法执行的结果[28]。这些经验与之前的研究一致,说明了为什么开发人员不使用静态分析工具[23]。最后,很少有开发人员使用我们之前试验过的任何工具,甚至在最引人注目的分析中-FindBugs,这个命令行工具在2014年也只被35个开发人员使用过(其中只有20个开发人员使用过一次)。我们之前确实在代码评审[3]中显示了FindBugs结果,但是这个尝试遇到了伸缩性问题(导致结果陈旧或延迟),【译者注:关于这一篇,可以看到《
【翻译】Google在构建静态代码分析工具方面的经验教训
》】并且产生了许多开发人员不感兴趣的结果。相比之下,TRICORDER将成功作为标准开发流程的一部分。III. 谷歌程序分析理念
A. 0误报率
“0误报”可能有点夸张,但我们严格限制了允许分析产生的误报数量。误报对可用性和采用[8]、[23]、[33]都是不利的。
关于“误报”一词的确切含义存在分歧。对于分析者来说,误报是他们的分析工具产生的不正确的报告。然而,对于开发人员来说,任何他们不想看到[5]的报告都是误报。
我们倾向于使用“有效误报率”这个术语来概括开发人员的观点。我们将有效的误报定义为来自工具的任何报告,其中用户选择不采取行动来解决该报告。作为一个例子,一些谷歌开发人员使用静态注释检查系统(例如用于数据竞争检测[34])。当一个注释检查工具正确地报告一个问题,它可能意味着有一个错误在源代码中(例如,变量实际上不受锁定保护),或者代码实际上是正常的但是注释集合不是足够详尽的工具。通常在程序分析研究中,后者不被认为是误报——开发人员需要向工具提供额外的信息。然而,一些开发人员认为这些问题是“误报”的,因为它们不代表代码[36]中的错误。
相反,我们发现如果分析错误地报告错误,但是提出建议的修复将提高代码可读性,这不被视为误报。易读性和文档分析经常被开发人员所接受,特别是当他们提出改进建议时。值得注意的是,某些分析可能在理论上有错误的假设,但在实践中却没有。例如,只有当程序以不寻常的方式构建时,分析才可能具有误报,但实际上,从未见过这样的程序。这样的分析可能具有理论误报,但在具有严格执行的风格指南的环境中,它实际上将具有零误报。
最重要的是,开发人员将决定分析工具是否具有高影响力,以及误报是什么。
B. 授权用户做出贡献
在使用各种语言和自定义API的公司中,没有任何一个团队拥有编写所有必要分析所需的领域知识。整个公司的开发人员之间都存在相关的专业知识和动力,我们希望通过授权开发人员贡献自己的分析来利用这些现有的知识。开发人员的贡献既丰富了可用的分析集,又使用户对分析结果的贡献更大。
然而,尽管这些贡献者是他们领域内的专家,但他们可能没有足够的知识或技能来有效地将他们的分析集成到开发人员工作流程中。理想情况下,使分析启动并运行所需的工作流集成和模板文件不应该是分析作者所关心的。这就是TRICORDER的用武之地,它是一个可插入的程序分析平台,支持整个公司的分析贡献者。
为了保持分析程序的高质量,我们与分析程序的编写有一个“合同”,关于我们什么时候可以从TRICORDER中移除他们的分析程序的权利。也就是说,如果:
没有人正在修复针对分析程序提交的bug。。
资源使用(例如CPU /磁盘/内存)正在影响TRI-CORDER性能。在这种情况下,分析器编写器需要开始维护TRI-CORDER调用的独立服务(有关详细信息,请参阅第四节a)。
分析器的结果让开发人员很恼火(有关如何计算该值,请参见第IV-E节)。
我们的经验是,工作中的自豪感加上禁用分析程序的威胁,使得作者非常积极地解决分析程序发现的问题。
C. 改进数据驱动的可用性
回应反馈很重要。开发人员使用分析工具构建信任,如果他们不理解工具的输出[8],这种信任很快就会丢失。我们还发现(通过收集针对分析程序的bug报告),许多分析结果都有令人困惑的文字信息;这通常是一个容易解决的问题。例如,对于一个分析人员来说,来自TRICORDER的针对该工具的所有bug中,75%是由于对结果措辞的错误解释造成的,并通过更新消息文本和/或链接到其他文档来修复。建立反馈循环以提高分析结果的可用性可以显著提高分析工具的实用性
D. 工作流集成是关键
将开发人员的工作流程集成到有效的[23]程序分析工具中是一个关键方面。如果一个分析工具是开发人员希望运行的独立二进制文件,那么它就不会像预期的那样频繁地运行。我们认为分析应该由开发人员事件自动触发,例如编辑代码,运行构建,创建/更新更改列表或提交更改列表。分析结果应该在代码检入之前显示,因为当工程师必须修改(可能工作的)提交代码时,权衡是不同的。我们调查开发人员向他们发送更改列表以修复我们计划在编译器错误时打开的代码中的错误,以及他们在编译器错误中遇到这些错误时。当遇到编译器错误时,开发人员认为错误代表重大错误的可能性是其两倍。早期显示结果的重要性与以前使用Find-Bugs [3]的经验相匹配。
如果可能,我们将静态分析集成到构建[2]中。我们支持基于ErrorProne的javac扩展[17]和Clang编译器[10]构建的各种分析。这些分析在发现问题时会中断构建,因此有效误报率必须基本为零【译者注:源代码分析可以发现质量、安全、测试类的问题,是否中断构建取决于企业质量门的阈值】。它们也不能显著地降低编译速度,因此必须有< 5%的开销。理想情况下,我们只显示导致构建失败的结果,就像我们发现构建经常被忽略时显示的警告一样。然而,构建集成并不总是实用的,
例如当误报率过高时,分析过于耗时,或者仅在新编辑的代码行上显示结果是值得的。
TRICORDER介绍了一个显示警告的有效位置。由于谷歌的所有开发人员在提交更改之前都使用代码评审工具,所以TRICORDER的主要用途是在代码评审时提供分析结果。这样做的另一个好处是启用了对等的问责机制,审查人员将看到作者是否选择忽略分析结果。我们仍然执行非常低的有效误报率(< 10%)。此外,默认情况下,我们只显示更改行的大多数分析结果;这使得分析结果与手头上的代码评审保持一致。在代码评审时完成的分析可能比中断构建的分析花费更长的时间,但是结果必须在评审结束前可用。审查多行的平均时间大于1小时;我们通常希望分析在不到5 10分钟内完成(理想情况下要少得多),因为开发人员可能在等待结果。
对于程序分析,还有其他潜在的集成点。许多ide包含各种静态分析。然而,大多数谷歌开发人员不使用ide,或者不使用ide来完成所有[38]任务,这使得ide集成成为不可能。尽管如此,IDE并不排除IDE集成,因为IDE可以向TRICORDER服务发出rpc。我们还利用测试来运行动态分析工具,比如ThreadSanitizer [39],[40]或AddressSanitizer[1]。这些工具通常没有误报和<10x的减速。TRICORDER还将谷歌的代码搜索工具中的一些分析结果夜间显示为可选图层。虽然大多数开发人员不使用该功能,但对于误报率较高的分析和具有专门的清理团队来筛选结果的分析来说十分有效。
E. 项目级别定制,而不是用户定制
谷歌过去的经验表明,允许特定于用户的定制会导致团队内部和团队之间的差异,并导致工具使用率下降。我们观察了这样的团队:当发现团队成员提交了包含该工具标记的警告的新代码时,开发人员放弃了他们最初使用的工具。我们努力消除每个用户对分析结果的定制。
为了实现这一点,我们取消了所有分析结果的优先级或严重性评级。相反,我们试图只显示高优先/严重程度的结果,并且当结果被标记为不重要时,我们会改进我们的分析工具。在对分析是否有有用的结果存在争议的情况下,我们可以选择性地进行分析。开发人员仍然能够显式地触发可选分析器,但是默认情况下它们不会运行。取消优先级有几个好处:
•我们能够删除或改进没有什么好处的低优先级检查。
•我们没有让开发人员过滤掉分析器的结果,而是开始得到关于错误的分析器的bug报告。例如,我们发现c++ linter也在linting Objective-C文件,并修复了这个问题;以前Objective-C开发人员只是隐藏了所有linter结果。
•我们大大减少了对某些结果出现的抱怨,或对不同观点不一致的抱怨。
我们允许有限的定制,但是定制是基于项目的,而不是基于用户的。例如,团队可以选择在默认情况下对所有代码运行可选分析。我们还禁用了不适用的分析程序;例如,我们不会在具有不同代码约定的第三方开放源代码上运行代码样式检查器。
IV. 实现
A. 架构
为了在变更列表创建和编辑上有效地提供分析结果,TRICORDER利用了微服务架构[29]。从服务的角度考虑问题会产生一种鼓励可伸缩性和模块化的思维方式。此外,TRICORDER利用了微服务架构的设计假定了系统的某些部分会出现故障,这意味着分析人员被设计成可复制的无状态的,以使系统具有可靠性和可扩展性。使用代码评审工具的注释系统,分析结果将作为机器人注释(简称robocomments)出现在代码评审中。
分析服务实现相同的API (Section IV-B)。该API使用协议缓冲区[31]定义为一种多语言序列化协议,并使用特定于google的RPC库进行通信。TRICORDER包含一系列用不同语言 (Java、c++、Python和Go)编写的分析器工作服务,这些语言实现了这种与语言无关的协议缓冲API。这些服务为分析器提供了一个特定于语言的接口,以实现抽象处理RPC的细节;分析作者可以用最有意义的语言实现分析器。TRICORDER还包括特定于编译器的分析服务,提供了一种插入jscompiler、javac和Clang的方法。此外,我们还有一个二进制多路复用器Linter工作者服务,支持用任意语言编写的字符串。
TRICORDER有三个阶段,在这三个阶段中,它调用分析服务;每个阶段都有更多的信息。
图1:TRICORDER体系结构的概述。实体框对应于作为作业运行的微服务,虚线框区分作业的不同部分。实箭头对应于在TRICORDER中发送的RPC,而虚线指的是指向外部系统和服务的RPC。
在FILES阶段,分析程序可以访问组成更改的文件的内容。例如,在这个阶段可以运行来检查诸如“line is over 80 characters”之类的属性。在DEPS(构建依赖关系的缩写)阶段,分析人员还知道所有由变更影响的构建目标的列表。例如,可以在此阶段运行一个分析程序,该程序报告何时有大量目标受到影响。最后,在编译阶段,分析人员可以使用完全解析的类型和隐式表达式访问整个程序的完整AST。将分析划分为多个阶段有几个实际的好处:
•我们可以在早期阶段为分析提供更快的结果,因为它们不需要等待构建。•我们可以在成本较高的阶段通过速率限制分析来减少资源使用。
•我们依赖的基础架构问题(例如构建服务)不会影响早期阶段的分析。 TRICORDER的整体架构如图1所示
TRICORDER的主循环发生在分析驱动程序中。驱动程序调用特定于语言或编译器的分析器工作人员来运行分析,然后将结果作为注释发送到代码评审系统。在每个worker中,传入的分析请求被分派到一组分析器。此外,分析作者可以选择使用analyzer worker API实现他们自己的独立服务。对于pipeline的不同阶段,分析驱动程序被分成不同的部分:Snapshot Listener向FILES分析器发送请求,Targets Listener向DEPS分析器发送请求,Build Listener向COMPILATION分析器发送请求。过程如下:
1)当生成一个新的变更列表快照时,变更列表快照通知器(通过发布者/订阅者模型)向TRICORDER发出信号,表示有一个新的快照。此消息包含关于快照的元数据(例如作者、变更列表描述和文件列表),以及一个源上下文(存储库名称、修订等),可以使用该上下文读取更改中已编辑的文件,并在稍后发布关于更改的机器人评论。当TRICORDER收到一个快照提醒时,它会发出几个异步调用:
•tricorder向文件分析器发送分析请求。当它收到结果时,它将结果转发给代码评审系统。
•tricorder向dependencies服务发出请求,以计算哪些构建目标受到更改的影响2)Dependencies Service在完成计算依赖关系后通知TRICORDER,TRI-CORDER进行以下异步调用:
•TRICORDER向DEPS分析器发送分析请求,并附带受变更影响的依赖项列表。当TRICORDER收到分析结果时,它会将它们转发给代码审查服务。
•TRICORDER请求Build Service启动直接受更改影响的所有目标的构建。3)构建服务在每个独立的编译单元构建时通知TRICORDER。构建用于捕获所有支持语言中每个编译器调用所需的所有输入。保留这组输入(例如jar文件,编译器参数,标题等)以供分析器以后使用。
当一条消息到达时,它向完成的编译单元发出信号,TRICORDER将RPC发送到COMPILATION分析器。特定于编译器的工作程序使用添加的分析通道重放编译(使用构建期间生成的输入)。 COMPILATION分析器可以访问AST和编译器提供的所有其他信息。当TRICORDER从分析器接收结果时,它们将被转发到代码审查服务。
异步通信的使用使TRICORDER能够更有效地利用其机器资源。早期的分析可以在运行构建时并行运行,并且编译单元也都是并行分析的。即使是最慢的分析也能在几分钟内提供结果。
B. 插件模型
TRICORDER支持跨语言的插件模型。分析器可以用任何语言编写;目前c++、Java、Python和Go都有最好的支持。分析器可以分析任何语言,甚至有各种各样的分析器关注于开发过程,而不是编程语言(Section IV-C)。
所有分析器服务都实现分析器RPC API。大多数分析程序作为分析worker之一的一部分运行,并实现特定于语言的接口。每个分析器必须支持以下操作:
1) getcategory返回该分析器生成的一组类别。分析器的类别是一个独特的人类可读的名称,显示为它生成的robocomments的一部分。
2) getstage返回这个分析器应该运行的阶段。
3) 分析接收有关更改的信息,并重新生成一个记录列表。
Notes包括有关分析结果的主要资料,包括:
分析结果的类别(以及可选的子类别)。
分析结果在代码中的位置,例如文件和该文件中的范围(行/列)。
错误消息。
包含关于分析器和/或消息的更详细信息的URL。
修复程序的有序列表。
生成的注释随后作为robocomments发布到谷歌的内部代码审查工具中。由于结构化输出是灵活的,所以它们还可以用于其他上下文(例如浏览源代码时)。在开源版本的Tricorder, Ship- shape[35]中可以获得这个API的更详细的信息。Shipshape有一个不同的体系结构来支持开源项目的需求,但是API和设计深受TRICORDER的影响。
C. 分析器
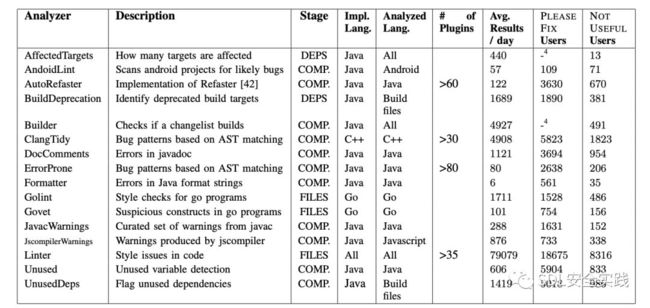
图2显示了一个选择的16个分析器,目前运行在TRICORDER(目前大约有30个,每个月都会有更多的上线)。
这个表中的六个分析器本身就是框架。例如,容易出错的[17]和ClangTidy[11]都分别基于Java和c++程序的AST匹配找到bug模式。它们都启用了各种单独的检查,每个检查都作为插件实现。另一个例子是Linter分析器。该分析器由超过35个独立的插件组成,所有这些插件都是通过linter二进制多路复用器调用的。插件可以用任何语言实现。多路复用器使用配置文件来确定要将特定文件发送到哪个linter(基于文件扩展名和路径),以及如何解析linter输出(通过正则表达式)。linter 检查器包括google配置的流行外部插件版本,如Java Checkstyle linter[9]和Pylint Python linter[32],以及许多自定义内部检查器。
图2:30台分析器中有16个以TRICORDER方式运行。第四和第五列报告了隐含语言和目标语言,区别。第六列报告了提供内部插件机制的分析器的插件数量。第七列显示每天的平均结果。最后两列报告惟一用户的数量。谁在2014年点击了请修复或无用(见第四- e节)。
几种分析器(目前有7种)是领域专用的;它们只针对代码库的一部分。这包括AndroidLint,它可以发现Android项目中特定的bug和样式冲突,以及一些特定于项目的配置模式的验证器。其他几个分析程序(另外7个)是关于向变更列表提交元数据的。例如,一个分析人员警告变更列表是否需要与head合并,而另一个分析人员警告变更列表是否会暂时影响谷歌代码的很大一部分。
为了决定一个分析器是否有意义,包括在TRICORDER,我们有新的分析器的标准,从我们的经验和理论的静态分析(第三节):
1)警告应该易于理解,修复应该清晰。当被指出时,问题应该是明显的和可操作的。例如,圈复杂度或基于位置的故障预测不满足这个标准。
2)警告应该有很少的误报。 开发人员应该认为我们至少有90%的时间都在指出实际问题。为了衡量这一点,我们在现有代码上运行分析器,并手动检查结果的统计样本大小。
3)警告应该针对可能产生重大影响的事情。 我们希望警告足够重要,以便当开发人员看到它们时,他们会认真对待并经常选择修复它们。 为了确定这一点,以语言为中心的分析器由语言专家进行审查。
4)警告应以较小但可通知的频率发生。检测从未真正发生过的警告是没有意义的,但是如果警告发生得太频繁,它很可能不会导致任何真正的问题。我们不想给人们太多的警告。
分析开发人员可以首先尝试对一小组白名单用户进行新的分析,这些用户首先会自愿查看实验结果。一些分析也可以在MapReduce上运行,覆盖所有现有代码,以在部署之前检查误报率。
D. 修复
分析工具的两个常见问题是,它们可能不会产生可执行的结果,而且繁忙的开发人员需要花费精力来修复突出显示的问题。为了解决这些问题,我们鼓励分析开发者在分析结果中提供修复建议。可以在代码评审工具中查看和应用这些修复程序。图3显示了由TRICORDER生成的示例注释。单击“show”链接后就可以看到修复程序(图4)。请注意,这里的修复程序没有绑定到特定的IDE,它们是每个分析的一部分与语言无关。让分析程序提供修复有几个好处:修复程序可以为分析结果提供额外的澄清,能够直接应用修复程序意味着处理分析结果不需要更改上下文,而工具提供的修复程序降低了修复代码中问题的门槛。为了应用补丁,我们利用了一个系统的可用性,该系统使变更列表的内容可用于编辑。也就是说,编辑就像应用补丁一样,可以直接对变更列表中的代码进行修改,修改后的代码将出现在变更列表所有者的工作区中。要实现与Gerrit类似的东西,可以利用现有api将补丁作为补丁应用于正在审查的代码。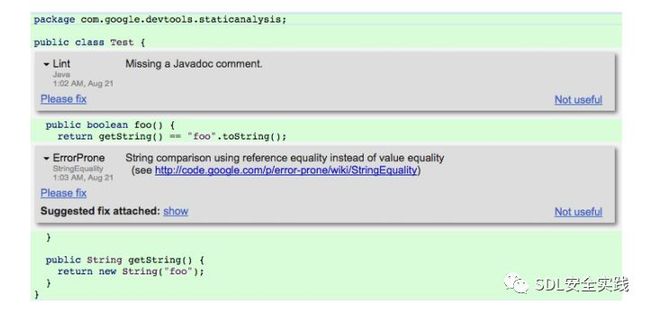
图3:分析结果的屏幕截图; 更改列表审阅者视图。 在这种情况下,有两个结果:一个来自Java Lint工具(checkstyle [9]的配置版本),另一个来自ErrorProne [17]。 如果分析结果有问题,审阅者可以单击NOT USEFUL链接。 他们也可以点击PLEASE FIX来表明作者应该修复结果。 他们还可以查看附加的修复程序(图4)。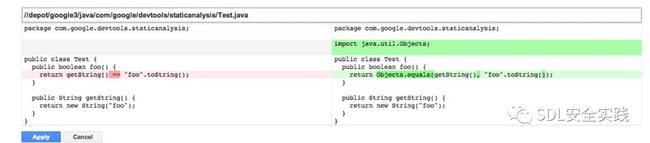
图4:图3中ErrorProne警告的预览修复视图的屏幕截图
E. 反馈
为了快速响应分析程序的问题,我们构建了一个反馈机制,跟踪开发人员如何与代码评审中生成的robocomments交互。如图3和图4所示,开发人员可以点击四个链接:
•没有用给开发人员机会提交关于robocomment的bug。
•请修复创建一个评论评论,要求作者修复robocomment,并且只对评论者可用。
•预览修复(图3中的“show”)显示了建议修复的差异视图,当robocomment附带修复时可用。
•Apply FIX(图4中的“Apply”)将建议的修复应用于代码,只有当robocomment附带修复时,作者才能使用它。此选项只能在使用预览修复后才能看到。
我们将分析器的“无用率”定义为:
NOT USEFUL/(NOT USEFUL + PLEASE FIX + APPLY FIX)
分析作者需要通过我们提供的仪表板检查这些数字。一个≥10%的比率使分析器处于试用状态,分析作者必须在解决问题方面显示出进展。如果速率超过25%,我们可能决定立即关闭分析器。在实践中,我们通常与分析程序编写人员一起解决问题,而不是立即禁用分析程序。一些分析程序只影响一小部分开发人员,因此我们不太担心出现暂时性的误报。尽管如此,有一个合适的策略已经被证明是非常宝贵的,可以让分析人员清楚地了解预期。
V. 成果
a)可用性:
我们通过无效的点击率和每种类型的点击次数来衡量TRICORDER的可用性,无论是对于整个TRICORDER还是对于特定的分析器。
图2显示开发人员通过点击积极参与分析。图2列出了2014年为每个分析器点击了至少一次的FIXASE FIX或者USEFUL的唯一用户数。可以看出,Linter已经在2014年从超过18,000名用户那里获得了PLEASE FIX点击。所有类别中点击“不好用”的用户数量大幅下降。
我们的点击率表明,开发人员通常对静态分析工具的结果感到满意。图5
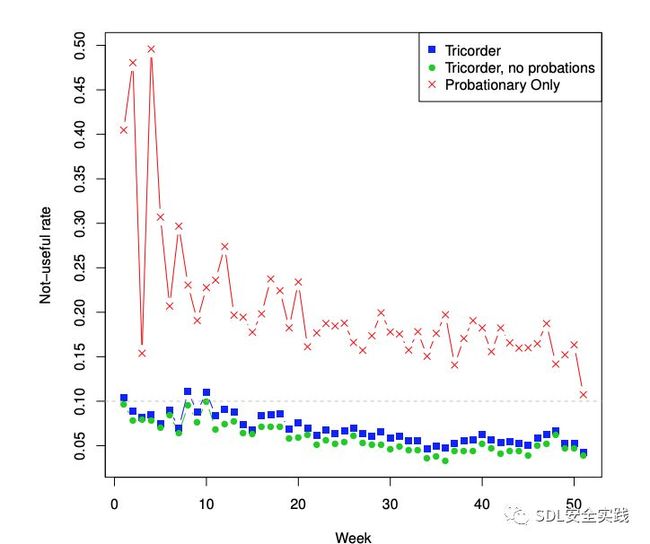
显示了所有TRICORDER分析器的一周;最近几个月,它通常在5%左右。当我们移除正在试用的分析器时,这个数字会下降到4%以下。

图6显示了几种Java分析器的无用速率的比较。 Checkstyle,ErrorProne和Unused-Deps分析都相当稳定,并且具有较低的not-useful; ErrorProne的数据由于产生的结果数量较少而具有更多的差异。 DocComments更有趣;该分析器最初处于试用期,开发人员努力将not-useful率降至10%以下。但是,第24周引入了一个错误,导致NOT USEULUL点击量急剧增加。开发人员能够使用我们提供的错误报告和点击日志来确定问题的根源,修复程序最终在第33周发布。
分析器开发者还可以分析每周的原始点击量。图7

显示了用于易出错分析的单击类型的细分。有趣的是注意到PLEASE FIX与PREVIEW FIX是多么相关;我们假设很多次,审核人单击PLEASE FIX,然后作者单击PREVIEW FIX查看问题是什么。APPLY FIX的点击量要低得多。基于开发人员的观察,我们假设许多开发者选择在他们自己的编辑器中修复代码,而不是使用代码审查工具来实现这一目的,特别是当他们已经在编辑器中处理其他审查者的评论时。请注意,提供修复方案有两个目的;一个是让开发人员轻松应用修复,而另一个是分析结果的进一步解释。
点击是对分析器质量的一种不完善的衡量:
许多开发人员在他们的review人员看到问题之前就报告修复问题,所以PLEASE FIX的数量是已知的较低的。
许多开发人员报告在他们自己的编辑器中修复问题,而不是通过APPLY FIX,所以这些数量也很低。
开发人员可能会忽略他们不打算修复的结果,而不是点击NOT USEFUL。这可能只是一个信号,表明开发人员对这个问题的感受有多强烈。
开发人员可能会偶然点击“NOT USEFUL”。
尽管有这些缺点,但点击一直是“开发人员烦恼”的好信号。我们最成功的分析仪的有效率在0-3%之间。
当开发人员单击“NOT USEFUL”时,会出现一个链接,将我们的问题跟踪系统中的一个bug提交给负责该分析器的项目;这个bug预先填充了关于robocomment的所有必要信息,并为开发人员提供了一个机会来评论为什么他们点击了NOT USEFUL。根据分析程序的不同,每次NOT USEFUL点击的错误率在10-60%之间.
b)代码库影响:
随着时间的推移,TRICORDER减少了代码库中违规实例的数量。对于ClangTidy分析器,我们可以看到,在代码评审中显示结果不仅可以防止新问题进入代码库,而且当人们了解新的检查时,还可以减少问题的总数。图8
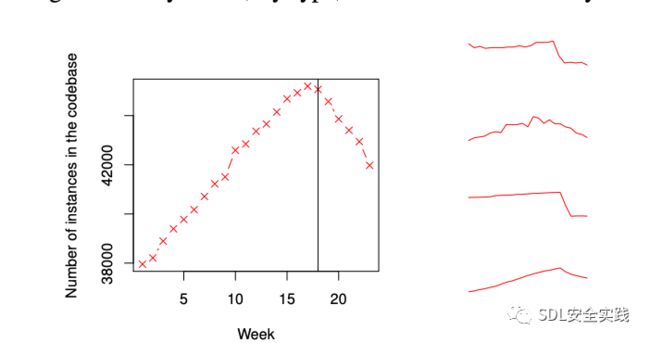
显示了每周发生ClangTidy misc-冗余-smartpt -get检查的次数;此检查标识了对智能指针不需要“.get()”调用的情况。垂直的线是这个检查开始在TRICORDER中显示的时候。在将check添加到TRI- CORDER之后,随着开发人员认识到不适当的cod- ing模式、停止在新代码中犯这样的错误,以及修复代码中其他地方出现的错误,代码库中的实例数量急剧减少。图8还显示了其他ClangTidy修复的趋势线示例;在TRICORDER中启用检查后,它们都显示了类似的下拉模式或水平下拉模式。只有水平的检查通常使用更复杂的非本地修复程序进行检查。
c)扩展性:
TRICORDER扩展方便。我们通过证明各种分析已经成功地插入,来评估这一点。正如IV-C节所讨论的,有超过30种不同的分析采用TRICORDER。图2显示了选择的16台分析器;这些分析者跨越了广泛的语言和突出的问题。这个表中的16个分析程序中有13个(除了Formatter、Build- Deprecation和Builder之外)是由其他10多个团队的成员提供的。许多其他开发人员向易出错、ClangTidy或Linter等分析程序提供了插件。
d)可伸缩性:
TRICORDER可以扩展到非常大的代码库。为了评估这一点,我们对每天在谷歌生成的所有变更列表快照运行TRICORDER。图9
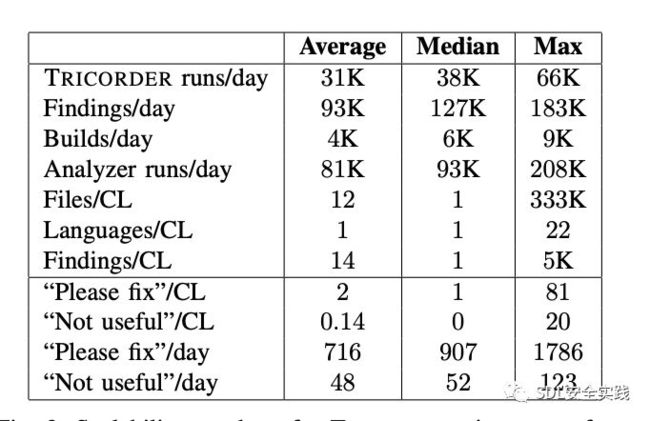
显示了TRICORDER的几个伸缩指标的平均值、中值和最大值。
平均每天,我们对31K个快照运行TRICORDER,每个快照的平均大小为12个文件,我们报告几个类别和语言的结果。相比之下,ReviewBot[7]对34个评审请求(对应于变更列表)进行了评估,而我们用于评估TRICORDER的请求有数百万个。平均而言,每个快照包含来自一种语言的文件,最多22种语言。总共一天,我们报告了大约30个类别的93K个结果。TRICORDER每天也运行接近5K的构建。每天,Review人员点击PLEASE FIX平均716项发现(来自Linters的416项),但只有48项发现没有得到有用的点击。一个普通的CL有两次“please-fix ”点击和没有not-useful 的点击。尽管我们的搜索结果比点击量要多得多,但大多数搜索结果并没有显示在评论中,因为它们显示在未修改的行上.
VI.相关工作
之前的一项研究调查了为什么开发人员不使用静态分析工具来发现bug,并从20个开发人员的[23]视图中收集结果。本研究的许多结论与我们使用之前的程序分析工具进行实验的经验相吻合。TRICORDER解决了本研究发现的主要痛点。例如,通过维护一个紧密的反馈循环,TRICORDER不断地确保工具输出得到改进,并且结果是可以理解的。TRICORDER还支持通过代码评审集成工具结果的协作;review者可以对静态分析结果提出建议或建议。本研究还强调了工作流程集成的重要性,这是TRICORDER的一个主要设计要点。
静态分析工具的研究非常广泛;我们只能在这里描述现有工具的一部分。FindBugs[18]是一个基于启发式的bug查找工具,它运行在Java字节码上。Coverity[12]、Klocwork[24]和Semmle[37]、[14]是专注于静态分析的商业工具。Linting工具如Checkstyle (java)和Pylint (Python)主要关注样式问题(间距、换行位置等)[9]、[32]。
在Eclipse[41]和Intellij[22]等ide中,分析结果和快速修复程序也常常是表面的。我们也可以通过在IDE中调用我们的service来在这里显示TRICORDER结果。许多商业工具还以看板格式[12]、[37]、[24]显示结果;虽然我们确实有dashboard,但我们发现,这只对分析程序编写者有用,帮助他们提高分析程序的质量。其他大公司,如微软,也在积极探索将静态分析集成到开发人员工作流[25]中的方法。Ebay开发了评估和比较不同静态分析工具在[21]实验中的价值的方法。IBM还试验了基于服务的静态分析方法[30]。这项工作是通过与IBM的几个团队进行的试点和调查进行评估的,他们确定了几个需要改进的领域。TRICORDER解决了这些改进中的每一个:它被集成到开发人员工作流中(而不是以批处理模式运行),它是可插拔的,并且支持由其他团队编写的分析,它还包含一个反馈循环,供分析作者使用改进平台和分析器。
之前发布的一个名为ReviewBot的系统在代码评审[6]和[7]中显示了静态分析结果。ReviewBot与TRICORDER的不同之处在于审阅人员必须显式地调用ReviewBot,分析结果不会显示给审阅人员,目前只支持三种(Java)静态分析工具。ReviewBot还增加了提供修复功能;这个修正系统与分析结果完全解耦。相反,TRICORDER修复程序是由分析程序生成的,而我们应用修复程序的机制(来自结构化分析结果)是与语言无关的。
与之前的工作不同,我们在开发人员工作流期间评估了TRICORDER,而不是作为对开发人员在其工作环境之外生成和看到的结果的调查。这种评估风格使我们能够看到开发人员在实际环境中的反应,而不是在实验室环境中。
VII. 探讨
TRICORDER自2013年7月开始投入生产。通过实现、启动和监视TRICORDER,我们了解了一些关于如何使程序分析工作的有趣的事情。在第三节中,我们概述了我们的理念,包括我们系统的目标和从过去经验中吸取的教训。现在我们重新审视我们的目标和提出的评估。
改进数据驱动的可用性。最后,开发者将决定一个分析工具是否具有高影响力,以及他们认为什么是误报。开发人员不喜欢误报。这就是为什么听取开发人员的反馈并采取行动是很重要的。平均每天有93K个发现,平均收到716个“请修复”和48个无用的点击。我们密切关注这些点击,如果需要,我们会让分析人员试用。我们讨论了分析器作者的改进,并鼓励他们改进他们的分析器——这种改进可能仅仅是更新结果的措辞。
授权用户进行贡献。TRICORDER通过提供一个可插入的框架来实现这一点,该框架允许开发人员在其专业领域内轻松地贡献分析。事实上,在TRICORDER中运行的大多数分析都是由管理TRICORDER本身的团队之外的开发人员提供的分析。
集成工作流程是关键。与VMWare[7]以前的预感知工具一样,我们发现代码重新查看是显示分析结果的绝佳时机。开发者在签入更改之前接收反馈,并且显示分析结果的机制是统一的——不管以前使用的是哪种IDE或开发环境。评审人员还可以看到并响应分析结果,从而承担同行责任;审稿人每周平均点击“请修复”5117次。
项目级别定制,而不是用户定制。根据经验,我们发现项目级的定制比用户级的定制更成功。这提供了灵活性,这样开发团队就可以用一种联合的方法来开发项目的代码,并且避免了开发人员之间关于分析结果的分歧,这可能会导致结果被忽略。除了上述内容之外,还应该提到一些关于复杂性、可伸缩性和修复的内容。图2中描述的所有检查都相对简单。我们不使用任何控制或数据流信息、指针分析、整个程序分析、抽象解释或其他类似的技术。尽管如此,他们还是为开发人员发现了真正的问题,并提供了良好的回报。也就是说,相对简单的检查有很大的影响。总的来说,我们在提供建议的修复方案的分析上取得了更大的成功。分析工具应该修复bug,而不仅仅是发现它们。对于如何解决这个问题,没有太多的困惑,而且自动应用该工具提供的修复程序的能力降低了对上下文切换的需要。最后,为了确保分析能够在谷歌的范围内运行,程序分析工具应该是可分割的。把分析工具想象成跨大型程序集的map-reduce。
最后的想法。在本文中,我们提出了一个静态分析平台,同时也对如何创建这样一个平台形式提出了自己的见解。我们的目标是鼓励分析作者在创建新工具和他们的工具的所有权衡时考虑这种理念,而不仅仅是技术上定义的误报率或分析的速度。我们也鼓励其他公司,即使他们已经尝试过程序分析工具之前,再尝试与此理念的思想。虽然我们多年来也没有广泛使用静态分析工具,但是最终正确使用静态分析工具会带来很大的回报。
VIII. 致谢
特别感谢所有帮助实现Tricorder的谷歌开发人员,包括Alex Eagle、Eddie Af- tandilian、Ambrose Feinstein、Alexander Kornienko和Mark Knichel,以及所有继续确保平台成功的分析人员。
引用
[1] AddressSanitizer Team. AddressSanitizer. http://clang.llvm.org/docs/AddressSanitizer.html, 2012.
[2] E. Aftandilian, R. Sauciuc, S. Priya, and S. Krishnan. Building useful program analysis tools using an extensible compiler. In Workshop on Source Code Analysis and Manipulation (SCAM), 2012.
[3] N. Ayewah, D. Hovemeyer, J. D. Morgenthaler, J. Penix, and W. Pugh. Using static analysis to find bugs. IEEE Software, 25(5):22–29, 2008.
[4] N. Ayewah and W. Pugh. The Google FindBugs fixit. In International Symposium on Software Testing and Analysis (ISSTA), pages 241–252, 2010.
[5] N. Ayewah, W. Pugh, J. D. Morgenthaler, J. Penix, and Y. Zhou. Evalu- ating static analysis defect warnings on production software. In Program Analysis for Software Tools and Engineering (PASTE), 2007.
[6] V. Balachandran. Fix-it: An extensible code auto-fix component in re- view bot. In Source Code Analysis and Manipulation (SCAM), 2013 IEEE 13th International Working Conference on, pages 167–172, Sept 2013.
[7] V. Balachandran. Reducing human effort and improving quality in peer code reviews using automatic static analysis and reviewer recommenda- tion. In Proceedings of the 2013 International Conference on Software Engineering, ICSE ’13, pages 931–940, Piscataway, NJ, USA, 2013. IEEE Press.
[8] A. Bessey, K. Block, B. Chelf, A. Chou, B. Fulton, S. Hallem, C. Henri- Gros, A. Kamsky, S. McPeak, , and D. Engler. A few billion lines of code later. Communications of the ACM, 53(2):66–75, 2010.
[9] Checkstyle Java Linter. http://checkstyle.sourceforge.net/, August 2014.
[10] Clang compiler. http://clang.llvm.org, August 2014.
[11] ClangTidy. http://clang.llvm.org/extra/clang-tidy.html, August 2014.
[12] Coverity. http://www.coverity.com/.
[13] Coverity 2012 scan report. http://www.coverity.com/press- releases/annual-coverity-scan-report-finds-open-source-and- proprietary-software-quality-better-than-industry-average-for-second- consecutive-year/. Accessed: 2015-02-11.
[14] O. de Moor, D. Sereni, M. Verbaere, E. Hajiyev, P. Avgustinov, T. Ek- man, N. Ongkingco, and J. Tibble. .QL: Object-Oriented Queries Made Easy. In GTTSE, pages 78–133, 2007.
[15] S. Elbaum, G. Rothermel, and J. Penix. Techniques for improving re- gression testing in continuous integration development environments. In International Symposium on Foundations of Software Engineering (FSE), 2014.
[16] P. Emanuelsson and U. Nilsson. A comparative study of industrial static analysis tools. Electronic Notes in Theoretical Computer Science, 217(0):5 – 21, 2008. Proceedings of the 3rd International Workshop on Systems Software Verification (SSV 2008).
[17] error-prone: Catch common Java mistakes as compile-time errors. http://code.google.com/p/error-prone/, August 2014.
[18] FindBugs. http://findbugs.sourceforge.net/.
[19] Gerrit code review. http://code.google.com/p/gerrit/, August 2014.
[20] Google. Build in the cloud: How the build system works. Available from http://http://google-engtools.blogspot.com/2011/08, August 2011. Accessed: 2014-11-14.
[21] C. Jaspan, I.-C. Chen, and A. Sharma. Understanding the value of program analysis tools. In Companion to the 22Nd ACM SIGPLAN Conference on Object-oriented Programming Systems and Applications Companion, pages 963–970, New York, NY, USA, 2007. ACM.
[22] Jetbrains. IntelliJ IDEA. Available at
http://www.jetbrains.com/idea/, 2014.
[23] B. Johnson, Y. Song, E. R. Murphy-Hill, and R. W. Bowdidge. Why don’t software developers use static analysis tools to find bugs? In International Conference on Software Engineering (ICSE), pages 672– 681, 2013.
[24] Klocwork. http://www.klocwork.com/.
[25] J. Larus, T. Ball, M. Das, R. DeLine, M. Fahndrich, J. Pincus, S. Ra- jamani, and R. Venkatapathy. Righting software. Software, IEEE, 21(3):92–100, May 2004.
[26] T. D. LaToza, G. Venolia, and R. DeLine. Maintaining mental models: A study of developer work habits. In International Conference on Software Engineering (ICSE), pages 492–501, New York, NY, USA, 2006. ACM.
[27] L. Layman, L. Williams, and R. Amant. Toward reducing fault fix time: Understanding developer behavior for the design of automated fault de- tection tools. In Empirical Software Engineering and Measurement,2007 ESEM 2007. First International Symposium on, pages 176–185,Sept 2007.
[28] C. Lewis, Z. Lin, C. Sadowski, X. Zhu, R. Ou, and E. J. W. Jr. Does bug prediction support human developers? findings from a google case study. In International Conference on Software Engineering (ICSE), 2013.
[29] J. Lewis and M. Fowler. Microservices. http://martinfowler.com/article/ microservices.html, 25 March 2014.
[30] M. Nanda, M. Gupta, S. Sinha, S. Chandra, D. Schmidt, and P. Bal- achandran. Making defect-finding tools work for you. In International Conference on Software Engineering (ICSE), volume 2, pages 99–108, May 2010.
[31] Protocol Buffers. http://code.google.com/p/protobuf/, August 2014.
[32] Pylint python linter. http://www.pylint.org/, August 2014.
[33] J. Ruthruff, J. Penix, J. D. Morgenthaler, S. Elbaum, and G. Rothermel. Predicting accurate and actionable static analysis warnings: An experi- mental approach. In International Conference on Software Engineering (ICSE), pages 341–350, 2008.
[34] C. Sadowski and D. Hutchins. Thread-safety annotation checking. Available from http://clang.llvm.org/docs/ LanguageExtensions.html#threadsafety, 2011.
[35] C. Sadowski, C. Jaspan, E. Söderberg, C. Winter, and J. van Gogh. Ship- shape program analysis platform. https://github.com/google/shipshape. Accessed: 2015-2-11.
[36] C. Sadowski and J. Yi. How developers use data race detection tools. In Evaluation and Usability of Programming Languages and Tools (PLATEAU), 2014.
[37] Semmle. https://semmle.com/.
[38] H. Seo, C. Sadowski, S. G. Elbaum, E. Aftandilian, and R. W. Bowdidge. Programmers’ build errors: a case study (at google). In International Conference on Software Engineering (ICSE), pages 724–734, 2014.
[39] K. Serebryany and T. Iskhodzhanov. ThreadSanitizer: Data race detec- tion in practice. In Workshop on Binary Instrumentation and Applica- tions (WBIA), 2009.
[40] K. Serebryany, A. Potapenko, T. Iskhodzhanov, and D. Vyukov. Dy- namic race detection with LLVM compiler. In International Workshop on Runtime Verification (RV), 2011.
[41] The Eclipse Foundation. The Eclipse Software Development Kit. Avail- able at http://www.eclipse.org/, 2009.
[42] L. Wasserman. Scalable, example-based refactorings with refaster. In
Workshop on Refactoring Tools, 2013.
[43] J. Whittaker, J. Arbon, and J. Carollo. How Google Tests Software. Always learning. Addison-Wesley, 2012.