Mysql语法
Mysql语法
SQL的分类:
1.DDL 数据定义语言
create–创建 alter–修改 drop–删除
2.DML 数据操作语言
insert(插入数据) update(修改数据) delete(删除数据)
3.DCL 数据控制语言
if else while
4.DQL 数据查询语言
select(查询表中的数据)
数据库操作
创建数据库:create database 数据库名称;
删除数据库:drop database 数据库名称;
![]()
查看所有数据库:show databases;
查看数据库创建信息:show create database 数据库名称;

查看当前数据库:select database();
使用某个数据库:use 数据库名称;
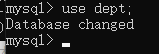
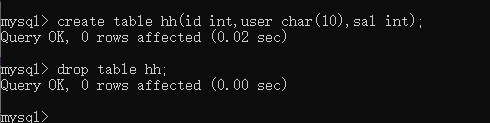
创建表:create table 表的名称(
字段名 数据类型 约束
);

删除表:drop table 表的名称;
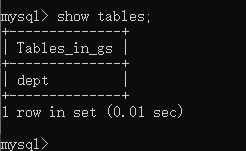
查看所有表:show tables;
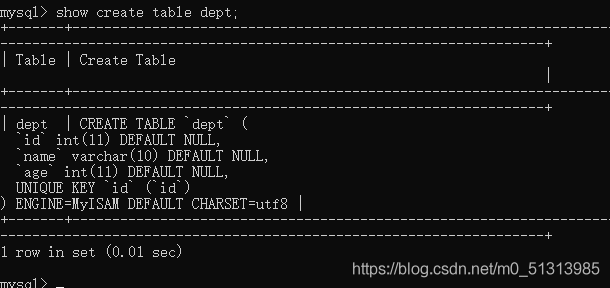
查看表结构定义的信息:show create table 表的名称;
查看表结构的详细信息:desc 表的名称;
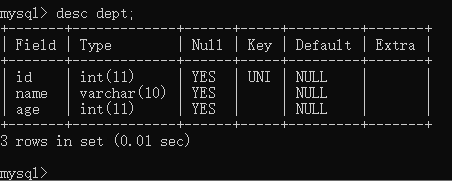
修改表
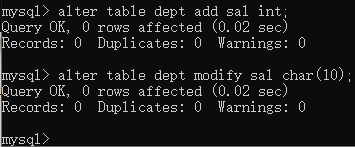
添加新字段:alter table 表名称 add 字段名 数据类型 约束;
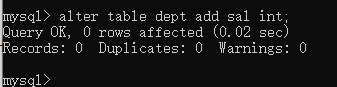
删除某字段:alter table 表名称 drop 字段名 数据类型;
修改字段数据类型、长度或约束:alter table 表名称 modify 字段名 数据类型 约束;
修改字段名称:alter table 表名称 change 旧字段 新字段 数据类型 约束;
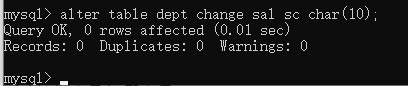
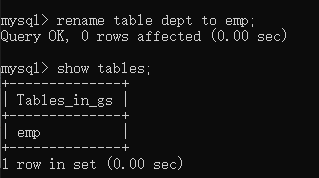
修改表名称: rename table 旧表名 to 新表名;
插入数据
insert into 表名 (字段1,字段2,字段3) values (值1,值2,值3); --向表中指定的字段添加值
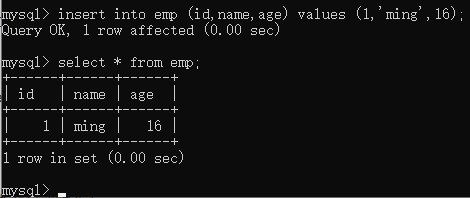
insert into 表名 values (值1,值2,值3,…); --向表中所有字段添加值
注意实现
插入的数据与字段数据的类型相同
数据的大小应该在规定的范围内
数据中的数据的列的位置和字段位置的相同的
字符串和日期类型的数据,必须要使用单引号括起来
插入中文数据乱码
1.插入中文,会产生乱码的问题。
2.怎么产生?怎么解决?
解决的方案,修改MySQL客户端的编码就可以了。改成GBK
3.修改MySQL客户端的编码
先把MySQL服务器停止
找到MySQL安装的路径,找到my .ini的配置文件*修改客户端的编码,改成gbk
[client]
port=3306
[mysql]
default-character-set=gbk
重启动MySQL的服务
修改数据的语句
update 表名 set 字段1=值1,字段2=值2 where 条件;
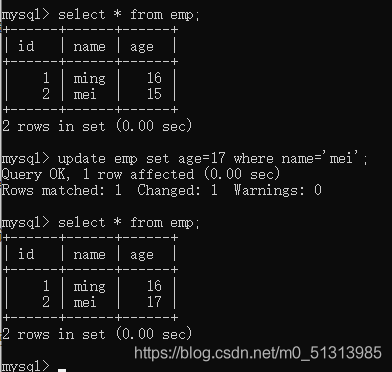
修改字段1和字段2的值
如果没有where的关键字,说明修改的默认所有的记录如果有where的关键字,修改的是符合条件的记录
删除数据
delete from 表 where 条件;
如果不加where ,默认删除所有的数据
如果添加where条件,删除符合条件的数据\
truncate 表 --先把整张表删除包括里面的数据,在创建一个跟原来一模一样的表
查询数据
select * from 表 --表示查询表中所有字段的数据
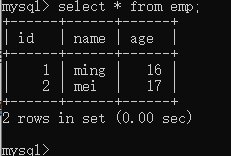
select 字段1,字段2,字段3 from 表 --查询指定字段的数据
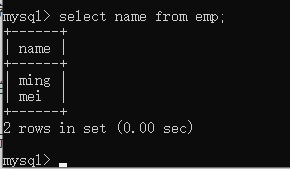
distinct —去掉重复的关键字(select distinct 字段 from 表)
*可以对查询的列进行计算
*查询语句中可以使用as的关键字起别名
*别名的真正的用法,采用的多表的查询,为了区分每张表,表起个别名。
*as的关键字可以省略不写。中间需要使用空格(一般用来给表起别名)
使用where的条件语句,进行查询条件的过滤。
where子句后可以使用的符号
1.常用的符号:< > >= <= <>(不等于) =
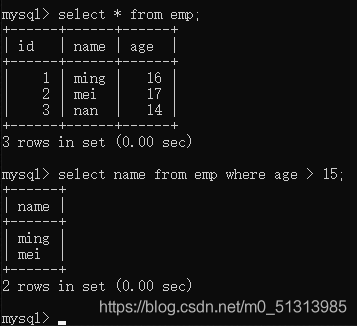
in ----代表范围
like —模糊查询(条件需要使用单引号,需要使用占位符)
select * from 表 where username like ‘X_’ 使用 _做占位符 开头为X两个字符的都行 _代表一个位子
select * from 表 where username like ‘X%’ 使用%做展位符 开头为X的字符都行 %代表多个位子
and --与
or --或
not --非
between…and
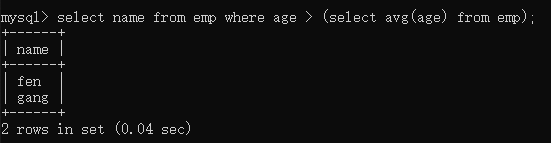
总结查询的语句:select 字段1,字段2 | * from 表 where 条件的过滤;
使用order by 对结果进行排序
order by asc | desc;
asc --升序(默认值)
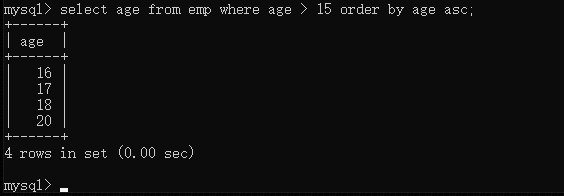
desc --降序
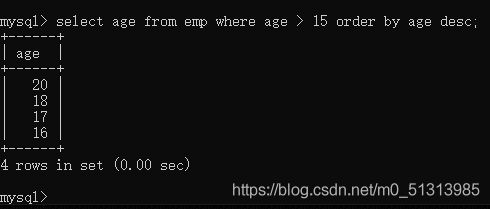
注意order by 放在select语句的最后
聚集函数
1.什么是聚集函数∶Excel表格。求数量,求和,平均值,最大值,最小值。
2.聚集函数操作的都是某一列的数据。
3.聚集函数:
count() —求数量 例:select count() from 表 where 条件过滤;
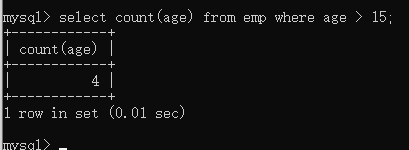
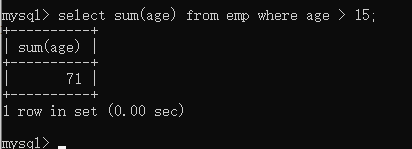
sum() —求某一列数据的和 无sum(),sum只对数值型数据起作用
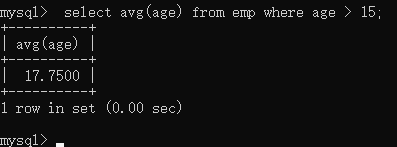
avg() —求平均分
max()和min() —求最大值和最小值
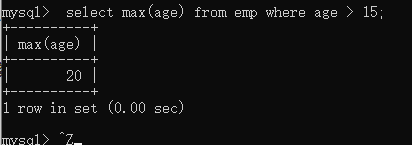
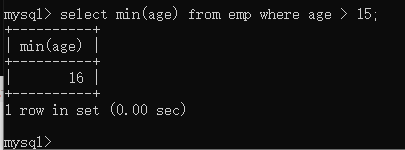
注意聚集函数求的都是某一列的数据
分组查询概念
group by 根据字段进行分组
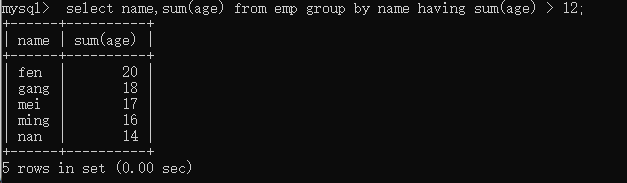
select * from 表; 默认是一组
使用where的条件,如果有分组,where的条件是分组之前的条件。*新的关键字,having关键字进行分组的条件过滤。
where关键字后不能使用聚集函数,而having可以使用聚集函数!!
单表约束(主键)
1.可以把某一列字段声明主键,这一列的数据有如下特点
*非空
*唯一
*被引用–当前主键的列,作为一条记录的标识。
2.声明主键
*使用关键字primary key声明某一个字段为主键。
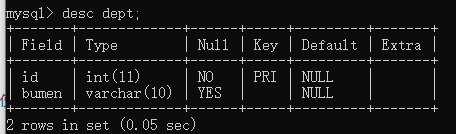
主键的自动增长
*主键的值特点,可以把主键的值交给数据库去维护。*自动增长只能使用int和bigint类型
通过关键字auto_increment
开发中,主键是基本都要设置的
多表约束(外键)
外键的约束∶目的保证表结构中的数据的完整性!!
外键多表的关系
*使用关键字foreign key (dno) references dept (did);相当于dno字段作为emp表的外键,值是从dept表中did取值。(emp为员工表,dept为部门表)
多表的设计
1.多表的设计存在3种方式
—对多
*在多方表中,创建一个新的字段,作为当前表的外键,指向一方表的主键。
多对多
*先创建一张中间表,中间表中至少包含2个字段,两个字段作为当前中间表的外键,指向原来多对多表的主
键。
一对一
*一对一,一般不处理,放在同一张表中就可以。
多表查询内链接
0.前提条件:两个表有联系,通过外键关联。
1.普通内链接
语法∶关键字… inner join … on条件;注意︰
在inner join关键字之前写表1在inner join关键字之后写表2on的后面写条件∶(表1是dept,表2是emp ) dept.did = emp.dno
语句:select * from dept inner join emp on dept.did = emp.dno;
2.隐式内链接(用的最多的)
语法: select … from表1,表2 where表1.字段=表2.字段;*语句: select * from dept, emp where dept.did = emp.dno;
*别名: select * from dept d, emp e where d.did = e.dno;
*指定字段: select d.dname,e.ename,e.sal from dept d,emp e where d.did = e.dno;
多表查询外链接
1.外链接又分成左外链接和右外链接
左外链接
使用关键字select * from表1 left outer join表2 on条件outer关键字省略不写
select * from dept left outer join emp on dept.did - emp.dno;
select * from dept left join emp on dept.did = emp.dno;
右外链接
使用关键字select * from表1 right outer join 表2 on 条件outer关键字省略不写
select * from dept right outer join emp on dept.did = emp.dno;
注意:1.笛卡尔积两个结果的乘积,数据是重复,目的︰去除掉重复的数据
子查询
1.子查询,嵌套查询,一个select语句不能查询出结果的,可以通过多个select语句来查询结果。