python dataframe 去重_数据处理奇技巧——python数据处理小技能
有人说做数据无非几点:逻辑思路,技术工具和业务需求,1)逻辑思路中涵盖的大多是一些算法、规则;
2)技术工具中主要是python、Excel和SQL;
3)业务逻辑里面则多为一些指标、客群等。
看着很多的内容,等处理过了才发现,无他,唯手熟尔~
做数据以来,难免会遇到各种处理方法上的问题,每次遇到问题点就整理一下关键的语句,逐渐的,才发现原来整理了一整套,今天抽取一些比较常用的语句,分成了几篇:
一篇是python的常用语句,
一篇是SQL的常规用法,
整理出来,也希望能给大家一些启发,后有Excel的内容,估计需要过段时间才能出场了。
这三篇文章不是告诉你一些系统的工具使用方法,而是针对那些经常使用python,但是又记不住数据处理的方法函数的人,做一个小技巧的总结。
希望大家能够喜欢。
下面先来说一下python的内容:
1、数据读取和筛选的方法
1)数据读取:
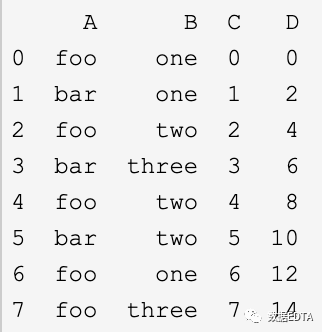
对应的代码为:
df[['tab1','tab2','tab3']] # 取某一列或者某几列df[df['size_num']>22.0] #单条件筛选df[(df['size_num']>22.0) & (df['size_num]<50)] #多条件筛选# 如果你想包括多个值,把它们放在一个list里面,然后使用isinprint(df.loc[df['B'].isin(['one','three'])])print(data.loc[1, :]) # 取一行数据;print(pd.loc[3:6]) # 类似于python的切片操作,取3:6行print(data.loc[:, ['a', 'b']]) # 取一列值;print(data.loc[1, ['a', 'b']]) # 取某行某列值;print(data.iloc[1, :]) # 取一行数据;print(data.iloc[:, 1]) # 取一列数据;条件筛选:
data.loc[np.logical_and(data['type_name']>=5, data['type_name']<=8)].groupby('tab_name')或者:
data[(data['type_name']>=5)&( data['type_name']<=8)] # 注意此处一定要用符号&进行连接;2)读取前五行:
pandas读取时限定行数:此方法只将前5行读入到内存中,所以比较快速。
import pandas as pddata = pd.read_csv('sub_customer.csv',nrows=5)head函数:也是pandas中的用法,不过这个用法需要将大量数据存入到内存中,然后才会读其中的前5行。
import pandas as pddata = pd.read_csv('sub_customer.csv')data.head(5)循环读取前五行方法:最原始的方法,非常耗时。
N = int(raw_input('Enter a line number : >> '))Filename = raw_input('Enter a file path: >> ')file = open(Filename,'r')lineNum = 0for line in file.readlines()[0:N]: print(line)file.close()2、for-in的两层循环写法
1)以下会将二维数据输出成一个二维的数组:
data = [[i for i in j if j!='null'] for j in data]2)以下会将二维数组输出成一个一维的数组:
data = [i for i in [j for j in data if j !='null']]3、分批读取文件的方法
1)txt分块读取的方法:
import time# https://blog.csdn.net/weixin_43790560/article/details/88587123def read_in_chunks(filePath, chunk_size=10*10): file_object = open(filePath) time.sleep(2) while True: chunk_data = file_object.read(chunk_size) if not chunk_data: break yield chunk_dataif __name__ == "__main__": path = '/Users/livan/PycharmProjects/data/Page Data/Facebook Insights Data Export - Visit Beijing - 2014-07.xml' for chunk in read_in_chunks(path): print(chunk)2)pandas也有分块读取数据的方法:
loop = truechunkSize = 10000path = '../data/result.csv'reader = pd.read_csv(path, iterator = True, dtype=str)while loop: try: chunk = reader.get_chunk(chunkSize).fillna('nan') except StopIteration: loop = False print('iteration is stopped~')4、pandas技能的交、并、差集
1)第一种处理方法:
交集:
#方法一:
a=[2,3,4,5]b=[2,5,8]tmp = [val for val in a if val in b]print(tmp)#[2, 5]#方法二:
list(set(a).intersection(set(b))#方法二比方法一快很多!
并集:
list(set(a).union(set(b)))补集:
list(set(b).difference(set(a)))# b中有而a中没有的。
2)第二种处理方法:
df1 = pd.DataFrame([['a', 10, '男'], ['b', 11, '男'], ['c', 11, '女'], ['a', 10, '女'], ['c', 11, '男']], columns=['name', 'age', 'sex'])df2 = pd.DataFrame([['a', 10, '男'], ['b', 11, '女']], columns=['name', 'age', 'sex'])# 取交集:
print(pd.merge(df1,df2,on=['name', 'age', 'sex']))# 取并集:
print(pd.merge(df1,df2,on=['name', 'age', 'sex'], how='outer'))how参数是连接方式:
how = 'inner'是内连接,即共同列的交集形成结果;

how = 'outer'是外连接,即共同列的并集形成结果;

how='left',dataframe的链接方式为左连接,我们可以理解基于左边位置dataframe的列进行连接,参数on设置连接的共有列名。
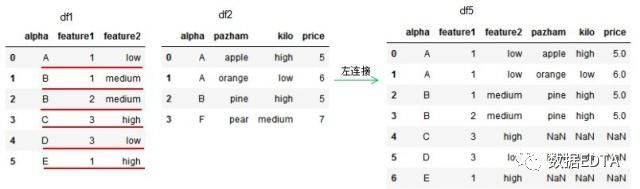
how='right',dataframe的链接方式为左连接,我们可以理解基于右边位置dataframe的列进行连接,参数on设置连接的共有列名。

# 取差集(从df1中去掉df2中存在的行):
# 下面需要有两次赋值追加append,因为一次时是取两个数据不同时存在的数据。
# 是两个的合集,但是再添加一次就可以将df2中的数据去除掉,就会得到df1中的独立存在的数据。
df1 = df1.append(df2)df1 = df1.append(df2)df3 = df1.drop_duplicates(subset=['name', 'age', 'sex'],keep=False)5、pandas中的concat连接
1)增加行拼接:
data = pd.concat([df1, df2])2)增加列拼接:
data = pd.concat([df1, df2], axis=1)data = data.reset_index(drop=True)print(data)dup_data = data['sex'].drop_duplicates()print(dup_data)6、pandas数据去重
1)去重复:
df1.drop_duplicates(subset=['name', 'age', 'sex'])2)简单方法:
df = pd.read_csv('./demo_duplicate.csv')print(df)print(df['Seqno'].unique()) # [0. 1.]# 使用duplicated 查看重复值
# 参数 keep可以标记重复值 {'first','last',False}
print(df['Seqno'].duplicated())'''0 False1 True2 True3 True4 FalseName: Seqno, dtype: bool'''# 删除 series 重复数据
print(df['Seqno'].drop_duplicates())'''0 0.04 1.0Name: Seqno, dtype: float64'''# 删除 dataframe 重复数据
print(df.drop_duplicates(['Seqno']))# 按照 Seqno 来 去重
''' Price Seqno Symbol time0 1623.0 0.0 APPL 14734119624 1649.0 1.0 APPL 1473411963'''# drop_dujplicates() 第二个参数 keep 包含的值有: first、last、False
print(df.drop_duplicates(['Seqno'], keep='last')) # 保存最后一个''' Price Seqno Symbol time3 1623.0 0.0 APPL 14734119634 1649.0 1.0 APPL 1473411963'''7、to_csv()中长数据转化成字符串
to_csv()函数中,如果是长数字,需要在后面添加‘\t’,以保证数字转化成字符串:
df1 = pd.DataFrame([['a', 10, '男'], ['b', 11, '男'], ['c', 11, '女'], ['a', 10, '女'], ['c', 11, '男']], columns=['name', 'age', 'sex'])df1['a'] = [str(i)+'\t' for i in df1['a']]此时再进行to_csv的函数时,长数据就不会变成科学计数法。
8、pandas中增加行列
本文只用了添加功能,因为在处理数据时能不删除,尽量不做删除动作,可以通过过滤来取到小的数据集。
1)增加行:at()函数
想增加一行,行名称为‘5’,内容为[16, 17, 18, 19]
df.loc['5'] = [16, 17, 18, 19] # 后面的序列是Iterable就行df.at['5'] = [16, 17, 18, 19]df.set_value('5', df.columns, [16, 17, 18, 19], takeable=False) # warning,set_value会被取消2)增加列:Insert()函数
可以指定插入位置,和插入列名称
df.insert(0, 'E', s)细节可查看文章:
https://www.cnblogs.com/guxh/p/9420610.html9、python常用高阶函数
1) lambda函数:匿名函数
数据会以参数的形式完整传给x,y,而后经过x+y运算循环呈现在x,y中;
add = lambda x, y : x+y add(1,2) # 结果为32) map函数:会根据提供的函数对指定序列做映射
def square(x) : # 计算平方数 return x ** 2将第二个参数的列表内容逐一放到square函数中,计算出对应的结果;map(square, [1,2,3,4,5]) # 计算列表各个元素的平方也可以与lambda函数结合使用:map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) # 可以放置多个参数3) reduce函数:是返回第一个数与第二个数做add运算,产生的结果再去add第三个数,以此类推。
def add(x, y) : # 两数相加 return x + yreduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数4) groupby函数:分组处理

几种常用的用法:
4.1)单列分组,然后按照另一列数据计算相应值:
data.groupby('race')['age'].mean()4.2)多列分组,然后按照另一列数据计算相应值:
Muldf = df.groupby(['Q','A']).agg('mean')4.3)多列分组,然后按照多列分别计算相应值:
data.groupby('race').agg({'age': np.median, 'signs_of_mental_illness': np.mean})4.4)所能对接的函数有很多,效果不同:
data.groupby('flee')['age'].plot(kind='kde',legend=True,figsize=(20, 5))5) agg({'tab1':'mean'})函数:主要是用在groupby后面,对每个分组的数据进行计算,里面内嵌字典,可以进行多字段,不同计算方式的操作;
df.groupby('key').agg({'tab1':'mean'})6) apply(sum)函数:主要用在groupby后面,对每个分组的数据进行计算,功能比agg要多,可以加入自定义的函数;
df.groupby('key').apply(lamdba x: x['v'].sum())df.groupby('key').apply(sum)当apply使用自定义的函数时,自定义函数的参数为整个df,然后再在这个df中确定其他字段的处理方式:
1)apply不带参数时:
def reduce(dx): dx.sum() #在apply中函数不需要加(),但是在其他地方调用函数需要加上(),不要搞混了 return dxdf.groupby('a').apply(reduce)2)apply带参数时:
def reduce(dx,k,kk): dx = dx*k+kk return dxdf.groupby('a').apply(reduce,axis=1,args=(2,1,))其中axis=1为按行计算,即总数据每行调用一次函数;axis=0为按列计算,即总数据每列调用一次函数;
pandas中使用apply()函数第一组值重复的解决方法:
global flagflag = Falsedef test(x): global flag if flag == False: flag = True return tssf(x) ==此处添加函数7) filter函数:接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
def is_odd(n): return n % 2 == 1#将[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]中的数据逐一传入is_odd中做运算,过滤结果存入tmplisttmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])newlist = list(tmplist)print(newlist)8) generator函数:迭代器函数
g = (x * x for x in range(10)) # 注意把[]改成()后,不是生成一个tuple,而是生成一个generatorwhile True: print(g.__next__())迭代器需要考虑的有yield关键字:
def foo(): print("starting...") while True: res = yield 4 print("res:", res)g = foo()运算一次,将结果反馈出来,并且停在yield处:
print(next(g))传递新的值到yield处,然后往下运行:
print(g.send(7))9) 三目运算:三目的格式为:条件为真时的结果 if 判段的条件 else 条件为假时的结果
print(x if(x>y) else y)10) np.where:条件筛选语句:
A = np.array([1, 7, 4, 9, 2, 3, 6, 0, 8, 5])B = np.where(A%2 == 0, A+1, A-1) # 偶+1,奇-1print(B)10、pandas组内排序问题
数据的组内排序是常用的方法:
data['ranks'] = data['act_timestamp'].groupby(data['session_id']).rank()data = data.sort_values(by=['session_id','ranks'], ascending=[True, True])data['act_timestamp'].groupby(data['session_id'])# 是一个迭代器,可以根据循环遍历处对应的值;for group in data.groupby(data['session_id']): print(group)细节内容可以参考如下文档:
https://blog.csdn.net/weixin_43685844/article/details/87913303
11、数据读写乱码和格式修改
1)数据的读写乱码主要有以下两种方案:
使用 df.to_csv(file_name2, encoding='utf-8') 查看是否还存在编码问题。
df.to_csv(file_name2,encoding="utf_8")使用 df.to_csv(file_name2, encoding='utf_8_sig') 查看是否问题依然存在。
df.to_csv(file_name3,encoding="utf_8_sig")2)读取csv文件时转化成字符串的问题:
df=pd.read_csv('D:/project/python_instruct/test_data2.csv', header=None,dtype='str')3)数据格式修改:
df[['two', 'three']] = df[['two', 'three']].astype(float)