机器学习-员工离职预测训练赛
【数据来源】DC竞赛的员工离职预测训练赛
一共两个csv表格,pfm_train.csv训练(1100行,31个字段),pfm_test.csv测试集(350行,30个字段)
【字段说明】
- Age:员工年龄
- Attrition:员工是否已经离职,1表示已经离职,0表示未离职,这是目标预测值;
- BusinessTravel:商务差旅频率,Non-Travel表示不出差,Travel_Rarely表示不经常出差,Travel_Frequently表示经常出差;、3BusinessTravel:商务差旅频率,Non-Travel表示不出差,Travel_Rarely表示不经常出差,Travel_Frequently表示经常出差;
- Department:员工所在部门,Sales表示销售部,Research & Development表示研发部,Human Resources表示人力资源部;
- DistanceFromHome:公司跟家庭住址的距离,从1到29,1表示最近,29表示最远;
- Education:员工的教育程度,从1到5,5表示教育程度最高;
- EducationField:员工所学习的专业领域,Life Sciences表示生命科学,Medical表示医疗,Marketing表示市场营销,Technical Degree表示技术学位,Human Resources表示人力资源,Other表示其他;
- EmployeeNumber:员工号码;
- EnvironmentSatisfaction:员工对于工作环境的满意程度,从1到4,1的满意程度最低,4的满意程度最高;
- Gender:员工性别,Male表示男性,Female表示女性;
- JobInvolvement:员工工作投入度,从1到4,1为投入度最低,4为投入度最高;
- JobLevel:职业级别,从1到5,1为最低级别,5为最高级别;
- JobRole:工作角色:Sales Executive是销售主管,Research Scientist是科学研究员,Laboratory Technician实验室技术员,Manufacturing Director是制造总监,Healthcare Representative是医疗代表,Manager是经理,Sales Representative是销售代表,Research Director是研究总监,Human Resources是人力资源;
- JobSatisfaction:工作满意度,从1到4,1代表满意程度最低,4代表满意程度最高;
- MaritalStatus:员工婚姻状况,Single代表单身,Married代表已婚,Divorced代表离婚;
- MonthlyIncome:员工月收入,范围在1009到19999之间;
- NumCompaniesWorked:员工曾经工作过的公司数;
- Over18:年龄是否超过18岁;
- OverTime:是否加班,Yes表示加班,No表示不加班;
- PercentSalaryHike:工资提高的百分比;
- PerformanceRating:绩效评估;
- RelationshipSatisfaction:关系满意度,从1到4,1表示满意度最低,4表示满意度最高;
- StandardHours:标准工时;
- StockOptionLevel:股票期权水平;
- TotalWorkingYears:总工龄;
- TrainingTimesLastYear:上一年的培训时长,从0到6,0表示没有培训,6表示培训时间最长;
- WorkLifeBalance:工作与生活平衡程度,从1到4,1表示平衡程度最低,4表示平衡程度最高;
- YearsAtCompany:在目前公司工作年数;
- YearsInCurrentRole:在目前工作职责的工作年数
- YearsSinceLastPromotion:距离上次升职时长
- YearsWithCurrManager:跟目前的管理者共事年数;
【观察数据】
import numpy as np
import pandas as pd
pd.set_option('display.max_columns',None)
#导入数据
train = pd.read_csv(r'/pfm_train.csv')
test = pd.read_csv(r'/pfm_test.csv')
print(train.shape) #(1100, 31)
print(test.shape) #(350,30)
#是否有缺失值
print(train.isnull().any()) #没有缺失值
print(test.isnull().any()) #没有缺失值
没有缺失值,因此不需要处理缺失值。接下来看下数据分布情况。
#描述性统计
print(train.describe())
Age的最小值是18,因此列Over18可删;StandardHours方差为0,也可删。另外员工工号列也可删除。
train.drop(['Over18','StandardHours',EmployeeNumber'],axis=1,inplace=True)
查看变量相关性
import matplotlib.pyplot as plt
import seaborn as sns
#%matplotlib inline jupyter notebook 或者 jupyter qtconsole使用
sns.heatmap(corr,xticklabels=corr.columns.values, yticklabels=corr.columns.values)
plt.show()
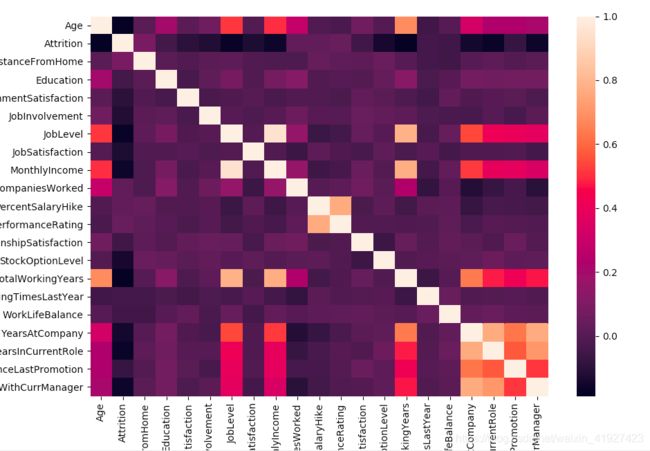
JobLevel、MothlyIncome、TotalWorkingYears;PercentSalaryHike、PerformanceRating相关性强,这里删除JobLevel、TotalWorkingYears、PerformanceRating特征
train.drop(['JobLevel','TotalWorkingYears','PerformanceRating'],axis=1,inplace=True)
【特征处理】
接下来会用到sklearn库内机器学习算法,因此需要提前将标称型数据转化成数值型。
#对标称属性进行one-hot编码
train_encode = pd.get_dummies(train)
#将目标预测值Attrition移到最后一列
Attrition = train_encode['Attrition']
train_encode.drop(['Attrition'],axis=1,inplace=True)
train_encode['Attrition'] = Attrition
【建模】
先看一下Logisitic回归的效果
#线性模型
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(penalty='l1')
logreg.fit(X_train,y_train)
print('logreg train score:{:.3f}'.format(logreg.score(X_train,y_train))) #0.892
print('logreg test score:{:.3f}'.format(logreg.score(X_test,y_test))) #0.898
为了模型有更好的解释性,选择l1正则化。参数C调参后精度变化不大。接下来看下各变量的系数。
df_coef = pd.DataFrame(index=X_train.columns,data=np.transpose(logreg.coef_))
df_coef['abs'] = df_coef.iloc[:,0].abs()
df_coef = df_coef.sort_values(by='abs', ascending=False)
print(df_coef.head())
这里选择了系数最大的前5个变量
0 abs
OverTime_Yes 1.855274 1.855274
BusinessTravel_Travel_Frequently 1.420350 1.420350
MaritalStatus_Single 1.187138 1.187138
JobRole_Healthcare Representative -0.817322 0.817322
Department_Sales 0.814622 0.814622
可以看到影响离职率的最大因素是:加班、婚姻状况、出差、职位及所属部门。
随机森林
#随机森林
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=5,random_state=1)
forest.fit(X_train,y_train)
print('forest train score:{:.3f}'.format(forest.score(X_train,y_train))) #0.975
print('forest train score:{:.3f}'.format(forest.score(X_test,y_test))) #0.847
随机森林的拟合度比Logistic回归要高,但是也存在过拟合的问题。接下来看下feature_importance_
df_feature_importances = pd.DataFrame(index=X_train.columns,data=np.transpose(forest.feature_importances_))
df_feature_importances['abs'] = df_feature_importances.iloc[:,0].abs()
df_feature_importances = df_feature_importances.sort_values(by='abs', ascending=False)
print(df_feature_importances.head())
0 abs
MonthlyIncome 0.077285 0.077285
TotalWorkingYears 0.073762 0.073762
Age 0.071067 0.071067
JobSatisfaction 0.058534 0.058534
DistanceFromHome 0.054720 0.054720
其他的算法暂时不列举了,目前就是Logistic的效果最好。
【预测】
#test数据集处理
test.drop(['Over18','StandardHours','EmployeeNumber','JobLevel','TotalWorkingYears','PerformanceRating'],axis=1,inplace=True)
test_encode = pd.get_dummies(test)
#预测
pred = logreg.predict(test_encode)