Crowd Counting using Deep Recurrent Spatial-Aware Network
摘要:提出了一种Deep Recurrent Spatial-Aware Network的网络架构,能够采用一种可学习的空间变化模块。
本文提出的方法: Deep Recurrent Spatial-Aware Network,包括两个部分:全局特征提取部分(GFE)和 Recurrent Spatial-Aware Refinement(RSAR).其中GFE模块将整个图像作为输入,进行特征提取。RSAR模块通过一个空间转换机制定位图像中的兴趣区域,然后采用残差学习对密度图进行迭代优化。
整体网络架构图:
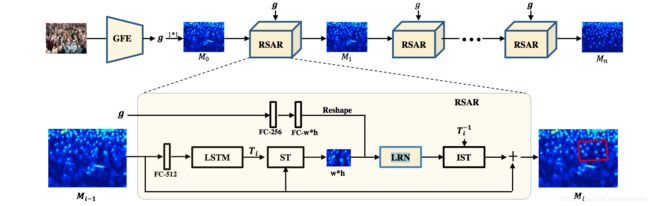
Global Feature Embedding(GFE)模块将整个图像作为输入,提取输入图片的global freature g,然后通过1*1卷积层对g进行卷积得到初始密度图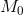 . The Recurrent Spatial-Aware Refinement(RSAR)模块通过spatial transformer network选择image region,并通过Local Refinement Network(LRN) 和gloval context feature计算所选择的image region的密度图。 ST表示Spatial transformer network,IST表示inverse spatial transformer network。 FC-N表示包含N个输出神经元的全连接层。
. The Recurrent Spatial-Aware Refinement(RSAR)模块通过spatial transformer network选择image region,并通过Local Refinement Network(LRN) 和gloval context feature计算所选择的image region的密度图。 ST表示Spatial transformer network,IST表示inverse spatial transformer network。 FC-N表示包含N个输出神经元的全连接层。
Global Feature Embedding

用于将一个输入图像转换为高维度feature maps,这个feature map用于产生图像的初始人群密度图。GFE包含三列CNN网络,每个CNN网络包含7个卷积层,每个卷积核以及通道数据均不相同,卷积层后面有三个max-pooling层。对于图像I,将其输入到FGM中,将三列卷积层的输出拼接到一起,得到一个global feature  。通过一个1*1卷积核大小的卷积层对g进行处理得到初始人群密度图
。通过一个1*1卷积核大小的卷积层对g进行处理得到初始人群密度图 .
.
![]()
由于过于粗略不能够用于准确评估图像中人数,因此本文使用Recurrent Attentive Refinement(RSAR)模块迭代优化密度图。
Recurrent Spatial-Aware Refinement
RSAR用于对人群密度图进行迭代优化,包含两个部分:1)a spatial transformer network ,定位人群密度图中真正感兴趣的region。2)a local refinement network 采用残差学习对该region对应的密度图进行优化。经过n轮迭代一个高质量的人群密度图就能够用于人群计数。
1)Attentional Region Localization
在第i轮迭代中,通过一个spatial transformer network 确定下步所要优化的image region。将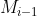 通过一个全连接层转换成512维度的向量,并将512维的向量输入到LSTM中。
通过一个全连接层转换成512维度的向量,并将512维的向量输入到LSTM中。
![]()
![]() 分别为记忆单元以及当前迭代中隐藏状态,FC为全连接层。LSTM用于捕捉密度图的历史状态以及行为转换。Spatial transformer中的转换矩阵
分别为记忆单元以及当前迭代中隐藏状态,FC为全连接层。LSTM用于捕捉密度图的历史状态以及行为转换。Spatial transformer中的转换矩阵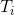 ,用于输入的密度图进行截取、转换以及旋转等操作。
,用于输入的密度图进行截取、转换以及旋转等操作。
![]()
是通过将隐藏状态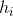 输入到一个隐藏层中计算而来。通过整个密度图与操作提取到region density map
输入到一个隐藏层中计算而来。通过整个密度图与操作提取到region density map 
![]()
ST表示spatial transformer,将 通过双线性插值resize为w*h。
Region Density Map Refinement

通过两个堆叠的全连接层,第一个全连接层包含256个神经元,第二个全连接层有w*h个神经元。通过将第二层全连接的输出reshape成w*h大小得到global context map ![]() 。计算global context map
。计算global context map ![]() 和region map ,通过一个Local Refinement Network计算和ground truth 之间的残差,从而对进行调整得到最终关注的区域。Local Refinement Network的网络结构如下图所示,包含三列卷积神经网络,将和
和region map ,通过一个Local Refinement Network计算和ground truth 之间的残差,从而对进行调整得到最终关注的区域。Local Refinement Network的网络结构如下图所示,包含三列卷积神经网络,将和![]() 拼接成的向量作为输入,计算attentional region的残差密度图。在第i轮迭代中,网络输出的密度图计算公式如下:
拼接成的向量作为输入,计算attentional region的残差密度图。在第i轮迭代中,网络输出的密度图计算公式如下:
![]()
其中![]() 是inverse transformed residual map,IST是inverse spatial transformer,可以将残差密度图通过
是inverse transformed residual map,IST是inverse spatial transformer,可以将残差密度图通过![]() 转换成attentional region。
转换成attentional region。
网络优化
1.由于全连接层的存在,需要对输入的图片进行预处理成统一大小。
2.假设数据扩增之后有N张训练图片,对于图片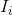 可以表示成2D点集合
可以表示成2D点集合![]() ,其中
,其中![]() 为图片中行人数量。
为图片中行人数量。
3.对于一张图片,其ground truth density map  是通过一种特殊策略生成,该策略能够在可以忽略偏差的范围内,保证在上求和
是通过一种特殊策略生成,该策略能够在可以忽略偏差的范围内,保证在上求和![]() 等于图片中的行人个数。
等于图片中的行人个数。
4.整个网络通过一种end-to-end的方式训练,整体的损失函数如下:
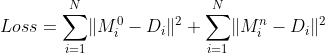
其中![]() 和
和![]() 分别为初始密度图和
分别为初始密度图和 的refined density map。
的refined density map。
5.采用tensorflow框架搭建人群密度估计图,整个网络的卷积层和全连接层的初始化权重通过truncated normal distribution with a deviation 0.01。学习率初始值为0.0001,每1000轮迭代学习率衰减0.98。训练batch为1。采用Adam optimation 调整网络参数值。
实验部分
在目前四个公开数据集上采用本文提出的方法进行实验并与当前state-of-art 方法的效果进行对比。
评估标准:
1. mean absolute error(MAE)
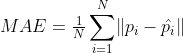
2.mean squared error(MSE)
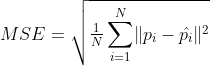
其中N为测试图片个数,![]() 分别为第i张图片ground truth count 和所预测的人群个数。
分别为第i张图片ground truth count 和所预测的人群个数。