Pandas进阶训练03
Pandas进阶训练03
透视表按指定行进行聚合:
 将该 DataFrame 的 D 列聚合,按照 A,B 列为索引进行聚合,聚合的方式为默认求均值。
将该 DataFrame 的 D 列聚合,按照 A,B 列为索引进行聚合,聚合的方式为默认求均值。
透视表聚合方式定义:
 上一题中 D 列聚合时,采用默认求均值的方法,若想使用更多的方式可以在 aggfunc 中实现。
上一题中 D 列聚合时,采用默认求均值的方法,若想使用更多的方式可以在 aggfunc 中实现。
透视表利用额外列进行辅助分割:
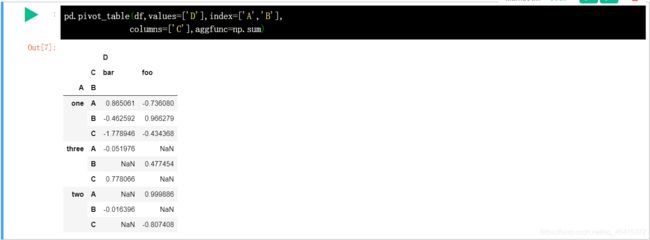 D 列按照 A,B 列进行聚合时,若关心 C 列对 D 列的影响,可以加入 columns 值进行分析。
D 列按照 A,B 列进行聚合时,若关心 C 列对 D 列的影响,可以加入 columns 值进行分析。
透视表的缺省值处理:

在透视表中由于不同的聚合方式,相应缺少的组合将为缺省值,可以加入 fill_value 对缺省值处理。
绝对类型
在数据的形式上主要包括数量型和性质型,数量型表示着数据可数范围可变,而性质型表示范围已经确定不可改变,绝对型数据就是性质型数据的一种。
绝对型数据定义:
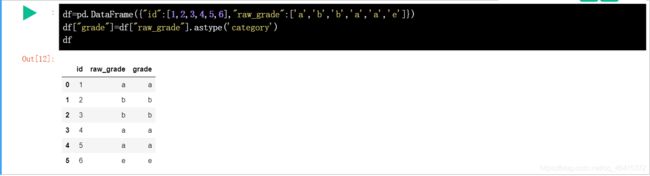
对绝对型数据重命名:

重新排列绝对型数据并补充相应的缺省值:

对绝对型数据进行排序:

对绝对型数据进行分组:

数据清洗
常常我们得到的数据是不符合我们最终处理的数据要求,包括许多缺省值以及坏的数据,需要我们对数据进行清洗。
缺失值拟合:
在FilghtNumber中有数值缺失,其中数值为按 10 增长,补充相应的缺省值使得数据完整,并让数据为 int 类型。
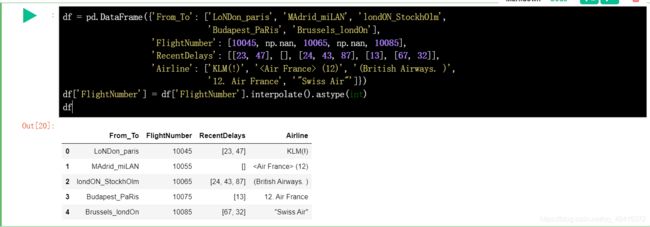
数据列拆分:
其中From_to应该为两独立的两列From和To,将From_to依照_拆分为独立两列建立为一个新表。

字符标准化:
其中注意到地点的名字都不规范(如:londON应该为London)需要对数据进行标准化处理。

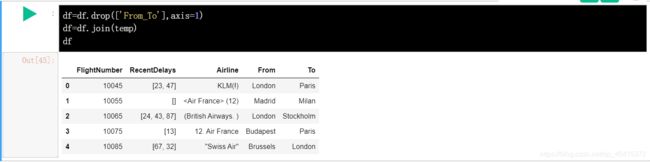
删除坏数据加入整理好的数据:
将最开始的 From_to 列删除,加入整理好的 From 和 to 列。
去除多余字符:
如同 airline 列中许多数据有许多其他字符,会对后期的数据分析有较大影响,需要对这类数据进行修正。

格式规范:
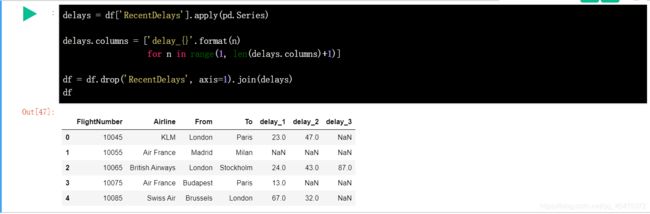
在 RecentDelays 中记录的方式为列表类型,由于其长度不一,这会为后期数据分析造成很大麻烦。这里将 RecentDelays 的列表拆开,取出列表中的相同位置元素作为一列,若为空值即用 NaN 代替。
数据预处理
信息区间划分:
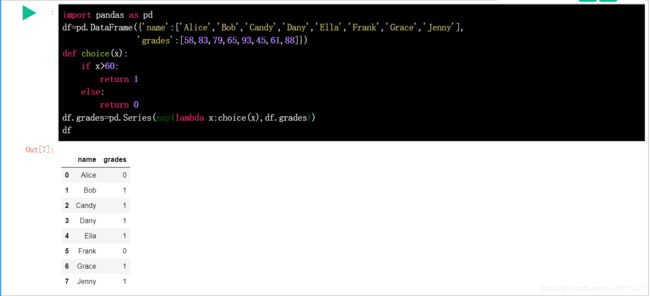
班级一部分同学的数学成绩表,如下图所示
df=pd.DataFrame({
‘name’:[‘Alice’,‘Bob’,‘Candy’,‘Dany’,‘Ella’,‘Frank’,‘Grace’,‘Jenny’],
‘grades’:[58,83,79,65,93,45,61,88]})
但我们更加关心的是该同学是否及格,将该数学成绩按照是否>60来进行划分。
数据去重:
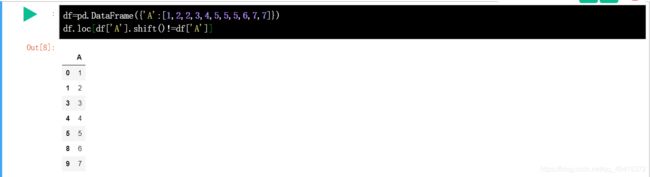
一个列为A的 DataFrame 数据,如下图所示
df = pd.DataFrame({‘A’: [1, 2, 2, 3, 4, 5, 5, 5, 6, 7, 7]})
尝试将 A 列中连续重复的数据清除。
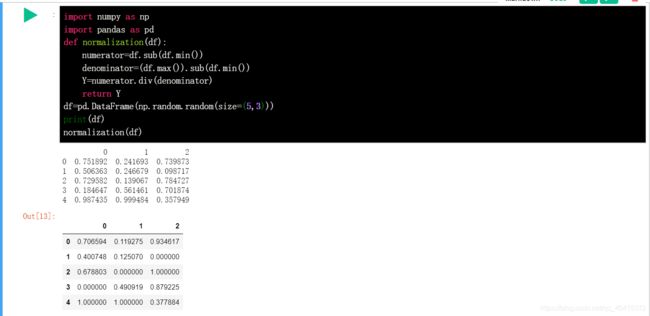
数据归一化:
时候,DataFrame 中不同列之间的数据差距太大,需要对其进行归一化处理。
其中,Max-Min 归一化是简单而常见的一种方式,公式如下:
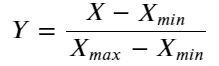
Pandas 绘图操作
Series 可视化:

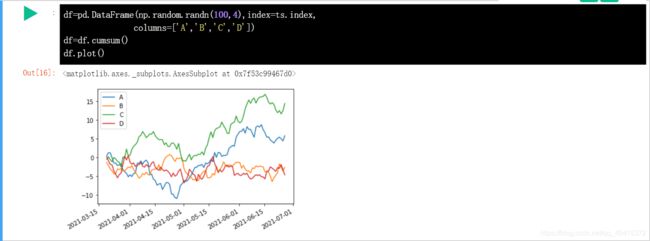
DataFrame 折线图:
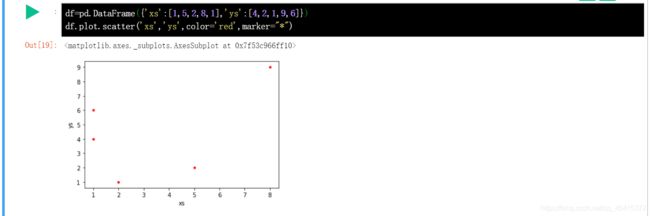
DataFrame 散点图:
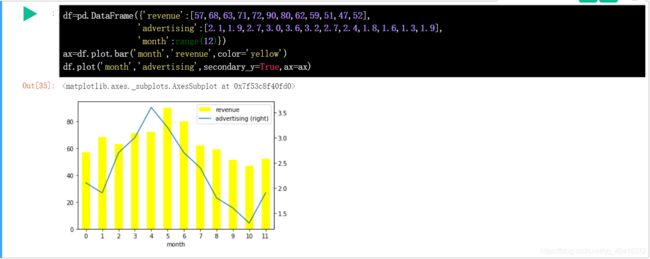
DataFrame 柱形图: