RabbitMQ 高可用集群搭建
RabbitMQ 高可用集群搭建
1 集群简介
1.1 集群架构
当单台 RabbitMQ 服务器的处理消息的能力达到瓶颈时,此时可以通过 RabbitMQ 集群来进行扩展,从而达到提升吞吐量的目的。RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的,每个节点共享所有的用户,虚拟主机,队列,交换器,绑定关系,运行时参数和其他分布式状态等信息。一个高可用,负载均衡的 RabbitMQ 集群架构应类似下图:
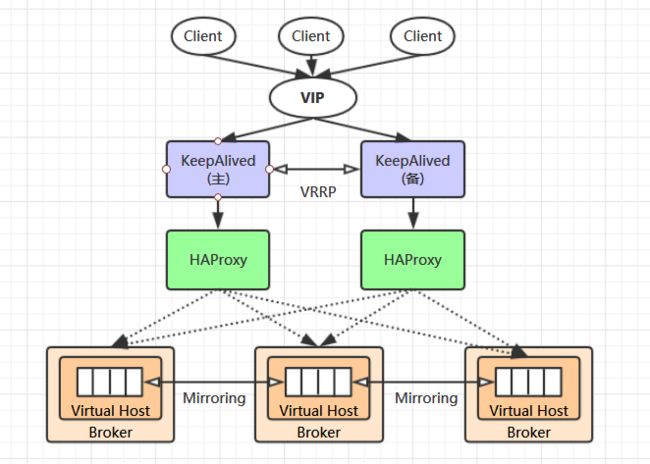
这里对上面的集群架构做一下解释说明:
首先一个基本的 RabbitMQ 集群不是高可用的,虽然集群共享队列,但在默认情况下,消息只会被路由到某一个节点的符合条件的队列上,并不会同步到其他节点的相同队列上。假设消息路由到 node1 的 my-queue 队列上,但是 node1 突然宕机了,那么消息就会丢失,想要解决这个问题,需要开启队列镜像,将集群中的队列彼此之间进行镜像,此时消息就会被拷贝到处于同一个镜像分组中的所有队列上。
其次 RabbitMQ 集群本身并没有提供负载均衡的功能,也就是说对于一个三节点的集群,每个节点的负载可能都是不相同的,想要解决这个问题可以通过硬件负载均衡或者软件负载均衡的方式,这里我们选择使用 HAProxy 来进行负载均衡,当然也可以使用其他负载均衡中间件,如LVS等。HAProxy 同时支持四层和七层负载均衡,并基于单一进程的事件驱动模型,因此它可以支持非常高的井发连接数。
接着假设我们只采用一台 HAProxy ,那么它就存在明显的单点故障的问题,所以至少需要两台 HAProxy ,同时这两台 HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived 。KeepAlived 采用 VRRP (Virtual Router Redundancy Protocol,虚拟路由冗余协议) 来解决单点失效的问题,它通常由一组一备两个节点组成,同一时间内只有主节点会提供对外服务,并同时提供一个虚拟的 IP 地址 (Virtual Internet Protocol Address ,简称 VIP) 。 如果主节点故障,那么备份节点会自动接管 VIP 并成为新的主节点 ,直到原有的主节点恢复。
最后,任何想要连接到 RabbitMQ 集群的客户端只需要连接到虚拟 IP,而不必关心集群是何种架构,示例如下:
ConnectionFactory factory = new ConnectionFactory();
// 假设虚拟ip为 192.168.0.200
factory.setHost("192.168.0.200");
1.2 部署情况
下面我们开始进行搭建,这里我使用三台主机,主机名分别为 rabbit-node2, rabbit-node3 和 rabbit3 ,其功能分配如下:
| 主机名 | IP地址 | 部署服务 | 操作系统 | 配置 |
|---|---|---|---|---|
| rabbit-node1 | 192.168.0.12 | RabbitMQ + HAProxy + KeepAlived | CentOS 7.6 | 4核8G |
| rabbit-node2 | 192.168.0.14 | RabbitMQ + HAProxy + KeepAlived | CentOS 7.6 | 4核8G |
| rabbit-node3 | 192.168.0.15 | RabbitMQ | CentOS 7.6 | 4核8G |
以上三台主机上我均已安装好了 RabbitMQ ,关于 RabbitMQ 的安装步骤可以参考:《RabbitMQ单机环境搭建》
2 RabbitMQ 集群搭建
2.1 初始化环境
分别修改主机名
hostnamectl set-hostname rabbit-node1
修改每台机器的 /etc/hosts 文件
cat >> /etc/hosts <<EOF
192.168.0.12 rabbit-node1
192.168.0.14 rabbit-node2
192.168.0.15 rabbit-node3
EOF
重启虚拟机便于系统识别hosts
# 重启网络
systemctl restart network
setenforce 0
# 重启
init 6
2.2 配置 Erlang Cookie
将 rabbit-node1 上的 .erlang.cookie 文件拷贝到其他两台主机上。该 cookie 文件相当于密钥令牌,集群中的 RabbitMQ 节点需要通过交换密钥令牌以获得相互认证,因此处于同一集群的所有节点需要具有相同的密钥令牌,否则在搭建过程中会出现 Authentication Fail 错误。
RabbitMQ 服务启动时,erlang VM 会自动创建该 cookie 文件,默认的存储路径为 /var/lib/rabbitmq/.erlang.cookie 或 $HOME/.erlang.cookie,该文件是一个隐藏文件,需要使用 ls -al 命令查看。(拷贝.cookie时,各节点都必须停止MQ服务):
# 停止所有服务,构建Erlang的集群环境
systemctl stop rabbitmq-server
scp /var/lib/rabbitmq/.erlang.cookie root@rabbit-node2:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie root@rabbit-node3:/var/lib/rabbitmq/
由于你可能在三台主机上使用不同的账户进行操作,为避免后面出现权限不足的问题,这里建议将 cookie 文件原来的 400 权限改为 600,命令如下:
chmod 600 /var/lib/rabbitmq/.erlang.cookie
注:cookie 中的内容就是一行随机字符串,可以使用 cat 命令查看。
2.3 启动服务
在三台主机上均执行以下命令,启动 RabbitMQ 服务:
systemctl start rabbitmq-server
开通 EPMD 端口
epmd进程使用的端口。用于RabbitMQ节点和CLI工具的端点发现服务。
# 开启防火墙 4369 端口
firewall-cmd --zone=public --add-port=4369/tcp --permanent
# 重启
systemctl restart firewalld.service
2.4 集群搭建
RabbitMQ 集群的搭建需要选择其中任意一个节点为基准,将其它节点逐步加入。这里我们以 rabbit-node1 为基准节点,将 rabbit-node2 和 rabbit-node3 加入集群。在 rabbit-node2 和rabbit-node3 上执行以下命令:
# 1.停止服务
rabbitmqctl stop_app
# 2.重置状态
rabbitmqctl reset
# 3.节点加入, 在一个node加入cluster之前,必须先停止该node的rabbitmq应用,即先执行stop_app
# rabbit-node2加入node1, rabbit-node3加入node2
rabbitmqctl join_cluster rabbit@rabbit-node1
# 4.启动服务
rabbitmqctl start_app
join_cluster 命令有一个可选的参数 --ram ,该参数代表新加入的节点是内存节点,默认是磁盘节点。如果是内存节点,则所有的队列、交换器、绑定关系、用户、访问权限和 vhost 的元数据都将存储在内存中,如果是磁盘节点,则存储在磁盘中。内存节点可以有更高的性能,但其重启后所有配置信息都会丢失,因此RabbitMQ 要求在集群中至少有一个磁盘节点,其他节点可以是内存节点。当内存节点离开集群时,它可以将变更通知到至少一个磁盘节点;然后在其重启时,再连接到磁盘节点上获取元数据信息。除非是将 RabbitMQ 用于 RPC 这种需要超低延迟的场景,否则在大多数情况下,RabbitMQ 的性能都是够用的,可以采用默认的磁盘节点的形式。这里为了演示, rabbit-node3 我就设置为内存节点。
另外,如果节点以磁盘节点的形式加入,则需要先使用 reset 命令进行重置,然后才能加入现有群集,重置节点会删除该节点上存在的所有的历史资源和数据。采用内存节点的形式加入时可以略过 reset 这一步,因为内存上的数据本身就不是持久化的。
2.5 查看集群状态
2.5.1 命令行查看
在 rabbit-node3 和 3 上执行以上命令后,集群就已经搭建成功,此时可以在任意节点上使用 rabbitmqctl cluster_status 命令查看集群状态,输出如下:
[root@rabbit-node1 keepalived]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit-node1 ...
[{
nodes,[{
disc,['rabbit@rabbit-node1','rabbit@rabbit-node2',
'rabbit@rabbit-node3']}]},
{
running_nodes,['rabbit@rabbit-node3','rabbit@rabbit-node2',
'rabbit@rabbit-node1']},
{
cluster_name,<<"rabbit@rabbit-node1">>},
{
partitions,[]},
{
alarms,[{
'rabbit@rabbit-node3',[]},
{
'rabbit@rabbit-node2',[]},
{
'rabbit@rabbit-node1',[]}]}]
可以看到 nodes 下显示了全部节点的信息,其中 rabbit-node2 和 rabbit3 上的节点都是 disc 类型,即磁盘节点;而 rabbit-node3 上的节点为 ram,即内存节点。此时代表集群已经搭建成功,默认的 cluster_name 名字为 rabbit@rabbit-node1,如果你想进行修改,可以使用以下命令:
rabbitmqctl set_cluster_name my_rabbitmq_cluster
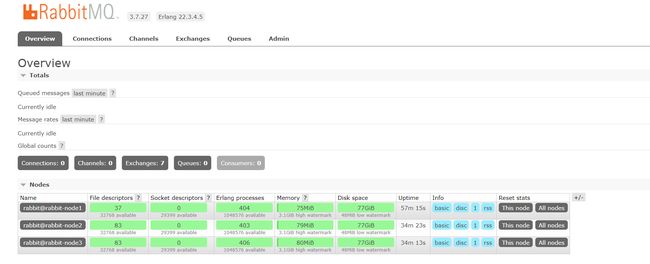
2.5.2 UI 界面查看
除了可以使用命令行外,还可以使用打开任意节点的 UI 界面进行查看,情况如下:
2.6 配置镜像队列
2.6.1 开启镜像队列
这里我们为所有队列开启镜像配置,其语法如下:
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
2.6.2 复制系数
在上面我们指定了 ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中。这里我们之所以这样配置,因为我们本身只有三个节点,因此复制操作的性能开销比较小。如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。此时需要同时修改镜像策略为 exactly,并指定复制系数 ha-params,示例命令如下:
rabbitmqctl set_policy ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
除此之外,RabbitMQ 还支持使用正则表达式来过滤需要进行镜像操作的队列,示例如下:
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'
此时只会对 ha 开头的队列进行镜像。更多镜像队列的配置说明,可以参考官方文档:Highly Available (Mirrored) Queues
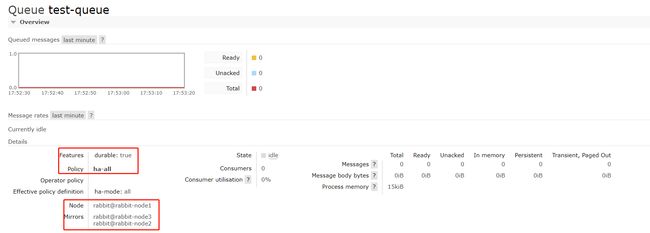
2.6.3 查看镜像状态
配置完成后,可以通过 Web UI 界面查看任意队列的镜像状态,情况如下:
2.7 集群的关闭与重启
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。
这带来的一个问题是,假设在一个三节点的集群当中,关闭的顺序为 node1,node2,node3,如果 node1 因为故障暂时没法恢复,此时 node2 和 node3 就无法启动。想要解决这个问题,可以先将 node1 节点进行剔除,命令如下:
rabbitmqctl forget_cluster_node rabbit@node1 --offline
此时需要加上 -offline 参数,它允许节点在自身没有启动的情况下将其他节点剔除。
2.8 解除集群
重置当前节点
# 1.停止服务
rabbitmqctl stop_app
# 2.重置集群状态
rabbitmqctl reset
# 3.重启服务
rabbitmqctl start_app
重新加入集群
# 1.停止服务
rabbitmqctl stop_app
# 2.重置状态
rabbitmqctl reset
# 3.节点加入
rabbitmqctl join_cluster rabbit@rabbit-node1
# 4.重启服务
rabbitmqctl start_app
完成后重新检查 RabbitMQ 集群状态
rabbitmqctl cluster_status
除了在当前节点重置集群外,还可在集群其他正常节点将节点踢出集群
rabbitmqctl forget_cluster_node rabbit@rabbit-node3
2.9 变更节点类型
我们可以将节点的类型从RAM更改为Disk,反之亦然。假设我们想要反转rabbit@rabbit-node2和rabbit@rabbit-node1的类型,将前者从RAM节点转换为磁盘节点,而后者从磁盘节点转换为RAM节点。为此,我们可以使用change_cluster_node_type命令。必须首先停止节点。
# 1.停止服务
rabbitmqctl stop_app
# 2.变更类型 ram disc
rabbitmqctl change_cluster_node_type disc
# 3.重启服务
rabbitmqctl start_app
2.10 清除 RabbitMQ 节点配置
# 如果遇到不能正常退出直接kill进程
systemctl stop rabbitmq-server
# 查看进程
ps aux|grep rabbitmq
# 清楚节点rabbitmq配置
rm -rf /var/lib/rabbitmq/mnesia
3 HAProxy 环境搭建
yum 源安装目前版本比较低,采用源码安装方式。
3.1 下载
HAProxy 官方下载地址为:www.haproxy.org/#down ,如果这个网站无法访问,也可以从 src.fedoraproject.org/repo/pkgs/h… 上进行下载。这里我下载的是 2.x 的版本,下载后进行解压:
tar -zxvf haproxy-2.1.8.tar.gz
3.2 编译
进入解压后根目录,执行下面的编译命令:
make TARGET=linux-glibc PREFIX=/usr/local/haproxy-2.1.8
make install PREFIX=/usr/local/haproxy-2.1.8
3.3 配置环境变量
配置环境变量:
vim /etc/profile
export HAPROXY_HOME=/usr/local/haproxy-2.1.8
export PATH=$PATH:$HAPROXY_HOME/sbin
使得配置的环境变量立即生效:
source /etc/profile
检查安装是否成功:
[root@rabbit-node1 haproxy-2.1.8]# haproxy -v
HA-Proxy version 2.1.8 2020/07/31 - https://haproxy.org/
Status: stable branch - will stop receiving fixes around Q1 2021.
Known bugs: http://www.haproxy.org/bugs/bugs-2.1.8.html
Running on: Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64
3.4 负载均衡配置
新建配置文件 haproxy.cfg,这里我新建的位置为:/etc/haproxy/haproxy.cfg。
# 创建目录
mkdir /etc/haproxy
# 编辑文件内容
vim /etc/haproxy/haproxy.cfg
文件内容如下:
# 全局配置
global
# 日志输出配置、所有日志都记录在本机,通过 local0 进行输出
log 127.0.0.1 local0 info
# 最大连接数
maxconn 4096
# 改变当前的工作目录
chroot /usr/local/haproxy-2.1.8
# 以指定的 UID 运行 haproxy 进程
uid 99
# 以指定的 GID 运行 haproxy 进程
gid 99
# 以守护进行的方式运行
daemon
# 当前进程的 pid 文件存放位置
pidfile /usr/local/haproxy-2.1.8/haproxy.pid
# 默认配置
defaults
# 应用全局的日志配置
log global
# 使用4层代理模式,7层代理模式则为"http"
mode tcp
# 日志类别
option tcplog
# 不记录健康检查的日志信息
option dontlognull
# 3次失败则认为服务不可用
retries 3
# 每个进程可用的最大连接数
maxconn 2000
# 连接超时
timeout connect 5s
# 客户端超时
timeout client 120s
# 服务端超时
timeout server 120s
# 绑定配置
listen rabbitmq_cluster
bind :5671
# 配置TCP模式
mode tcp
# 采用加权轮询的机制进行负载均衡
balance roundrobin
# RabbitMQ 集群节点配置
server mq-node1 rabbit-node1:5672 check inter 5000 rise 2 fall 3 weight 1
server mq-node2 rabbit-node2:5672 check inter 5000 rise 2 fall 3 weight 1
server mq-node3 rabbit-node3:5672 check inter 5000 rise 2 fall 3 weight 1
# 配置监控页面
listen monitor
bind :8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
负载均衡的主要配置在 listen rabbitmq_cluster 下,这里指定负载均衡的方式为加权轮询,同时定义好健康检查机制:
server node1 rabbit-node1:5672 check inter 5000 rise 2 fall 3 weight 1
以上配置代表对地址为 rabbit-node1:5672 的 node1 节点每隔 5 秒进行一次健康检查,如果连续两次的检查结果都是正常,则认为该节点可用,此时可以将客户端的请求轮询到该节点上;如果连续 3 次的检查结果都不正常,则认为该节点不可用。weight 用于指定节点在轮询过程中的权重。
3.5 启动服务
以上搭建步骤在 rabbit-node1 和 rabbit-node2 上完全相同,搭建完成使用以下命令启动服务:
# 启动
haproxy -f /etc/haproxy/haproxy.cfg
# 查看运行
ps aux|grep haproxy
# 停止 没有killall命令, 安装yum -y install psmisc
killall haproxy
开启监控页面访问端口
firewall-cmd --zone=public --add-port=8100/tcp --permanent
systemctl restart firewalld.service
启动后可以在监控页面进行查看,端口为设置的 8100,完整地址为:http://rabbit-node1:8100/stats ,页面情况如下:
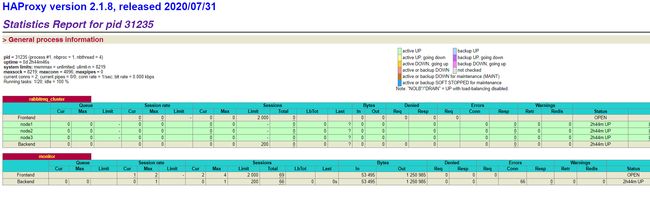
所有节点都为绿色,代表节点健康。此时证明 HAProxy 搭建成功,并已经对 RabbitMQ 集群进行监控。
4 Keepalived 环境搭建
接着就可以搭建 Keepalived 来解决 HAProxy 故障转移的问题。这里我在 rabbit-node1 和 rabbit-node2上安装 KeepAlived ,两台主机上的搭建的步骤完全相同,只是部分配置略有不同,具体如下:
环境说明
| Name | IP Addr | Service Name | Descprition |
|---|---|---|---|
| VIP | 192.168.0.200 | 虚拟 IP | |
| MASTER | 192.168.0.12 | rabbit-node1 | 主服务器 IP |
| BACKUP | 192.168.0.14 | rabbit-node2 | 备服务器 IP |
4.1 安装
Keepalived 可以使用 yum 直接安装,在 MASTER 服务器和 BACKUP 服务器执行:
yum -y install keepalived
4.2 配置 MASTER 和 BACKUP
确认网卡
[root@rabbit-node1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether fa:16:3e:52:87:80 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.12/24 brd 192.168.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.0.200/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe52:8780/64 scope link
valid_lft forever preferred_lft forever
[root@rabbit-node1 ~]#
本例使用 eth0 这块网卡。
vim /etc/keepalived/keepalived.conf
MASTER 节点配置
完整配置如下:
global_defs {
# 路由id,主备节点不能相同
router_id node1
notification_email {
# email 接收方
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
# email 发送方
notification_email_from Alexandre.Cassen@firewall.loc
# 邮件服务器, smtp 协议
smtp_server 192.168.200.1
smtp_connect_timeout 30
vrrp_skip_check_adv_addr
# 使用 unicast_src_ip 需要注释 vrrp_strict,而且也可以进行 ping 测试
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
# 自定义监控脚本
vrrp_script chk_haproxy {
# 脚本位置
script "/etc/keepalived/haproxy_check.sh"
# 脚本执行的时间间隔
interval 5
weight 10
}
vrrp_instance VI_1 {
# Keepalived的角色,MASTER 表示主节点,BACKUP 表示备份节点
state MASTER
# 指定监测的网卡,可以使用 ifconfig 进行查看
interface eth0
# 虚拟路由的id,主备节点需要设置为相同
virtual_router_id 51
# 优先级,主节点的优先级需要设置比备份节点高
priority 100
# 设置主备之间的检查时间,单位为秒
advert_int 1
# 如果两节点的上联交换机禁用了组播,则采用 vrrp 单播通告的方式
unicast_src_ip 192.168.0.12
unicast_peer {
192.168.0.14
}
# 定义验证类型和密码
authentication {
auth_type PASS
auth_pass 123456
}
# 调用上面自定义的监控脚本
track_script {
chk_haproxy
}
virtual_ipaddress {
# 虚拟IP地址,可以设置多个
192.168.0.200
}
}
备份节点的配置与主节点基本相同,但是需要修改其 state 为 BACKUP;同时其优先级 priority 需要比主节点低。
BACKUP 节点配置
完整配置如下:
global_defs {
# 路由id,主备节点不能相同
router_id node2
notification_email {
# email 接收方
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
# email 发送方
notification_email_from Alexandre.Cassen@firewall.loc
# 邮件服务器, smtp 协议
smtp_server 192.168.200.1
smtp_connect_timeout 30
vrrp_skip_check_adv_addr
# 使用 unicast_src_ip 需要注释 vrrp_strict,而且也可以进行 ping 测试
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 5
weight 10
}
vrrp_instance VI_1 {
# BACKUP 表示备份节点
state BACKUP
# 指定监测的网卡
interface eth0
# 虚拟路由的id,主备节点需要设置为相同
virtual_router_id 51
# 优先级,备份节点要比主节点低
priority 50
advert_int 1
# 如果两节点的上联交换机禁用了组播,则采用 vrrp 单播通告的方式
unicast_src_ip 192.168.0.14
unicast_peer {
192.168.0.12
}
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.0.200
}
}
注意以下几点
- state 角色为 BACKUP
- interface 为网卡的 ID,要根据机器确认
- virtual_route_id 要与 MASTER 一致,默认为 51
- priority 要比 MASTER 小
- unicast_src_ip 要设置正确,组播地址设置之后,要注释 vrrp_strict 选项
4.3 配置 HAProxy 检查
以上配置定义了 Keepalived 的 MASTER 节点和 BACKUP 节点,并设置对外提供服务的虚拟 IP 为 192.168.0.200。此外最主要的是定义了通过 haproxy_check.sh 来对 HAProxy 进行监控,这个脚本需要我们自行创建,内容如下:
vim /etc/keepalived/haproxy_check.sh
#!/bin/bash
# 判断haproxy是否已经启动
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
#如果没有启动,则启动
haproxy -f /etc/haproxy/haproxy.cfg
fi
#睡眠3秒以便haproxy完全启动
sleep 3
#如果haproxy还是没有启动,此时需要将本机的keepalived服务停掉,以便让VIP自动漂移到另外一台haproxy
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
systemctl stop keepalived
fi
创建后为其赋予执行权限
chmod +x /etc/keepalived/haproxy_check.sh
这个脚本主要用于判断 HAProxy 服务是否正常,如果不正常且无法启动,此时就需要将本机 Keepalived 关闭,从而让虚拟 IP 漂移到备份节点。
4.4 配置并启动服务
配置 IP 转发,需要修改配置文件 /etc/sysctl.conf,默认只有 root 可以修改,分别在 MASTER 和 BACKUP上修改。
# 切换用户
su -root
# 文件配置
echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
# 生效
sysctl -p
rabbit-node1 和 rabbit-node2 上启动 KeepAlived 服务,命令如下:
systemctl start keepalived
设置开机自动启
systemctl enable keepalived
启动后此时 rabbit-node1 为主节点,可以在 rabbit-node1 上使用 ip a 命令查看到虚拟 IP 的情况:
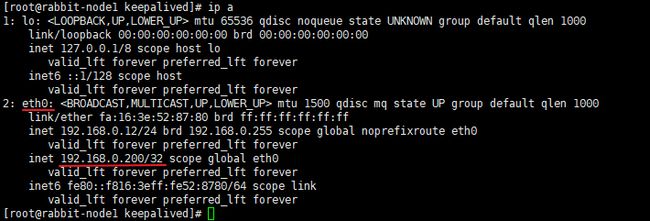
此时只有 rabbit-node1 上是存在虚拟 IP 的,而 rabbit-node2 上是没有的。
漂移规则如下:
- 默认使用 MASTER 服务器(
192.168.0.12),虚拟 IP 为192.168.0.200,此时 MASTER 服务器会有 2 个IP。 - 当 MASTER 出问题时,IP 会漂移到 BACKUP 服务器(
192.168.0.14),此时 BACKUP 服务器会有 2 个IP。 - 当 MASTER 重新启动后,虚拟 IP 又会漂移回 MASTER 服务器。
4.5 验证故障转移
这里我们验证一下故障转移,因为按照我们上面的检测脚本,如果 HAProxy 已经停止且无法重启时 KeepAlived 服务就会停止,这里我们直接使用以下工具进行验证。
安装 tcpdump 包
yum -y install tcpdump
在 MASTER 服务器上执行
[root@rabbit-node1 ~]# tcpdump -i eth0 vrrp -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:42:48.521201 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
23:42:49.522332 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
23:42:50.523458 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
23:42:51.524597 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
...
...
这表明 MASTER 在向 BACKUP 广播,MASTER 在线。此时虚拟 IP 时挂在 MASTER 上的,如果想退出, 按 Ctrl+C。
如果 MASTER 停止 keepalived,虚拟 IP 会漂移到 BACKUP 服务器上。
我们可以测试一下:
首先,停止 MASTER 的 keepalived
systemctl stop keepalived
然后,在 MASTER 服务器上查看 VRRP 服务
[root@rabbit-node1 ~]# tcpdump -i eth0 vrrp -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:44:19.297025 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
23:44:20.297257 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
23:44:21.297652 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
23:44:22.297348 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
...
...
这表明 MASTER 收到 BACKUP 的广播,此时虚拟 IP 时挂在 BACKUP 服务器上。
此时再次使用 ip a 分别查看,可以发现 MASTER 上的 VIP 已经漂移到 BACKUP 上,情况如下:
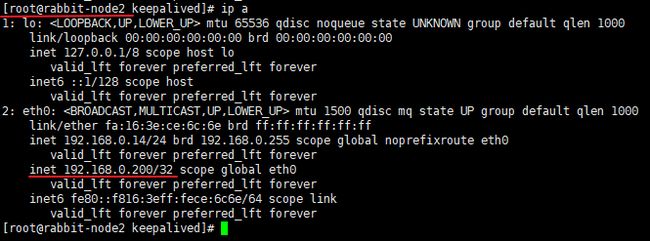
再次重启 MASTER 服务器,会发现 VIP 又重新漂移回 MASTER 服务器。
此时对外服务的 VIP 依然可用,代表已经成功地进行了故障转移。至此集群已经搭建成功,任何需要发送或者接受消息的客户端服务只需要连接到该 VIP 即可,示例如下:
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.0.200");
4.6 配置日志
注意此配置为可选步骤。
keepalived 默认将日志输出到系统日志/var/log/messages中,因为系统日志很多,查询问题时相对麻烦。
我们可以将 keepalived 的日志单独拿出来,这需要修改日志输出路径。
修改 Keepalived 配置
vim /etc/sysconfig/keepalived
更改如下:
# Options for keepalived. See `keepalived --help' output and keepalived(8) and
# keepalived.conf(5) man pages for a list of all options. Here are the most
# common ones :
#
# --vrrp -P Only run with VRRP subsystem.
# --check -C Only run with Health-checker subsystem.
# --dont-release-vrrp -V Dont remove VRRP VIPs & VROUTEs on daemon stop.
# --dont-release-ipvs -I Dont remove IPVS topology on daemon stop.
# --dump-conf -d Dump the configuration data.
# --log-detail -D Detailed log messages.
# --log-facility -S 0-7 Set local syslog facility (default=LOG_DAEMON)
#
KEEPALIVED_OPTIONS="-D -d -S 0"
把 KEEPALIVED_OPTIONS=”-D” 修改为 KEEPALIVED_OPTIONS=”-D -d -S 0”,其中 -S 指定 syslog 的 facility
修改 /etc/rsyslog.conf 末尾添加
vim /etc/rsyslog.conf
local0.* /var/log/keepalived.log
重启日志记录服务
systemctl restart rsyslog
重启 keepalived
systemctl restart keepalived
此时,可以从 /var/log/keepalived.log 查看日志了。
参考资料
- https://juejin.im/post/6844904071183220749
- RabbitMQ 官方文档 —— 集群指南:www.rabbitmq.com/clustering.…
- RabbitMQ 官方文档 —— 高可用镜像队列:www.rabbitmq.com/ha.html
- HAProxy 官方配置手册:cbonte.github.io/haproxy-dco…
- KeepAlived 官方配置手册:www.keepalived.org/manpage.htm…