Tesseract-OCR的使用---提取图片中的文字(OneNote)
方法1:利用我们常用的聊天通讯工具QQ
使用方法:先随便选择一个好友发送该图片,然后点击图片发大查看,然后长按识别,就会对应弹出选项“提取图中文字”选择即可。

方法2:微软office中的OneNote软件即可
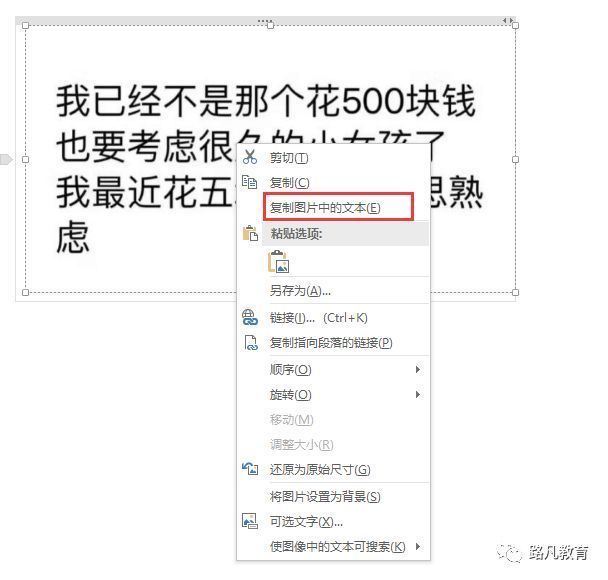
使用方法:把要提取文字的图片插入OneNote中,然后右击,选择复制图片中的文字即可,然后粘贴到其他文档中就ok了。
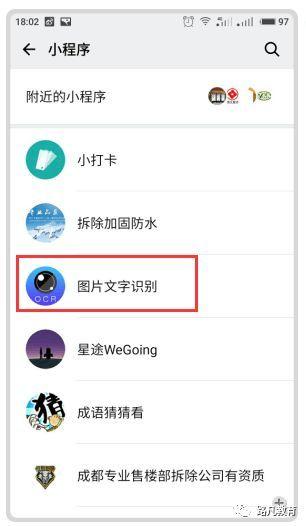
方法3:使用微信小程序
使用方法:直接微信中搜索图片文字识别小程序,然后打开上传有文字的图片即可。
Tesseract ,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
源码地址为: https://github.com/tesseract-ocr/tesseract ;
EXE可执行文件地址: http://download.csdn.net/download/whatday/7740469 ;
接下来,我们将在Windows环境下安装Tesseract并实现简单的转换和训练:
1、Tesseract实现
大体流程:Tesseract安装 -> 打开命令行 -> 生成目标文件
Tesseract安装
下载tesseract-ocr-setup-3.02.02.exe安装包,安装成功后会在相应磁盘下有Tesseract-OCR文件夹,如图
打开命令行
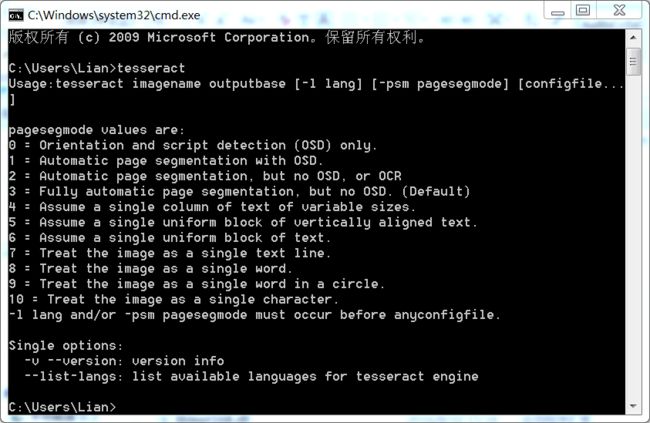
打开命令行,输入tesseract,回车;以下便是tesseract的大体面貌:
生成目标文件
先准备一张图片文件,如test.png
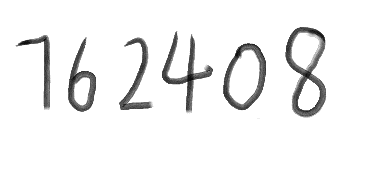
将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。

打开文件output_1.txt,发现tesseract成功的将图像转换成 152408 。

可喜可贺,说明老牌名将tesseract还是很强的!但是还是有点不够准确,那么我们有没有什么办法能提高tesseract识别字符准确率呢?接下来,我们将使用配套训练工具 jTessBoxEditor 来训练样本,来提高我们的准确率!
2、Tesseract训练:
大体流程为:安装jTessBoxEditor -> 获取样本文件 -> Merge样本文件 –> 生成BOX文件 -> 定义字符配置文件 -> 字符矫正 -> 执行批处理文件 -> 将生成的traineddata放入tessdata中
安装jTessBoxEditor
下载jTessBoxEditor,地址 https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ ;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装 JRE (Java Runtime Environment,Java运行环境)。
获取样本文件
我们可以用画图工具绘制样本文件,数量越多越好,我自己画了5张图,如图:
【注意】:样本图像文件格式必须为tif\tiff格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
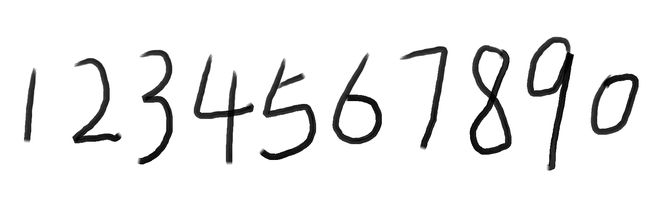




Merge样本文件
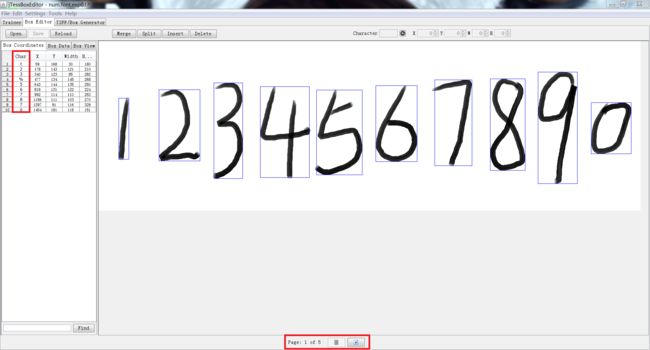
打开jTessBoxEditor,Tools->Merge TIFF,将样本文件全部选上,并将合并文件保存为num.font.exp0.tif
生成BOX文件
打开命令行并切换至num.font.exp0.tif所在目录,输入,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
定义字符配置文件
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font 0 0 0 0 0
【语法】:
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
字符矫正
打开jTessBoxEditor,BOX Editor -> Open,打开num.font.exp0.tif; 矫正
修改后记得保存。
执行批处理文件
在目标目录下生成一个批处理文件

-F font_properties -U unicharset -& pause
保存后执行即可,执行结果如图:

最终文件夹内会有以下文件,如图:

将生成的traineddata放入tessdata中
最后将num.trainddata复制到Tesseract-OCR中tessdata文件夹即可。
3、最后的测试
按照之前步骤,使用命令行输入
tesseract test.png output_2 -l num
我们可以看到新生成的文件output_2的内容为 762408 ,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的eng语言匹配库。
Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路。
文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除。
一、准备工作
1、下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。
2、下载chi_sim.traindata字库。要有这个才能识别中文。下好后,放到Tesseract-OCR项目的tessdata文件夹里面。
3、下载jTessBoxEditor,这个是用来训练字库的。
以上的几个在百度都能找到下载,就不详细讲了。
二、识别
1、进入cmd,进入到要识别的图片的路径下。
2、输入命令
|
1
|
tesseract 图片名称 生成的结果文件的名称 字库
|
例如我的图片识别就是:
|
1
|
tesseract test.jpg result -l chi_sim
|

识别完后会生成result.txt文件
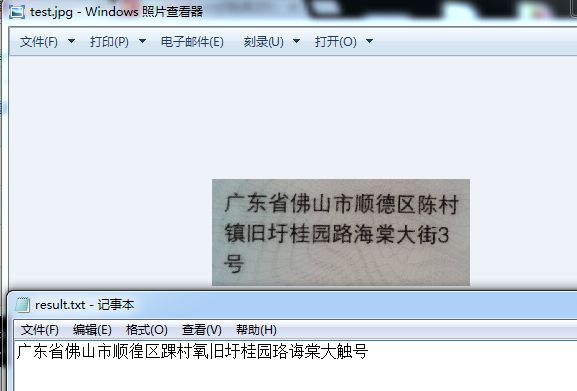
当然啦效果不太理想。所以我们要训练自己的字库。
三、训练
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
更改图片名字,这个是有要求的=。=
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
2、生成box文件。
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
|

box文件和对应的tif一定要在相同的目录下,不然后面打不开。
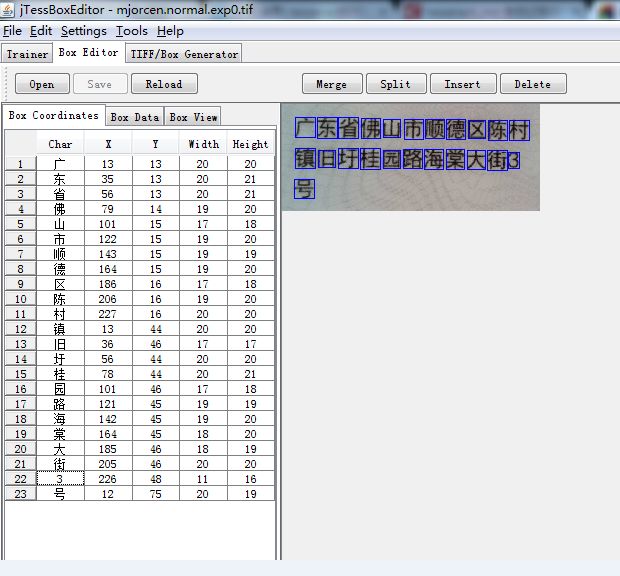
3、打开jTessBoxEditor矫正错误并训练
打开train.bat
找到tif图,打开,并校正。
4、训练。
只要在命令行输入命令即可。
|
1
|
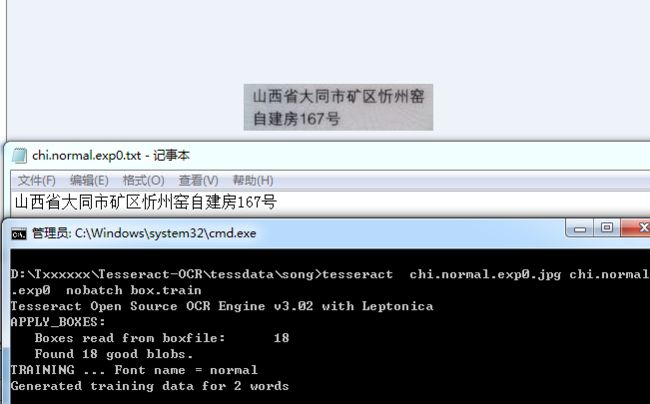
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.train
|
|
1
|
unicharset_extractor mjorcen.normal.exp0.box
|

在这我明明已经矫正好了,但是还是有1个字符不能识别出来,报的错跟实际上完全没有相关性,不知道是不是bug,到后面的结果就是“园”字没有识别出来。
先不管,毕竟只有一个样本。
新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
继续敲命令
|
1
2
3
4
5
6
7
8
9
|
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.tr
cntraining mjorcen.normal.exp0.tr
|
最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
如图:

命令行输入,合并五个文件:
|
1
|
combine_tessdata normal.
|
得到训练好的字库。
四、测试
1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:
|
1
|
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal
|
3、效果

对比:
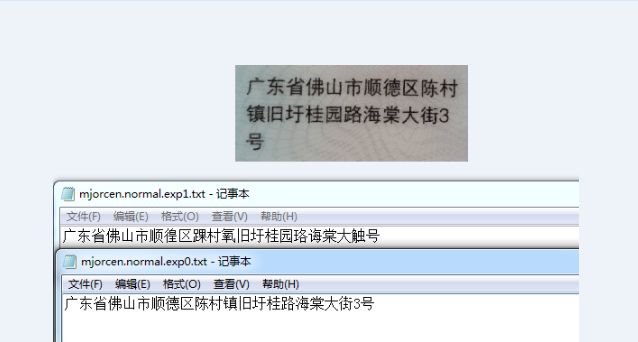
总结:肯定要自己训练过后的字库识别效果好,接下来要把整个项目弄进android,还要研究怎么将多个字库合并成一个字库,因为我不可能一次训练完所有的图片文字的。到时候有什么成果了再分享博文。希望大家可以点赞!谢谢。
更新:没有错误的话命令行的提示应该是这样的
About Me
| ........................................................................................................................ ● 本文作者:小麦苗,部分内容整理自网络,若有侵权请联系小麦苗删除 ● 本文在itpub( http://blog.itpub.net/26736162 )、博客园( http://www.cnblogs.com/lhrbest )和个人weixin公众号( xiaomaimiaolhr )上有同步更新 ● 本文itpub地址: http://blog.itpub.net/26736162 ● 本文博客园地址: http://www.cnblogs.com/lhrbest ● 本文pdf版、个人简介及小麦苗云盘地址: http://blog.itpub.net/26736162/viewspace-1624453/ ● 数据库笔试面试题库及解答: http://blog.itpub.net/26736162/viewspace-2134706/ ● DBA宝典今日头条号地址: http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826 ........................................................................................................................ ● QQ群号: 230161599 (满) 、618766405 ● weixin群:可加我weixin,我拉大家进群,非诚勿扰 ● 联系我请加QQ好友 ( 646634621 ) ,注明添加缘由 ● 于 2018-12-01 06:00 ~ 2018-12-31 24:00 在魔都完成 ● 最新修改时间:2018-12-01 06:00 ~ 2018-12-31 24:00 ● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解 ● 版权所有,欢迎分享本文,转载请保留出处 ........................................................................................................................ ● 小麦苗的微店 : https://weidian.com/s/793741433?wfr=c&ifr=shopdetail ● 小麦苗出版的数据库类丛书 : http://blog.itpub.net/26736162/viewspace-2142121/ ● 小麦苗OCP、OCM、高可用网络班 : http://blog.itpub.net/26736162/viewspace-2148098/ ● 小麦苗腾讯课堂主页 : https://lhr.ke.qq.com/ ........................................................................................................................ 使用 weixin客户端 扫描下面的二维码来关注小麦苗的weixin公众号( xiaomaimiaolhr )及QQ群(DBA宝典)、添加小麦苗weixin, 学习最实用的数据库技术。 ........................................................................................................................ |

 |
 |
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2285595/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2285595/