zookeeper服务端启动入口是QuorumPeerMain的main方法,
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
main.initializeAndRun(args);
.....省略异常校验代码......
其中主要的逻辑方法是initializeAndRun
protected void initializeAndRun(String[] args)
throws ConfigException, IOException, AdminServerException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.isDistributed()) {
//集群模式
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
//单机模式
ZooKeeperServerMain.main(args);
}
}
通常采用配置文件zoo.cfg的方式加载配置,也就是args.length == 1 && args[0]是配置文件的路径,其中QuorumPeerConfig通过parse(String path)方法存储了配置解析的信息。可参考zookeeper中的配置信息详解
如果配置了多个server节点(config.isDistributed()),将以集群方式启动,否则以单机模式启动,首先分析单机模式的启动
单机版服务器启动

主要处理函数:ZooKeeperServerMain.runFromConfig
public void runFromConfig(ServerConfig config) throws IOException, AdminServerException {
LOG.info("Starting server");
FileTxnSnapLog txnLog = null;
try {
txnLog = new FileTxnSnapLog(config.dataLogDir, config.dataDir);
final ZooKeeperServer zkServer = new ZooKeeperServer(txnLog,
config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, null);
txnLog.setServerStats(zkServer.serverStats());
// Registers shutdown handler which will be used to know the
// server error or shutdown state changes.
final CountDownLatch shutdownLatch = new CountDownLatch(1);
zkServer.registerServerShutdownHandler(
new ZooKeeperServerShutdownHandler(shutdownLatch));
// Start Admin server
adminServer = AdminServerFactory.createAdminServer();
adminServer.setZooKeeperServer(zkServer);
adminServer.start();
boolean needStartZKServer = true;
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false);
cnxnFactory.startup(zkServer);
// zkServer has been started. So we don't need to start it again in secureCnxnFactory.
needStartZKServer = false;
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), true);
secureCnxnFactory.startup(zkServer, needStartZKServer);
}
containerManager = new ContainerManager(zkServer.getZKDatabase(), zkServer.firstProcessor,
Integer.getInteger("znode.container.checkIntervalMs", (int) TimeUnit.MINUTES.toMillis(1)),
Integer.getInteger("znode.container.maxPerMinute", 10000)
);
containerManager.start();
// Watch status of ZooKeeper server. It will do a graceful shutdown
// if the server is not running or hits an internal error.
shutdownLatch.await();
shutdown();
if (cnxnFactory != null) {
cnxnFactory.join();
}
if (secureCnxnFactory != null) {
secureCnxnFactory.join();
}
if (zkServer.canShutdown()) {
zkServer.shutdown(true);
}
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Server interrupted", e);
} finally {
if (txnLog != null) {
txnLog.close();
}
}
}
初始化过程:
1.创建数据管理器FileTxnSnapLog
FileTxnSnapLog是zookeeper上层服务器和底层数据存储的对接层,提供操作事务日志和快照的接口,可参考zookeeper源码分析(6)-数据和存储 ,在启动服务器时用来恢复本地数据
2.创建服务器实例ZooKeeperServer
ZooKeeperServer是单机版服务端的实现,
构造函数如下:
public ZooKeeperServer(FileTxnSnapLog txnLogFactory, int tickTime,
int minSessionTimeout, int maxSessionTimeout, ZKDatabase zkDb) {
serverStats = new ServerStats(this);
this.txnLogFactory = txnLogFactory;
this.txnLogFactory.setServerStats(this.serverStats);
this.zkDb = zkDb;
this.tickTime = tickTime;
//没有配置默认为2*tickTime
setMinSessionTimeout(minSessionTimeout);
//没有配置默认为20*tickTime
setMaxSessionTimeout(maxSessionTimeout);
listener = new ZooKeeperServerListenerImpl(this);
ServerStats是服务器运行的统计器,包含最基本的运行时信息,ZooKeeperServer实现了ServerStats.Provider接口
public class ServerStats {
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端向客户端发送的响应包次数
private long packetsSent;
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端从客户端接收的请求包次数
private long packetsReceived;
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端请求处理的最大延时
private long maxLatency;
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端请求处理的最小延时
private long minLatency = Long.MAX_VALUE;
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端请求处理的总延时
private long totalLatency = 0;
//从服务器启动开始,或最近一次重置服务端统计信息之后,服务端请求处理总次数
private long count = 0;
//记录事务日志fsync刷盘的超过阈值时间的报警次数
private AtomicLong fsyncThresholdExceedCount = new AtomicLong(0);
private final Provider provider;
public interface Provider {
public long getOutstandingRequests();
public long getLastProcessedZxid();
public String getState();
public int getNumAliveConnections();
public long getDataDirSize();
public long getLogDirSize();
}
public ServerStats(Provider provider) {
this.provider = provider;
}
设置服务器tickTime和会话超时时间限制,初始化ZooKeeperServerListenerImpl,用来监听某些重要线程挂掉时,更改ZooKeeperServer的state为State.ERROR
3.启动AdminServer
AdminServer主要是用来接收一些执行命令的请求,默认实现为JettyAdminServer,默认暴露端口为8080,可通过http://
4.初始化ServerCnxnFactory并启动
ServerCnxnFactory是创建和客户端交互的IO线程和worker线程,有NIOServerCnxnFactory,NettyServerCnxnFactory实现。默认为NIOServerCnxnFactory实现,使用非阻塞事件驱动的NIO方式处理连接,创建线程数和机器硬件有关,如
32核的机器默认为1个
接收新连接的线程,1个会话校验线程,4个IO读写线程和64个IO数据处理线程
配置如下:
public void configure(InetSocketAddress addr, int maxcc, boolean secure) throws IOException {
maxClientCnxns = maxcc;
sessionlessCnxnTimeout = Integer.getInteger(
ZOOKEEPER_NIO_SESSIONLESS_CNXN_TIMEOUT, 10000);
// We also use the sessionlessCnxnTimeout as expiring interval for
// cnxnExpiryQueue. These don't need to be the same, but the expiring
// interval passed into the ExpiryQueue() constructor below should be
// less than or equal to the timeout.
cnxnExpiryQueue =
new ExpiryQueue(sessionlessCnxnTimeout);
expirerThread = new ConnectionExpirerThread();
int numCores = Runtime.getRuntime().availableProcessors();
// 32 cores sweet spot seems to be 4 selector threads
numSelectorThreads = Integer.getInteger(
ZOOKEEPER_NIO_NUM_SELECTOR_THREADS,
Math.max((int) Math.sqrt((float) numCores/2), 1));
if (numSelectorThreads < 1) {
throw new IOException("numSelectorThreads must be at least 1");
}
numWorkerThreads = Integer.getInteger(
ZOOKEEPER_NIO_NUM_WORKER_THREADS, 2 * numCores);
workerShutdownTimeoutMS = Long.getLong(
ZOOKEEPER_NIO_SHUTDOWN_TIMEOUT, 5000);
for(int i=0; i 启动流程为
public void startup(ZooKeeperServer zks, boolean startServer)
throws IOException, InterruptedException {
start();
setZooKeeperServer(zks);
if (startServer) {
zks.startdata();
zks.startup();
}
}
public void start() {
stopped = false;
if (workerPool == null) {
workerPool = new WorkerService(
"NIOWorker", numWorkerThreads, false);
}
for(SelectorThread thread : selectorThreads) {
if (thread.getState() == Thread.State.NEW) {
thread.start();
}
}
// ensure thread is started once and only once
if (acceptThread.getState() == Thread.State.NEW) {
acceptThread.start();
}
if (expirerThread.getState() == Thread.State.NEW) {
expirerThread.start();
}
}
可见分别启动了expirerThread,acceptThread,selectorThreads和workerPool
acceptThread是单线程的,主要用来接收客户端新的连接请求,并把新的客户端socket交给一个selectorThread处理,放入它的acceptedQueue,并使它的selector的select操作马上返回。
selectorThread做的事情为
1.将acceptedQueue中的客户端连接取出,包装成NIOServerCnxn,代表一个客户端线程的通信,包含了读写数据相关的方法
2.不断找出有read/write通知的客户端socket(),并调用handleIO,交给workerPool处理io请求数据,在处理数据时,会将当前请求包装成一个IOWorkRequest,最后会包装为ScheduledWorkRequest,也就是一个任务。会暂时取消该channel上的事件监听,等处理完毕之后,会重新更新注册事件。此外,处理数据的前后均会激活会话,重新计算过期时间touchCnxn
private void handleIO(SelectionKey key) {
IOWorkRequest workRequest = new IOWorkRequest(this, key);
NIOServerCnxn cnxn = (NIOServerCnxn) key.attachment();
// Stop selecting this key while processing on its
// connection
cnxn.disableSelectable();
key.interestOps(0);
touchCnxn(cnxn);
workerPool.schedule(workRequest);
}
expirerThread是用来客户端连接过期校验的线程,通过从ExpiryQueue
ExpiryQueue维护了两个map
ConcurrentHashMapkey为每个连接,value为当前连接的过期时间
ConcurrentHashMap:key为下一个过期时间,value为会话过期时间满足key的一批连接
计算会话的下个超时时间的公式为
lastExpirationTime = currentTime + sessionTimeout
newExpirationTime = (lastExpirationTime / expirationInterval + 1) * expirationInterval;
其中expirationInterval为expirerThread定时会话超时检查的时间间隔,这个公式保证了会话总会在离他会话过期的下一个最近时间间隔得到检查。
每次会话激活的时候都会更新连接对应的这两个map,重新计算下个过期时间,expirerThread只要在下个定时检查时间中从ExpiryQueue.expiryMap获得超时的一批连接,清理掉就好。
5.从本地快照数据文件和事务日志文件中恢复本地数据
public void startdata()
throws IOException, InterruptedException {
//check to see if zkDb is not null
if (zkDb == null) {
zkDb = new ZKDatabase(this.txnLogFactory);
}
if (!zkDb.isInitialized()) {
loadData();
}
}
简要的说就是从最近可用的快照中恢复dataTree,并从对应的事务日志中恢复数据的变更,可参考 zookeeper源码分析(6)-数据和存储
6.ZookeeperServer的初始化和启动
public synchronized void startup() {
if (sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
setupRequestProcessors();
registerJMX();
setState(State.RUNNING);
notifyAll();
}
1.创建会话管理器SessionTrackerImpl,是负责服务端的会话管理,如果客户端在会话过期时间内没有激活会话,会将过期的会话清掉。
2.初始化zookeeper的请求处理链
PrepRequestProcessor -> SyncRequestProcessor -> FinalRequestProcessor
也就是数据经过NIOServerCnxn,如果是读IO,会调用ZookeeperServer.processPacket方法,交由处理链处理。可参考zookeeper源码分析(7)-服务器请求处理链的初始化
3.注册JMX服务
4.更改服务状态为State.RUNNING,通知其他阻塞线程并释放锁,至此单机版启动完毕
集群服务器启动
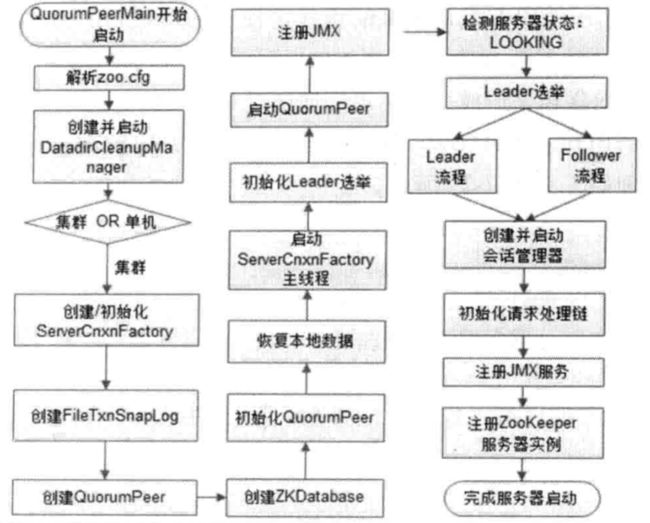
集群版是zab协议的实现,所以相比单机版会多了选举,以及集群中主从服务器的通信和事务请求的发起等逻辑实现。
主要处理函数:QuorumPeerMain.runFromConfig
public void runFromConfig(QuorumPeerConfig config)
throws IOException, AdminServerException
{
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = null;
ServerCnxnFactory secureCnxnFactory = null;
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns(),
false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(),
config.getMaxClientCnxns(),
true);
}
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(
config.getDataLogDir(),
config.getDataDir()));
quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
quorumPeer.enableLocalSessionsUpgrading(
config.isLocalSessionsUpgradingEnabled());
//quorumPeer.setQuorumPeers(config.getAllMembers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setConfigFileName(config.getConfigFilename());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
if (config.getLastSeenQuorumVerifier()!=null) {
quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
}
quorumPeer.initConfigInZKDatabase();
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
初始化过程主要包括:
- 创建并初始化ServerCnxnFactory,同单机版
- 创建数据管理器FileTxnSnapLog
- 创建QuorumPeer实例
QuorumPeer是集群模式下特有的对象,是ZookeeperServer的托管者,在运行期间,会不断检测当前服务器实例的状态,同时根据情况发起Leader选举。 - 创建内存数据库zkDatabase
- 启动quorumPeer
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
loadDataBase();
startServerCnxnFactory();
try {
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
startLeaderElection();
super.start();
}
主要流程包括:
1.恢复本地数据,获得本机最新的lastProcessedZxid 和 currentEpoch等,参考zookeeper源码分析(6)-数据和存储
2.启动ServerCnxnFactory主线程,参考单机版
3.开始集群选举
synchronized public void startLeaderElection() {
try {
if (getPeerState() == ServerState.LOOKING) {
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
}
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
this.electionAlg = createElectionAlgorithm(electionType);
}
如果是 ServerState.LOOKING状态,就构造自己的投票currentVote,electionAlg从3.4之后的版本默认为3,
启动之后的执行流程为:
public void run() {
········省略JMX注册·············
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk =
new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
//运行至此表明当前follewer线程出现问题,需要重置为looking,进行新 一轮的选举
setFollower(null);
updateServerState();
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
//运行至此表明当前leader线程出现问题,需要重置为looking,进行新 一轮的选举
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
start_fle = Time.currentElapsedTime();
}
} finally {
········清理操作·····
}
可以看到,当是looking状态时,会通过选举设置当前投票,setCurrentVote(makeLEStrategy().lookForLeader());默认的选举方法为FastLeaderElection.lookForLeader,这个方法会通过选举最终确定当前服务器的状态,是Leader的话就进行leader相关的初始化并启动leader.lead(),follewer同样启动自己的流程follower.followLeader()。具体分析参考zookeeper源码分析(4)-选举流程和服务器启动处理
至此,服务端启动分析完毕。
感谢您的阅读,我是Monica23334 || Monica2333 。立下每周写一篇原创文章flag的小姐姐,关注我并期待打脸吧~
