Python自然语言处理 | 获得文本语料与词汇资源
- 本章解决问题-
- 什么是有用的文本语料和词汇资源,我们如何使用Python获取它们?
- 哪些Python结构最适合这项工作?
- 编写Python代码时我们如何避免重复的工作?
这里写目录标题
- 1获取文本语料库
-
- 1.1 古腾堡语料库
- 1.2 网络和聊天文本
- 1.3 布朗语料库
- 1.4 路透社语料库
- 1.5 就职演说语料库
- 1.6 其他语料库
- 1.7 文本语料的结构
- 1.8 载入自己的语料库
- 2 条件频率分布
-
- 2.1 条件和事件
- 2.2 按文体计数词汇
- 2.4 使用双连词生成随机文本
- 3 更多关于python:代码重用
- 4 词典资源
-
- 4.1词汇列表语料库
- 4.2 停用词语料库
- 4.3 名字语料库
- 4.4 表格词典
- 4.5 词汇工具:Toolbox 和 Shoebox
- 5 Wordnet
- 6 练习
1获取文本语料库
1.1 古腾堡语料库
- NLTK包含古腾堡项目(Project Gutenberg)电子文档的一小部分文本。 该项目大约有25000(现在是36000)本免费电子书。
# 获得古腾堡语料库
import nltk
from nltk.corpus import gutenberg
gutenberg.fileids() # 获得古腾堡语料库的文本
emma = gutenberg.words('austen-emma.txt')
len(emma) # 告诉文本中词汇的个数
emma = nltk.Text(gutenberg.words('austen-emma.txt'))
emma.concordance("surprise") # 找出surprise出现最多的句子
- 平均词长=字符总数/词语总数
- 平均句长=词语总数/句子总数
- 平均词种数=词语总数/词种数
# 需要先下载“punkt”数据;
# 下载失败解决方案:https://blog.csdn.net/xiangduixuexi/article/details/108601873
import nltk
nltk.download('punkt')
# 下载是否成功的尝试,sents:是计算句子数量
macheth_sentences = nltk.corpus.gutenberg.sents("shakespeare-macbeth.txt")
macheth_sentences
# 平均词长特征值序列
fea1_li = []
# 平均句长特征值序列
fea2_li = []
# 平均词种数特征值序列
fea3_li = []
# 遍历每个作者所写的文本
for fileid in gutenberg.fileids():
# 统计字符数
num_chars = len(gutenberg.raw(fileid))
# 统计词语数
num_words = len(gutenberg.words(fileid))
# 统计句子数
num_sents = len(gutenberg.sents(fileid))
# 统计词种数
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)]))
# 特征1:计算平均词长
average_word_len = int(num_chars/num_words)
fea1_li.append(average_word_len)
# 特征2:计算平均句长
average_sent_len = int(num_words/num_sents)
fea2_li.append(average_sent_len)
# 特征3:计算平均词种数
average_word_category = int(num_words/num_vocab)
fea3_li.append(average_word_category)
1.2 网络和聊天文本
- NLTK的网络文本小集合的内容包括Firefox交流论坛,在纽约无意听到的对话,《加勒比海盗》的电影剧本,个人广告和葡萄酒的评论。
- 一个即时消息聊天会话语料库,最初由美国海军研究生院为研究自动检测互联网幼童虐待癖而收集的。语料库包含超过10,000张帖子,以“UserNNN”形式的通用名替换掉用户名,手工编辑消除任何其他身份信息,制作而成。语料库被分成15个文件,每个文件包含几百个按特定日期和特定年龄的聊天室(青少年、20岁、30岁、40岁、再加上一个通用的成年人聊天室)收集的帖子。文件名中包含日期、聊天室和帖子数量,例如: 10-19-20s_706posts.xml包含2006年10月19日从20多岁聊天室收集的706个帖子。
# Firefox交流论坛
from nltk.corpus import webtext
for fileid in webtext.fileids():
print(fileid, webtext.raw(fileid)[:65],'...')
# 即时消息聊天会话语料库
from nltk.corpus import nps_chat
chatroom = nps_chat.posts('10-19-20s_706posts.xml')
chatroom[123]
1.3 布朗语料库
布朗语意库是第一个百万词集的英语电子语料库,有布朗大学于1961年创建,包含500多个不同来源的文本,按照文本类型,如新闻、社评等分类。
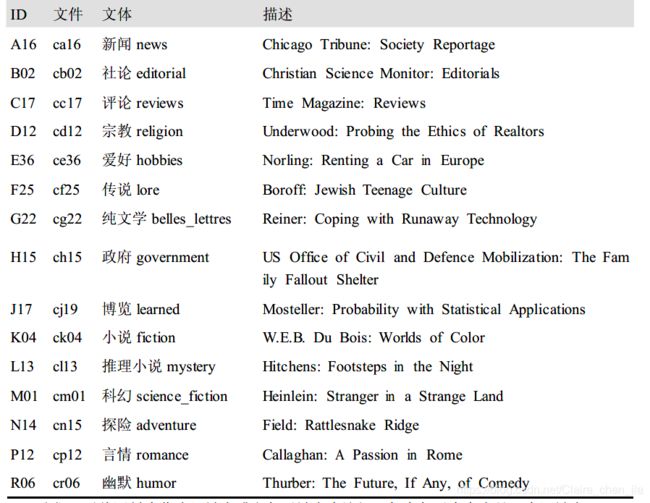
- 语料库基本操作
# 导入布朗语料库
from nltk.corpus import brown
#查看种类
print(brown.categories())
# 查看新闻类的文本
print(brown.words(categories="news"))
# cg22是纯文学文体的标号,查看纯文学文体
print(brown.words(fileids=["cg22"]))
# 查看"news","editorial","reviews"的文本,以列表形式返回
print(brown.sents(categories=["news","editorial","reviews"]) )
- 比较不同问文体中情态动词用法差异
"""
第一步:对特定文体进行计数。
"""
#导入模块
from nltk.book import *
from nltk.corpus import brown
# 获得新闻类和小说的文本
news_text=brown.words(categories="news")
fiction_text=brown.words(categories="fiction")
# 将文本转为小写的文本,再计算词汇的分布
fdist1=FreqDist([w.lower() for w in news_text])
fdist2=FreqDist([w.lower() for w in fiction_text])
# 比较两类词汇["can","could","may","might","must","will"]的用法差异
modals=["can","could","may","might","must","will"]
for m in modals:
print(m+" num in news_text:"+str(fdist1[m])+" freq:"+str(100*fdist1[m]/len(news_text)))
print(m+" num in fiction_text:"+str(fdist2[m])+" freq:"+str(100*fdist2[m]/len(fiction_text)))
"""
第二步:统计每一个感兴趣的文体。我们使用NLTK提供的条件概率分布函数。
"""
cfd=nltk.ConditionalFreqDist(
(genre,word)
for genre in brown.categories()
for word in brown.words(categories=genre))
genres=['news','religion','hobbies','science_fiction','romance','humor']
modals=['can','could','may','might','must','will']
cfd.tabulate(conditions=genres,samples=modals)
1.4 路透社语料库
- 路透社语料库包含10,788个新闻文档,共计130万字。
- 这些文档分成90个主题,按照“训练”和“测试”分为两组。因此,fileid为“test/14826”的文档属于测试组。
- 这样分割是为了训练和测试算法的,这种算法自动检测文档的主题,我们将在第6章中看到。
- 总结:包含的全是新闻文档,并按照测试和训练分组,可用来训练与测试算法。
- 语料库获取
# 导入模块
from nltk.corpus import reuters
# 获取文本
print(reuters.fileids())
# 获取文本分类
print(reuters.catergories())
- 语料库查询
由于路透社的新闻类别是有互相重叠部分,故接受查找含有一个或多个类别的文档,也可以查找一个或多个文档涉及到的类别。
print(reuters.categories('training/9865'))
print(reuters.categories(['training/9865','training/9880']))
print(reuters.fileids('barley'))
print( reuters.fileids(['barley','corn']))
- 查找句子
类似的,我们可以以文档或类别为单位查找我们想要的词或句子。这些文本中最开始的几个词是标题,按照惯例以大写字母存储。
print(reuters.words('training/9865')[:14])
print(reuters.words(categories=['barley','corn']))
print(reuters.words(['training/9865','training/9880']))
1.5 就职演说语料库
55个文本的集合,每个文本都是一个总统的演讲。这个集合的显著特征就是时间维度。
# 获取语料库
import nltk
from nltk.corpus import inaugural
print(inaugural.fileids())
# 每个文本的年代都出现在他的文件名中。要从文件名中提取出年代,只需要使用fileid[:4]即可。
for fileid in inaugural.fileids():
print(fileid[:4])
# 看看‘American’和‘citizen’随着时间推移的使用情况。
import nltk
from nltk.corpus import inaugural
cfd=nltk.ConditionalFreqDist((target,fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['american','citizen']
if w.lower().startswith(target) )
cfd.plot()

1.6 其他语料库
- 标注文本语料库:许多文本语料库都包含语言学标注,有词性标注,命名实体,句法结构,语义角色等。
- 世界人权宣言语料库:包含300种语言的世界人权宣言,其fileids包含所使用的编码,如utf-8或者Latin1编码
# 比较其中一种语言的前20字母分布频率
from nltk.corpus import udhr
raw_text=udhr.raw("English-Latin1")
print(FreqDist(raw_text))
FreqDist(raw_text).plot(20)

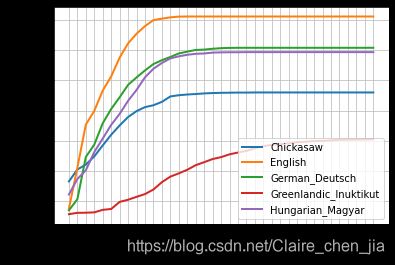
# 不同语言版本的字长差异
from nltk.corpus import udhr
lan = ['Chickasaw', 'English','German_Deutsch','Greenlandic_Inuktikut','Hungarian_Magyar']
cfd = nltk.ConditionalFreqDist((lang,len(word)) for lang in lan for word in udhr.words(lang + '-Latin1'))
# 绘制不同语言版本的字符长度分布
cfd.plot(cumulative=True)
# 看英语和Chickasaw中单词长度小于10个字符的词汇个数
cfd.tabulate(conditions=['Chickasaw', 'English'],samples=range(10),cumulative=True)

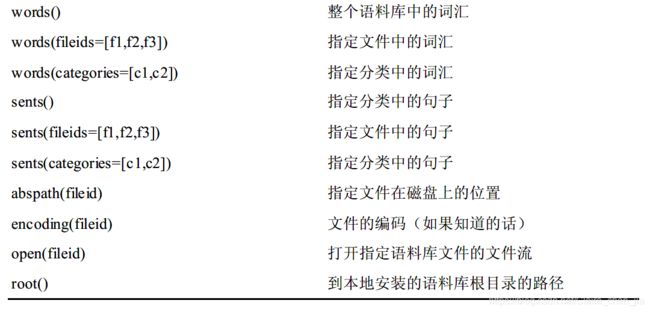
1.7 文本语料的结构
- 最简单的语料库结构是简单的文本集合。但是可以根据文本的文体、来源、作者、语言等属性对文本进行分类。
- NLTK语料库阅读器支持高效的访问大量语料库,并且能用于处理新的语料库。
- NLTK中定义了很多语料库函数。

"""
比较区别:
raw:原始文本
words:词汇
sents:句子
"""
raw = gutenberg.raw("burgess-busterbrown.txt")
print(raw[1:20])
words = gutenberg.words("burgess-busterbrown.txt")
print(words[1:20])
sents = gutenberg.sents("burgess-busterbrown.txt")
print(sents[1:20])
1.8 载入自己的语料库
在NLTK中,使用PlaintextCorpusReader\ BracketParseCorpusReader对象来载入自己的语料库或者文本集合
from nltk.corpus import PlaintextCorpusReader
corpus_root = '/usr/share/dict' # 自己的语料库路径
wordlists = PlaintextCorpusReader(corpus_root,'.*') # 载入自己的语料库
wordlists.fileids() # 列出语料库中的文本文件
from nltk.corpus import BracketParseCorpusReader
corpus_root = r"C:\corporalpenntreebank\parsed\mrglwsj" # 存放路径
file_pattern = r".*/wsj_.*\.mrg" # 文件匹配
ptb = BracketParseCorpusReader(corpus_root,file_pattern)
ptb.fileids()
ptb.sents(fileids='20/wsj_2013.mrg')[19]
2 条件频率分布
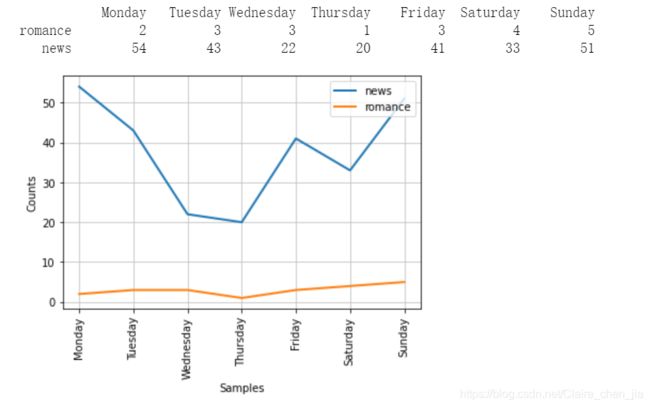
条件频率分布是频率分布的集合,每个频率分布有一个不同的“条件”。这个条件通常是文本的类别。图2-4描绘了–个带两个条件的条件频率分布
的片段,一个是新闻文本,一个是言情文本
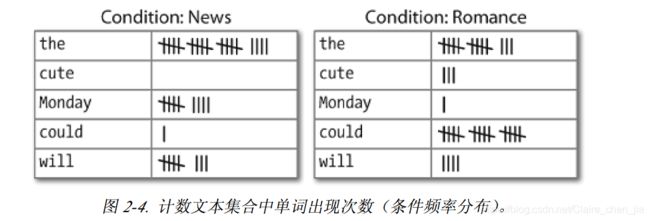
2.1 条件和事件
- 条件频率分布需要给每个事件关联一个条件,因此处理的不是一个词序列,而是一个配对序列。
- 也就是说,创建条件频率分布对象需要的是元组的列表,这个元组列表一般通过列表解析的方法来得到,形式为(条件,事件)。
2.2 按文体计数词汇
这里以文体计数词汇的应用来反映条件
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre,word)
for genre in brown.categories()
for word in brown.words(categories=genre)
)
cfd
genre_word = [
(genre,word)
for genre in ['news','romance']
for word in brown.words(categories=genre)
]
print(len(genre_word))
print(genre_word[:4]) # news 的文本的单词
print(genre_word[-4:]) #romance 的文本的单词
cfd = nltk.ConditionalFreqDist(genre_word)
cfd
# 访问cfd中的两个条件
cfd["news"]
cfd["romance"]
## 2.3绘制分布图和分布表
1. 条件频率分布对象含有一个plot方法来给内部的数据绘图,也含有一个tabulate方法给内部数据绘制表格。通过图和表格更容易表现出数据间的关系。
2. plot方法和tabulate方法都含有conditions参数和samples参数。conditions参数控制图和表格中条件的显示,而samples参数控制样本的显示。
3. 一个特别的地方就是,在创建条件频率分布对象时,传入的列表解析式可以不加方括号。
cdf=nltk.ConditionalFreqDist(
(target,file[:4])
for target in ['america','citizen']
for file in inaugural.fileids()
for w in inaugural.words(file)
if w.lower().startswith(target))
print(cdf["america"])
print(cdf["citizen"])
# 绘制表格
cdf.tabulate(samples=["1988","1989","1990"])
# 绘制累计分布的表格
cdf.tabulate(samples=["1988","1989","1990","2000","2001"],cumulative=True)
# 绘制分布图
cdf.plot(samples=["1988","1989","1990","2000","2001"],cumulative=True)

"""
处理布朗语料库的新闻和言情文体,找出一周中最有新闻价值并且是最浪漫的日子。
定义一个变量days 包含星期的链表如[‘Monday’, …]。然后使用cfd.tabulate(samples=days)为这些词的计数制表。
接下来用绘图替代制表尝试同样的事情。
你可以在额外的参数conditions=[‘Monday’, …]的帮助下控制星期输出的顺序。
"""
days=['Monday', 'Tuesday', 'Wednesday','Thursday', 'Friday', 'Saturday', 'Sunday']
cdf=nltk.ConditionalFreqDist(
(genre,word)
for genre in ['news','romance']
for word in brown.words(categories=genre))
cfd.tabulate(conditions=['romance','news'],samples=days)
cfd.plot(samples=days)
# 以一定比例取日子的新闻价值和浪漫性属性作为综合评价指标
import matplotlib.pyplot as plt
idays = [1,2,3,4,5,6,7]#代表星期一到星期日
lr = []
for rr in range(0,10,1):
r = rr/10 # 默认以0.1为步长
res =[(r)*cfd['news'][d]+(1-r)*cfd['romance'][d] for d in days ]#计算每一天的权重
# print(res)
plt.plot(idays, res)
lr.append(res.index(max(res)))
else:
print (lr)
plt.show()
2.4 使用双连词生成随机文本
- 思路是由于bigrams可以生成双连词配对(word1,word2)。
- 对一个文本使用bigrams得到这个文本所有双连词,并统计每个双连词的个数,其中以搭配中的word1作为条件,word2作为事件。
- 在文本生成模型中,num为生成文本的长度,word为起始词,选取双连词中以word为条件的所有搭配中频率最高的。如living后面跟着的{‘creature’: 7, ‘thing’: 4, ‘substance’: 2, ‘soul’: 1, ‘.’: 1, ‘,’: 1},creature频率最高,这样生成的文本中living后面就会跟creature。

from nltk import corpus
def generate_model(cfdist,word,num=10):
for i in range(num):
print(word)
word=cfdist[word].max()
text = corpus.genesis.words("english-kjv.txt")
bigrams = bigrams(text)
cfd=nltk.ConditionalFreqDist(bigrams)
print(cfd["living"])
generate_model(cfd,"living")
3 更多关于python:代码重用
- 使用文本编辑器创建程序
- 函数
- 模块
- 在一个文件中定义的变量和函数的集合称为python的一个模块。
- 相关模块的集合称为一个包,而包的集合称为库。
- 要注意的是文件命名最好不要重复,不然会被当前目录下的文件覆盖掉的。
4 词典资源
词典或者词典资源是一个词和/或短语及其相关信息的集合,例如:词性和词意定义等相关信息。词典资源附属于文本,而且通常在文本的基础上创建和丰富。
4.1词汇列表语料库
nltk中包括了一些仅仅包含词汇列表的语料库。词汇语料库是UNIX中的/usr/dict/words文件,被一些拼写检查程序所使用。我们可以用它来寻找文本语料中不常见的或拼写错误的词汇。
# 过滤异常词汇
def unusual_words(text):
text_vocab=set(w.lower() for w in text if w.isalpha())
english_vocab=set(w.lower() for w in nltk.corpus.words.words())
# print(text_vocab)
unusual=text_vocab.difference(english_vocab) # text_vocab.difference()
return sorted(unusual)
dif1=unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))
dif1[:20]
dif2=unusual_words(nltk.corpus.nps_chat.words())
dif2[:20]
# dict1.difference(dict2)表示dict1-dict2,即dict1中所有不属于dict2的词。
dict1 = {
'1','2','3'}
dict2 = {
'1','2','4'}
dict1.difference(dict2)
4.2 停用词语料库
该语料库包括的是高频词汇,如:the, to 和 and, 有时在进一步进行处理之前需要将他们从文档中过滤。停用词通常没有什么词汇内容,而它们的出现会使区分文本变得困难。
"""
nltk中的常用词库
"""
from nltk.corpus import stopwords
stopwords.words('english')
# 过滤停用词列表
def content_fraction(text):
stopwords=nltk.corpus.stopwords.words('english')
content=[w for w in text if w.lower() not in stopwords] # 过滤掉常用词
print (content[:50])
return len(content)/len(text)
content_fraction(nltk.corpus.reuters.words())
4.3 名字语料库
该语料库包括8000个按性别分类的名字。男性和女性的名字存储在单独的文件中。
# 找出同时出现在两个文件中的名字即分辨不出性别的名字
names=nltk.corpus.names
names.fileids()
male_name=names.words('male.txt')
female_name=names.words('female.txt')
[w for w in male_name if w in female_name]
# 研究男性和女性名字的结尾字母
cfd=nltk.ConditionalFreqDist(
(fileid, name[-1])
for fileid in names.fileids()
for name in names.words(fileid))
# 绘表
cfd.tabulate()
# 绘图
cfd.plot()

4.4 表格词典
表格(或电子表格)是一种略微丰富的词典资源,在每一行中含有一个词及其一些性质。nltk中包括美国英语的CMU发音词典。
# 发音的词典:CMU发音词典是为语音合成器而设计的。
entries=nltk.corpus.cmudict.entries()
len(entries)
# 对任意一个词,词典资源都有语音的代码——不同的声音有着不同的标签——称做音素。CMU发音词典中的符号是从Arpabet来的。
for entry in entries[39943:39951]:
print (entry)
# 比较词典:nltk中包含了所谓的斯瓦迪士核心词列表(Swadesh wordlists), 包括几种语言的约200个常用词的列表。
# 语言标识符使用ISO639双字母码。
from nltk.corpus import swadesh
# swadesh.fileids()获得的是语言的类别。
swadesh.fileids()
# swadesh.words()获得的是语言下的词列表。
swadesh.words('en') # 英语的常用词
# 法语和英语的词汇转换
fr2en=swadesh.entries(['fr', 'en'])
fr2en
# 构建法语与英语的转换器
translate=dict(fr2en)
translate['chien']
# 通过添加其他源语言,我们可以让我们这个简单的翻译器更为有用。
# 让我们使用dict()函数把德语-英语和西班牙语-英语对相互转换成一个词典,然后用这些添加的映射更新我们原来的翻译词典。
de2en=swadesh.entries(['de', 'en'])
es2en=swadesh.entries(['es', 'en'])
translate.update(dict(de2en))
translate.update(dict(es2en))
print(translate['Hund'])
print(translate['perro'])
print(translate['jeter'])
在这里插入代码片
4.5 词汇工具:Toolbox 和 Shoebox
- 目前最流行的语言学家用来管理数据的工具是Toolbox(工具箱),以前叫Shoebox(鞋柜)。
- Toolbox文件由一些条目的集合组成,其中每个条目由一个或者多个字段组成。
- 大多数字段都是可选是或者重复的,这意味着这个词汇资源不能作为一个表格或电子表格来处理。
# 条目包括一系列的属性-值对,如('ps','V'),表示词性是'V'(动词),('ge', 'gag')表示英文注释是'gag'。
# 最后的3个配对包含一个罗托卡特语例句和它的巴布亚皮钦语及英语翻译。
from nltk.corpus import toolbox
dic1=toolbox.entries('rotokas.dic')
dic1[:20]
"""
('kaa',
[('ps', 'V'),
('pt', 'A'),
('ge', 'gag'),
('tkp', 'nek i pas'),
('dcsv', 'true'),
('vx', '1'),
('sc', '???'),
('dt', '29/Oct/2005'),
('ex', 'Apoka ira kaaroi aioa-ia reoreopaoro.'),
('xp', 'Kaikai i pas long nek bilong Apoka bikos em i kaikai na toktok.'),
('xe', 'Apoka is gagging from food while talking.')])
"""
5 Wordnet
学习参考:
知识图谱之WordNet
python WordNet的使用方法(整理版)
- Wordnet 介绍
-
WordNet是普林斯顿大学认知科学实验室与计算机系联合开发的一个英语词库,收录了超过十万个实词。
-
在WordNet中,意义相近的单词组成一个同义词组(Synset),而同义词组之间则以上-下义,同义-反义,整体-部分以及蕴含等语义关系连接在一起,构成一个由同义词组作为结点,语义关系作为边的网状结构。
-
基本功能有如下网址可以学习:http://wordnetweb.princeton.edu/perl/webwn、http://www.nltk.org/howto/wordnet.html
- 安装与测试
# 安装
import nltk
nltk.download('wordnet')
# 测试
from nltk.corpus import wordnet as wn
print(wn.synsets('published')) # 打印publish的多个词义
dog = wn.synset('dog.n.01') # 狗的概念
print(dog.hypernyms()) # 狗的父类(上位词)
print(dog.hyponyms()) # 狗的子类(下位词)
- 主要功能介绍
# (1) 上位词/下位词
hypernyms() # 上位(父类)
hyponyms() # 下位(子类)
# (2) 同义词/反义词
lemma_names() # 同义
antonyms() # 反义
# (3) 蕴涵关系
entailments()
# (4) 整体与部位
part_meronyms() # 部分
substance_meronyms() # 实质
member_holonyms() # 成员
# (5) 计算概念之间距离
path_similarity() # 相似度
lowest_common_hypernyms() # 在何种层面相似
- 举例
# 导入包
from nltk.corpus import wordnet as wn
# 查询一个词所在的所有词集(synsets),如查找dog这个词有多少种意思
wn.synsets('dog') # [Synset('dog.n.01'), Synset('frump.n.01'), Synset('dog.n.03'),Synset('cad.n.01'),Synset('frank.n.02'), Synset('pawl.n.01'), Synset('andiron.n.01'), Synset('chase.v.01')]
# 查询一个词在一个同义词集中的定义
wn.synset('dog.n.01').definition()
# 查询一个词语在一所属词集的一个词义的例子
wn.synset('dog.n.01').examples()
# 查询词语某种词性所在的同义词集合,pos值可以为——NOUN,VERB,ADJ,ADV…
wn.synsets('dog',pos=wn.NOUN)
# 查询一个同义词集中的所有词,同义词
wn.synset('dog.n.01').lemma_names( )
# 输出词集和词的配对——词条(lemma)
wn.synset('dog.n.01').lemmas( )
# 利用词条查询反义词
good = wn.synset('good.a.01')
good.lemmas()[0] # Lemma('good.a.01.good')
good.lemmas()[0].antonyms() # [Lemma('bad.a.01.bad')]
# 查询两个词之间的语义相似度
dog = wn.synset('dog.n.01')
cat = wn.synset('cat.n.01')
dog.path_similarity(cat)
# 查询两个词之间的语义相似度
dog = wn.synset('dog.n.01')
cat = wn.synset('cat.n.01')
dog.path_similarity(cat)
# 查询一个词的整体与局部
print(wn.synset('tree.n.01').part_meronyms() ) # 部分
print(wn.synset('tree.n.01').substance_meronyms()) # 实质
print(wn.synset('tree.n.01').member_holonyms() )# 整体
for synset in wn.synsets('mint',wn.NOUN):
print( synset.name, ':',synset.definition)
"""
:
:
:
:
:
:
"""
# mint.n.04是mint.n.02的一部分,是组成mint.n.05的材质。
wn.synset('mint.n.04').part_holonyms() # [Synset('mint.n.02')]
wn.synset('mint.n.04').substance_holonyms() # [Synset('mint.n.05')]
# 蕴含的关系:走路蕴含着抬脚
wn.synset('walk.v.01').entailments()
# 在何种成面相似
right = wn.synset('right_whale.n.01')
orca = wn.synset('orca.n.01')
minke = wn.synset('minke_whale.n.01')
tortoise = wn.synset('tortoise.n.01')
novel = wn.synset('novel.n.01')
right.lowest_common_hypernyms(minke) # [Synset('baleen_whale.n.01')]
```python
# 可以通过查找每个同义词集深度量化这个一般性的概念
print(wn.synset('baleen_whale.n.01').min_depth()) # 14
print(wn.synset('right_whale.n.01').min_depth()) # 15
print(wn.synset('vertebrate.n.01').min_depth()) # 8
print(wn.synset('entity.n.01').min_depth()) # 0
6 练习
Python自然语言处理第二章习题
# 根据Strunk和White的《Elements of Style》,词howerer在开头使用是“in whatever way”或“to whatever extent”的意思,而没有“nevertheless”的意思。
# 正确用法的例子:However you advise him,he will probably do as he thinks best.使用词汇索引工具在各种文本中研究这个词的实际用法。
however=nltk.Text(gutenberg.words('austen-persuasion.txt'))
however.concordance("However")