汉英平行语料标注与分析Python
为什么要对汉英平行语料进行标注
现有大量的中英文语料需要切分成子句,人工切分费时费力。想通过机器学习,训练出一个模型来自动切分中英文语料。
解决方法:
1、中英语料分开,分别处理。
中英语料测试数据:数据是手动切分的,用来训练模型
例如在塞内加尔, |* 人口基金和人口和发展议员网络结成了战略性的伙伴关系。
He reported that after robust debate, |* the group had agreed on a number of amendments to the draft rules.
2、对语料分词,使用了python 中jieba包。
中英语料切分后的数据样式:
[‘例如’, ‘在’, ‘塞内加尔’, ‘,’, ‘|’, ‘*’, ‘人口’, ‘基金’, ‘和’, ‘人口’, ‘和’, ‘发展’, ‘议员’, ‘网络’, ‘结成’, ‘了’, ‘战略性’, ‘的’, ‘伙伴关系’]
[‘He’, ‘reported’, ‘that’, ‘after’, ‘robust’, ‘debate’, ‘,’, ‘|’, ‘*’, ‘the’, ‘group’, ‘had’, ‘agreed’, ‘on’, ‘a’, ‘number’, ‘of’, ‘amendments’, ‘to’, ‘the’, ‘draft’, ‘rules’, ‘.’]
3、打标签,串联词向量
本案例是用的是中英文词的一个维度为300的词向量。
中英三百维度的词向量样例:
的 -0.254230 -0.567097 -0.760745 0.387182 0.314964 0.388335 -0.013473 0.054860 0.103747 -0.430785 -0.048426 0.013260 0.067262 0.536135 -0.410416 0.011060 -0.376738 -0.136188 -0.595998 -0.691267 0.470151 -0.376128 -0.718711 0.412484 0.361128 -0.903709 -0.079028 0.229357 -0.305639 -0.147824 0.010847 0.524443 0.666182 0.154945 0.150673 -0.570325 0.096042 0.334632 -0.513343 -0.573375 0.328332 0.610434 0.178008 0.009032 -0.077070 -0.016572 0.195357 -0.122537 0.325543 -1.363964 0.443672 0.077969 0.584805 0.335752 0.119967 -0.170610 -0.520913 0.158421 -0.508672 -0.166721 0.181477 0.369602 0.523401 0.429872 0.173435 -0.312771 0.335903 0.518895 0.542752 0.419010 -0.245816 -0.128933 -0.195445 0.061597 0.695403 0.088074 0.121659 0.244421 -0.107125 -0.224489 0.319902 -0.228942 0.091792 0.341533 -0.351497 0.070126 -0.795452 1.147082 -0.576406 -0.443434 0.042094 -0.239812 -1.124892 0.267834 -0.602194 -0.519699 0.223323 0.013981 -0.000470 -0.076023 0.037136 -0.012691 0.015549 0.572485 -0.385890 0.080784 -0.097333 0.345313 -0.157934 -0.293646 -0.170700 0.176534 0.415452 0.163730 0.291591 -0.094499 0.419486 -0.376567 -0.024772 -0.595986 0.773194 0.391482 -0.071243 0.191064 -0.545650 0.091075 -0.336529 0.673306 -0.501969 -0.289221 0.177007 -0.037102 0.035434 0.513676 -0.597816 0.049086 0.049108 0.062951 -0.496376 0.352374 0.621980 0.570757 0.780539 0.565490 -0.330062 0.508579 0.152026 0.031733 -0.428875 0.344656 -0.037227 0.832538 0.074059 -0.525335 -0.268743 0.771322 -0.285225 -0.168556 0.253570 -0.198149 -0.609952 -0.095206 -0.548955 0.430851 0.456865 0.531679 0.217277 0.345369 -0.367018 -0.654313 0.778746 -0.017197 0.484232 -0.425492 -0.631148 -0.239337 -0.428860 0.275984 -0.378578 -0.142655 0.053201 -0.135373 0.551125 -0.352845 -0.454848 0.134624 -0.438403 0.148434 0.235269 0.978149 -0.022455 -0.067468 -0.672244 -0.907232 -0.201719 -0.300359 0.313614 -0.021673 -0.177402 0.260658 -0.318365 0.793563 -0.080414 0.388042 -0.434709 -0.123833 0.448992 0.140282 -0.181500 0.591642 0.434861 0.139838 -0.039862 -0.653306 0.463219 -0.191682 -0.129603 0.070453 -0.796369 0.082836 -0.210015 0.026230 -0.680434 -0.417512 0.000373 -0.126974 0.653641 0.140033 0.446051 0.626412 -0.079690 0.503048 -0.370356 0.180872 -0.466744 0.027738 -0.257809 -0.001753 0.490566 0.068581 -0.082726 0.109126 -0.366784 -0.698250 -0.401023 -0.131260 -0.419494 -0.009050 -0.585448 -0.270416 -0.229943 -1.045729 0.139306 -0.048815 0.623892 -0.876350 -0.002742 -0.329828 -0.357240 -0.294111 0.739936 -0.858966 -0.428089 -0.426555 0.055564 0.658721 0.054668 0.206946 -0.384711 0.273433 -0.259578 -0.829414 -0.242818 0.006366 0.214144 0.581732 -0.302534 -0.218684 -0.132700 -0.600512 -0.053248 0.530463 -0.289732 0.765354 0.637659 0.054150 -0.303837 0.570524 -0.595272 0.991729 0.451677 -0.389568 0.093150 0.095215 0.321639 0.473147 -0.184696 0.161738 0.434923 -0.133551
that 0.14805 0.10875 -0.036278 -0.15386 0.37181 0.293 -0.7026 0.00095636 0.24551 0.034012 0.034138 0.64364 -0.012599 0.024661 0.16286 0.077917 -0.31525 0.72081 -0.51842 -0.255 0.48959 3.1749 -0.37991 -0.03827 0.04576 0.06793 -0.11716 -0.3341 -0.10723 -0.23873 -0.4576 -0.024502 0.14723 -0.13546 0.089812 -0.38768 -0.95797 -0.62072 -0.11763 0.21322 0.080894 -0.25967 -0.093584 0.52106 -0.11793 0.21224 0.45115 -0.063134 -0.21954 -0.027564 0.01874 -0.35228 -0.23418 0.17759 0.19368 -0.20396 -0.11582 -0.19091 0.11507 0.13767 0.083718 0.17958 -0.22568 0.0061614 0.15113 -0.17524 -0.23794 0.21519 -0.087514 0.30629 0.41841 0.2913 -0.04346 0.204 -0.073017 0.38145 -0.14291 -0.17308 -0.3977 -0.2886 -0.028762 0.020877 -0.11252 0.31002 0.17208 0.11718 -0.72813 -0.27098 0.35079 -1.1096 0.71817 0.30775 0.53219 0.062995 -0.50855 0.41816 0.29686 0.062927 0.043386 -0.32052 0.14399 0.2765 -0.02649 0.077377 0.057718 -0.089084 0.06331 1.1641 -0.44109 -0.28368 0.26062 -0.48025 0.04018 -0.13092 0.42519 0.15305 -0.26543 -0.25001 -0.34873 0.13545 0.28868 0.56992 0.23826 0.29515 0.11743 -0.41814 0.35357 0.059823 0.37723 0.096062 -0.18146 0.19874 0.20747 -0.24454 0.31293 0.28901 0.079401 -0.28556 -0.031735 -0.043442 0.021977 0.25087 0.18158 -0.31774 1.6057 0.34543 -0.019671 -0.62405 0.17909 0.1502 -0.0012357 0.27507 -0.030791 0.38623 0.23872 -0.59215 -0.23935 0.338 0.19547 -0.1736 -0.22177 0.12624 0.13052 -0.16421 0.0092456 0.19234 -0.055088 0.1565 -0.28712 0.53327 0.45624 0.40083 0.36637 0.14608 -0.13729 -0.15897 -0.39163 0.094353 0.13397 0.095591 1.4247 -0.263 -0.15679 0.043102 -0.11161 0.11686 -0.32476 0.21426 0.44216 0.36477 0.10703 0.23798 -0.14344 0.27233 0.17654 -0.17613 0.05481 0.48022 -0.086013 -0.21791
4、打标签,串联词向量
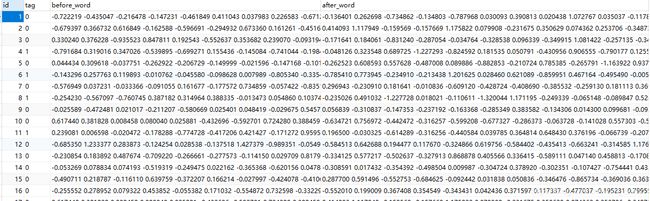
中英文打标签样例展示,并将词与对应的词向量串联,入库:
塞内加尔 人口 1
, well 1
as well 0
1-4 切分武库步骤代码
import jieba
from pymysql import *
class Making:
def __init__(self, path):
self.path = path
self.end_flag = [',', '。', '?', '!', '、', ';', '·', '?', '!', '.', '…']
self.def_vector = " ".join(["0" for i in range(1, 301)])
# 创建Connection连接
self.conn = connect(host='localhost', port=3306, database='corpus', user='root', password='123456', autocommit=True)
# 获得Cursor对象
self.cursor = self.conn.cursor(cursors.DictCursor)
# 查询词向量sql语句
self.sele_sql = 'SELECT vector FROM chinese WHERE word=%s'
# 标签入库sql语句
self.in_sql = 'INSERT INTO tag_zh(tag, before_word, after_word) VALUES (%s, %s, %s)'
def split_txt_zh(self):
with open(self.path, "r", encoding='utf-8') as f:
for line in f:
# 去除每行的换行符和无用的空格
line = "".join(line.strip().split(' '))
# 去除空行
if len(line) == 0:
continue
# 分词
terms = jieba.lcut(line)[:-1]
print(terms)
# 便利所有词
for index, term in enumerate(terms):
# 找到可能切分的位置
if (term in self.end_flag) and index < len(terms) - 2:
# *| 切分
if terms[index + 1] == '*' and terms[index + 2] == '|':
before_word = terms[index - 1]
after_word = terms[index + 3]
flag = 1
# 打标签入库
self.test_sql(before_word, after_word, flag)
elif terms[index + 1] == '|':
# |* 切分
if terms[index + 2] == '*':
before_word = terms[index - 1]
after_word = terms[index + 3]
flag = 1
# 打标签入库
self.test_sql(before_word, after_word, flag)
continue
# | 切分
before_word = terms[index - 1]
after_word = terms[index + 2]
flag = 1
# 打标签入库
self.test_sql(before_word, after_word, flag)
# 不切分
else:
before_word = terms[index - 1]
after_word = terms[index + 1]
flag = 0
# 打标签入库
self.test_sql(before_word, after_word, flag)
def test_sql(self, before_word, after_word, flag):
global before_vector, after_vector
# 查询标点前一个词
before = self.cursor.execute(self.sele_sql, before_word)
# 语料中是否存在,不存在为0向量
if before == 0:
before_vector = self.def_vector
for i in range(before):
# 获取查询的结果(字典)
result = self.cursor.fetchone()
before_vector = result['vector']
# 标点后一个词
after = self.cursor.execute(self.sele_sql, after_word)
if after == 0:
after_vector = self.def_vector
for i in range(after):
# 获取查询的结果
result = self.cursor.fetchone()
after_vector = result['vector']
self.cursor.execute(self.in_sql, (flag, before_vector, after_vector))
def run(self):
# 1. 分词
# 2. 找标点,取词
# 3. 打标签
# 4. 从库中取对应词的词向量,并标签入库
self.split_txt_zh()
if __name__ == '__main__':
tag = Making("ChineseContent.txt")
tag.run()
5、用分类器进行训练模型,使用sklearn包
import numpy as np
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV, train_test_split
def load_data(filename):
data = np.genfromtxt(filename, delimiter=',')
x = data[:, 1:] # 数据特征
y = data[:, 0].astype(int) # 标签
scaler = StandardScaler()
x_std = scaler.fit_transform(x) # 标准化
# 将数据划分为训练集和测试集,test_size=.3表示30%的测试集
x_train, x_test, y_train, y_test = train_test_split(x_std, y, test_size=.3)
return x_train, x_test, y_train, y_test
def svm_c(x_train, x_test, y_train, y_test):
# rbf核函数,设置数据权重
svc = SVC(kernel='rbf', class_weight='balanced',)
c_range = np.logspace(-5, 15, 11, base=2)
gamma_range = np.logspace(-9, 3, 13, base=2)
# 网格搜索交叉验证的参数范围,cv=3,3折交叉
param_grid = [{
'kernel': ['rbf'], 'C': c_range, 'gamma': gamma_range}]
grid = GridSearchCV(svc, param_grid, cv=3, n_jobs=-1)
# 训练模型
clf = grid.fit(x_train, y_train)
# 计算测试集精度
score = grid.score(x_test, y_test)
print('精度为%s' % score)
if __name__ == '__main__':
svm_c(*load_data('file.csv'))
数据分析
中文切分位置前一个词的词云

中文切分位置后一个词的词云

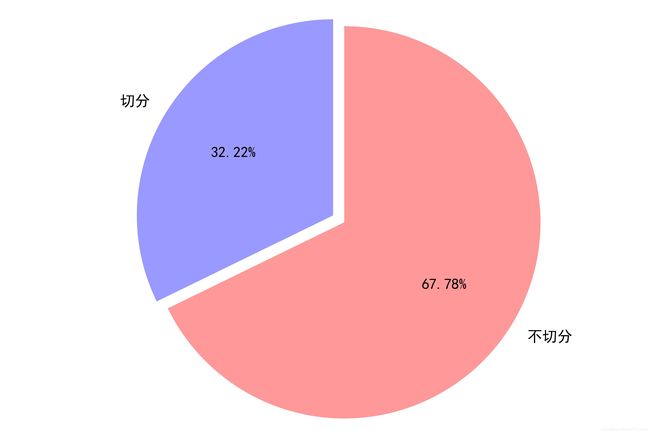
中文语料遇到标点切分饼状图
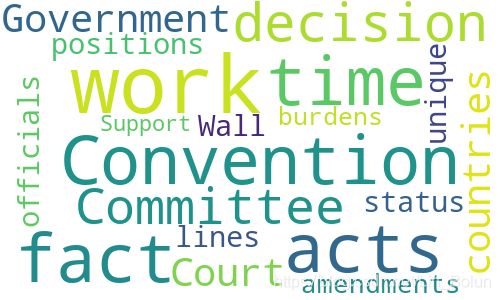
英文切分位置前一个词的词云
英文切分位置后一个词的词云