【语音识别学习】未分词的2-gram语言模型统计Python实现(含源码)
一、概述
对于语音识别来说,大体上就分为三个方面,一个是声学模型(acoustical model)的训练,一个是语言模型(language model)的训练,最后就是对给定一段语音的解码了,当然,咱们今天讨论的是第二部分,其他的就先丢到一边吧!(在这给大家打一打气,其实语言模型是这三个方面里最复杂的部分了,这部分搞懂之后,其他的也就so easy啦)
现如今,无论是从流行程度还是经典程度来说,n-gram模型都可以说排在前面,而且思想也比较好理解,比较适合入门,这篇博文和之后的代码实现也都是基于此。
二、n-gram语言模型
话不多说,先来简要介绍一下n-gram语言模型吧。
n-gram的作用
先说一说它的作用,语音识别,就是要把一串连续的语音转变为一个合理的句子,那么很容易想到的就可以分为两个步骤,先根据语音中的帧识别出音素,如果对于中文的话就是拼音,然后再根据拼音转化为语义正确的汉字,那么前一部分比较好理解,就找到大量的语音,然后标注好每个语音中所具有的拼音,常规的机器学习的思想,当然这也是有特定的模型的,最经典的就是hmm-gmm模型,当然还有各种各样的神经网络模型,感兴趣的同学可以去查看,但关键是,就算你成功识别出了拼音,但也没有音调,有的就是类似wo ni ta这样形式的拼音,如何把它组合成我们日常生活中的句子呢?
n-gram的原理
这就要用到我们的语言模型了,假定S表示一个有意义的句子,它由一串特定顺序排列的词(w1,w2,…,wm)组成,m表示句子的长度,即单词个数。计算S在整个语料库中出现的可能性P(s),或表示成P(w1,w2,…,wm),可根据链式法则分解为:
![]()
其中P(w2|w1)就表示当w1出现了,w2再出现的概率,P(w3|w1w2)就表示当w1w2同时出现了,w3再在他们之后出现的概率,之后的以此类推,这就是最原始的n-gram模型,但这个概率是不好算的,你要一直统计前m-1个字出现了,Wm出现的概率。
由此就出现了诸如1-gram、2-gram模型,聪明的你应该可以想到了,对于1-gram模型,其计算公式就是:

2-gram模型计算公式就是:

这些说起来是个模型,但其实就是一个很简单的统计概率问题,最重要的部分还是对数据的爬取以及对其进行解码的优化。虽然解码思路也很简单,但如果直接暴力解码的话是一个NLP问题,所以要寻找合适的方法解决,关于数据的爬取,如果有同学没有什么思路的话可以关注我之后的博文,会专门讲解一个简单使用的每日百万级数据的Python程序。
三、python代码实现过程详解
接下来,就开始上干货了,我会大致讲解一下我这一部分的实现思路,然后在最后附上我的python源码,需要的同学可以下载下去再研究。
首先,咱们大体把你要实现的东西梳理一下。
- 统计数据库中相邻两个汉字各种情况出现的次数
- 用上述统计出来的结果生成2-gram模型,也就是将频数转换为频率
- 如果需要进行平滑处理的话,还需要编写平滑处理的代码
- 最后,完成2-gram模型统计后,为了验证成果,写一个小的demo,这个demo就类似于一个简单的输入法。
OK,理清了这四件我们要完成的事情之后,让我们分别来干掉他们。
统计数据库中相邻汉字的频数
首先,对于第一个任务,要统计数据库中的相邻汉字的频数,这其实还是很好实现的,前提是你选择了合适的数据库。在这次的程序中我选择了MongoDB存储我爬虫爬取到的文本数据,遍历这些数据很容易,就和Python中字典的使用方法差不多,而对于取到文本之后的工作,就不用我说了吧,就是对字符串的操作。
比如"今天天气真好啊"这句话,你需要做的就是分别统计"今天"、“天天”、"天气"等等,再继续下去,好像有点问题哈,"气真"不是个词的样子,但没关系,这是在分词之前的一个实现,自然就没有考虑词的问题,之后加入了分词之后,这个问题就不在存在了,或者说就减少了。然后将这样统计的结果存入一个字典类似的东西,然后再最后写入磁盘就OK啦
下面贴出我实现的部分代码:
twoGram_improve/run.py(其中用于统计的部分)
def statistics():
"""
用于统计数据库中相邻两词出现次数,并存入字典
:return: 具有所有字词统计次数的字典
"""
result = {
}
count = 0
for content in table.find().batch_size(500):
content = content['content'].strip()
count += 1
i = 0
for i in range(len(content)-2):
if is_Chinese(content[i]) and is_Chinese(content[i+1]):
pText = '{0}{1}'.format(content[i], content[i + 1])
if pText in result:
result[pText] += 1
else:
result[pText] = 1
print('统计完成数据: {0}'.format(count))
# print('完成统计: {0}.'.format(content))
return result
twoGram_improve/run.py(其中用于写入磁盘的部分)
def write_to_file(filename, result):
with open(filename, 'w') as fw:
for key, value in result.items():
fw.write('\'{0}\'在数据库中出现的次数为: {1}\n'.format(key, value))
fw.close()
平滑操作
关于平滑操作的原理,我在这里就不过多赘述了,但我之前总结过一片博文,大致讲述了一下平滑操作的目的和原理,可以参考【总结】几个简单语言模型平滑方法,这里只给出一个极为简单的Laplace平滑变换(其实就是加1)。
twoGram_improve\utils\Smooth.py(Laplace平滑部分)
def Laplace(filename):
pattern = re.compile(r'(.*?)\.txt')
forename = re.search(pattern, filename)
if forename:
forename = forename.group(1)
newfilename = forename + '-Laplace.txt'
fw = open(newfilename, 'w')
with open(filename, 'r') as fr:
pattern = re.compile(': (\d+)')
patternWord = re.compile('(.*?)\d+')
for line in fr.readlines():
perNum = re.search(pattern, line)
perWord = re.search(patternWord, line)
if perNum and perWord:
perNum = int(perNum.group(1)) + 1
perWord = str(perWord.group(1))
fw.write(perWord + str(perNum) + '\n')
fr.close()
fw.close()
根据统计结果生成2-gram模型
现在到了重点,终于要生成模型了,既然都已经了解原理了,这部分的工作也就显得没有那么复杂了,其实就是要把频数转换为频率存储起来,那么首先要做的就是计算总数喽!
twoGram_improve\generateTwoGram.py
def get_all():
with open(r_filename, 'r') as fr:
pattern = re.compile(r': (\d+)')
num = 0
for line in fr.readlines():
perNum = re.search(pattern, line)
if perNum:
perNum = int(perNum.group(1))
num += perNum
return num
然后就是生成频率,其实就是把之前统计频数的文件读入,然后再将他们除以总数存入即可。
twoGram_improve\generateTwoGram.py
def get_frequency(all):
"""
获取2-gram
:param all: 总字数
:return: None
"""
fw = open(w_filename, 'w')
with open(r_filename, 'r') as fr:
patternNum = re.compile(r': (\d+)')
patternWord = re.compile(r'\'([\u4e00-\u9fa5]+)\'')
for line in fr.readlines():
perNum = re.search(patternNum, line)
perWord = re.search(patternWord, line)
if perNum and perWord:
perNum = int(perNum.group(1))/all
perWord = perWord.group(1)
fw.write('P({0}|{1}) = {2}\n'.format(perWord[1], perWord[0], perNum))
fr.close()
fw.close()
验证加demo
截至到现在,我们的2-gram未分词的语言模型就建立完成了,是不是感觉很简单?但前面我只说那是重点,并没有说是难点,难点其实在解码部分呢!
我们试想一下,当我给你一句话的拼音的时候,你要怎么根据2-gram模型来生成一句完整的汉字呢?肯定是先匹配第一个拼音,看看其对应的汉字是哪些,然后看第二个拼音,找到第二个拼音对应的所有汉字,对其两两计算概率,然后对之后的每一个拼音也要重复的进行这个过程,并且把其概率乘起来,得到最终的所有可能情况的概率,再比较大小,把概率最大的那一个输出,对不对?用图来描述的话就是下面这个样子。
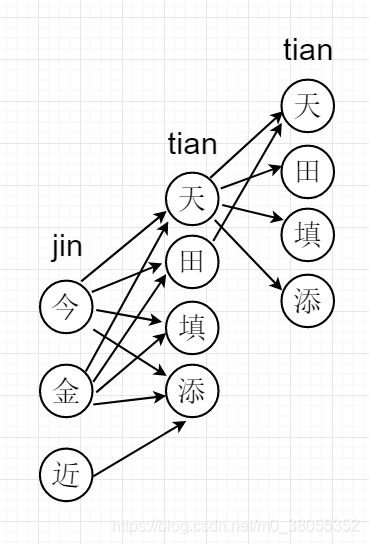
这只是一个示意图,那么假设每一列有20个字的话,如果你输入了10个拼音,那么需要计算的次数就是20的10次方!这是一般的计算机远远承受不了的,其实这就是一个NLP问题,靠穷举是完成不了的。
在这里我参考了微软输入法的方法,一种类似动态规划的思想,就是每次就计算20*20,也就是当前两个字的概率,对于以上图示过程来说,就是,首先计算"jin"和"tian"的各个汉字组合概率,假设jin对应20个汉字,然后对于"tian"中的每一个汉字,会计算出20个概率,取其中最大的一个,存入一个实现给定的数组中,然后接着计算"tian"和"tian",用同样的方法计算,这样,多利用了一个二维数组,就将一个n×n×n×n…的问题,变成了n×n+n×n+n×n的问题,大大减少了问题的复杂度。
twoGram_improve\demo\run.py
def function_p(dict, result):
while True:
pinyin = str(input('请输入拼音: '))
if pinyin == 'exit':
break
li = split_word(pinyin) # 将各个拼音分开
M = 0 # 词表的列数 每个拼音可能出现的最多汉字数
T = len(li) # 词表的行数 即拼音的个数
table = [] # 词表
for item in li: # 求得词表 以及词表的 M 参数
pattern = re.compile('\n' + str(item) + '=([\u4e00-\u9fa5]+)')
characters = re.search(pattern, result)
if characters:
characters = characters.group(1)
if len(characters) > M:
M = len(characters)
table.append(characters)
prob = [[-1000000 for i in range(M)] for i in range(T)] # 存储此时对应的最大概率
ptr = [[0 for i in range(M)] for i in range(T)] # 存储最大概率的路径
if not table: # 如果输入的不是合法的拼音或没输入则返回重新输入
continue
for j in range(len(table[0])): # 将第一个拼音初始化
ptr[0][j] = j
prob[0][j] = 0
for i in range(1, T): # 对于每一个拼音 也就是词表的每一行
for j in range(0, len(table[i])): # 对于当前行的每一个汉字
maxP = -1000000
idx = 0
for k in range(0, len(table[i - 1])): # 遍历当前拼音的前一个拼音对应的所有汉字
if table[i - 1][k] + table[i][j] not in dict: # 若在统计的词典中不存在 则加入
dict[table[i - 1][k] + table[i][j]] = -16.57585272128594
thisP = prob[i - 1][k] + dict[table[i - 1][k] + table[i][j]]
if thisP > maxP:
maxP = thisP
idx = k
prob[i][j] = maxP
ptr[i][j] = idx
# 获取最后一行最大值的索引
maxP = max(prob[T - 1])
idx = prob[T - 1].index(maxP)
# 输出结果
i = T - 1
string = ''
while i >= 0:
string += table[i][idx]
idx = ptr[i][idx]
i -= 1
# 字符串逆序输出
print(string[::-1])
到这里,全部的功能我们就都实现了,当然以上我只贴了部分代码,展现了基本的处理思路,如果想要更加详细的了解并且学习的话,可以去我的github上下载查阅。
下面附上我的源代码链接:
https://github.com/AndroidStudio2017/TwoGram
如有叙述有误,欢迎指正!
在之后我也会再更新一篇关于爬虫分享的博文和一篇分词之后2-gram的博文,有兴趣的小伙伴可以关注一下orz