YOLOv1-详解
YOLOv1-详解
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
目录
前言
(一)算法原理
(二)主干网络
(三)网络训练
(四)损失函数
(五)网络预测
(六)优缺点
前言
写这篇博客是为了以后再看到yolo时有个参考,同时供各位交流学习,水平有限,欢迎各位交流学习,批评指正。
在正文开始之前,先附上我在学习过程中的参考资料,感谢各位博主学者分享。
参考资料:
1. yolov1论文翻译1:https://blog.csdn.net/shuiyixin/article/details/82533849
2. yolov1论文翻译2:https://blog.csdn.net/m0_37192554/article/details/81092761
3. yolov1论文笔记1:https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social
4. yolov1论文笔记2:https://zhuanlan.zhihu.com/p/94986199
5. 什么是mAP:https://blog.csdn.net/shuiyixin/article/details/86349643
6. 分类与回归:https://blog.csdn.net/shuiyixin/article/details/88816416
7. tf_yolov3代码解析:https://blog.csdn.net/sxlsxl119/article/details/103028005
8. 入门级yolo教程:https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
(一)算法原理
假设我们处理的图片是一张正方形图片,yolo将图片分割为SxS个grid(网格),每个网格大小相等,如下图所示:

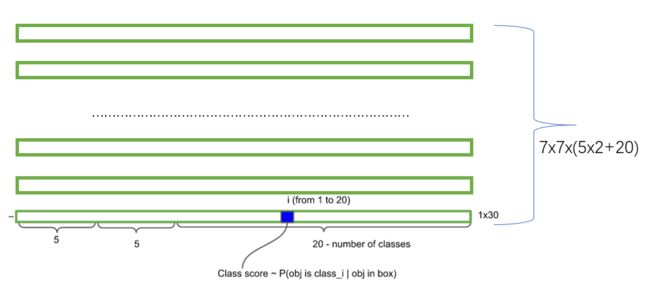
每个网格预测B个bounding boxs,每个bbox包含5个量(x, y, w, h, confidence),其中,x,y表示bbox的坐标,w和h为bbox的宽和高,confidence表示这个bbox含有目标的概率及坐标预测的准确率;另外,每个网格还需要预测该网格中物体的类别,这里物体类别用one-hot编码表示。因此,整个ground truth的长度为:SxSx(Bx5+C)。在yolov1中,将图片分为7x7的网格,每个网格预测2个bboxs,共98个bboxs。更直观详细的关于bbox的解释如图所示(https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social):

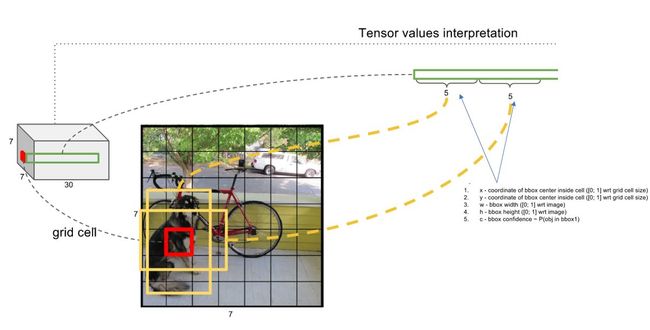

这里对bbox的细节做一个说明:每个bbox输出4个关于位置的值:x,y,w,h, 我们在处理输入的图片的时候想让图片的大小任意,这一点对于卷积神经网络来说不算太难,但是,如果输出的位置坐标是一个任意的正实数,模型很可能在大小不同的物体上泛化能力有很大的差异。因此,对bbox的坐标进行归一化处理,对于x和y而言,x和y是预测的bbox的中心位置,使相对于对应网格归一化到0-1之间;对于w和h,因为一个物体很可能远大于grid的大小,预测物体的高和宽很可能大于bounding boxs的高和宽,这样w除以bounding boxs的宽度,h除以bounding boxs的高度依旧不在0和1之间,解决办法是用图像的width和height归一化到0-1之间。
每个网格预测的两个bbox是怎么得到的:在训练开始时作为超参数输入bbox的信息,随着训练次数增加,loss降低,bbox越来越准确(某个帖子评论区看到的,不确定是否准确)。
关于“Object的中心落在哪个网格,就由哪个网格检测这个object”的理解:在训练过程中,假设Object的中心落在网格1中,网格1产生两个bboxs,哪个bbox与该Object的ground truth(即训练集中该Object的人工标注框)的IOU大,就选取这个bbox来检测Object,也就是,把该网格预测的这个bbox作为predict box,和ground truth做运算得到loss。随着训练过程不断反馈,loss降低,网格预测的bbox越来越准确(越来越接近ground truth),最终得到一个精准的检测模型。
(二)主干网络

网络结构借鉴了 GoogLeNet 。24个卷积层,2个全连接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
卷积层用于提取图像特征,全连接层用于预测图像位置和类别概率。
(三)网络训练
预训练分类网络:将前20 个卷积层,加上1个平均池化层和1个全连接层作为预训练网络,采用imagenet数据集分辨率为224x224的图像进行预训练。
训练检测网络:《Object detection networks on convolutional feature maps》提到说在预训练网络中增加卷积和全链接层可以改善性能。将预训练网络的前20个卷积层应用到检测中,加入剩下的4个卷积层和2个全连接层,随机初始化权重。为了得到更精细化的视觉信息,将分辨率增加为448x448。
在最后一层预测类别概率和边界框坐标。将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。Leaky RELU可以解决RELU的梯度消失问题。
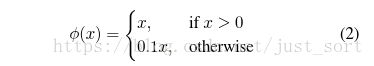
为减轻过拟合,采用dropout和数据增强方法,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层,采用随机缩放和translations方法使原始图像变换到20%大小,在hsv颜色空间以因子1.5随机调整曝光率和饱和度。
dropout:
参考:https://blog.csdn.net/hjimce/article/details/50413257
https://blog.csdn.net/program_developer/article/details/80737724
dropout来源于2012年的文章《Improving neural networks by preventing co-adaptation of feature detectors》
后又有多篇文章提到dropout:《ImageNet Classification with Deep Convolutional Neural Networks》、《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》
其原理是:在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。简单来说就是:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
(四)损失函数
这部分来源:https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social

关于损失函数的一些说明:损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。简单的全部采用了sum-squared error loss来做这件事会有以下不足: a) 8维的localization error和20维的classification error同等重要显然是不合理的; b) 如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。 解决方案如下:
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight,在pascal VOC训练中取5。(上图蓝色框)
- 对没有object的bbox的confidence loss,赋予小的loss weight,在pascal VOC训练中取0.5。(上图橙色框)
- 有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
-
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。
(五)网络预测
参考:https://www.jianshu.com/p/d535a3825905?from=timeline&isappinstalled=0
由于输出层为全连接层,运用训练好的yolo模型进行测试时,只支持与训练图像分辨率大小相同的图像作为输入。
基于网格的目标检测方法存在一个问题:训练过的CNN遇到新的测试图像时,通常会生成多个网格单元向量,这些向量都尝试检测相同的对象,这意味着有很多输出向量全都包含同一对象的不同的边界框。通俗来讲:自己标注样本的时候,一个物体只标一次,并只指定一个具体的cell(训练过程就是这样训练的)。但是当你预测的时候,并不是只有一个cell预测这个物体。是一堆cell预测这个问题,画出来很多框,因此需要nms选出来最好的框。即针对每一类别,采用nms方法去除重复检测的边界框。
nms算法主要解决的是一个目标被多次检测的问题,意义主要在于把一个区域里交叠的很多框选一个最优。
(六)优缺点
yolov1的优点:
- 速度快,能够达到实时的要求。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。
yolo的不足:
-
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
-
测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
-
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。