数据转换 :str、int、float、tuple、list,dict
1. List 列表
支持字符、数字、字符串包含在列表中,用[ ]标识,是有序对象 ,索引从0开始,有append(),extend()、insert()等方法,可以切片
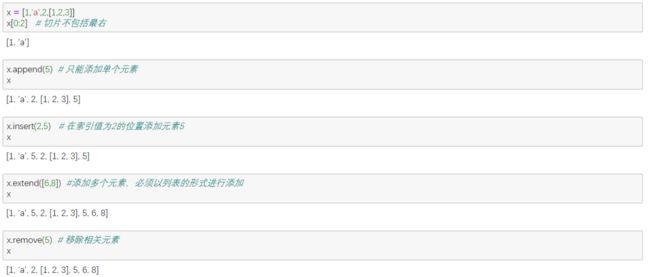
2. Tuple 元组
用()标识,不能二次赋值,可认为是不可变的列表,有序对象,可以切片
 3. dict 字典
3. dict 字典
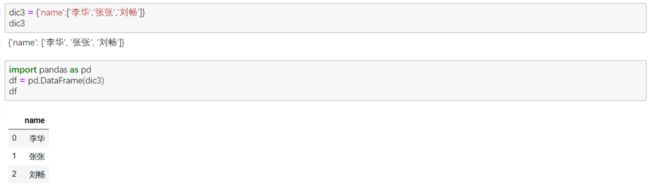
由键和值组成,用{}标识,可以利用键对值进行索引

① 字典的索引使用相关的键
![]()
② 字典和列表结合(在pandas中经常使用)

③ key是不可变的,但values是可变的(可以以列表的形式存在),即可以为列表,参考pandas
④ 字典的常用操作 update、in not in(只针对key)


⑤ 字典的其他知识点
字典的元素访问只能使用键,而不是使用索引,因为字典是无序的
对于嵌套字典,输出嵌套内容,通过重复指向来输出
.get(key)方法:直接查看key的value,如果没有相应key则返回None,添加print参数可以多返回一个值
.keys()方法:输出字典所有key,注意这里的输出内容格式是视图,可以用list()得到key的列表,类似range()
.values()方法:输出字典所有values,原理同.keys()方法
.items()方法:输出字典所有items(元素),原理同.keys()方法
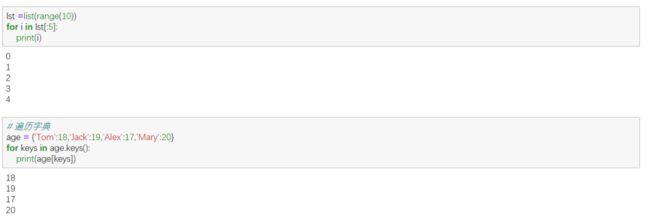
⑥ 字典的遍历(使用keys、values、items)

4. 字符串
① 字符串引号
'' "" ''' ''' 三种引号灵活使用,前两种用在字符串中,三引号用来直接换行
② 转义字符 \
注:"/"左倾斜是正斜杠,"\"右倾斜是反斜杠,可以记为:除号是正斜杠一般来说对于目录分隔符,Windows用反斜杠

③ 字符串常用功能:replace 、split、join、stipestartswith、endswith等



st = 'aBDEAjc kLM'print(st.upper()) # 全部大写print(st.lower()) # 全部小写print(st.swapcase()) # 大小写互换print(st.capitalize()) # 首字母大写st = '1234567'print(st.isnumeric()) # 如果 string 只包含数字则返回 True,否则返回 False.st = 'DNVAK'print(st.isalpha()) # 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 Falsest = 'avd 'print(st.strip()) # 删除字符末尾的空格
④ 格式化字符串
%i为整型,%s为字符串型,%f为浮点型




最强大的格式化,也是使用最多的就是format

二. 变量、运算符与序列
1. 变量
用 = 连接 ,=左边为变量名,=代表赋值,=右边代表对给变量赋的值
变量首字符必须是字母或者下划线_ ,不能是数字
可以进行多变量赋值和动态赋值

2. 运算符
算术运算符 + - * / % ** // >= <= ==

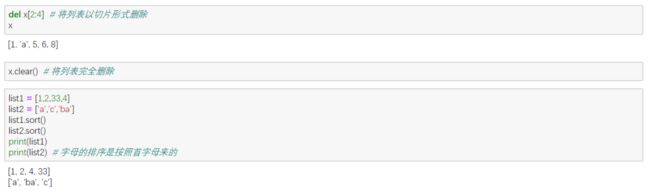
3. 序列
可变序列:列表List
不可变序列:元组tuple,字符串str
*生成器 range
① 判断元素是否在序列中 in 、not in
② 序列相加与相乘

③ 下标索引,从0开始,从最右边开始索引的话,是从-1开始
④ 切片 通过索引范围取得,左闭右开,最右端索引无法取得,使用[:]可以全部取得
⑤ 步长
![]()
⑥ 序列的内置全局函数 len()、 max()、 min()、 sum()、 index()、count()
⑦ 生成器 range() 依然是左闭右开,不包含右边元素,可以使用步长
三. 语句
最基本的语句:赋值语句
同样比较基本的语句:运行函数/方法
条件语句:if
循环语句:for/while循环,循环遍历序列/字典等
函数语句:def
模块语句: import
1. 条件语句 if
① 基本条件判断

② 多重条件判断

2. 循环语句 for while
① for 语句


② while语句
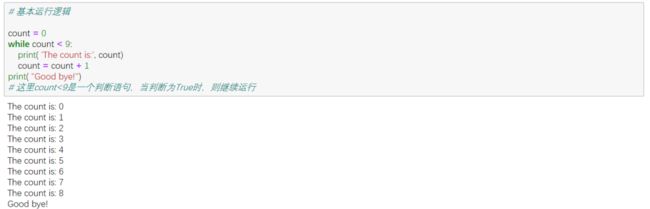
③ 循环控制语句
break:在语句块执行过程中终止循环,并且跳出整个循环
continue:在语句块执行过程中跳出该次循环,执行下一次循环
pass:pass是空语句,是为了保持程序结构的完整性
函数组成
函数名称
函数参数
函数内的算法,内置函数可以通过help()查看,自定义函数自己定义算法
1. 常用内置函数
- abs
- sorted
- max
- min
- sum
- len
- divmod(a,b) →获取商和余数 divmod(5,2) >>(2,1)
- pow(a,b) 获取乘方数。pow(2,3)>>>8
- round(a,b) 获取指定位数的小数 round(3.1415,2)→3.14
- range()
2. 常用类型转换函数
- int()
- float()
- str()
- bool()
- list()
- iter()
- dict()
- enumerate() 返回枚举对象
- tuple()
- set() 集合{}
- hex() 转换为16进制的
- oct() 转换为8进制的
- bin() 转换为2进制的
- chr() 转换为相应ASCI码
- ord() 转换ASCI字符为相应的数字
3. 相关操作函数
- eval():执行一个表达式,或字符串作为运算。eval('1'+'1')>>>2
- exec():执行python语句
- type():返回一个对象的类型
- id():返回一个对象的唯一标识符
- help():调用系统内置的帮助系统
- global():返回当前全局变量的字典
- reversed(sequence):返回一个反转序列的迭代器。reversed('a','c','b')>>>['b','c','a']
4. 自定义函数
def 定义函数
return 赋予该函数的返回值
在调用时常常对其进赋值
① 局部变量与全局变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中
global语句 → 把局部变量变为全局变量
② 定义一个函数,可统计出输入任意的字符中英文字母、空格、数字和其它字符的个数
st.isalpha() 判断字母
st.isspace() 判断空格
st.isdigit() 判断数字
5. 匿名函数
格式:f = lambda a,b,c:a+b+c
f(1,2,3)>>>6

五. 模块与包
模块类似于通过不同的代码功能,组合成一个脚本文件,变成一个可重复利用的独立功能模块,可以封装调用
1. 模块路径问题
import pandas
print(pandas.__file__)
# 查看现有包所在路径,将自己创建的包存入该路径
import sys
sys.path.append('C:/Users/Hjx/Desktop/')
# 加载sys包,把自己创建的包的所在路径添加上
2. 模块调用方式
- import pandas
- From pandas import DataFrame
- import pandas as pd
3. 常用模块 random、time
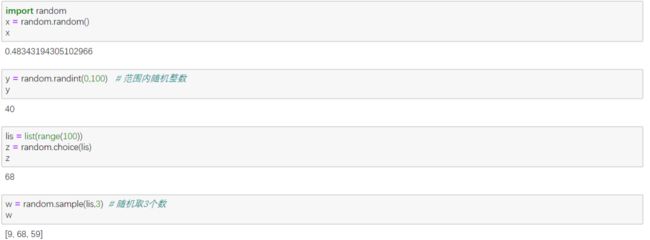
① import random
常用:random()、randit()、choice()、sample()、shuffle()
![]()
② import time
常用:sleep()、ctime()
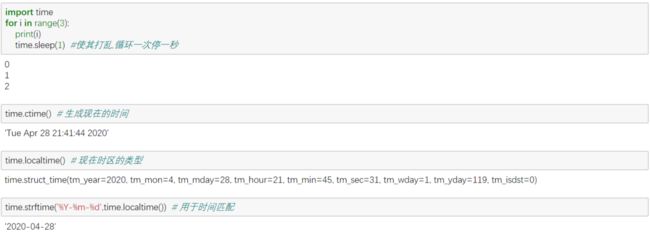
注:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
包都可以通过pip进行下载安装
- pip list查看当前安装好的包
六. 文件
1. 文件路径
使用/ 或者 \\ \或者r'',不是可以直接从电脑文件路径中粘贴过来的

2. 打开文件 open()
f = open(r'C:\Users\Desktop\hello.txt',encoding='utf-8')f.read()print('读取完毕')# open('路径', '模式', enconding = '编码' )# 模式:r:读取文件,默认;w:写入;rw:读取+写入;a:追加# 简答的读取方法:.read() → 读取后,光标将会留在读取末尾# 另外一种打开文件的方式,就不需要f.close()with open(r'C:\Users\Desktop\hello.txt',encoding='utf-8') as f:print(f.read())print('读取为空')# 运行第一次.read()之后,光标位于末尾,再次读取输出为空f.seek(0) # 将光标重新移到开始print(f.read())print('第二次读取')# 所以现在用 f.seek(0) 来移动光标f.close()# print(f.read()) # 关闭后无法读取# 关闭文件链接 f.close(),养成一个好习惯
3. 系统模块下的路径操作 os
import os
① os.name # 可以显示正在使用的平台,如果是windows,则用‘nt’表示,对Linux/Unix用户,则是'posix'
② os.getcwd() # 显示当前脚本的文件路径
③ os.listdir() # 显示当前文件夹下的所有文件
④ os.chdir('C:/Users/Desktop') # 更改文件路径,常用在爬虫保存文件中
⑤ os.remove(***) # 删除某某文件
⑥ os.path.split() # 将文件的路径以及相应文件名分开
⑦ os.path.exists() #判断文件是否存在
⑧绝对路径与相对路径
#相对路径与绝对路径
f1 = open('C:/Users/Desktop/hello.txt',encoding='utf-8')
os.chdir('C:/Users/Desktop/')
f2 = open('hello.txt',encoding='utf-8') #这种方式打开文件都会在该文件夹下 (在爬虫的保存文件中非常常用)
4. 读取文件 read()、readline()、readlines()
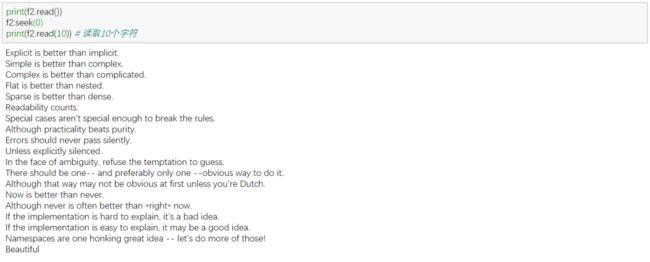
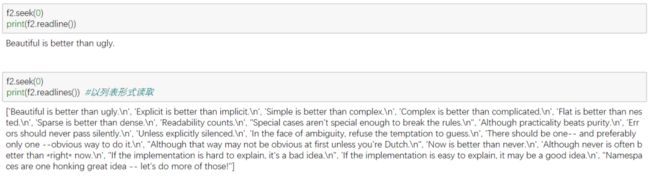
5. 写入文件 write()

6. pickle模块的使用
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
python的pickle模块实现了基本的数据序列和反序列化
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
pickle.dump() / pickle.load() 文件后缀为pkl

- END -


读书、观影
分享生活的碎片
有理想的人不会伤心