人工智能-数学基础-函数与优化
一.最优化问题
1.一元方程最优化问题
求解函数极小值 f ( x ) = x 2 + x − 1 f(x) = x^2 + x -1 f(x)=x2+x−1
1.1 传统求解
先求导,使导数为0: f ′ ( x ) = 2 x + 1 = 0 f\prime(x) = 2x+ 1=0 f′(x)=2x+1=0
x = − 0.5 x = -0.5 x=−0.5
但是大多数情况下,函数很难直接计算导数为0,并且计算机无法跟人脑似的解方程,所以大多数情况下需要依靠数值求解。
1.2 随机过程求解,类似“模拟退火”
依靠不断地尝试求解:
"""
一元二次方程求极值(随机过程,模拟退火)
"""
import numpy as np
# 要求解的一元二次方程
def f(x):
return x ** 2 + x - 1
# 估计一个附近值
x = 1
y = f(x)
for step in range(10000):
# 生成随机的在 -0.5到0.5之间范围的自变量
xt = x + (np.random.random() - 0.5)
yt = f(xt)
# 当yt变得比y小的时候, 将 xt 赋值给 x, 不停地迭代, y值会变得越来越小, 直至到达极值
if yt < y:
x = xt
y = yt
print(x, y)
else:
continue
print(x, y)
1.3 梯度下降法
设 当 前 自 变 量 为 x t , 新 的 x t + 1 = x t + Δ x , 后 使 得 f ( x t ) ≥ f ( x t + 1 ) 即 可 。 设当前自变量为 x_t,新的x_{t+1} = x_t + \Delta x,后使得 f(x_t) \geq f(x_{t+1}) 即可。 设当前自变量为xt,新的xt+1=xt+Δx,后使得f(xt)≥f(xt+1)即可。 重 复 这 个 过 程 , 直 到 最 后 的 x t , x t + 1 , ⋯ , x t + n 不 再 发 生 变 化 。 即 趋 于 收 敛 。 重复这个过程,直到最后的 x_t,x_{t+1},\cdots,x_{t+n}不再发生变化。即趋于收敛。 重复这个过程,直到最后的xt,xt+1,⋯,xt+n不再发生变化。即趋于收敛。 函数可以展开为: f ( x t + 1 ) = f ( x t + Δ x ) ≈ f ( x t ) + f ′ ( x ) Δ x f(x_{t+1}) = f(x_t + \Delta x) \approx f(x_t) + f\prime(x)\Delta x f(xt+1)=f(xt+Δx)≈f(xt)+f′(x)Δx
f ( x t + 1 ) − f ( x t ) ≈ f ′ ( x ) Δ x , 因 此 当 Δ x = − η f ′ ( x ) 且 ( η > 0 ) 时 , f ( x t + 1 ) − f ( x t ) ≈ − η f ′ ( x ) 2 ≤ 0 f(x_{t+1}) -f(x_t) \approx f\prime(x)\Delta x,因此当 \Delta x = -\eta f\prime(x)且 (\eta > 0)时, f(x_{t+1}) -f(x_t) \approx -\eta f\prime(x)^2 \leq 0 f(xt+1)−f(xt)≈f′(x)Δx,因此当Δx=−ηf′(x)且(η>0)时,f(xt+1)−f(xt)≈−ηf′(x)2≤0
当 Δ x = − η f ′ ( x ) 时 , f ( x t ) ≥ f ( x t + 1 ) 当 \Delta x = -\eta f\prime(x)时,f(x_t) \geq f(x_{t+1}) 当Δx=−ηf′(x)时,f(xt)≥f(xt+1)
说明:
η 称 为 学 习 率 , 学 习 率 过 大 , 此 时 迭 代 发 散 , 学 习 过 小 , 迭 代 收 敛 缓 慢 , 取 得 合 适 的 极 小 值 时 , 此 时 称 为 迭 代 收 敛 。 \eta称为学习率,学习率过大,此时迭代发散,学习过小,迭代收敛缓慢,取得合适的极小值时,此时称为迭代收敛。 η称为学习率,学习率过大,此时迭代发散,学习过小,迭代收敛缓慢,取得合适的极小值时,此时称为迭代收敛。
"""
一元二次方程求极值(梯度下降法(导数))
"""
# 要求解的一元二次方程
def f(x):
return x ** 2 + x - 1
# 该方程的梯度(或导数)
def gradf(x):
return 2 * x + 1
# 给予一个初始值, 该值是估计值, 即凭借经验得出的x的近似值
x = 1
# 机器学习中称为学习率, 过小的话, 会导致迭代收敛过于缓慢,
# 过大的话, 又会导致迭代发散
eta = 0.01
for step in range(1000):
dydx = gradf(x)
# 理想结果是该计算收敛, 最终 x 会无限接近甚至达到极小值所在点
x = x - dydx * eta
print(step, x, f(x))
print(x, f(x))
2.多元函数求极小值
有 多 个 自 变 量 的 函 数 , f ( x 1 , x 2 , ⋯ , x n ) , 即 f ( x ) , f ( x → ) , f ( x ) 例 如 求 解 f ( x 1 , x 2 ) = x 1 2 + x 2 2 + 2 x 1 + x 2 − 1 有多个自变量的函数, f(x_1,x_2,\cdots,x_n) ,即 f(x), f(\overrightarrow x), f(\bf x) 例如求解f(x_1,x_2) = x_1^2 + x_2^2 + 2x_1 + x_2 - 1 有多个自变量的函数,f(x1,x2,⋯,xn),即f(x),f(x),f(x)例如求解f(x1,x2)=x12+x22+2x1+x2−1
多 元 函 数 求 偏 导 : ∂ f ( x 1 , x 2 ) ∂ x 1 = 2 x 1 + 2 ; ∂ f ( x 1 , x 2 ) ∂ x 2 = 2 x 2 + 1 , 对 某 个 自 变 量 进 行 展 开 : 多元函数求偏导:\frac {\partial f(x_1,x_2)}{\partial x_1} = 2x_1 + 2; \frac {\partial f(x_1,x_2)}{\partial x_2} = 2x_2 + 1,对某个自变量进行展开: 多元函数求偏导:∂x1∂f(x1,x2)=2x1+2;∂x2∂f(x1,x2)=2x2+1,对某个自变量进行展开:
f ( x 1 , x 2 , ⋯ , x i + Δ x i , ⋯ , x n ) ≈ f ( x ) + ∂ f ∂ x i Δ x i f(x_1,x_2,\cdots,x_i + \Delta x_i, \cdots,x_n) \approx f(x) + \frac {\partial f}{\partial x_i}\Delta x_i f(x1,x2,⋯,xi+Δxi,⋯,xn)≈f(x)+∂xi∂fΔxi
注 释 : Δ x 代 表 一 个 微 小 的 变 化 注释: \Delta x代表一个微小的变化 注释:Δx代表一个微小的变化
如果第二个自变量也发生了微小的变化:
f ( x 1 , x 2 + Δ x 2 , ⋯ , x i + Δ x i , ⋯ , x n ) ≈ f ( x ) + ∂ f ∂ x i Δ x i + ∂ f ∂ x 2 Δ x 2 f(x_1,x_2+ \Delta x_2,\cdots,x_i + \Delta x_i, \cdots,x_n) \approx f(x) + \frac {\partial f}{\partial x_i}\Delta x_i + \frac {\partial f}{\partial x_2}\Delta x_2 f(x1,x2+Δx2,⋯,xi+Δxi,⋯,xn)≈f(x)+∂xi∂fΔxi+∂x2∂fΔx2
如果所有自变量都发生了微小的变化:
f ( x 1 + Δ x 1 , ⋯ , x i + Δ x i , ⋯ , x n + Δ x n ) ≈ f ( x ) + ∑ i = 1 n ∂ f ∂ x i Δ x i f(x_1 + \Delta x_1,\cdots,x_i + \Delta x_i, \cdots,x_n+ \Delta x_n) \approx f(x) + \sum_{i=1}^n \frac {\partial f}{\partial x_i}\Delta x_i f(x1+Δx1,⋯,xi+Δxi,⋯,xn+Δxn)≈f(x)+i=1∑n∂xi∂fΔxi
此时:
∇ f = [ ∂ f ∂ x x , ⋯ , ∂ f ∂ x n ] 称 为 梯 度 向 量 ; \nabla f = [ \frac {\partial f}{\partial x_x},\cdots,\frac {\partial f}{\partial x_n}] 称为梯度向量; ∇f=[∂xx∂f,⋯,∂xn∂f]称为梯度向量;
Δ x = [ Δ x 1 , ⋯ , Δ x n ] 为 增 量 向 量 ; \Delta x = [\Delta x_1,\cdots ,\Delta x_n] 为增量向量; Δx=[Δx1,⋯,Δxn]为增量向量;
当 Δ x = − η ∇ f , f ( x + Δ x ) − f ( x ) = ∇ f Δ x = − η ∇ f 2 = − η ∑ i = 1 n ( ∂ f ∂ x i ) 2 ≥ 0 当 \Delta x = -\eta \nabla f ,f(x+\Delta x) - f(x) = \nabla f \Delta x = -\eta \nabla f ^2 = -\eta\sum_{i=1}^n (\frac {\partial f}{\partial x_i})^2 \geq 0 当Δx=−η∇f,f(x+Δx)−f(x)=∇fΔx=−η∇f2=−ηi=1∑n(∂xi∂f)2≥0
即 : x t + 1 = x t − η ∇ f 时 , 函 数 f ( x t + 1 ) ≤ f ( x t ) 即: x_{t+1} = x_t -\eta \nabla f时,函数 f(x_{t+1}) \leq f(x_t) 即:xt+1=xt−η∇f时,函数f(xt+1)≤f(xt)
展 开 成 分 量 : x i ← x i − η ∂ f ∂ x i 展开成分量:x_i \leftarrow x_i - \eta \frac {\partial f}{\partial x_i} 展开成分量:xi←xi−η∂xi∂f
以 上 可 以 进 行 梯 度 下 降 法 以上可以进行梯度下降法 以上可以进行梯度下降法
"""
多元函数求极值(梯度下降法(导数))
"""
# 要求解的多元方程
def f(x1, x2):
return x1 ** 2 + x2 ** 2 + 2 * x1 + x2 - 1
# 该方程的梯度(或导数)
def gradf(x1, x2):
return 2 * x1 + 2, 2 * x2 + 1
# 给予一个初始值, 该值是估计值, 即凭借经验得出的x1, x2的近似值
x1, x2 = 1, 1
# 机器学习中称为学习率, 过小的话, 会导致迭代收敛过于缓慢,
# 过大的话, 又会导致迭代发散
eta = 0.3
for step in range(50):
# 求多元函数各个自变量的偏导数
dydx1, dydx2 = gradf(x1, x2)
# 每个自变量依次进行收敛
x1 = x1 - dydx1 * eta
x2 = x2 - dydx2 * eta
print(step, x1, x2, f(x1, x2))
print(step, x1, x2, f(x1, x2))
3.实际运用:求任意数字的开根号
任意一个数字假设为x,假设: x = a \sqrt{x} = a x=a
定义一个函数:
L = ( a 2 − x ) 2 , 此 为 目 标 函 数 , 当 x = a , 函 数 取 得 极 小 值 L=(a^2-x)^2,此为目标函数,当\sqrt{x} = a,函数取得极小值 L=(a2−x)2,此为目标函数,当x=a,函数取得极小值
求取极小值的过程就是迭代的过程:
1.随意取初始值 a= 0
2. 对a进行求导
a t + 1 = a t − η ∂ f ∂ a = a t − 4 η a ( a 2 − x ) a_{t+1} = a_t-\eta \frac {\partial f}{\partial a}=a_t-4 \eta a(a^2-x) at+1=at−η∂a∂f=at−4ηa(a2−x)
3.迭代过程中:
a.需要调整学习率,使得模型尽快收敛而且不发散。
b.如果迭代发散,需要减少学习率
c.如果收敛缓慢需要增加学习率
d.需要调整不同的初始值。
"""
.梯度下降法求解开根号, 如: 求解 根号5
思路: 将该问题转化为数学问题, 转化为求解 y = (x^2 - b)^2 的最小值问题
"""
def sqrt(b):
# 我们转化的数学模型, 需要求解它的极小值
def f(x, b):
return (x ** 2 - b) ** 2
# 我们所建立的数学模型的导数(也称梯度)
def gradf(x, b):
return 4 * x * (x ** 2 - b)
# 给予一个初始值, 该值是估计值, 即凭借经验得出的x的近似值
x = 1
# 机器学习中称为学习率, 过小的话, 会导致迭代收敛过于缓慢,
# 过大的话, 又会导致迭代发散
eta = 0.001
# 进行迭代
for step in range(1000):
# 求解每次迭代中的导数值
dydx = gradf(x, b)
# 理想结果是该计算收敛, 最终 x 会无限接近甚至达到极小值所在点
x = x - eta * dydx
print(step, x, f(x, b))
return x
b = 5
print(sqrt(b))
二.利用梯度下降法进行机器学习
2.1 预测股票涨幅
预测股票涨跌,假设通过观察,某天涨跌幅d,与前两天的涨跌幅有关,则进行建模:
y = a x 1 + b x 2 + c y=ax_1+bx_2+c y=ax1+bx2+c
y是对于今天的股票的预测。a,b,c是建模过程中所用的预设参数,称为可训练参数。
模型进行调整的依据为:
l = ( d − y ) 2 l=(d-y)^2 l=(d−y)2
此时l称为损失函数,用于衡量预测输出y与真实值d之间的接近程度。
我们可以利用现有历史数据,可以制作很多的的数据对{x1,x2,d},称为样本或训练数据。使用训练数据对可训练参数进行调整。以上就是机器学习的过程。
步骤:
1.准备数据,矩阵分块计算
2.训练模型
L = 1 N ∑ i N ( y i + d i ) 2 L=\frac{1}{N} \sum_{i}^N (y_i+d_i)^2 L=N1i∑N(yi+di)2
对可训练参数求导:
∂ L ∂ a = 1 N ∑ i N ∂ L ∂ y i ∂ y i ∂ a = 1 N ∑ i N 2 ( y i − d i ) x i , 1 = 2 ( y − d ) x 1 ‾ \frac {\partial L}{\partial a}=\frac{1}{N}\sum_{i}^N \frac {\partial L}{\partial y_i}\frac {\partial y_i}{\partial a} =\frac{1}{N}\sum_{i}^N2(y_i-d_i)x_{i,1}=\overline{2(y-d)x_1} ∂a∂L=N1i∑N∂yi∂L∂a∂yi=N1i∑N2(yi−di)xi,1=2(y−d)x1
∂ L ∂ b = 1 N ∑ i N ∂ L ∂ y i ∂ y i ∂ b = 1 N ∑ i N 2 ( y i − d i ) x i , 2 = 2 ( y − d ) x 2 ‾ \frac {\partial L}{\partial b}=\frac{1}{N}\sum_{i}^N \frac {\partial L}{\partial y_i}\frac {\partial y_i}{\partial b} =\frac{1}{N}\sum_{i}^N2(y_i-d_i)x_{i,2}=\overline{2(y-d)x_2} ∂b∂L=N1i∑N∂yi∂L∂b∂yi=N1i∑N2(yi−di)xi,2=2(y−d)x2
"""
用前两天的股票升降幅预测第三天的股票升降幅
"""
import tushare as ts
import matplotlib.pyplot as plt
import numpy as np
data = ts.get_hist_data("600848")
np.array(data)
print(data)
# 此为构建的模型,y= ax1 + bx2 + c 就是对于今天的股票的预测。x1, x2分别为前两天的升降值, a, b, c为可训练参数
# 调整的依据就是:使得损失函数 L = (d - y)^2 最小
def model(x1, x2, a, b, c):
return a * x1 + b * x2 + c
# 损失函数, 损失函数越小, 则该预测模型越准确(此为目标函数)
def loss_function(d, y):
return (d - y) ** 2
# 对目标函数的几个可训练参数 a, b, c分别求导
def gradL(x1, x2, d, a, b, c):
y = model(x1, x2, a, b, c)
# 这里运用的是矩阵的分块计算, 计算得出的值是一个列表
dLdy = 2 * (y - d)
dLda = dLdy * x1
dLdb = dLdy * x2
dLdc = dLdy * 1
# 求一下均值
return np.mean(dLda), np.mean(dLdb), np.mean(dLdc)
# 数据
x = data.values[:, 6]
"""
对数据进行分块, 向量 [x1, x2, d]所组成的数据, 进行计算时类似于此种形式
例如数据集 [4月1日, 4月2日, 4月3日, 4月4日, 4月5日]
x1 = [4月1日, 4月2日, 4月3日]
x2 = [4月2日, 4月3日, 4月4日]
x3 = [4月3日, 4月4日, 4月5日]
计算时, 每一列分别参加一组计算, 即为用前两天的数据, 预测第三天的值
"""
x1 = x[:-3]
x2 = x[1:-2]
d = x[2:-1]
# 预测值
a, b, c = 0, 0, 0
# 学习率
eta = 0.05
for step in range(100):
# 求解 a, b, c 的偏导
ga, gb, gc = gradL(x1, x2, d, a, b, c)
# 进行迭代
a = a - eta * ga
b = b - eta * gb
c = c - eta * gc
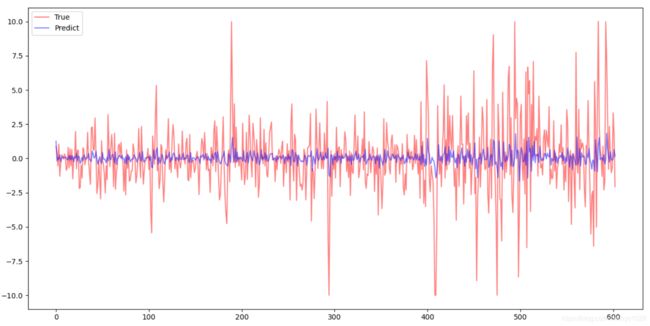
y = model(x1, x2, a, b, c)
plt.switch_backend("TkAgg")
plt.plot(d, alpha=0.5, color="#ff0000", label="True")
plt.plot(y, alpha=0.5, color="#0000ff", label="Predict")
plt.legend()
plt.show()
2.2 使用批尺寸进行模型训练
2.1 中为全量数据直接代入 ,每次迭代过程中如果不使用全量数据集。而使用数据集的一部分进行训练。即使用Mini-batch。BatchSize,批尺寸。每次选择多数数据进行训练。
"""
用前两天的股票升降幅预测第三天的股票升降幅, 采用批尺寸
"""
import tushare as ts
import matplotlib.pyplot as plt
import numpy as np
data = ts.get_hist_data("600848")
np.array(data)
print(data)
# 此为构建的模型,y= ax1 + bx2 + c 就是对于今天的股票的预测。x1, x2分别为前两天的升降值, a, b, c为可训练参数
# 调整的依据就是:使得损失函数 L = (d - y)^2 最小
def model(x1, x2, a, b, c):
return a * x1 + b * x2 + c
# 损失函数, 损失函数越小, 则该预测模型越准确(此为目标函数)
def loss_function(d, y):
return (d - y) ** 2
# 对目标函数的几个可训练参数 a, b, c分别求导
def gradL(x1, x2, d, a, b, c):
y = model(x1, x2, a, b, c)
# 这里运用的是矩阵的分块计算, 计算得出的值是一个列表
dLdy = 2 * (y - d)
dLda = dLdy * x1
dLdb = dLdy * x2
dLdc = dLdy * 1
# 求一下均值
return np.mean(dLda), np.mean(dLdb), np.mean(dLdc)
# 数据
x = data.values[:, 6]
"""
对数据进行分块, 向量 [x1, x2, d]所组成的数据, 进行计算时类似于此种形式
例如数据集 [4月1日, 4月2日, 4月3日, 4月4日, 4月5日]
x1 = [4月1日, 4月2日, 4月3日]
x2 = [4月2日, 4月3日, 4月4日]
x3 = [4月3日, 4月4日, 4月5日]
计算时, 每一列分别参加一组计算, 即为用前两天的数据, 预测第三天的值
"""
x1 = x[:-3]
x2 = x[1:-2]
d = x[2:-1]
# 预测值
a, b, c = 0, 0, 0
# 学习率
eta = 0.05
# 采用批尺寸代入已经数据
batch_size = 30
for step in range(100):
idx = np.random.randint(0, len(d), batch_size)
inx1 = x1[idx]
inx2 = x2[idx]
ind = d[idx]
# 求解 a, b, c 的偏导
ga, gb, gc = gradL(inx1, inx2, ind, a, b, c)
# 进行迭代
a = a - eta * ga
b = b - eta * gb
c = c - eta * gc
y = model(x1, x2, a, b, c)
plt.switch_backend("TkAgg")
plt.plot(d, alpha=0.5, color="#ff0000", label="True")
plt.plot(y, alpha=0.5, color="#0000ff", label="Predict")
plt.legend()
plt.show()

批尺寸说明(BatchSize):
a.如果迭代收敛缓慢,可以增加批尺寸
b.如果迭代过程中计算速度较慢,可以减少批尺寸
c.通常批尺寸依赖计算机内存,如果内存够大,则批尺寸可以适当大一些
2.3 进行其他建模
例如假设,股票当前的升降幅与前三天的升降幅相关:
"""
用前三天的股票升降幅预测第四天的股票升降幅, 采用批尺寸
"""
import tushare as ts
import matplotlib.pyplot as plt
import numpy as np
plt.switch_backend("TkAgg")
data = ts.get_hist_data("600848")
def model(x1, x2, x3, a, b, c, d):
return a * x1 + b * x2 + c * x3 + d
def gradL(x1, x2, x3, dd, a, b, c, d):
y = model(x1, x2, x3, a, b, c, d)
dLdy = 2 * (y - dd)
dLda = dLdy * x1
dLdb = dLdy * x2
dLdc = dLdy * x3
dLdd = dLdy * 1
return np.mean(dLda), np.mean(dLdb), np.mean(dLdc), np.mean(dLdd)
# 数据
x = data.values[:, 6]
x1 = x[:-4] # 可能有几千天
x2 = x[1:-3]
x3 = x[2:-2]
dd = x[3:-1]
a, b, c, d = 0, 0, 0, 0
eta = 0.05
batch_size = 100
for step in range(100):
idx = np.random.randint(0, len(dd), batch_size)
inx1 = x1[idx]
inx2 = x2[idx]
inx3 = x3[idx]
ind = dd[idx]
ga, gb, gc, gd = gradL(x1, x2, x3, dd, a, b, c, d)
a = a - eta * ga
b -= eta * gb
c -= eta * gc
d -= eta * gd
y = model(x1, x2, x3, a, b, c, d)
plt.plot(dd, color="#ff0000", alpha=0.5, label="True")
plt.plot(y, color="#0000ff", alpha=0.5, label="Predict")
plt.legend()
plt.show()
print(data)
