自然语言处理(NLP)-第三方库(工具包):fastText【作用:基于深度学习的文本分类、word2vec训练词向量、词向量模型迁移(直接拿别人已经训练好的词向量模型来使用)】
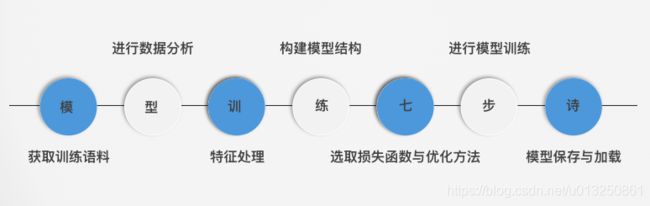
作为NLP工程领域常用的工具包, fasttext有两大作用:
- 进行文本分类
- 训练词向量
fasttext工具包的优势:正如它的名字, 在保持较高精度的情况下, 快速的进行训练和预测是fasttext的最大优势.
fasttext优势的原因:
- fasttext工具包中内含的fasttext模型具有十分简单的网络结构.
- 使用fasttext模型训练词向量时使用层次softmax结构, 来提升超多类别下的模型性能.
- 由于fasttext模型过于简单无法捕捉词序特征, 因此会进行n-gram特征提取以弥补模型缺陷提升精度.
fasttext的离线安装:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
# 使用pip安装python中的fasttext工具包
$ sudo pip install .
fasttext的在线安装:
(base) D:\Workspaces_AI\NLP\nlpStudy>pip install fastText
验证安装:
Python 3.7.3 (default, Mar 27 2019, 22:11:17)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import fasttext
>>>
一、fastText的原理剖析
1. fastText的模型架构
fastText的架构非常简单,有三层:输入层、隐含层、输出层(Hierarchical Softmax)
输入层:是对文档embedding之后的向量,包含有N-garm特征
隐藏层:是对输入数据的求和平均
输出层:是文档对应标签
如下图所示:

1.1 N-garm的理解
1.1.1 bag of word

bag of word 又称为bow,称为词袋。是一种只统计词频的手段。
例如:在机器学习的课程中通过朴素贝叶斯来预测文本的类别,我们学习的countVectorizer和TfidfVectorizer都可以理解为一种bow模型。
1.1.2 N-gram模型
但是在很多情况下,词袋模型是不满足我们的需求的。
例如:我爱她 和她爱我在词袋模型下面,概率完全相同,但是其含义确实差别非常大。
为了解决这个问题,就有了N-gram模型,它不仅考虑词频,还会考虑当前词前面的词语,比如我爱,她爱。
N-gram模型的描述是:第n个词出现与前n-1个词相关,而与其他任何词不相关。(当然在很多场景下和前n-1个词也会相关,但是为了简化问题,经常会这样去计算)
例如:I love deep learning这个句子,在n=2的情况下,可以表示为{i love},{love deep},{deep learning},n=3的情况下,可以表示为{I love deep},{love deep learning}。
在n=2的情况下,这个模型被称为Bi-garm(二元n-garm模型)
在n=3 的情况下,这个模型被称为Tri-garm(三元n-garm模型)
具体可以参考 ed3book chapter3
所以在fasttext的输入层,不仅有分词之后的词语,还有包含有N-gram的组合词语一起作为输入
2. fastText中的层次化的softmax-对传统softmax的优化方法1
为了提高效率,在fastText中计算分类标签的概率的时候,不再是使用传统的softmax来进行多分类的计算,而是使用的哈夫曼树(Huffman,也成为霍夫曼树),使用层次化的softmax(Hierarchial softmax)来进行概率的计算。
2.1 哈夫曼树和哈夫曼编码

2.1.1 哈夫曼树的定义
哈夫曼树概念:给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
2.1.2 哈夫曼树的相关概念
二叉树:每个节点最多有2个子树的有序树,两个子树分别称为左子树、右子树。有序的意思是:树有左右之分,不能颠倒
叶子节点:一棵树当中没有子结点的结点称为叶子结点,简称“叶子”
路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和
树的高度:树中结点的最大层次。包含n个结点的二叉树的高度至少为log2 (n+1)。
2.1.3 哈夫曼树的构造算法
- 把 { W 1 , W 2 , W 3 … W n } \{W_1,W_2,W_3 \dots W_n\} { W1,W2,W3…Wn}看成n棵树的森林
- 在森林中选择两个根节点权值最小的树进行合并,作为一颗新树的左右子树,新树的根节点权值为左右子树的和
- 删除之前选择出的子树,把新树加入森林
- 重复2-3步骤,直到森林只有一棵树为止,概树就是所求的哈夫曼树
例如:圆圈中的表示每个词语出现的次数,以这些词语为叶子节点构造的哈夫曼树过程如下:
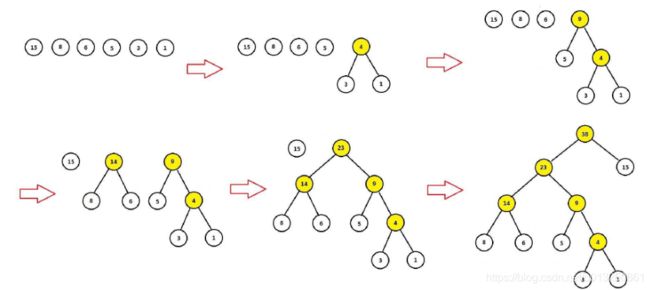
可见:
- 权重越大,距离根节点越近
- 叶子的个数为n,构造哈夫曼树中新增的节点的个数为n-1
2.2.1 哈夫曼编码
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。
例如,需传送的报文为AFTER DATA EAR ARE ART AREA,这里用到的字符集为A,E,R,T,F,D,各字母出现的次数为{8,4,5,3,1,1}。现要求为这些字母设计编码。要区别6个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101对A,E,R,T,F,D进行编码发送
但是很明显,上述的编码的方式并不是最优的,即整理传送的字节数量并不是最少的。
为了提高数据传送的效率,同时为了保证任一字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码[前缀编码],可以使用哈夫曼树生成哈夫曼编码解决问题
可用字符集中的每个字符作为叶子结点生成一棵编码二叉树,为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送报文的最短长度
因此,求传送报文的最短长度问题转化为求由字符集中的所有字符作为叶子结点,由字符出现频率作为其权值所产生的哈夫曼树的问题。利用哈夫曼树来设计二进制的前缀编码,既满足前缀编码的条件,又保证报文编码总长最短。
下图中label1 .... label6分别表示A,E,R,T,F,D

2.3 梯度计算

上图中,红色为哈夫曼编码,即label5的哈夫曼编码为1001,那么此时如何定义条件概率 P ( L a b e l 5 ∣ c o n t e x ) P(Label5|contex) P(Label5∣contex)呢?
以Label5为例,从根节点到Label5中间经历了4次分支,每次分支都可以认为是进行了一次2分类,根据哈夫曼编码,可以把路径中的每个非叶子节点0认为是负类,1认为是正类(也可以把0认为是正类)
由机器学习课程中逻辑回归使用sigmoid函数进行2分类的过程中,一个节点被分为正类的概率是 δ ( X T θ ) = 1 1 + e − X T θ \delta(X^{T}\theta) = \frac{1}{1+e^{-X^T\theta}} δ(XTθ)=1+e−XTθ1,被分类负类的概率是: 1 − δ ( X T θ ) 1-\delta(X^T\theta) 1−δ(XTθ),其中 θ \theta θ就是图中非叶子节点对应的参数 θ \theta θ。
对于从根节点出发,到达Label5一共经历4次2分类,将每次分类结果的概率写出来就是:
- 第一次: P ( 1 ∣ X , θ 1 ) = δ ( X T θ 1 ) P(1|X,\theta_1) = \delta(X^T\theta_1) P(1∣X,θ1)=δ(XTθ1) ,即从根节点到23节点的概率是在知道X和 θ 1 \theta_1 θ1的情况下取值为1的概率
- 第二次: P ( 0 ∣ X , θ 2 ) = 1 − δ ( X T θ 2 ) P(0|X,\theta_2) =1- \delta(X^T\theta_2) P(0∣X,θ2)=1−δ(XTθ2)
- 第三次: P ( 0 ∣ X , θ 3 ) = 1 − δ ( X T θ 4 ) P(0 |X,\theta_3) =1- \delta(X^T\theta_4) P(0∣X,θ3)=1−δ(XTθ4)
- 第四次: P ( 1 ∣ X , θ 4 ) = δ ( X T θ 4 ) P(1|X,\theta_4) = \delta(X^T\theta_4) P(1∣X,θ4)=δ(XTθ4)
但是我们需要求的是 P ( L a b e l ∣ c o n t e x ) P(Label|contex) P(Label∣contex), 他等于前4词的概率的乘积,公式如下( d j w d_j^w djw是第j个节点的哈夫曼编码)
P ( L a b e l ∣ c o n t e x t ) = ∏ j = 2 5 P ( d j ∣ X , θ j − 1 ) P(Label|context) = \prod_{j=2}^5P(d_j|X,\theta_{j-1}) P(Label∣context)=j=2∏5P(dj∣X,θj−1)
其中:
P ( d j ∣ X , θ j − 1 ) = { δ ( X T θ j − 1 ) , d j = 1 ; 1 − δ ( X T θ j − 1 ) d j = 0 ; P(d_j|X,\theta_{j-1}) = \left\{ \begin{aligned} &\delta(X^T\theta_{j-1}), & d_j=1;\\ &1-\delta(X^T\theta_{j-1}) & d_j=0; \end{aligned} \right. P(dj∣X,θj−1)={ δ(XTθj−1),1−δ(XTθj−1)dj=1;dj=0;
或者也可以写成一个整体,把目标值作为指数,之后取log之后会前置:
P ( d j ∣ X , θ j − 1 ) = [ δ ( X T θ j − 1 ) ] d j ⋅ [ 1 − δ ( X T θ j − 1 ) ] 1 − d j P(d_j|X,\theta_{j-1}) = [\delta(X^T\theta_{j-1})]^{d_j} \cdot [1-\delta(X^T\theta_{j-1})]^{1-d_j} P(dj∣X,θj−1)=[δ(XTθj−1)]dj⋅[1−δ(XTθj−1)]1−dj
在机器学习中的逻辑回归中,我们经常把二分类的损失函数(目标函数)定义为对数似然损失,即
l = − 1 M ∑ l a b e l ∈ l a b e l s l o g P ( l a b e l ∣ c o n t e x t ) l =-\frac{1}{M} \sum_{label\in labels} log\ P(label|context) l=−M1label∈labels∑log P(label∣context)
式子中,求和符号表示的是使用样本的过程中,每一个label对应的概率取对数后的和,之后求取均值。
带入前面对 P ( l a b e l ∣ c o n t e x t ) P(label|context) P(label∣context)的定义得到:
l = − 1 M ∑ l a b e l ∈ l a b e l s l o g ∏ j = 2 { [ δ ( X T θ j − 1 ) ] d j ⋅ [ 1 − δ ( X T θ j − 1 ) ] 1 − d j } = − 1 M ∑ l a b e l ∈ l a b e l s ∑ j = 2 { d j ⋅ l o g [ δ ( X T θ j − 1 ) ] + ( 1 − d j ) ⋅ l o g [ 1 − δ ( X T θ j − 1 ) ] } \begin{aligned} l & = -\frac{1}{M}\sum_{label\in labels}log \prod_{j=2}\{[\delta(X^T\theta_{j-1})]^{d_j} \cdot [1-\delta(X^T\theta_{j-1})]^{1-d_j}\} \\ & =-\frac{1}{M} \sum_{label\in labels} \sum_{j=2}\{d_j\cdot log[\delta(X^T\theta_{j-1})]+ (1-d_j) \cdot log [1-\delta(X^T\theta_{j-1})]\} \end{aligned} l=−M1label∈labels∑logj=2∏{ [δ(XTθj−1)]dj⋅[1−δ(XTθj−1)]1−dj}=−M1label∈labels∑j=2∑{ dj⋅log[δ(XTθj−1)]+(1−dj)⋅log[1−δ(XTθj−1)]}
有了损失函数之后,接下来就是对其中的 X , θ X,\theta X,θ进行求导,并更新,最终还需要更新最开始的每个词语词向量
层次化softmax的好处:传统的softmax的时间复杂度为L(Labels的数量),但是使用层次化softmax之后时间复杂度的log(L) (二叉树高度和宽度的近似),从而在多分类的场景提高了效率
3. fastText中的negative sampling(负采样)-对传统softmax的优化方法2
negative sampling,即每次从除当前label外的其他label中,随机的选择几个作为负样本。具体的采样方法:
如果所有的label为 V V V,那么我们就将一段长度为1的线段分成 V V V份,每份对应所有label中的一类label。当然每个词对应的线段长度是不一样的,高频label对应的线段长,低频label对应的线段短。每个label的线段长度由下式决定:
l e n ( w ) = c o u n t ( l a b e l ) α ∑ w ∈ l a b e l s c o u n t ( l a b e l s ) α len(w) = \frac{count(label)^{\alpha}}{\sum_{w \in labels} count(labels)^{\alpha}} len(w)=∑w∈labelscount(labels)αcount(label)α
其中:a在fasttext中为0.75,即负采样的数量和原来词频的平方根成正比
在采样前,我们将这段长度为1的线段划分成 M M M等份,这里 M > > V M>>V M>>V,这样可以保证每个label对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个label对应的线段上。在采样的时候,我们只需要从 M M M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例。

简单的理解就是,从原来所有的样本中,等比例的选择neg个负样本作(遇到自己则跳过),作为训练样本,添加到训练数据中,和正例样本一起来进行训练。
Negative Sampling也是采用了二元逻辑回归来求解模型参数,通过负采样,我们得到了neg个负例,将正例定义为 l a b e l 0 label_0 label0,负例定义为 l a b e l i , i = 1 , 2 , 3... n e g label_i,i=1,2,3...neg labeli,i=1,2,3...neg
定义正例的概率为 P ( l a b e l 0 ∣ context ) = σ ( x k T θ ) , y i = 1 P\left( label_{0}|\text {context}\right)=\sigma\left(x_{\mathrm{k}}^{T} \theta\right), y_{i}=1 P(label0∣context)=σ(xkTθ),yi=1
则负例的概率为: P ( l a b e l i ∣ context ) = 1 − σ ( x k T θ ) , y i = 0 , i = 1 , 2 , 3.. n e g P\left( label_{i}|\text {context}\right)=1-\sigma\left(x_{\mathrm{k}}^{T} \theta\right), y_{i}=0,i=1,2,3..neg P(labeli∣context)=1−σ(xkTθ),yi=0,i=1,2,3..neg
此时对应的对数似然函数为:
L = ∑ i = 0 n e g y i log ( σ ( x l a b e l 0 T θ ) ) + ( 1 − y i ) log ( 1 − σ ( x l a b e l 0 T θ ) ) L=\sum_{i=0}^{n e g} y_{i} \log \left(\sigma\left(x_{label_0}^{T} \theta\right)\right)+\left(1-y_{i}\right) \log \left(1-\sigma\left(x_{label_0}^{T} \theta\right)\right) L=i=0∑negyilog(σ(xlabel0Tθ))+(1−yi)log(1−σ(xlabel0Tθ))
具体的训练时候损失的计算过程(源代码已经更新,不再是下图中的代码):

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1fANro6v-1616123412945)(…/…/…/…/NLP%E8%AF%BE%E4%BB%B6%E7%BC%96%E5%86%99/markdown/doc/images/2.2/fasttext%E8%B4%9F%E9%87%87%E6%A0%B7.png)]
可以看出:一个neg+1个样本进行了训练,得到了总的损失。
之后会使用梯度上升的方法进行梯度计算和参数更新,仅仅每次只用一波样本(一个正例和neg个反例)更新梯度,来进行迭代更新
具体的更新伪代码如下:

其中内部大括号部分为w相关参数的梯度计算过程,e为w的梯度和学习率的乘积,具体参考:https://blog.csdn.net/itplus/article/details/37998797
负采样的好处:
- 提高训练速度,选择了部分数据进行计算损失,同时整个对每一个label而言都是一个二分类,损失计算更加简单,只需要让当前label的值的概率尽可能大,其他label的都为反例,概率会尽可能小
- 改进效果,增加部分负样本,能够模拟真实场景下的噪声情况,能够让模型的稳健性更强
二、文本分类(有监督的深度学习)
文本分类的是将文档(例如电子邮件,帖子,文本消息,产品评论等)分配给一个或多个类别. 当今文本分类的实现多是使用机器学习方法从训练数据中提取分类规则以进行分类, 因此构建文本分类器需要带标签的数据.
文本分类的种类
- 二分类:文本被分类两个类别中, 往往这两个类别是对立面, 比如: 判断一句评论是好评还是差评.
- 单标签多分类:文本被分入到多个类别中, 且每条文本只能属于某一个类别(即被打上某一个标签), 比如: 输入一个人名, 判断它是来自哪个国家的人名.
- 多标签多分类:文本被分入到多个类别中, 但每条文本可以属于多个类别(即被打上多个标签), 比如: 输入一段描述, 判断可能是和哪些兴趣爱好有关, 一段描述中可能即讨论了美食, 又讨论了游戏爱好.
使用fasttext工具进行文本分类的过程
- 第一步: 获取数据
- 第二步: 训练集与验证集的划分
- 第三步: 训练模型
- 第四步: 使用模型进行预测并评估
- 第五步: 模型调优
- 第六步: 模型保存与重加载
1、第一步: 获取数据
cooking.stackexchange.txt中的每一行都包含一个标签列表,后跟相应的文档, 标签列表以类似"__label__sauce __label__cheese"的形式展现, 代表有两个标签sauce和cheese, 所有标签__label__均以前缀开头,这是fastText识别标签或单词的方式. 标签之后的一段话就是文本信息.如: How much does potato starch affect a cheese sauce recipe?
Windows下安装wget。下载地址:http://downloads.sourceforge.net/gnuwin32/wget-1.11.4-1-setup.exe
配置系统环境变量:
新建变量GNU_HOME: C:\Program Files (x86)\GnuWin32
在Path变量中添加: ;%GNU_HOME%\bin
# 获取烹饪相关的数据集, 它是由facebook AI实验室提供的演示数据集
$ wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
# 查看数据的前10条
$ head cooking.stackexchange.txt
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?
__label__food-safety __label__acidity Dangerous pathogens capable of growing in acidic environments
__label__cast-iron __label__stove How do I cover up the white spots on my cast iron stove?
__label__restaurant Michelin Three Star Restaurant; but if the chef is not there
__label__knife-skills __label__dicing Without knife skills, how can I quickly and accurately dice vegetables?
__label__storage-method __label__equipment __label__bread What's the purpose of a bread box?
__label__baking __label__food-safety __label__substitutions __label__peanuts how to seperate peanut oil from roasted peanuts at home?
__label__chocolate American equivalent for British chocolate terms
__label__baking __label__oven __label__convection Fan bake vs bake
__label__sauce __label__storage-lifetime __label__acidity __label__mayonnaise Regulation and balancing of readymade packed mayonnaise and other sauces
2、第二步: 训练集与验证集的划分
Linux系统:
# 查看数据总数
$ wc cooking.stackexchange.txt
15404 169582 1401900 cooking.stackexchange.txt
# 12404条数据作为训练数据
$ head -n 12404 cooking.stackexchange.txt > cooking.train
# 3000条数据作为验证数据
$ tail -n 3000 cooking.stackexchange.txt > cooking.valid
Windows系统:
直接将文件切分为两个文件:cooking.train、cooking.valid
3、第三步: 训练模型
- Progress: 训练进度, 因为我们这里显示的是最后的训练完成信息, 所以进度是100%
- words/sec/thread: 每个线程每秒处理的平均词汇数
- lr: 当前的学习率, 因为训练完成所以学习率是0
- avg.loss: 训练过程的平均损失
- ETA: 预计剩余训练时间, 因为已训练完成所以是0
Linux系统:
# 代码运行在python解释器中
# 导入fasttext
>>> import fasttext
# 使用fasttext的train_supervised方法进行文本分类模型的训练
>>> model = fasttext.train_supervised(input="cooking.train")
# 获得结果
Read 0M words
# 不重复的词汇总数
Number of words: 14543
# 标签总数
Number of labels: 735
# Progress: 训练进度, 因为我们这里显示的是最后的训练完成信息, 所以进度是100%
# words/sec/thread: 每个线程每秒处理的平均词汇数
# lr: 当前的学习率, 因为训练完成所以学习率是0
# avg.loss: 训练过程的平均损失
# ETA: 预计剩余训练时间, 因为已训练完成所以是0
Progress: 100.0% words/sec/thread: 60162 lr: 0.000000 avg.loss: 10.056812 ETA: 0h 0m 0s
Windows系统:
import fasttext
model = fasttext.train_supervised(input="cooking.train")
if __name__=="__main__":
model
打印结果:
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 39299 lr: 0.000000 avg.loss: 10.028418 ETA: 0h 0m 0s
4、第四步: 使用模型进行预测并评估
Linux系统:
# 使用模型预测一段输入文本, 通过我们常识, 可知预测是正确的, 但是对应预测概率并不大
>>> model.predict("Which baking dish is best to bake a banana bread ?")
# 元组中的第一项代表标签, 第二项代表对应的概率
(('__label__baking',), array([0.06550845]))
# 通过我们常识可知预测是错误的
>>> model.predict("Why not put knives in the dishwasher?")
(('__label__food-safety',), array([0.07541209]))
# 为了评估模型到底表现如何, 我们在3000条的验证集上进行测试
>>> model.test("cooking.valid")
# 元组中的每项分别代表, 验证集样本数量, 精度以及召回率
# 我们看到模型精度和召回率表现都很差, 接下来我们讲学习如何进行优化.
(3000, 0.124, 0.0541)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.train")
if __name__=="__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 14543
Number of labels: 735
Progress: 100.0% words/sec/thread: 41096 lr: 0.000000 avg.loss: 10.043181 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.06778254]))
predict_result02 = (('__label__food-safety',), array([0.0718687]))
test_result = (3000, 0.13733333333333334, 0.05939166786795445)
5、第五步:模型调优
5.1 原始数据处理
通过查看数据, 我们发现数据中存在许多标点符号与单词相连以及大小写不统一, 这些因素对我们最终的分类目标没有益处, 反是增加了模型提取分类规律的难度, 因此我们选择将它们去除或转化
处理前的部分数据:
__label__fish Arctic char available in North-America
__label__pasta __label__salt __label__boiling When cooking pasta in salted water how much of the salt is absorbed?
__label__coffee Emergency Coffee via Chocolate Covered Coffee Beans?
__label__cake Non-beet alternatives to standard red food dye
__label__cheese __label__lentils Could cheese "halt" the tenderness of cooking lentils?
__label__asian-cuisine __label__chili-peppers __label__kimchi __label__korean-cuisine What kind of peppers are used in Gochugaru ()?
__label__consistency Pavlova Roll failure
__label__eggs __label__bread What qualities should I be looking for when making the best French Toast?
__label__meat __label__flour __label__stews __label__braising Coating meat in flour before browning, bad idea?
__label__food-safety Raw roast beef on the edge of safe?
__label__pork __label__food-identification How do I determine the cut of a pork steak prior to purchasing it?
通过服务器终端进行简单的数据预处理:使标点符号与单词分离、统一使用小写字母【Windows系统可以使用Git Bash命令窗口,Git Bash命令窗口有sed 命令】:
>> cat cooking.stackexchange.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > cooking.preprocessed.txt
>> head -n 12404 cooking.preprocessed.txt > cooking.preprocessed.train
>> tail -n 3000 cooking.preprocessed.txt > cooking.preprocessed.valid
处理后的部分数据:
__label__fish arctic char available in north-america
__label__pasta __label__salt __label__boiling when cooking pasta in salted water how much of the salt is absorbed ?
__label__coffee emergency coffee via chocolate covered coffee beans ?
__label__cake non-beet alternatives to standard red food dye
__label__cheese __label__lentils could cheese "halt" the tenderness of cooking lentils ?
__label__asian-cuisine __label__chili-peppers __label__kimchi __label__korean-cuisine what kind of peppers are used in gochugaru ( ) ?
__label__consistency pavlova roll failure
__label__eggs __label__bread what qualities should i be looking for when making the best french toast ?
__label__meat __label__flour __label__stews __label__braising coating meat in flour before browning , bad idea ?
__label__food-safety raw roast beef on the edge of safe ?
__label__pork __label__food-identification how do i determine the cut of a pork steak prior to purchasing it ?
数据处理后进行训练并测试:
Linux系统:
# 重新训练
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train")
Read 0M words
# 不重复的词汇总数减少很多, 因为之前会把带大写字母或者与标点符号相连接的单词都认为是新的单词
Number of words: 8952
Number of labels: 735
# 我们看到平均损失有所下降
Progress: 100.0% words/sec/thread: 65737 lr: 0.000000 avg.loss: 9.966091 ETA: 0h 0m 0s
# 重新测试
>>> model.test("cooking.preprocessed.valid")
# 我们看到精度和召回率都有所提升
(3000, 0.161, 0.06962663975782038)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train")
if __name__=="__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 42495 lr: 0.000000 avg.loss: 9.988613 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.20235862]))
predict_result02 = (('__label__food-safety',), array([0.10484533]))
test_result = (3000, 0.16733333333333333, 0.07236557589736198)
5.2 增加训练轮数
设置train_supervised方法中的参数epoch来增加训练轮数, 默认的轮数是5次。
增加轮数意味着模型能够有更多机会在有限数据中调整分类规律, 当然这也会增加训练时间
Linux系统:
# 设置train_supervised方法中的参数epoch来增加训练轮数, 默认的轮数是5次
# 增加轮数意味着模型能够有更多机会在有限数据中调整分类规律, 当然这也会增加训练时间
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25)
Read 0M words
Number of words: 8952
Number of labels: 735
# 我们看到平均损失继续下降
Progress: 100.0% words/sec/thread: 66283 lr: 0.000000 avg.loss: 7.203885 ETA: 0h 0m 0s
>>> model.test("cooking.preprocessed.valid")
# 我们看到精度已经提升到了42%, 召回率提升至18%.
(3000, 0.4206666666666667, 0.1819230214790255)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25)
if __name__=="__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 43462 lr: 0.000000 avg.loss: 7.147898 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.58875704]))
predict_result02 = (('__label__equipment',), array([0.47682756]))
test_result = (3000, 0.519, 0.22444860890875018)
5.3 调整学习率
设置train_supervised方法中的参数lr来调整学习率, 默认的学习率大小是0.1。
增大学习率意味着增大了梯度下降的步长使其在有限的迭代步骤下更接近最优点
Linux系统:
# 设置train_supervised方法中的参数lr来调整学习率, 默认的学习率大小是0.1
# 增大学习率意味着增大了梯度下降的步长使其在有限的迭代步骤下更接近最优点
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train", lr=1.0, epoch=25)
Read 0M words
Number of words: 8952
Number of labels: 735
# 平均损失继续下降
Progress: 100.0% words/sec/thread: 66027 lr: 0.000000 avg.loss: 4.278283 ETA: 0h 0m 0s
>>> model.test("cooking.preprocessed.valid")
# 我们看到精度已经提升到了47%, 召回率提升至20%.
(3000, 0.47633333333333333, 0.20599682860025947)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25, lr=1.0)
if __name__=="__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 42748 lr: 0.000000 avg.loss: 4.222660 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.90052789]))
predict_result02 = (('__label__knives',), array([0.44448078]))
test_result = (3000, 0.5816666666666667, 0.2515496612368459)
5.4 增加n-gram特征
设置train_supervised方法中的参数wordNgrams来添加n-gram特征, 默认是1, 也就是没有n-gram特征
我们这里将其设置为2意味着添加2-gram特征, 这些特征帮助模型捕捉前后词汇之间的关联, 更好的提取分类规则用于模型分类, 当然这也会增加模型训时练占用的资源和时间.
Linux系统:
# 设置train_supervised方法中的参数wordNgrams来添加n-gram特征, 默认是1, 也就是没有n-gram特征
# 我们这里将其设置为2意味着添加2-gram特征, 这些特征帮助模型捕捉前后词汇之间的关联, 更好的提取分类规则用于模型分类, 当然这也会增加模型训时练占用的资源和时间.
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train", lr=1.0, epoch=25, wordNgrams=2)
Read 0M words
Number of words: 8952
Number of labels: 735
# 平均损失继续下降
Progress: 100.0% words/sec/thread: 65084 lr: 0.000000 avg.loss: 3.189422 ETA: 0h 0m 0s
>>> model.test("cooking.preprocessed.valid")
# 我们看到精度已经提升到了49%, 召回率提升至21%.
(3000, 0.49233333333333335, 0.2129162462159435)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25, lr=1.0, wordNgrams=2)
if __name__ == "__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 41833 lr: 0.000000 avg.loss: 3.114212 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.39613214]))
predict_result02 = (('__label__knives',), array([0.39759707]))
test_result = (3000, 0.601, 0.25991062418913075)
5.5 修改损失计算方式
随着我们不断的添加优化策略, 模型训练速度也越来越慢
为了能够提升fasttext模型的训练效率, 减小训练时间
设置train_supervised方法中的参数loss来修改损失计算方式(等效于输出层的结构), 默认是softmax层结构
我们这里将其设置为’hs’, 代表层次softmax结构, 意味着输出层的结构(计算方式)发生了变化, 将以一种更低复杂度的方式来计算损失.
Linux系统:
# 随着我们不断的添加优化策略, 模型训练速度也越来越慢
# 为了能够提升fasttext模型的训练效率, 减小训练时间
# 设置train_supervised方法中的参数loss来修改损失计算方式(等效于输出层的结构), 默认是softmax层结构
# 我们这里将其设置为'hs', 代表层次softmax结构, 意味着输出层的结构(计算方式)发生了变化, 将以一种更低复杂度的方式来计算损失.
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train", lr=1.0, epoch=25, wordNgrams=2, loss='hs')
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 1341740 lr: 0.000000 avg.loss: 2.225962 ETA: 0h 0m 0s
>>> model.test("cooking.preprocessed.valid")
# 我们看到精度和召回率稍有波动, 但训练时间却缩短到仅仅几秒
(3000, 0.483, 0.20887991927346114)
Window系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25, lr=1.0, wordNgrams=2, loss='hs')
if __name__ == "__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 863764 lr: 0.000000 avg.loss: 2.213320 ETA: 0h 0m 0s
predict_result01 = (('__label__baking',), array([0.38502374]))
predict_result02 = (('__label__knives',), array([0.47718713]))
test_result = (3000, 0.594, 0.256883378982269)
5.6 自动超参数调优
手动调节和寻找超参数是非常困难的, 因为参数之间可能相关, 并且不同数据集需要的超参数也不同,
因此可以使用fasttext的autotuneValidationFile参数进行自动超参数调优.
autotuneValidationFile参数需要指定验证数据集所在路径, 它将在验证集上使用随机搜索方法寻找可能最优的超参数.
使用autotuneDuration参数可以控制随机搜索的时间, 默认是300s, 根据不同的需求, 我们可以延长或缩短时间.
验证集路径’cooking.valid’, 随机搜索600秒
Linux系统:
# 手动调节和寻找超参数是非常困难的, 因为参数之间可能相关, 并且不同数据集需要的超参数也不同,
# 因此可以使用fasttext的autotuneValidationFile参数进行自动超参数调优.
# autotuneValidationFile参数需要指定验证数据集所在路径, 它将在验证集上使用随机搜索方法寻找可能最优的超参数.
# 使用autotuneDuration参数可以控制随机搜索的时间, 默认是300s, 根据不同的需求, 我们可以延长或缩短时间.
# 验证集路径'cooking.preprocessed.valid', 随机搜索600秒
>>> model = fasttext.train_supervised(input='cooking.preprocessed.train', autotuneValidationFile='cooking.preprocessed.valid', autotuneDuration=600)
Progress: 100.0% Trials: 38 Best score: 0.376170 ETA: 0h 0m 0s
Training again with best arguments
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 63791 lr: 0.000000 avg.loss: 1.888165 ETA: 0h 0m 0s
Window系统:
import fasttext
model = fasttext.train_supervised(input='cooking.preprocessed.train', autotuneValidationFile='cooking.preprocessed.valid', autotuneDuration=60) # 随机搜索600秒【默认300秒】
if __name__ == "__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?")
predict_result02 = model.predict("Why not put knives in the dishwasher?")
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
5.7 实际生产中多标签多分类问题的损失计算方式
针对多标签多分类问题, 使用’softmax’或者’hs’有时并不是最佳选择, 因为我们最终得到的应该是多个标签, 而softmax却只能最大化一个标签.
所以我们往往会选择为每个标签使用独立的二分类器作为输出层结构,
对应的损失计算方式为’ova’表示one vs all.
这种输出层的改变意味着我们在统一语料下同时训练多个二分类模型,
对于二分类模型来讲, lr不宜过大, 这里我们设置为0.2
Linux:
# 针对多标签多分类问题, 使用'softmax'或者'hs'有时并不是最佳选择, 因为我们最终得到的应该是多个标签, 而softmax却只能最大化一个标签.
# 所以我们往往会选择为每个标签使用独立的二分类器作为输出层结构,
# 对应的损失计算方式为'ova'表示one vs all.
# 这种输出层的改变意味着我们在统一语料下同时训练多个二分类模型,
# 对于二分类模型来讲, lr不宜过大, 这里我们设置为0.2
>>> model = fasttext.train_supervised(input="cooking.preprocessed.train", lr=0.2, epoch=25, wordNgrams=2, loss='ova')
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 65044 lr: 0.000000 avg.loss: 7.713312 ETA: 0h 0m 0s
我们使用模型进行单条样本的预测, 来看一下它的输出结果.
参数k代表指定模型输出多少个标签, 默认为1, 这里设置为-1, 意味着尽可能多的输出.
参数threshold代表显示的标签概率阈值, 设置为0.5, 意味着显示概率大于0.5的标签
# 我们使用模型进行单条样本的预测, 来看一下它的输出结果.
# 参数k代表指定模型输出多少个标签, 默认为1, 这里设置为-1, 意味着尽可能多的输出.
# 参数threshold代表显示的标签概率阈值, 设置为0.5, 意味着显示概率大于0.5的标签
>>> model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
可以看到根据输入文本, 输出了它的三个最有可能的标签
# 可以看到根据输入文本, 输出了它的三个最有可能的标签
((u'__label__baking', u'__label__bananas', u'__label__bread'), array([1.00000, 0.939923, 0.592677]))
Windows系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25, lr=0.2, wordNgrams=2, loss='ova')
if __name__ == "__main__":
model
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
predict_result02 = model.predict("Why not put knives in the dishwasher?", k=-1, threshold=0.01)
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
打印结果:
Read 0M words
Number of words: 8952
Number of labels: 735
Progress: 100.0% words/sec/thread: 37512 lr: 0.000000 avg.loss: 7.719700 ETA: 0h 0m 0s
predict_result01 = (('__label__baking', '__label__bread', '__label__equipment'), array([1.00001001, 0.99088436, 0.83974397]))
predict_result02 = (('__label__knives', '__label__equipment', '__label__utensils'), array([0.06372499, 0.06188598, 0.02229618]))
test_result = (3000, 0.597, 0.25818076978520976)
6、第六步: 模型保存与重加载
使用model的save_model方法保存模型到指定目录,你可以在指定目录下找到model_cooking.bin文件
使用fasttext的load_model进行模型的重加载
Linux:
# 使用model的save_model方法保存模型到指定目录
# 你可以在指定目录下找到model_cooking.bin文件
>>> model.save_model("./model_cooking.bin")
# 使用fasttext的load_model进行模型的重加载
>>> model = fasttext.load_model("./model_cooking.bin")
# 重加载后的模型使用方法和之前完全相同
>>> model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
((u'__label__baking', u'__label__bananas', u'__label__bread'), array([1.00000, 0.939923, 0.592677]))
Windows系统:
import fasttext
model = fasttext.train_supervised(input="cooking.preprocessed.train", epoch=25, lr=0.2, wordNgrams=2, loss='ova')
if __name__ == "__main__":
model
model.save_model("./model_cooking.bin") # 使用model的save_model方法保存模型到指定目录
model = fasttext.load_model("./model_cooking.bin") # 使用fasttext的load_model进行模型的重加载
predict_result01 = model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
predict_result02 = model.predict("Why not put knives in the dishwasher?", k=-1, threshold=0.01)
print("predict_result01 = {0}".format(predict_result01))
print("predict_result02 = {0}".format(predict_result02))
test_result = model.test("cooking.preprocessed.valid")
print("test_result = {0}".format(test_result))
三、训练词向量
用向量表示文本中的词汇(或字符)是现代机器学习中最流行的做法, 这些向量能够很好的捕捉语言之间的关系, 从而提升基于词向量的各种NLP任务的效果.
使用fasttext工具训练词向量的过程
- 第一步: 获取数据
- 第二步: 训练词向量
- 第三步: 模型超参数设定
- 第四步: 模型效果检验
- 第五步: 模型的保存与重加载
1、第一步: 获取训练数据
1.1 获取源数据
在这里, 我们将研究英语维基百科的部分网页信息, 它的大小在300M左右。
# 在这里, 我们将研究英语维基百科的部分网页信息, 它的大小在300M左右
# 这些语料已经被准备好, 我们可以通过Matt Mahoney的网站下载.
# 首先创建一个存储数据的文件夹data
$ mkdir data
# 使用wget下载数据的zip压缩包, 它将存储在data目录中
$ wget -c http://mattmahoney.net/dc/enwik9.zip -P data
# 使用unzip解压, 如果你的服务器中还没有unzip命令, 请使用: yum install unzip -y
# 解压后在data目录下会出现enwik9的文件夹
$ unzip data/enwik9.zip -d data
1.2 查看原始数据:
$ head -10 data/enwik9
# 原始数据将输出很多包含XML/HTML格式的内容, 这些内容并不是我们需要的
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.3/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.3/ http://www.mediawiki.org/xml/export-0.3.xsd" version="0.3" xml:lang="en">
<siteinfo>
<sitename>Wikipedia</sitename>
<base>http://en.wikipedia.org/wiki/Main_Page</base>
<generator>MediaWiki 1.6alpha</generator>
<case>first-letter</case>
<namespaces>
<namespace key="-2">Media</namespace>
<namespace key="-1">Special</namespace>
<namespace key="0" />
1.3 原始数据处理
wikifil.pl脚本:
#!/usr/bin/perl
# Program to filter Wikipedia XML dumps to "clean" text consisting only of lowercase
# letters (a-z, converted from A-Z), and spaces (never consecutive).
# All other characters are converted to spaces. Only text which normally appears
# in the web browser is displayed. Tables are removed. Image captions are
# preserved. Links are converted to normal text. Digits are spelled out.
# Written by Matt Mahoney, June 10, 2006. This program is released to the public domain.
$/=">"; # input record separator
while (<>) {
if (/) {
$text=1;} # remove all but between ...
if (/#redirect/i) {
$text=0;} # remove #REDIRECT
if ($text) {
# Remove any text not normally visible
if (/<\/text>/) {
$text=0;}
s/<.*>//; # remove xml tags
s/&/&/g; # decode URL encoded chars
s/</;
s/>/>/g;
s///g ; # remove references ...
s/<[^>]*>//g; # remove xhtml tags
s/\[http:[^] ]*/[/g; # remove normal url, preserve visible text
s/\|thumb//ig; # remove images links, preserve caption
s/\|left//ig;
s/\|right//ig;
s/\|\d+px//ig;
s/\[\[image:[^\[\]]*\|//ig;
s/\[\[category:([^|\]]*)[^]]*\]\]/[[$1]]/ig; # show categories without markup
s/\[\[[a-z\-]*:[^\]]*\]\]//g; # remove links to other languages
s/\[\[[^\|\]]*\|/[[/g; # remove wiki url, preserve visible text
s/\{\{[^\}]*\}\}//g; # remove {
{icons}} and {tables}
s/\{[^\}]*\}//g;
s/\[//g; # remove [ and ]
s/\]//g;
s/&[^;]*;/ /g; # remove URL encoded chars
# convert to lowercase letters and spaces, spell digits
$_=" $_ ";
tr/A-Z/a-z/;
s/0/ zero /g;
s/1/ one /g;
s/2/ two /g;
s/3/ three /g;
s/4/ four /g;
s/5/ five /g;
s/6/ six /g;
s/7/ seven /g;
s/8/ eight /g;
s/9/ nine /g;
tr/a-z/ /cs;
chop;
print $_;
}
}
使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容【Windows系统可以使用Git Bash命令窗口,Git Bash命令窗口perl命令】
# 使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容
$ perl wikifil.pl data/enwik9 > data/fil9
查看预处理后的数据:
# 查看前80个字符
head -c 80 data/fil9
# 输出结果为由空格分割的单词
anarchism originated as a term of abuse first used against early working class
2、第二步: 训练词向量
使用fasttext的train_unsupervised(无监督训练方法)进行词向量的训练,它的参数是数据集的持久化文件路径’data/fil9’。
Linux系统:
# 代码运行在python解释器中
# 导入fasttext
>>> import fasttext
# 使用fasttext的train_unsupervised(无监督训练方法)进行词向量的训练
# 它的参数是数据集的持久化文件路径'data/fil9'
>>> model = fasttext.train_unsupervised('data/fil9')
# 有效训练词汇量为124M, 共218316个单词
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 53996 lr: 0.000000 loss: 0.734999 ETA: 0h 0m
查看单词对应的词向量:
# 通过get_word_vector方法来获得指定词汇的词向量
>>> model.get_word_vector("the")
array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,
0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,
...
-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],
dtype=float32)
Windows系统:
import fasttext
model = fasttext.train_unsupervised('data/fil9')
if __name__ == "__main__":
model
vector_of_the = model.get_word_vector("the")
print("vector_of_the = \n{0}".format(vector_of_the))
打印结果:
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 28466 lr: 0.000000 avg.loss: 0.619826 ETA: 0h 0m 0s
vector_of_the =
[-0.09176216 -0.05832345 0.0191018 0.11178942 -0.01712495 -0.34625632
-0.09929453 0.05793274 -0.19560948 -0.25466377 0.0252221 -0.03766044
-0.08714669 0.02594473 -0.22714391 0.3556243 -0.16054079 -0.32303935
-0.02460975 -0.10192005 0.10686079 -0.19614927 0.04507151 -0.07510009
-0.03644683 -0.3675648 -0.14031157 0.03368374 0.06287843 0.32430416
0.14121428 -0.17357464 0.18931322 -0.14820297 0.08563495 0.16823296
0.05046154 -0.2144276 0.02580023 -0.18719815 0.17053135 -0.19649449
-0.11190141 -0.39764288 -0.04434433 -0.0673959 0.02062983 0.0260213
-0.02527183 -0.10407501 -0.17223638 -0.10144253 0.15879004 -0.36408037
-0.04893739 -0.06658145 -0.62139446 -0.10785068 -0.02135039 0.28785816
-0.18697593 -0.0986968 0.08008742 0.32631087 0.07539485 0.08220806
-0.19432037 -0.14406013 -0.07266578 0.1243678 -0.08104107 0.24794671
-0.04169198 0.03104601 -0.35601816 0.06507382 -0.1291676 -0.0833559
0.24631317 0.15177608 0.37756354 -0.20903172 0.0110182 0.0871611
0.44552273 -0.19934641 0.10094192 0.00813372 -0.16169298 0.30151305
-0.08831821 -0.34397462 -0.2149849 -0.16884513 0.05650288 -0.20579952
-0.16272669 -0.03395516 0.1753662 -0.3416498 ]
3、第三步: 模型超参数设定
在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
- 无监督训练模式: ‘skipgram’ 或者 ‘cbow’, 默认为’skipgram’, 在实践中,skipgram模式在利用子词方面比cbow更好.
- 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大【维度越大,抽取的特征越多,表征能力越强】.
- 数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次.
- 学习率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内.
- 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.
# 在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
# 无监督训练模式: 'skipgram' 或者 'cbow', 默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好.
# 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大.
# 数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次.
# 学习率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内.
# 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.
>>> model = fasttext.train_unsupervised('data/fil9', "cbow", dim=300, epoch=1, lr=0.1, thread=8)
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 49523 lr: 0.000000 avg.loss: 1.777205 ETA: 0h 0m 0s
4、第四步: 模型效果检验
检查单词向量质量的一种简单方法就是查看其邻近单词, 通过我们主观来判断这些邻近单词是否与目标单词相关来粗略评定模型效果好坏。
- 查找"运动"的邻近单词, 我们可以发现"体育网", “运动汽车”, "运动服"等.
- 查找"音乐"的邻近单词, 我们可以发现与音乐有关的词汇.
- 查找"小狗"的邻近单词, 我们可以发现与小狗有关的词汇.
# 检查单词向量质量的一种简单方法就是查看其邻近单词, 通过我们主观来判断这些邻近单词是否与目标单词相关来粗略评定模型效果好坏.
# 查找"运动"的邻近单词, 我们可以发现"体育网", "运动汽车", "运动服"等.
>>> model.get_nearest_neighbors('sports')
[(0.8414610624313354, 'sportsnet'), (0.8134572505950928, 'sport'), (0.8100415468215942, 'sportscars'), (0.8021156787872314, 'sportsground'), (0.7889881134033203, 'sportswomen'), (0.7863013744354248, 'sportsplex'), (0.7786710262298584, 'sporty'), (0.7696356177330017, 'sportscar'), (0.7619683146476746, 'sportswear'), (0.7600985765457153, 'sportin')]
# 查找"音乐"的邻近单词, 我们可以发现与音乐有关的词汇.
>>> model.get_nearest_neighbors('music')
[(0.8908010125160217, 'emusic'), (0.8464668393135071, 'musicmoz'), (0.8444250822067261, 'musics'), (0.8113634586334229, 'allmusic'), (0.8106718063354492, 'musices'), (0.8049437999725342, 'musicam'), (0.8004694581031799, 'musicom'), (0.7952923774719238, 'muchmusic'), (0.7852965593338013, 'musicweb'), (0.7767147421836853, 'musico')]
# 查找"小狗"的邻近单词, 我们可以发现与小狗有关的词汇.
>>> model.get_nearest_neighbors('dog')
[(0.8456876873970032, 'catdog'), (0.7480780482292175, 'dogcow'), (0.7289096117019653, 'sleddog'), (0.7269964218139648, 'hotdog'), (0.7114801406860352, 'sheepdog'), (0.6947550773620605, 'dogo'), (0.6897546648979187, 'bodog'), (0.6621081829071045, 'maddog'), (0.6605004072189331, 'dogs'), (0.6398137211799622, 'dogpile')]
5、第五步: 模型的保存与重加载
使用save_model保存模型;使用fasttext.load_model加载模型
# 使用save_model保存模型
>>> model.save_model("fil9.bin")
# 使用fasttext.load_model加载模型
>>> model = fasttext.load_model("fil9.bin")
>>> model.get_word_vector("the")
array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874,
0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221,
...
-0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143],
dtype=float32)
四、词向量模型迁移(直接拿别人已经训练好的词向量模型来使用)
词向量迁移:在自己的项目中直接使用别人在大型语料库上已经进行训练完成的词向量模型。
fasttext工具中可以提供的可迁移的词向量
- fasttext提供了157种语言 的在CommonCrawl & Wikipedia 语料上进行训练的可迁移词向量模型
- 它们采用CBOW模式进行训练, 词向量维度为300维.
- 可通过该地址查看具体语言词向量模型: https://fasttext.cc/docs/en/crawl-vectors.html
- fasttext提供了 294种语言 的在 Wikipedia 语料上进行训练的可迁移词向量模型
- 它们采用skipgram模式进行训练, 词向量维度同样是300维.
- 可通过该地址查看具体语言词向量模型: https://fasttext.cc/docs/en/pretrained-vectors.html
如何使用fasttext进行词向量模型迁移
- 第一步: 下载词向量模型压缩的bin.gz文件
- 第二步: 解压bin.gz文件到bin文件
- 第三步: 加载bin文件获取词向量
- 第四步: 利用邻近词进行效果检验
import fasttext
if __name__ == "__main__":
pretrained_model = fasttext.load_model("cc.zh.300.bin")
print("pretrained_model.words[:100] = {0}".format(pretrained_model.words[:100]))
vector_of_the = pretrained_model.get_word_vector("the")
print("vector_of_the = {0}".format(vector_of_the))
print('model.get_nearest_neighbors("音乐") ={0}'.format(pretrained_model.get_nearest_neighbors("音乐")))
print('model.get_nearest_neighbors("美术") ={0}'.format(pretrained_model.get_nearest_neighbors("美术")))
print('model.get_nearest_neighbors("周杰伦") ={0}'.format(pretrained_model.get_nearest_neighbors("周杰伦")))
打印结果:
pretrained_model.words[:100] = [',', '的', '。', '', '、', '是', '一', '在', ':', '了', '(', ')', "'", '和', '不', '有', '我', ',', ')', '(', '“', '”', '也', '人', '个', ':', '中', '.', '就', '他', '》', '《', '-', '你', '都', '上', '大', '!', '这', '为', '多', '与', '章', '「', '到', '」', '要', '?', '被', '而', '能', '等', '可以', '年', ';', '|', '以', '及', '之', '公司', '对', '中国', '很', '会', '小', '但', '我们', '最', '更', '/', '1', '三', '新', '自己', '可', '2', '或', '次', '好', '将', '第', '种', '她', '…', '3', '地', '對', '用', '工作', '下', '后', '由', '两', '使用', '还', '又', '您', '?', '其', '已']
vector_of_the = [ 2.83299554e-02 2.33187713e-03 1.36764288e-01 7.39692524e-02
1.39168892e-02 7.82695115e-02 1.11727618e-01 -3.16218287e-02
-1.27780810e-01 1.27872340e-02 -2.55014189e-02 9.86402156e-04
-1.46241095e-02 -3.54048721e-02 -2.51251012e-02 -4.44358587e-02
-3.31990421e-02 1.90696735e-02 2.03274831e-01 2.08707899e-03
-6.40445203e-02 -2.61098724e-02 2.64394730e-02 2.51781847e-03
-8.10158625e-02 1.46124065e-01 -1.30163193e-01 -1.76550075e-02
1.04698185e-02 -4.77032922e-02 1.81796253e-02 8.46806318e-02
-9.96279567e-02 -5.86302988e-02 3.07471212e-03 5.06289788e-02
-5.73958270e-03 -9.23708528e-02 9.22054797e-02 2.19214763e-02
-3.18841916e-03 1.29185403e-02 -5.14824204e-02 -9.69366822e-03
-4.36747000e-02 -2.64506638e-02 2.69500576e-02 -1.92980543e-02
-5.92812970e-02 -2.34292485e-02 -3.96108069e-02 8.11716355e-03
-2.70715877e-02 -4.85226035e-01 1.13693830e-02 -4.00817096e-02
-3.62500921e-02 1.03012323e-02 2.00460535e-02 7.57535547e-02
-2.93635912e-02 -5.78514338e-02 1.89056285e-02 5.00109643e-02
2.99260169e-02 -1.63752586e-04 -6.97084814e-02 -1.55530507e-02
1.37065388e-02 -2.81840190e-03 3.19729336e-02 -2.30297670e-02
-9.33173764e-03 5.09245973e-03 -2.20647827e-01 3.14267501e-02
2.31536720e-02 -1.25775225e-02 -3.07837166e-02 4.48456630e-02
4.90459427e-02 2.88263671e-02 -1.46270916e-03 3.98606062e-02
-5.58197964e-04 2.96456888e-02 -8.34255200e-03 -2.62771808e-02
8.20593089e-02 9.42407027e-02 5.77388704e-02 2.56576929e-02
-1.55801326e-02 -3.88855897e-02 -7.70438183e-03 2.44518295e-02
-5.14636515e-03 1.07458197e-01 5.57008162e-02 -1.00818677e-02
1.30714089e-01 -7.65488669e-03 1.72294080e-02 -9.52566862e-02
-1.74345136e-01 -1.49983019e-02 3.26392502e-02 8.36990122e-03
-2.21034363e-02 4.80376706e-02 7.73724914e-03 2.04776525e-02
1.26936346e-01 3.98457795e-03 -1.74200051e-02 -2.64329687e-02
6.60122652e-03 -4.61578965e-02 -1.65160298e-02 -3.72875556e-02
3.46623994e-02 -4.33888361e-02 2.64325179e-02 -1.42425057e-02
4.48260754e-02 -2.91653462e-02 -1.24630053e-02 5.07909525e-03
4.69027553e-04 2.85666212e-02 1.31365359e-01 2.68803909e-02
-4.89150397e-02 5.25267422e-03 -4.81516495e-02 -1.65925361e-02
1.28320344e-02 -2.18593851e-02 -4.89627905e-02 -4.81087193e-02
-3.09242383e-02 -4.90602478e-03 2.20398009e-01 3.15981768e-02
-1.73793718e-01 3.35136130e-02 -7.38247931e-02 -7.54843503e-02
-3.76006737e-02 -2.23829132e-02 1.07085824e-01 7.46346544e-03
5.07014617e-03 -2.25644708e-02 -5.85216377e-03 -1.22892344e-02
2.40955576e-02 -3.86240054e-03 -1.01518603e-02 7.64382109e-02
-1.54113602e-02 4.95404610e-03 8.94018356e-03 -5.41297998e-03
2.80214027e-02 2.75027677e-02 1.36028007e-02 -1.02453306e-02
-1.56776533e-02 4.14362960e-02 2.66471449e-02 8.14858638e-03
-7.20718876e-02 3.23500484e-03 -3.09573207e-02 8.08387436e-03
6.25490583e-03 -4.16759960e-03 2.01017316e-03 -6.50798380e-02
2.32797023e-02 -1.67584419e-01 2.04147794e-03 -2.19203550e-02
-2.53692493e-02 -2.05096379e-01 3.39250080e-02 -3.54752317e-02
7.10167512e-02 -3.19727883e-02 -4.80146445e-02 -4.67859767e-02
-4.09557298e-03 2.40184236e-02 -3.27165946e-02 -8.00134800e-03
8.29899311e-03 -5.47821671e-02 -1.70383453e-02 1.68768466e-01
-3.27380262e-02 -5.22904564e-03 -5.12977242e-02 5.12947142e-03
5.25860973e-02 -3.67032215e-02 -1.80079862e-02 7.39449337e-02
6.03070073e-02 5.81426993e-02 -5.48052602e-03 -4.11980748e-02
3.69645469e-03 3.09765153e-02 2.12551057e-02 4.11658399e-02
-8.31688195e-03 5.36505226e-03 6.02733903e-02 -3.92289162e-02
-9.13495198e-03 3.12871113e-03 4.61774766e-02 -3.43044810e-02
-3.56039144e-02 -9.29420162e-03 1.35901235e-02 9.88295674e-03
-4.70753685e-02 -5.17600179e-02 -6.27560318e-02 3.64909828e-01
-1.30512249e-02 8.73684138e-02 9.34837759e-03 3.16907354e-02
1.66677907e-02 -2.23183818e-03 5.98338619e-03 4.94831204e-02
5.29364310e-02 -1.73280649e-02 3.16320881e-02 1.61211286e-02
6.31420910e-02 7.47584831e-03 -3.43635529e-02 1.00579355e-02
4.26177345e-02 -1.11310348e-01 -4.70249215e-03 1.52847636e-02
3.36849615e-02 3.68684754e-02 9.62911546e-03 4.61199507e-02
3.60683538e-03 -9.67130214e-02 3.21644321e-02 8.00635964e-02
-2.44498193e-01 -3.56191304e-03 3.03447880e-02 6.60906285e-02
-3.79791111e-03 1.17770676e-02 -2.35124715e-02 -4.82241549e-02
7.70387948e-02 2.66050138e-02 -1.44300358e-02 -3.95540521e-02
-7.86118582e-03 -1.43535435e-04 4.50247414e-02 -7.23173395e-02
-1.02583416e-01 -2.48780474e-03 -3.63161378e-02 5.28936274e-03
-5.11447713e-02 1.72110915e-01 4.28471230e-02 6.32201582e-02
-2.63313837e-02 2.38881968e-02 -2.01566219e-02 1.69124268e-02
-6.05482562e-03 -8.04027021e-02 2.81601809e-02 3.19189299e-03
-1.32810632e-02 5.33408336e-02 -6.09975755e-02 -2.46565342e-02
2.23067477e-02 1.94031838e-03 -2.57408153e-02 -8.26434698e-03]
model.get_nearest_neighbors("音乐") =[(0.6703276634216309, '乐曲'), (0.6569967269897461, '音乐人'), (0.6565821170806885, '声乐'), (0.6557438373565674, '轻音乐'), (0.6536258459091187, '音乐家'), (0.6502416133880615, '配乐'), (0.6501686573028564, '艺术'), (0.6437276005744934, '音乐会'), (0.639589250087738, '原声'), (0.6368917226791382, '音响')]
model.get_nearest_neighbors("美术") =[(0.724744975566864, '艺术'), (0.7165924310684204, '绘画'), (0.6741853356361389, '霍廷霄'), (0.6470299363136292, '纯艺'), (0.6335071921348572, '美术家'), (0.6304370164871216, '美院'), (0.624431312084198, '艺术类'), (0.6244068741798401, '陈浩忠'), (0.62302166223526, '美术史'), (0.621710479259491, '环艺系')]
model.get_nearest_neighbors("周杰伦") =[(0.6995140910148621, '杰伦'), (0.6967097520828247, '周杰倫'), (0.6859776377677917, '周董'), (0.6381043195724487, '陈奕迅'), (0.6367626190185547, '张靓颖'), (0.6313326358795166, '张韶涵'), (0.6271176338195801, '谢霆锋'), (0.6188404560089111, '周华健'), (0.6184280514717102, '林俊杰'), (0.6143589019775391, '王力宏')]
1、第一步: 下载词向量模型压缩的bin.gz文件
下载 “在CommonCrawl和Wikipedia语料上已经训练好的中文词向量模型” 文件 cc.zh.300.bin.gz【大小:4.17GB】。
# 这里我们以迁移在CommonCrawl和Wikipedia语料上进行训练的中文词向量模型为例:
# 下载中文词向量模型(bin.gz文件)
wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.bin.gz
2、第二步: 解压bin.gz文件到bin文件
使用gunzip进行解压, 获取cc.zh.300.bin文件
# 使用gunzip进行解压, 获取cc.zh.300.bin文件
gunzip cc.zh.300.bin.gz
3、第三步: 加载bin文件获取词向量
直接加载 “cc.zh.300.bin” 词向量模型文件即可使用。
# 加载模型
>>> model = fasttext.load_model("cc.zh.300.bin")
# 查看前100个词汇(这里的词汇是广义的, 可以是中文符号或汉字))
>>> model.words[:100]
[',', '的', '。', '', '、', '是', '一', '在', ':', '了', '(', ')', "'", '和', '不', '有', '我', ',', ')', '(', '“', '”', '也', '人', '个', ':', '中', '.', '就', '他', '》', '《', '-', '你', '都', '上', '大', '!', '这', '为', '多', '与', '章', '「', '到', '」', '要', '?', '被', '而', '能', '等', '可以', '年', ';', '|', '以', '及', '之', '公司', '对', '中国', '很', '会', '小', '但', '我们', '最', '更', '/', '1', '三', '新', '自己', '可', '2', '或', '次', '好', '将', '第', '种', '她', '…', '3', '地', '對', '用', '工作', '下', '后', '由', '两', '使用', '还', '又', '您', '?', '其', '已']
# 使用模型获得'音乐'这个名词的词向量
>>> model.get_word_vector("音乐")
array([-6.81843981e-02, 3.84048335e-02, 4.63239700e-01, 6.11658543e-02,
9.38086119e-03, -9.63955745e-02, 1.28141120e-01, -6.51574507e-02,
...
3.13430429e-02, -6.43611327e-02, 1.68979481e-01, -1.95011273e-01],
dtype=float32)
4、第四步: 利用邻近词进行效果检验
以’音乐’为例, 返回的邻近词基本上与音乐都有关系, 如乐曲, 音乐会, 声乐等.
# 以'音乐'为例, 返回的邻近词基本上与音乐都有关系, 如乐曲, 音乐会, 声乐等.
>>> model.get_nearest_neighbors("音乐")
[(0.6703276634216309, '乐曲'), (0.6569967269897461, '音乐人'), (0.6565821170806885, '声乐'), (0.6557438373565674, '轻音乐'), (0.6536258459091187, '音乐家'), (0.6502416133880615, '配乐'), (0.6501686573028564, '艺术'), (0.6437276005744934, '音乐会'), (0.639589250087738, '原声'), (0.6368917226791382, '音响')]
以’美术’为例, 返回的邻近词基本上与美术都有关系, 如艺术, 绘画, 霍廷霄(满城尽带黄金甲的美术师)等.
# 以'美术'为例, 返回的邻近词基本上与美术都有关系, 如艺术, 绘画, 霍廷霄(满城尽带黄金甲的美术师)等.
>>> model.get_nearest_neighbors("美术")
[(0.724744975566864, '艺术'), (0.7165924310684204, '绘画'), (0.6741853356361389, '霍廷霄'), (0.6470299363136292, '纯艺'), (0.6335071921348572, '美术家'), (0.6304370164871216, '美院'), (0.624431312084198, '艺术类'), (0.6244068741798401, '陈浩忠'), (0.62302166223526, '美术史'), (0.621710479259491, '环艺系')]
以’周杰伦’为例, 返回的邻近词基本上与明星有关系, 如杰伦, 周董, 陈奕迅等.
# 以'周杰伦'为例, 返回的邻近词基本上与明星有关系, 如杰伦, 周董, 陈奕迅等.
>>> model.get_nearest_neighbors("周杰伦")
[(0.6995140910148621, '杰伦'), (0.6967097520828247, '周杰倫'), (0.6859776377677917, '周董'), (0.6381043195724487, '陈奕迅'), (0.6367626190185547, '张靓颖'), (0.6313326358795166, '张韶涵'), (0.6271176338195801, '谢霆锋'), (0.6188404560089111, '周华健'), (0.6184280514717102, '林俊杰'), (0.6143589019775391, '王力宏')]
参考资料:
fastText/elmo/bert对比
nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert