mybatis 取出转string_MyBatis:一发入魂

MyBatis是什么?
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
它是一款半自动的ORM持久层框架,具有较高的SQL灵活性,支持高级映射(一对一,一对多),动态SQL,延迟加载和缓存等特性,但它的数据库无关性较低
- 什么是ORM?
Object Relation Mapping,对象关系映射。对象指的是Java对象,关系指的是数据库中的关系模型,对象关系映射,指的就是在Java对象和数据库的关系模型之间建立一种对应关系,比如用一个Java的Student类,去对应数据库中的一张student表,类中的属性和表中的列一一对应。Student类就对应student表,一个Student对象就对应student表中的一行数据 - 为什么mybatis是半自动的ORM框架?
用mybatis进行开发,需要手动编写SQL语句。而全自动的ORM框架,如hibernate,则不需要编写SQL语句。用hibernate开发,只需要定义好ORM映射关系,就可以直接进行CRUD操作了。由于mybatis需要手写SQL语句,所以它有较高的灵活性,可以根据需要,自由地对SQL进行定制,也因为要手写SQL,当要切换数据库时,SQL语句可能就要重写,因为不同的数据库有不同的方言(Dialect),所以mybatis的数据库无关性低。虽然mybatis需要手写SQL,但相比JDBC,它提供了输入映射和输出映射,可以很方便地进行SQL参数设置,以及结果集封装。并且还提供了关联查询和动态SQL等功能,极大地提升了开发的效率。并且它的学习成本也比hibernate低很多
MyBatis官方网站:
mybatismybatis.org以下文章较长请注意:
需要入门MyBatis的小伙伴不妨看一下这个视频,可以帮助你们:
知乎视频www.zhihu.comMybatis全套视频:【Java小黑马】2021年-MyBatis全套最新课程_MyBatisPlus入门到精通一站式讲解_MyBatis入门/MyBatis精讲/Mybatis实战_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
一:作用域(Scope)和生命周期
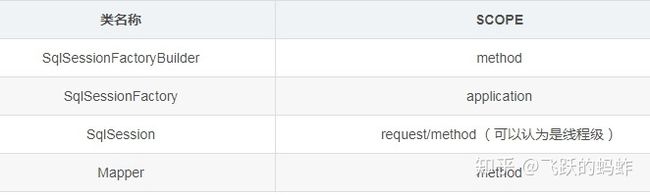
二:Mybatis config文件:
1.TypeAliases 类型别名是为 Java 类型设置一个短的名字。它只和 XML 配置有关,存在的意义仅在于用来减少类完全限定名的冗余。例如:
2.typeHandlers:
无论是 MyBatis在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时, 都会用类型处理器将获取的值以合适的方式转换成 Java 类型。
你可以重写类型处理器或创建你自己的类型处理器来处理不支持的或非标准的类型。 具体做法为:实现 org.apache.ibatis.type.TypeHandler 接口, 或继承一个很便利的类 org.apache.ibatis.type.BaseTypeHandler, 然后可以选择性地将它映射到一个 JDBC 类型。比如:
@MappedJdbcTypes(JdbcType.VARCHAR)
public class JunliTypeHandler extends BaseTypeHandler {
@Override
public void setNonNullParameter(PreparedStatement preparedStatement, int i, String s, JdbcType jdbcType) throws SQLException {
preparedStatement.setString(i, s + "LIJUN");
}
@Override
public String getNullableResult(ResultSet resultSet, String s) throws SQLException {
return resultSet.getString(s)+"LIJUN";
}
@Override
public String getNullableResult(ResultSet resultSet, int i) throws SQLException {
return resultSet.getString(i);
}
@Override
public String getNullableResult(CallableStatement callableStatement, int i) throws SQLException {
return callableStatement.getString(i);
}
}
@MappedJdbcTypes(JdbcType.VARCHAR) 使用这个的类型处理器将会覆盖已经存在的处理 Java 的 String 类型属性和 VARCHAR 参数及结果的类型处理器。preparedStatement.setString(i, s + “LIJUN”); 表示在所有String类型后面加上 LIJUN 但是有时候我们只是想特定的字段加上LIJUN。可以如下配置(mybatis-config.xml 就不需要了):
//插入
insert into test (id, nums, name
)
values (#{
id,jdbcType=INTEGER}, #{
nums,jdbcType=INTEGER}, #{
name,jdbcType=VARCHAR,typeHandler=com.junli.mybatis.demo.mybatis.JunliTypeHandler}
)
//返回
3.插件(plugins)
MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
- Executor (update, query, flushStatements, commit, rollback,getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
下面通过自定义插件来打印出查询的sql语句:
@Intercepts({
@Signature(type = Executor.class,
method = "query",
args = {
MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})})
public class JunliPlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
BoundSql boundSql = mappedStatement.getBoundSql(invocation.getArgs()[1]);
System.out.println(String.format("plugin output sql = %s , param=%s", boundSql.getSql(),boundSql.getParameterObject()));
return invocation.proceed();
}
@Override
public Object plugin(Object o) {
return Plugin.wrap(o,this);
}
@Override
public void setProperties(Properties properties) {
}配置插件:
4.映射器(mappers)
既然 MyBatis 的行为已经由上述元素配置完了,我们现在就要定义 SQL 映射语句了。但是首先我们需要告诉 MyBatis 到哪里去找到这些语句。 Java 在自动查找这方面没有提供一个很好的方法,所以最佳的方式是告诉 MyBatis 到哪里去找映射文件。你可以使用相对于类路径的资源引用, 或完全限定资源定位符(包括 file:/// 的 URL),或类名和包名等。例如:
三、Mapper XML 文件 解读
MyBatis 的真正强大在于它的映射语句,也是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 就是针对 SQL 构建的,并且比普通的方法做的更好。
SQL映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
- cache – 给定命名空间的缓存配置。
- cache-ref – 其他命名空间缓存配置的引用。
- resultMap
- – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
主要说一下resultMap
resultMap 元素有很多子元素和一个值得讨论的结构。
resultMap
- constructor - 用于在实例化类时,注入结果到构造方法中
idArg - ID 参数;标记出作为 ID 的结果可以帮助提高整体性能
arg - 将被注入到构造方法的一个普通结果 - id – 一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能
- result – 注入到字段或 JavaBean 属性的普通结果
- association – 一个复杂类型的关联;许多结果将包装成这种类型
- 嵌套结果映射 – 关联可以指定为一个 resultMap 元素,或者引用一个
- collection – 一个复杂类型的集合嵌套结果映射 – 集合可以指定为一个 resultMap 元素,或者引用一个
- discriminator – 使用结果值来决定使用哪个 resultMap.
resultMap 关联查询.
关联查询分为两种: - 关联的嵌套查询
例子:
我们有两个查询语句:一个来加载博客,另外一个来加载作者,而且博客的结果映射描 述了“BaseResultMap_Author”语句应该被用来加载它的 author 属性。
其他所有的属性将会被自动加载,假设它们的列和属性名相匹配。
这种方式很简单, 但是对于大型数据集合和列表将不会表现很好。 问题就是我们熟知的 “N+1 查询问题”。概括地讲,N+1 查询问题可以是这样引起的:1. 你执行了一个单独的 SQL 语句来获取结果列表(就是“+1”)。
2. 对返回的每条记录,你执行了一个查询语句来为每个加载细节(就是“N”)。
这个问题会导致成百上千的 SQL 语句被执行。这通常不是期望的。
MyBatis 能延迟加载这样的查询就是一个好处,因此你可以分散这些语句同时运行的消 耗。然而,如果你加载一个列表,之后迅速迭代来访问嵌套的数据,你会调用所有的延迟加 载,这样的行为可能是很糟糕的。所以还有另外一种方法。
- 关联的嵌套结果
重新上面的例子
集合的嵌套查询
我们来继续上面的示例,一个博客只有一个作者。但是博客有很多文章。在博客类中, 这可以由下面这样的写法来表示:
private List posts; 实例:
集合的嵌套结果实现:
缓存:Mybatis中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存是指SqlSession级别的缓存,当在同一个SqlSession中进行相同的SQL语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存1024条SQL。二级缓存是指可以跨SqlSession的缓存。
Mybatis中进行SQL查询是通过org.apache.ibatis.executor.Executor接口进行的,总体来讲,它一共有两类实现,一类是BaseExecutor,一类是CachingExecutor。前者是非启用二级缓存时使用的,而后者是采用的装饰器模式,在启用了二级缓存时使用,当二级缓存没有命中时,底层还是通过BaseExecutor来实现的。
- 一级缓存
一级缓存是默认启用的,在BaseExecutor的query()方法中实现,底层默认使用的是PerpetualCache实现,PerpetualCache采用HashMap存储数据。一级缓存会在进行增、删、改操作时进行清除。 - 二级缓存
二级缓存是默认启用的,如想取消,则可以通过Mybatis配置文件中的元素下的子元素来指定cacheEnabled为false。
我们要想使用二级缓存,是需要在对应的Mapper.xml文件中定义其中的查询语句需要使用哪个cache来缓存数据的。这有两种方式可以定义,一种是通过cache元素定义,一种是通过cache-ref元素来定义。但是需要注意的是对于同一个Mapper来讲,它只能使用一个Cache,当同时使用了和时使用定义的优先级更高。Mapper使用的Cache是与我们的Mapper对应的namespace绑定的,一个namespace最多只会有一个Cache与其绑定。
- 自定义cache
前面提到Mybatis的Cache默认会使用PerpetualCache存储数据,如果我们不想按照它的逻辑实现,或者我们想使用其它缓存框架来实现,比如使用Ehcache、Redis等,这个时候我们就可以使用自己的Cache实现,Mybatis是给我们留有对应的接口,允许我们进行自定义的。要想实现自定义的Cache我们必须定义一个自己的类来实现Mybatis提供的Cache接口,实现对应的接口方法。
**
* 自定义缓存
*/
public class JunliCache implements Cache {
private ReadWriteLock lock = new ReentrantReadWriteLock();
private ConcurrentHashMap cache = new ConcurrentHashMap();
private String id;
public JunliCache() {
System.out.println("初始化-1!");
}
/**
* 必须有该构造函数
*/
public JunliCache(String id) {
System.out.println("初始化-2!");
this.id = id;
}
/**
* 获取缓存编号
*/
@Override
public String getId() {
System.out.println("得到ID:" + id);
return id;
}
/***
* 获取缓存对象的大小
* @return int
*/
@Override
public int getSize() {
System.out.println("获取缓存大小!");
return 0;
}
/**
* 保存key值缓存对象
*
* @param key key
* @param value value
*/
@Override
public void putObject(Object key, Object value) {
System.out.println("往缓存中添加元素:key=" + key + ",value=" + value);
cache.put(key, value);
}
/**
* 通过KEY
*
* @param key key
* @return Object
*/
@Override
public Object getObject(Object key) {
System.out.println("通过kEY获取值:" + key);
System.out.println("OVER");
System.out.println("=======================================================");
System.out.println("值为:" + cache.get(key));
System.out.println("=====================OVER==============================");
return cache.get(key);
}
/**
* 通过key删除缓存对象
*
* @param key key
* @return
*/
@Override
public Object removeObject(Object key) {
System.out.println("移除缓存对象:" + key);
return null;
}
/**
* 清空缓存
*/
@Override
public void clear() {
System.out.println("清除缓存!");
cache.clear();
}
/**
* 获取缓存的读写锁
*
* @return ReadWriteLock
*/
@Override
public ReadWriteLock getReadWriteLock() {
System.out.println("获取锁对象!!!");
return lock;
}
} 四、动态 SQL
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似.MyBatis 采用功能强大的基于 OGNL 的表达式来淘汰其它大部分元素。
- if
AND title like #{
title}
- choose (when, otherwise)
AND title like #{
title}
AND author_name like #{
author.name}
AND featured = 1
- trim (where, set)
state = #{
state}
AND title like #{
title}
AND author_name like #{
author.name}
...
username=#{
username},
password=#{
password},
email=#{
email},
bio=#{
bio}
- foreach
#{
item}
文章转载自:mokingone的专栏_mokingone_CSDN博客-spring,设计模式,设计模式领域博主
最后:小伙伴有需要学习MyBatis 同学,打开下方链接观看学习;
【Java小黑马】2021年-MyBatis全套最新课程_MyBatisPlus入门到精通一站式讲解_MyBatis入门/MyBatis精讲/Mybatis实战_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
更多编程视频:https://space.bilibili.com/602384997