T r a n s f o r m e r 实 现 英 译 中 机 器 翻 译 Transformer实现英译中机器翻译 Transformer实现英译中机器翻译
import os
import time
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from pprint import pprint
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
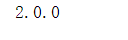
import pandas as pd
train = pd.read_csv("./nmt/news-commentary-v14.en-zh.tsv",error_bad_lines=False,sep='\t',header=None)
train.head()

train_df = train.iloc[:280000]
val_df = train.iloc[280000:]
val_df.shape
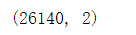
with tf.io.TFRecordWriter('./nmt/train.tfrecord') as writer:
for en, zh in train_df.values:
try:
feature = {
'en': tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(en)])),
'zh': tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(zh)]))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
except:
pass
with tf.io.TFRecordWriter('./nmt/valid.tfrecord') as writer:
for en, zh in val_df.values:
try:
feature = {
'en': tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(en)])),
'zh': tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(zh)]))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
except:
pass
feature_description = {
'en': tf.io.FixedLenFeature([], tf.string),
'zh': tf.io.FixedLenFeature([], tf.string),
}
def _parse_example(example_string):
feature_dict = tf.io.parse_single_example(example_string, feature_description)
return feature_dict['en'], feature_dict['zh']
train_examples = tf.data.TFRecordDataset('./nmt/train.tfrecord').map(_parse_example)
count=0
for i in train_examples:
count +=1
count
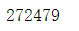
val_examples= tf.data.TFRecordDataset('./nmt/valid.tfrecord').map(_parse_example)
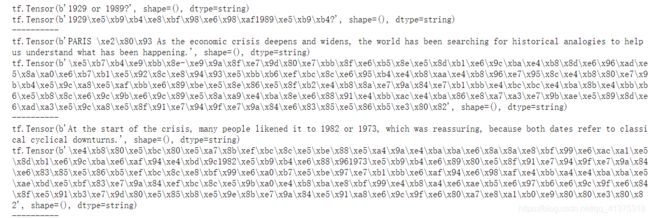
for en, zh in train_examples.take(3):
print(en)
print(zh)
print('-' * 10)
sample_examples = []
num_samples = 10
for en_t, zh_t in train_examples.take(num_samples):
en = en_t.numpy().decode("utf-8")
zh = zh_t.numpy().decode("utf-8")
print(en)
print(zh)
print('-' * 10)
sample_examples.append((en, zh))

output_dir = "./nmt"
en_vocab_file = os.path.join(output_dir, "en_vocab")
zh_vocab_file = os.path.join(output_dir, "zh_vocab")
checkpoint_path = os.path.join(output_dir, "checkpoints")
log_dir = os.path.join(output_dir, 'logs')
if not os.path.exists(output_dir):
os.makedirs(output_dir)
try:
subword_encoder_en = tfds.features.text.SubwordTextEncoder.load_from_file(en_vocab_file)
print(f"载入已建立的字典: {en_vocab_file}")
except:
print("没有已建立的字典,从头建立。")
subword_encoder_en = tfds.features.text.SubwordTextEncoder.build_from_corpus(
(en.numpy() for en, _ in train_examples),
target_vocab_size = 20000)
subword_encoder_en.save_to_file(en_vocab_file)
print(f"字典大小:{subword_encoder_en.vocab_size}")
print(f"前 10 个 subwords:{subword_encoder_en.subwords[:10]}")
print()

sample_string = 'Beijing is beautiful.'
indices = subword_encoder_en.encode(sample_string)
indices
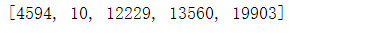
print("{0:10}{1:6}".format("Index", "Subword"))
print("-" * 15)
for idx in indices:
subword = subword_encoder_en.decode([idx])
print('{0:5}{1:6}'.format(idx, ' ' * 5 + subword))

indices = subword_encoder_en.encode(sample_string)
decoded_string = subword_encoder_en.decode(indices)
assert decoded_string == sample_string
pprint((sample_string, decoded_string))
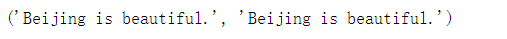
%%time
try:
subword_encoder_zh = tfds.features.text.SubwordTextEncoder.load_from_file(zh_vocab_file)
print(f"载入已建立的字典: {zh_vocab_file}")
except:
print("没有已建立的字典,从头建立。")
subword_encoder_zh = tfds.features.text.SubwordTextEncoder.build_from_corpus(
(zh.numpy() for _, zh in train_examples),
target_vocab_size=20000,
max_subword_length=1)
subword_encoder_zh.save_to_file(zh_vocab_file)
print(f"字典大小:{subword_encoder_zh.vocab_size}")
print(f"前 10 个 subwords:{subword_encoder_zh.subwords[:10]}")
print()

sample_string = sample_examples[0][1]
indices = subword_encoder_zh.encode(sample_string)
print(sample_string)
print(indices)

en = "The eurozone’s collapse forces a major realignment of European politics."
zh = "欧元区的瓦解强迫欧洲政治进行一次重大改组。"
en_indices = subword_encoder_en.encode(en)
zh_indices = subword_encoder_zh.encode(zh)
print("[英中原文](转化前)")
print(en)
print(zh)
print()
print('-' * 20)
print()
print("[英中序列](转化后)")
print(en_indices)
print(zh_indices)
