知识图谱 基于CRF的命名实体识别模型
基于CRF的命名实体识别模型
条件随机场 CRF
条件随机场 CRF 是在已知一组输入随机变量条件的情况下,输出另一组随机变量的条件概率分布模型;其前提是假设输出随机变量构成马尔可夫随机场;条件随机场可以应用于不同类型的标注问题,例如:单个目标的标注、序列结构的标注和图结构的标注等。
在给定训练集 x x x 和对应的标记序列 y y y ,以及多个特征函数需要学习 CRF 的模型参数 λ j , u k \lambda_j,u_k λj,uk 和 条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x) ,条件概率和模型参数的参数化形式如下:
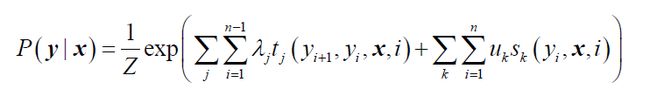
其中可以看出 CRF 有两类特征函数,一类是定义在 y y y 节点上的节点特征函数,这类特征函数只和当前节点有关如下式所示,其中 K K K 是定义在该节点的节点特征函数的总个数, i i i 是当前节点在序列的位置。
s k ( y i , x , i ) , k = 1 , 2 , . . . , K s_k(y_i,x,i), k = 1,2,...,K sk(yi,x,i),k=1,2,...,K
另一类是定义在 y y y 上下文的局部特征函数,这类特征函数只和当前节点和上一节点有关如下公式所示,其中 J J J 是定义在该节点的局部特征函数的总个数, i i i 是当前节点在序列的位置。
t j ( y i + 1 , y i , x , i ) , j = 1 , 2 , . . . , J t_j(y_{i+1},y_i,x,i), j = 1,2,...,J tj(yi+1,yi,x,i),j=1,2,...,J
基于CRF的命名实体识别
首先采用 CRF 模型对每个汉字标注对应实体类型的BIO标记,BIO 标记有 B-Person-人名的开始部分、I-Person-人名的中间部分、B-Organization-组织机构的开始部分、I-Organization-组织机构的中间部分和 O-非实体信息。例如:句子“白居易是中国杰出的诗人”,其对应的观察序列和标注序列如下所示:

根据 CRF 的特征函数可以构建上下文特征、词本身特征和词性特征等,示例如下:

基于 BiLSTM + CRF 的命名实体识别模型
模型实现原理
基于 BiLSTM + CRF 的命名实体识别模型如下所示,每个句子按照词序逐个输入双向LSTM中,结合正反向隐层输出得到每个词属于每个实体类别标签的概率,输入CRF中,优化目标函数,从而得到每个词所属的实体类别。
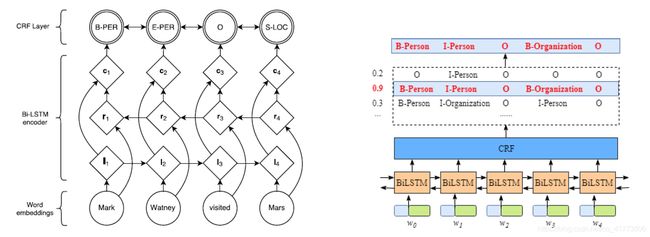
其中 BiLSTM 层的输入是每个词的向量表示;BiLSTM 层的输出是当前时刻的输入属于每个实体类别标签的概率。
CRF 层主要负责计算得分,根据上面的介绍 CRF 的两类特征函数分别计算得分,第一类仅仅和当前节点有关的特征函数 s k ( y i , x , i ) s_k(y_i,x,i) sk(yi,x,i) 计算 Emission 得分,如下图所示,例如图中 w 0 w_0 w0 被标记为 B-Person 的分数为1.5, w 1 w_1 w1 被标记为 B-Person 的分数为0.2。
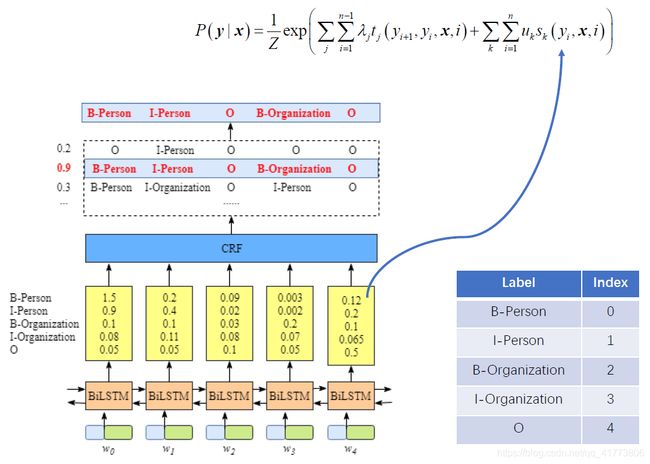
第二类和当前节点和上一节点有关的特征函数 t j ( y i + 1 , y i , x , i ) t_j(y_{i+1},y_i,x,i) tj(yi+1,yi,x,i) 计算 Transition 得分,如下图所示:

CRF 路径得分计算公式与示例如下图所示:

CRF 的损失函数计算公式如下所示,对于5个词组成的句子,假定类别标签有5个(B-Person, I-Person, B-Organization, I-Organization, O),其可能的类别序列有 5 5 = 3125 5^5 = 3125 55=3125 种,即 N = 3125

模型编码实现
文件目录介绍
-
data:微博命名实体数据集weiboNER包含.tran .dev .test训练集、开发集和测试集三部分。预训练好的 50 维的词向量gigaword_chn.all.a2b.uni.ite50.vec -
model:模型训练,包含bilstm_crf.py和crf.py -
utils:工具包,主要包含数据预处理相关方法 -
BiLSTM+CRF源码地址
程序运行逻辑
if __name__ == '__main__':
# 各类参数设置
''' ...
'''
# 数据处理
data_initialization(data, train_file, dev_file, test_file)
data.build_word_pretrain_emb(word_emb_file)
print('finish loading')
data.generate_instance(train_file, 'train')
print("train_file done")
data.generate_instance(dev_file, 'dev')
print("dev_file done")
data.generate_instance(test_file, 'test')
print("test_file done")
print('random seed: ' + str(seed_num))
# 模型的声明
model = BiLSTM_CRF(data)
print("打印模型可优化的参数名称")
for name, param in model.named_parameters():
if param.requires_grad:
print(name)
save_model_dir = "data/model_para/OntoNotes_lstm_gat_crf_epoch"
o_label2index = data.label_alphabet.instance2index['O']
train(data, model, save_model_dir, o_label2index)
数据处理
data_initialization() 调用 ../utils/data.py 中对应的方法构建训练集、开发集和测试集词典,并从数据中确定标签格式,weiboNER 数据中使用的是 BIO 标签。
build_word_pretrain_emb() 也是 ../utils/data.py 中的方法,用于载入预训练的词向量,在本实践中即为了加载 gigaword_chn.all.a2b.uni.ite50.vec。加载该预训练词向量依据data_initialization() 生成的数据词典生成一个 np.empty() 的数据对象,并根据数据词典的词汇进行填充,没有对应词汇则随机生成词汇自动填充。
generate_instance() 也是 ../utils/data.py 中的方法,用于生成词汇在词典中的 id 和词汇标签在标签集合中的 id ,便于输入到神经网络模型中进行训练。
模型训练
BiLSTM_CRF() 调用 ../model/bilstm_crf.py 中 BiLSTM_CRF 类的构造函数声明模型,并调用 train() 方法进行模型的训练。在训练过程中先使用 batchify_with_label() 方法将数据 tensor 化,然后将一个 batch 经过 tensor 化后的张量输入到模型中进行计算 neg_log_likelihood() 损失值等信息,并通过损失值的反传和模型参数进行模型优化。
模型训练的关键就在于 neg_log_likelihood() 方法如下所示,其中使用 _get_lstm_features()方法利用 LSTM 模型获得上面实现原理介绍的第一类特征函数的特征;使用 CRF 类中的初始化函数中的 torch.zeros() 获得第二类特征函数的特征;最后使用 CRF 类中的 neg_log_likelihood_loss() 计算上面实现原理介绍的 LSTM + CRF 的总损失值;使用 CRF 类中的 _viterbi_decode() 用于模型的检验和测试。
def neg_log_likelihood(self, batch_word, mask, batch_label, batch_wordlen):
"""
:param batch_word: ([batch_size, max_sentence_length])
:param mask: ([batch_size, max_sentence_length])
:param batch_label: ([batch_size, max_sentence_length])
:param batch_wordlen: ([batch_size])
:return:
loss : 类似 tensor(3052.6426, device='cuda:0', grad_fn=)
tag_seq: ([batch_size, max_sentence_length])
"""
lstm_feature = self._get_lstm_features(batch_word, batch_wordlen)
total_loss = self.crf.neg_log_likelihood_loss(lstm_feature, mask, batch_label)
scores, tag_seq = self.crf._viterbi_decode(lstm_feature, mask)
return total_loss, tag_seq
使用 CRF++ 训练命名实体识别模型
CRF++0.58 工具包安装
工具包下载
- CRF++官方下载地址:https://taku910.github.io/crfpp/
- window版本百度网盘链接:https://pan.baidu.com/s/1LBTUUJX8rHWeQqfZxJCJOw 提取码:9mzm
- Linux版本百度网盘链接:https://pan.baidu.com/s/1LkBUidOcIlLEltcTpQbkwQ 提取码:11s2
编译安装
在解码目录依次执行下面几条命令
sudo ./configure --prefix=/-yourfilepath-/crf # 安装到指定目录
make
make install
使用 CRF++0.58 工具包训练命名实体识别模型
进入到安装目录下 /-yourfilepath-/crf,进行模型训练,CRF源码地址
数据集准备
本命名实体识别模型使用 weiboNER 数据集包含一个训练集 weiboNER.train 和 weiboNER.test ,将这两个数据集移动到安装目录下 /-yourfilepath-/crf
特征模板设计
CRF++中的特征设计如下图所示:

如果觉得自定义特征模板设计有一定难度,可以参考 CRF++0.58 工具包中的 example 示例中包含的 template 文件,同时也可以将 example 中的执行脚本 exec.sh 拷贝到执行目录下/-yourfilepath-/crf。
模型训练与测试
模型训练可以在安装目录下 yourfilepath-/crf 用终端执行如下命令进行训练,也可以自行使用 ./bin/crf_leran 查看训练脚本的使用说明:
./bin/crf_learn -c 4.0 -m 50 template weiboNER.train model
模型测试可以在安装目录下 yourfilepath-/crf 用终端执行如下命令进行训练,也可以自行使用 ./bin/crf_test --help 查看测试脚本的使用说明:
./bin.crf_test -m model weiboNER.test > result.test
模型训练与测试完成之后,安装目录 yourfilepath-/crf 下应该有如下图所示的文件:

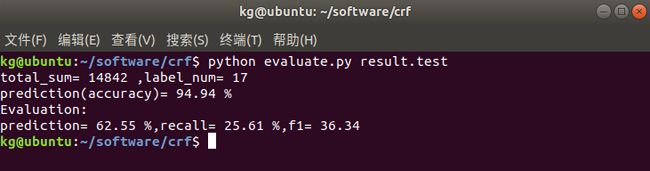
模型评估
使用 P,R 和 F1值评估使用 CRF++0.58 工具包训练的命名实体识别模型性能,评估源码如下所示:
import numpy as np
import os
import sys
def buildConfusionMatrix(result_file):
labels = []
with open(result_file,'r',encoding="utf-8") as f:
for i in f.readlines():
labels.append(i.strip().split())
f.close()
true_labels = []
predict_labels = []
label2idx = dict()
for i in labels:
if 0 == len(i):
continue
true_labels.append(i[1])
predict_labels.append(i[2])
if i[1] not in label2idx:
label2idx[i[1]] = len(label2idx)
confMatrix = np.zeros([len(label2idx),len(label2idx)],dtype=np.int32)
for i in range(len(true_labels)):
true_labels_idx = label2idx[true_labels[i]]
predict_labels_idx = label2idx[predict_labels[i]]
confMatrix[true_labels_idx][predict_labels_idx] += 1
return confMatrix, label2idx
def calculate_all_prediction(confMatrix):
'''
计算总精度:对角线上所有值除以总数
'''
total_sum = confMatrix.sum()
correct_sum = (np.diag(confMatrix)).sum()
prediction = round(100*float(correct_sum)/float(total_sum),2)
return prediction
def calculate_label_prediction(confMatrix,labelidx):
'''
计算某一个类标预测精度:该类被预测正确的数除以该类的总数
'''
label_total_sum = confMatrix.sum(axis=0)[labelidx]
label_correct_sum = confMatrix[labelidx][labelidx]
prediction = 0
if label_total_sum != 0:
prediction = round(100*float(label_correct_sum)/float(label_total_sum),2)
return prediction
def calculate_label_recall(confMatrix,labelidx):
'''
计算某一个类标的召回率:
'''
label_total_sum = confMatrix.sum(axis=1)[labelidx]
label_correct_sum = confMatrix[labelidx][labelidx]
recall = 0
if label_total_sum != 0:
recall = round(100*float(label_correct_sum)/float(label_total_sum),2)
return recall
def calculate_f1(prediction,recall):
if (prediction+recall)==0:
return 0
return round(2*prediction*recall/(prediction+recall),2)
def main():
#读取文件并转化为混淆矩阵,并返回label2idx
result_file = sys.argv[1]
confMatrix,label2idx = buildConfusionMatrix(result_file)
total_sum = confMatrix.sum()
all_prediction = calculate_all_prediction(confMatrix)
label_prediction = []
label_recall = []
print('total_sum=',total_sum,',label_num=',len(label2idx))
for i in label2idx:
label_prediction.append(calculate_label_prediction(confMatrix,label2idx[i]))
label_recall.append(calculate_label_recall(confMatrix,label2idx[i]))
for j in label2idx:
labelidx_i = label2idx[i]
label2idx_j = label2idx[j]
print('prediction(accuracy)=',all_prediction,'%')
p = round(np.array(label_prediction).sum()/len(label_prediction),2)
r = round(np.array(label_recall).sum()/len(label_prediction),2)
print('Evaluation:\nprediction=',p,'%,recall=',r,'%,f1=',calculate_f1(p,r))
if __name__ == "__main__":
main()
评估结果如下图所示: