数据传输效率优化
一、数据的序列化和反序列化
服务器对象Object------数据流---->客户端Object对象
传统序列化:
Serializable/Parcelable
效率低
像新闻端用户浏览时会下载大量图片和文字
采用传统数据传输会造成内存的浪费和CPU计算时间的占用
数据的序列化是程序代码里面必不可少的组成部分,当我们讨论到数据序列化的性能的时候,需要了解有哪些候选的方案,他们各自的优缺点是什么。首先什么是序列化?用下面的图来解释一下:
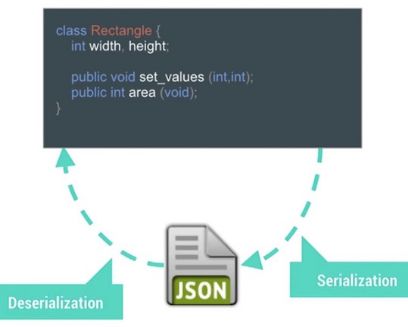
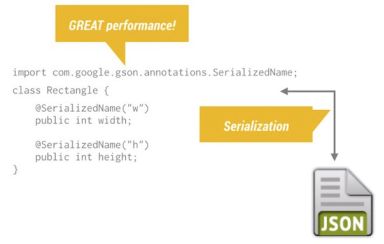
数据序列化的行为可能发生在数据传递过程中的任何阶段,例如网络传输,不同进程间数据传递,不同类之间的参数传递,把数据存储到磁盘上等等。通常情况下,我们会把那些需要序列化的类实现Serializable接口(如下图所示),但是这种传统的做法效率不高,实施的过程会消耗更多的内存。

但是我们如果使用GSON库来处理这个序列化的问题,不仅仅执行速度更快,内存的使用效率也更高。Android的XML布局文件会在编译的阶段被转换成更加复杂的格式,具备更加高效的执行性能与更高的内存使用效率。
下面介绍三个数据序列化的候选方案:
- Protocal Buffers:强大,灵活,但是对内存的消耗会比较大,并不是移动终端上的最佳选择。
- Nano-Proto-Buffers:基于Protocal,为移动终端做了特殊的优化,代码执行效率更高,内存使用效率更佳。
- FlatBuffers:这个开源库最开始是由Google研发的,专注于提供更优秀的性能。
上面这些方案在性能方面的数据对比如下图所示:
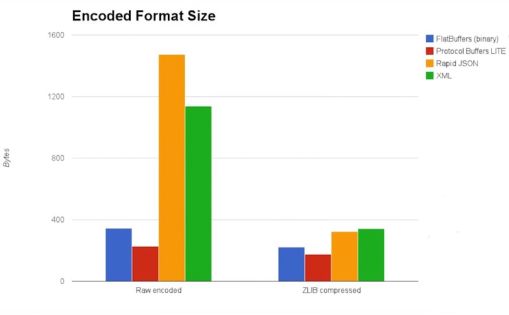
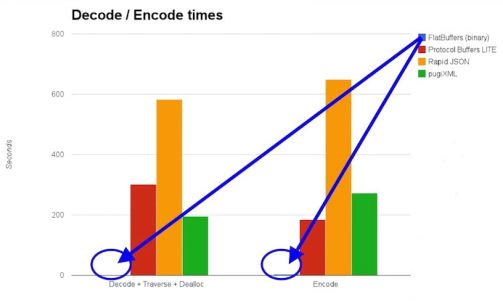
可见,FlatBuffers 几乎从空间和时间复杂度上完胜其他技术。
FlatBuffers 是一个开源的跨平台数据序列化库,可以应用到几乎任何语言(C++, C#, Go, Java, JavaScript, PHP, Python),最开始是 Google 为游戏或者其他对性能要求很高的应用开发的。
项目地址在 GitHub 上。 官方的文档地址。
FlatBuffer 的优点
FlatBuffer 相对于其他序列化技术,例如 XML,JSON,Protocol Buffers 等,有哪些优势呢?官方文档的说法如下:
1.直接读取序列化数据,而不需要解析(Parsing)或者解包(Unpacking):FlatBuffer 把数据层级结构保存在一个扁平化的二进制缓存(一维数组)中,同时能够保持直接获取里面的结构化数据,而不需要解析,并且还能保证数据结构变化的前后向兼容。
2.高效的内存使用和速度:FlatBuffer 使用过程中,不需要额外的内存,几乎接近原始数据在内存中的大小。
3.灵活:数据能够前后向兼容,并且能够灵活控制你的数据结构。
4.很少的代码侵入性:使用少量的自动生成的代码即可实现。
5.强数据类性,易于使用,跨平台,几乎语言无关。
官方提供了一个性能对比表如下:
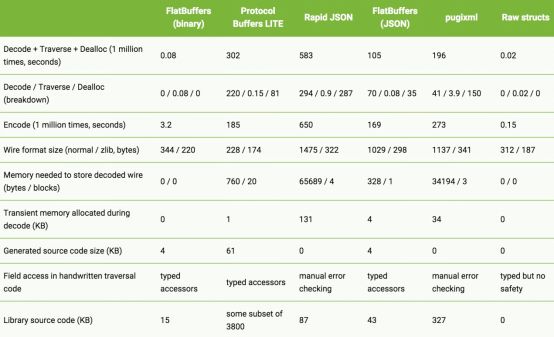
在做 Android 开发的时候,JSON 是最常用的数据序列化技术。我们知道,JSON 的可读性很强,但是序列化和反序列化性能却是最差的。解析的时候,JSON 解析器首先,需要在内存中初始化一个对应的数据结构,这个事件经常会消耗 100ms ~ 200ms2;解析过程中,要产生大量的临时变量,造成 Java 虚拟机的 GC 和内存抖动,解析 20KB 的数据,大概会消耗 100KB 的临时内存2。FlatBuffers 就解决了这些问题。
FlatBuffer 使用
下载文件编译工具1.下载源码$ git clone https://github.com/google/flatbuffers2.下载编译工具https://cmake.org/download/ 下载对应的cmake工具
参考网上:可以使用 cmake编译成flatc工具。但是暂时没有搞懂怎么编译?
最后,在这个地方可以下载windows的 exe可以运用文件。https://github.com/google/flatbuffers/releases比较坑的最新的1.7.1没有exe没有exe下载。也没有看后面的,以为需要自己编译。最后一不留 神看到1.7.0有下载。哎。。。。。。。。
编写描述使用 FlatBuffers 的 IDL 定义好数据结构 Schema,编写 Schema 的详细文档在这里 http://google.github.io/flatbuffers/flatbuffers_guide_writing_schema.html。参考一个例子
namespace com.haocai.app.flatbuffer;
table Items {
ItemId : long;
timestemp : int;
basic:[Basic];
}
table Basic{
id:int;
name:string;
email:int;
code:long;
isVip:bool;
count:int;
carList:[Car];
}
table Car{
id:long;
number:long;
describle:string;
}
root_type Items;
使用工具 生产相应数据类
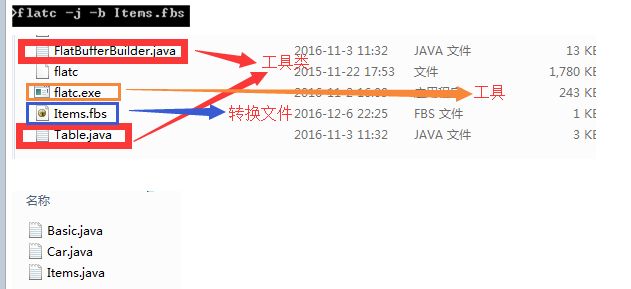
2.根据json生成和fbs 生成flatbuffer 二进制文件.bin
例如repos_json.json (有数据),对应的数据结构repos_schema.fbs ,生成repos_json.bin(二进制flatbuffer格式的)
$ ./flatc -j -b repos_schema.fbs repos_json.json
工程中使用
编写对应描述文件,翻译成对应语言的类。把对应的类, 放到你的工程中。
调用
MainActivity.Java
public class MainActivity extends AppCompatActivity {
private static final String TAG ="main" ;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void serialize(View v) {
//----------------序列化-------------
FlatBufferBuilder builder = new FlatBufferBuilder();
int id1 = builder.createString("兰博基尼");
//准备Car对象
int car1 = Car.createCar(builder,10001L,88888L,id1);
int id2 = builder.createString("奥迪A8");
//准备Car对象
int car2 = Car.createCar(builder,10001L,88888L,id2);
int id3 = builder.createString("奥迪A9");
//准备Car对象
int car3 = Car.createCar(builder,10001L,88888L,id3);
int[] cars = new int[3];
cars[0] = car1;
cars[1] = car2;
cars[2] = car3;
//创建Basic对象里面的Car集合
int carList = Basic.createCarListVector(builder,cars);
int name = builder.createString("kpioneer");
int email = builder.createString("[email protected]");
int basic = Basic.createBasic(builder,10,name,email,100L,true,100,carList);
int basicOffset = Items.createBasicVector(builder,new int[]{basic});
/**
* table Items {
ItemId : long;
timestemp : int;
basic:[Basic];
}
*/
Items.startItems(builder);
Items.addItemId(builder,1000L);
Items.addTimestemp(builder,2016);
Items.addBasic(builder,basicOffset);
int rootItems = Items.endItems(builder);
Items.finishItemsBuffer(builder,rootItems);
//============保存数据到文件=================
File sdcard = Environment.getExternalStorageDirectory();
//保存的路径
File file = new File(sdcard,"Items.txt");
if(file.exists()){
file.delete();
}
ByteBuffer data = builder.dataBuffer();
FileOutputStream out = null;
FileChannel channel = null;
try {
out = new FileOutputStream(file);
channel = out.getChannel();
while(data.hasRemaining()){
channel.write(data);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
if(out!=null){
out.close();
}
if(channel!=null){
channel.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
//===================反序列化=============================
FileInputStream fis = null;
FileChannel readChannel = null;
try {
fis = new FileInputStream(file);
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
readChannel = fis.getChannel();
int readBytes = 0;
while ((readBytes=readChannel.read(byteBuffer))!=-1){
System.out.println("读取数据个数:"+readBytes);
}
//把指针回到最初的状态,准备从byteBuffer当中读取数据
byteBuffer.flip();
//解析出二进制为Items对象。
Items items = Items.getRootAsItems(byteBuffer);
//读取数据测试看看是否跟保存的一致
Log.i(TAG,"items.id:"+items.ItemId());
Log.i(TAG,"items.timestemp:"+items.timestemp());
Basic basic2 = items.basic(0);
Log.i(TAG,"basic2.name:"+basic2.name());
Log.i(TAG,"basic2.email:"+basic2.email());
//carList
int length = basic2.carListLength();
for (int i=0;i基本原理

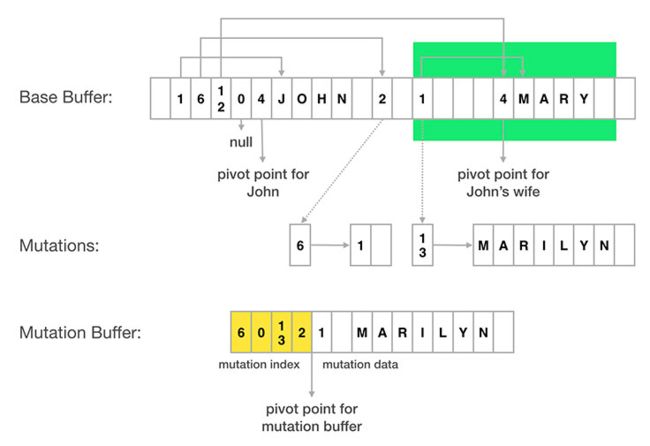
在上面的布局中,你需要注意:
每个对象都被分为两个部分:元数据的部分(或vtable)在轴心点的左边,真实的数据部分在右边。
每个字段对应于vtable中的一个槽,其中存储了那个字段的真实数据的偏移量。比如,John的table的第一个槽的值为1,表明了John的名字被存放在了距离Jonh的轴心点向右偏移一个字节的地方。
对于对象字段,vtable中的偏移量指向子对象的轴心点。比如,John的vtable中的第三个槽指向了Mary的轴心点。
要表示字段没有值,我们可以在一个vtable槽中使用一个0偏移量。
特别感谢:
动脑学院Ricky