推荐我的vue教程:VUE系列教程目录
通过上一篇文章我们的项目架构基本就出来了,让大家去看看关于JSZip,以及store.js的知识,因为store比较简单,所以不做说明了,这里会着重讲讲JSZip的使用。JSZip因为其代码有些地方比较混乱,所以我们将对其部分功能进行重写。
前言
在正式进行JSZip的说明之前,我们进入JSZip官网,如图:
乍一看全部英文,傻眼了,我也是英语比较差的一员,曾发誓此生绝不学英语的人,我只认识JS代码啊!于是去求助那些英语好的人,他们在旁边坐着给我翻译,我才知道这个鬼东西到底是什么玩意儿。
进来之后上面罗嗦了一推,告诉你很多语法,但是从来没有人告诉你这些语法有什么用,能搞什么,于是我只能猜了,大家一起猜
JSZip概述
首先他说要
var JSZip = require("jszip");
才能引用jszip,可是我们使用的VUE框架,用的编辑器是atom,还有严格的eslint语法校验ES6,而且只在需要的地方引用,所以不能这样引,同时他是使用这种方式:var zip = new JSZip();来创建zip对象的,所以我们把/page/property/upload_review.vue文件变为:
upload_review
在控制台我们可以看到,Zip的输出如下:

他的原型链上有十一个方法,这里我们使用它的loadAsync方法。从名字就知道这是用来异步加载的,我们点开这个方法:

看到这里,JS基础不好的同学应该会问[[scopes]]这个东西是什么?我只是告诉你这是域,这里我们不多加说明,有时间可以去看看你一直想知道的关于JavaScript scope的一切。我们不知道怎么用它的loadAsync方法,可以从官网上找,在我们打开的JSZip官网首页的最低下,如图:

我们可以看到Read a zip file怎么去读取zip文件.loadAsync(content).then(function (zip) {}),我们把/page/property/upload_review.vue文件变为:
upload_review
这里按理来说我们console.log(zip)输出的是加载完后的zip对象,但是却报错了Error: Can't find end of central directory : is this a zip file ?...,因为我们这样请求静态文件的方式是错误。
JSZip详解
因为方式错误,倒腾了很久才终于明白了,踩了无数的坑才明白究竟是怎么回事。于是,我们打开Read remote file,看到如图:

这里什么也没写,只告诉我们在这里右键---查看网页源代码,然后我们下翻到104行,如图:

我们可以看到这段代码
//=========================
// JSZipUtils
//=========================
JSZipUtils.getBinaryContent('/jszip/test/ref/text.zip', function(err, data) {
var elt = document.getElementById('jszip_utils');
if(err) {
showError(elt, err);
return;
}
try {
JSZip.loadAsync(data)
.then(function(zip) {
return zip.file("Hello.txt").async("string");
})
.then(function success(text) {
showContent(elt, text);
}, function error(e) {
showError(elt, e);
});
} catch(e) {
showError(elt, e);
}
});
大家一定会疑问JSZipUtils.getBinaryContent是干什么的?我们翻到24行,可以看到他引用了一个叫jszip-utils.js的js,如下
我们单击打开这个js,乍一看,哎呦这是什么东西?耐心,其实它一点都不难也就几十行代码,我们仔细看,就会发现,这里面有我们刚才疑问的JSZipUtils.getBinaryContent这个方法,如下:(有兴趣的可以看看,没兴趣的跳过这段代码)
JSZipUtils.getBinaryContent = function(path, callback) {
/*
* Here is the tricky part : getting the data.
* In firefox/chrome/opera/... setting the mimeType to 'text/plain; charset=x-user-defined'
* is enough, the result is in the standard xhr.responseText.
* cf https://developer.mozilla.org/En/XMLHttpRequest/Using_XMLHttpRequest#Receiving_binary_data_in_older_browsers
* In IE <= 9, we must use (the IE only) attribute responseBody
* (for binary data, its content is different from responseText).
* In IE 10, the 'charset=x-user-defined' trick doesn't work, only the
* responseType will work :
* http://msdn.microsoft.com/en-us/library/ie/hh673569%28v=vs.85%29.aspx#Binary_Object_upload_and_download
*
* I'd like to use jQuery to avoid this XHR madness, but it doesn't support
* the responseType attribute : http://bugs.jquery.com/ticket/11461
*/
try {
var xhr = createXHR();
xhr.open('GET', path, true);
// recent browsers
if ("responseType" in xhr) {
xhr.responseType = "arraybuffer";
}
// older browser
if(xhr.overrideMimeType) {
xhr.overrideMimeType("text/plain; charset=x-user-defined");
}
xhr.onreadystatechange = function(evt) {
var file, err;
// use `xhr` and not `this`... thanks IE
if (xhr.readyState === 4) {
if (xhr.status === 200 || xhr.status === 0) {
file = null;
err = null;
try {
file = JSZipUtils._getBinaryFromXHR(xhr);
} catch(e) {
err = new Error(e);
}
callback(err, file);
} else {
callback(new Error("Ajax error for " + path + " : " + this.status + " " + this.statusText), null);
}
}
};
xhr.send();
} catch (e) {
callback(new Error(e), null);
}
};
我们观察代码可以发现,它在做发送一个ajax请求,而请求的对象是一个地址对应的文件,咦?这不正式我们的需求吗?请求一个压缩文件。它的这段代码有点罗嗦,于是决定重写这段请求部分,用过aiax发送请求的同学应该不陌生,如果没有用过也不要紧,不难,自己去官网看看:ajax教程,当然考虑到前端圈里基础差的同学还是很多的,本人,也就耐心的给你们把ajax简单教教。
JSZipUtils重写,ajax请求压缩文件信息
首先,在/page/property/upload_review.vue文件中删掉var url = '/static/lookview.zip'代码后面的内容,然后,创建XMLHttpRequest 对象,XMLHttpRequest 是 AJAX 的基础。考虑到浏览器的兼容,代码如下:
var url = '/static/lookview.zip' // 我们请求的本地压缩文件
var xmlhttp = null
if (window.XMLHttpRequest) { // code for IE7+, Firefox, Chrome, Opera, Safari
/* eslint-disable no-new */
xmlhttp = new window.XMLHttpRequest()
} else { // code for IE6, IE5
/* eslint-disable no-new */
xmlhttp = new window.ActiveXObject('Microsoft.XMLHTTP')
}
注意:由于我们使用的是VUE框架和atom编辑器,不知道哪一个原因不让new一个对象,要是想new一个对象,必须在前面加上
/* eslint-disable no-new */东西
创建完XMLHttpRequest 对象后,就该向服务器发送请求啦,我们使用 XMLHttpRequest 对象的 open() :
xmlhttp.open('GET', url, true)
注意:到了这里我并没有决定在open之后将请求发送到服务器即
xmlhttp.send(),因为这里我们要解决跨域问题,以及一些高、低级浏览器的兼容。
于是,在open之后加上这段代码,
xmlhttp.withCredentials = true
// recent browsers
if ('responseType' in xmlhttp) {
xmlhttp.responseType = 'arraybuffer'
}
// older browser
if (xmlhttp.overrideMimeType) {
xmlhttp.overrideMimeType('text/plain; charset=x-user-defined')
}
处理了跨域问题,以及一些高、低级浏览器的兼容,这时我们再将请求发送到服务器,并且进行响应:
xmlhttp.send() // 将请求发送到服务器
xmlhttp.onreadystatechange = function () { // 当请求被发送到服务器时,我们需要执行一些基于响应的任务。每当 readyState 改变时,就会触发 onreadystatechange 事件。
if (xmlhttp.readyState === 4 && xmlhttp.status === 200) { // 当 readyState 等于 4 且状态为 200 时,表示响应已就绪
var file = xmlhttp.response || xmlhttp.responseText // 判断何种响应结果
console.log(file)
}
}
这样我们就拿到了相应的结果,即我们请求的压缩文件,下来就是继续刚才的异步加载了,于是,我们把/page/property/upload_review.vue文件变为:
upload_review
这下我们console.log(zip)就不再报错,里面就有东西了,如图:

但是我们又遇到了一个难题,你可以在上面的图片中看到,我们需要的目录竟然是这个样子的,这个JSZip竟然没有直接返回相关的目录信息,这就意味这我们得把这个东西想办法转化成我们需要的目录,怎么转换呢?转换成什么方式呢?还有一个棘手问题,如果你打开其中一个你就会发现,尼玛,文件信息在哪里?我的文件信息呢?靠,疯了。
本地缓存解难题
到了这里就不在考验你的编程了,开始考验你的逻辑思维及创世力了。
我们需要一个文件目录,那文件目录是什么?是树,没好好听课吧,幸好老子学习的时候没有偷懒。那js里面有哪个东西类似与树?是对象,好我们就把我们需要的文件转换对象的方式,创世力考验完了,下来就是逻辑思维了,我们怎么样才能得到文件信息呢?代码:
zip.forEach(function (relativePath, zipEntry) {
var fileName = zipEntry.name
// console.log(zipEntry.name)
if (zipEntry.name.slice(zipEntry.name.length - 1) !== '/') { // 后面是斜线的不要,因为是目录即文件夹
// console.log(zip.folder(zipEntry.name))
zip.file(zipEntry.name).async('base64').then(function success (text) {
}, function error (e) {
})
}
})
代码说明:我们通过
zip.file()方法获取信息,并通过.async()异步方式以base64编码的方式进行编码,以then方法的回调函数的第一个参数得到文件的以base64编码的二进制信息。
小伙伴一定会奇怪为什么不输出二进制信息呢?记住text不要输出,因为文件的信息很大控制台输出的话,浏览器崩都是小事,电脑性能差点会崩到死机。怎么才能解决崩溃的问题呢?
这又是一个坑,你们不知道我走到这一步花了一下午的时间,然后浏览器崩了,我也崩了,不可能重来吧!(当然重来也没有更好的方法),怎么办?想了几分钟,想办法把信息存到本地,而不要存在内存里这样就不会崩了,怎么存到本地?indexDB数据库就有了用武之地,indexDB怎么用呢?如果看过我的博客:web前端-在迷惘中的探索HTML5(二)本地存储之IndexDB,就明白了,这里不会去给你讲怎么用,只会给你代码,想知道自己去看啊。
zip.file(zipEntry.name).async('base64').then(function success (text) {
var indexDB = window.indexedDB // 创建indexDB数据库对象
var curDb = null
var req = indexDB.open('kangruideIndexDB')
req.onupgradeneeded = function () {
// 创建表的结构
var db = req.result
db.createObjectStore('upload_review', {
autoIncrement: 'file_id' // 指明当前数据id自增长(indexdb)
})
}
req.onsuccess = function () {
// 在成功后对象的result属性为本次申请的结果
curDb = req.result // curDb为数据库对象,用来操作数据表,维护数据表
var tran = curDb.transaction(['upload_review'], 'readwrite')
var objectStore = tran.objectStore('upload_review')
// 把text信息放入这个对象里
var zipFile = {
file_name: fileName,
file_content: text
}
var adduser = objectStore.add(zipFile) // 为当前数据表增加记录
adduser.onsuccess = function () {
}
}, function error (e) {
})
到了这里你打开浏览器的本地存储,会看到如图:
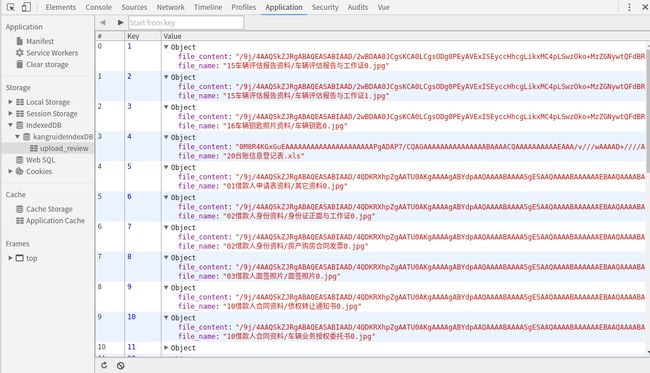
小伙伴说既然你都存进去了取出来渲染到页面上,不就完了,是啊要求简单一点到这里想办法读取就完了,可是你们真的以为把它直接渲染到页面上,浏览器就不会崩了?所以我们不能直接进行读取,什么时候读取最适合呢?思考思考,那就是我们有目录,进去了以后在打开某一个具体的文件时,读取这个具体文件这一个单独的文件时,因为信息量少,所以才不会崩,当然如果你拿一个单独文件20M以上,他还是会崩的,但是那种东西不会前端来进行解析的,因为那是后端的事,是服务器处理的。
获取信息后的目录实现
我们上面只是简单说了说采用什么方法实现目录树的构建,可是具体该怎么弄?上面我们在forEach的时候,if (zipEntry.name.slice(zipEntry.name.length - 1) !== '/')拿到了文件名并剔除了文件夹。举个例子,大家可以想想这样是不是只留下了类似与01借款人申请表资料/实例/申请表与工作证0.jpg这个样子的文件名,我们发现这里有它的路径信息(即申请表与工作证0.jpg的上一层是实例而实例绝对是文件夹,包括01借款人申请表资料),我们把所有包含01借款人申请表资料的路径信息拿出来,不就相当与把01借款人申请表资料文件目录底下有那些文件不久知道了,但是我们怎么对它进行处理?答案还是对象。
意思就是这个样子:
01借款人申请表资料: {
'其它资料0.jpg': '其它资料0.jpg',
'申请表与工作证0.jpg': '申请表与工作证0.jpg',
'实例': {
'申请表与工作证0.jpg': '申请表与工作证0.jpg'
}
}
是不是一幕了然?我们只需要对类似与这个的目录对象进行处理,即判断对象的键值有没有文件后缀就知道它是文件夹还是文件以及究竟是什么文件或者对象属性的值是不是对象就知道他是不是文件夹,是不是就豁然开朗了,虽然后面还有很多麻烦事,但是当你走到这里,方向就没有走错,下来只是怎么把路径信息变成这样,以及具体的细节处理了。
对象树构建目录树
下来就是处理路径信息变为对象树了,我们继续修改/page/property/upload_review.vue文件:
返回
zip在线预览
您的浏览器不支持在线预览,请您下载预览
文件预览
-
{{keys}}
小说明:会VUE的小伙伴会问,
var fileObj = JSON.parse(JSON.stringify(self.file_obj))
self.file_obj = JSON.parse(JSON.stringify(fileObj))
这样写是什么意思?因为对象的相等是指针指向同一块内存,当其中一个变化,共享的都变化,所以我们需要进行深度拷贝,即指向各自的内存空间,当然你使用数组时也会出现这样的问题。
啊,累死了,到此运行后效果如图:
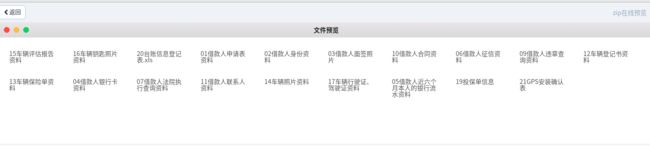
而我们构建的对象树,如图:
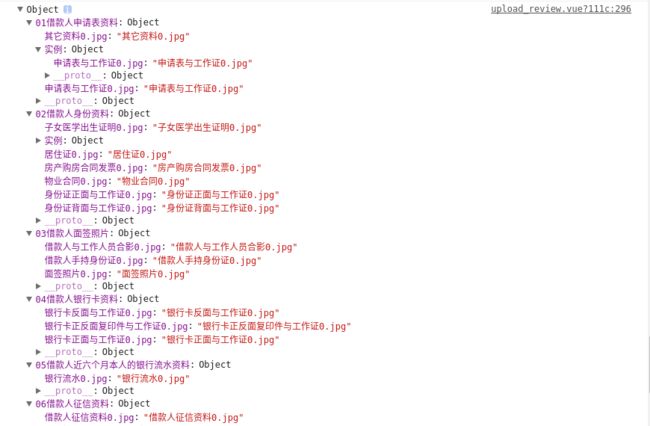
到了这里解决了百分之五十的问题,小伙伴们可以去检查看看目录是否对应。
小结
到了这里我写了四个多小时的博客,终于写了一半了,我们掌握了怎么用indexDB,掌握了JSZip,以及ajax还有VUE的整体构建,小伙伴们请进行实战操作,不然,你永远也学不会,祝大家学习愉快。
提示:在最近几天我会慢慢附上VUE系列教程的其他后续篇幅,后面还有精彩敬请期待,请大家关注我的专题:web前端。如有意见可以进行评论,每一条评论我都会认真对待。