【Hadoop学习笔记】大数据框架原理及主要工具概述
一、大数据原理
大数据技术与工程开发技术在架构上有很大的不同
- 大数据技术当然更关系数据,相关架构也都是围绕着数据展开,重要要考虑如何存储、计算、传输大规模的数据等;而工程端的计算处理模型都是“输入-> 计算-> 输出”模型。
- 最大的不同点就是工程技术程序是主体,数据是传输对象,将数据输入后工程才开始计算,然后输出结果。而面临PB级别的大数据计算任务,再去搬移数据,无论读取、传输、处理已经任何服务器的网络贷款、磁盘、内存可以承载的工作,所以大数据技术的没有遵循工程端的设计思想,从移动数据转变为移动计算,因为程序的大小远比数据要小很多。
结论 :移动成本也更划算
移动计算程序到数据所在位置进行计算简要过程如下:
1.需要处理的大规模数据存储到服务器集群所在的服务器上
使用HDFS分布式文件存储系统,将文件分成多个块,以块为单位存储到服务器上
2.数据引擎根据不同服务器的计算能力,为每天服务器启动分布式任务执行进程,等待分配任务;
3.将打包的数据计算程序(MapReduce程序或者spark程序)打包;
4.使用大数据执行启动数据计算程序包,首先解析程序要处理的数据,拆分成若干片(Split),每一个数据片都分配给一个任务执行进程处理
5.任务执行进行接收到任务后,会看是否已经有了计算程序包,没有的话去下载程序包;
6.并行计算处理,将结果汇总
二、大数据存储方案——HDFS
1. 主要问题
数据存储都需要解决三个问题
(1) 数据存储容量
(2)数据读写速度
(3)数据可靠性
2. HDFS原理
HDFS的解决方案学习可以参考存储的解决方案——RAID方案;
RAID是通过磁盘阵列去解决存储的读写性能,是一种垂直扩展的解决方案,HDFS是将这种思想运用到了水平扩展的方向上。
HDFS架构
和 RAID 在多个磁盘上进行文件存储及并行读写的思路一样,HDFS 是在一个大规模分布式服务器集群上,对数据分片后进行并行读写及冗余存储。因为 HDFS 可以部署在一个比较大的服务器集群上,集群中所有服务器的磁盘都可供 HDFS 使用,所以整个 HDFS 的存储空间可以达到 PB 级容量。
HDFS有两个角色组成,NameNode节点和 DataNode节点
DataNode负责文件数据的存储与读写操作,HDFS将文件数据分成若干数据块(Block),每个DataNode存储一部分的Block,这样整个文件就分布存储在整个的DataNode集群中。
NameNode负责整个大数据文件系统的元数据管理(MetaData),包括文件路径名、数据块的ID以及存储位置等信息;

3. 数据存储高可用方案
(1)数据存储故障容错
HDFS的应对措施是存储数据块计算并存储校验和(CheckSum),读取数据的时候也会校验此信息,如果不一致则会从备份的datanode中获取数据。
(2)磁盘故障容错
DataNode如果检测到模块磁盘损坏,则会将相应的blockid上报给namenode,由namenode分配任务将这些数据的备份复制出一份备份数据。
(3)DataNode故障容错
nameNode与DataNode保持心跳机制,当发现dataNode出现宕机后,则会对对应dataNode数据找出相应的备份,并按照用户设置数量复制出新的备份数据,保证高可用;
(4)NameNode高可用方案

三、MapReduce计算框架
1. MapReduce既是一个编程模型,也是一个计算框架了;
MapReduce分为Map和Reduce两个阶段,
(1)Map的主要输入是一对
(2)然后将Key相同的
(3)再讲这个结果输出给reduce,经过计算输出0个或多个
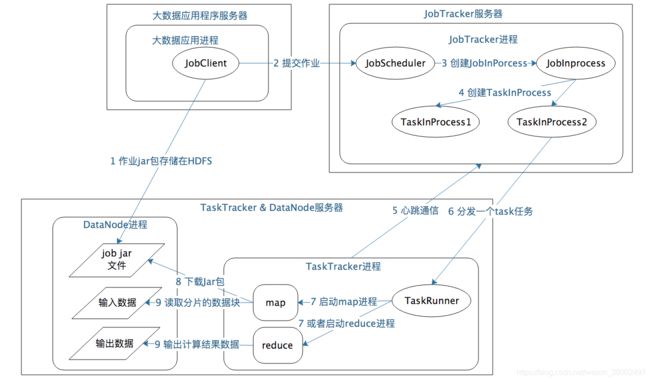
2. MapReduce的数据计算过程
MapReduce计算过程涉及三个关键进程
(1)大数据应用进程
这个进程是启动MapReduce程序的主入口,包括指定Map和Reduce类,处理输入输出文件路径等;并提交作业给Hadoop集群就是下面的JobTracker进程。此进程是用户启动的MapReduce进程。
(2)JobTracker进程
JobTracker进程根据要处理的输入数据量,发送指令到TaskTracker 进程启动相应数量的 Map 和 Reduce 进程任务,并管理整个作业生命周期的任务调度和监控;
JobTracker是 Hadoop 集群的常驻进程,在整个 Hadoop 集群全局唯一。
(3)TaskTracker进程
TaskTracker进程负责启动和管理 Map 进程以及 Reduce 进程。因为需要每个数据块都有对应的 map 函数,TaskTracker 进程通常和 HDFS 的 DataNode 进程启动在同一个服务器。
MapReduce整体流程
2. 数据合并和连接机制
Map的输出与reduce的输入之间是通过MapReduce计算框架处理数据合并和链接操作的,这个过程叫做shuffle。
shuffle过程:

每个 Map 任务的计算结果都会写入到本地文件系统,等 Map 任务快要计算完成的时候,MapReduce 计算框架会启动 shuffle 过程,在 Map 任务进程调用一个 Partitioner 接口,对 Map 产生的每个
map 输出的
分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle
四、大数据资源调用框架——Yarn

五、Hive——大数据SQL执行解释器
Hive就是将SQL解析为可以执行的MapReduce计算过程。
1.Hive架构
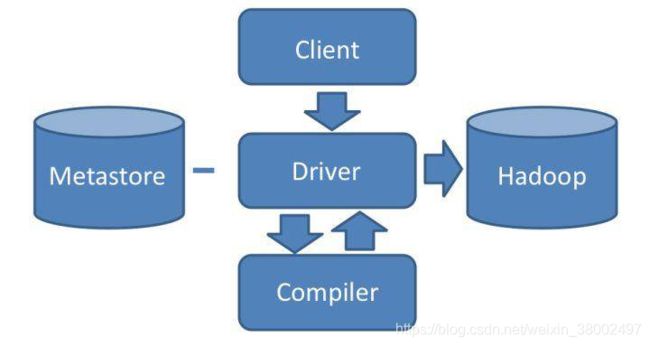
通过 Client提交SQL给Driver,如果是DDL的语句,则通过metastore元数据组件存储记录,一般是关系型数据库实现,存储表名,字段名,字段类型,关联的HDFS文件的路径等meta信息
如果是DQL语句,Driver则就提交给自己的编译器Complier进行语法分析、语法解析、语法优化系列操作,生成MapReduce作业提交Hadoop MapReduce集群处理
PS:join操作 ,Hive通过shuffle阶段进行结果的整合后,将相同key的结果统一reduce实现。

六、Spark——替代MapReduce的大数据计算框架
先说一个数字 ,Spark比MapReduce快了100多倍;
(一)Spark核心计算流程

主要过程:
- 首先,Spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext
初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG
图,切分成最小的执行单位也就是计算任务。 - 然后 Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager
收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。 - Worker 收到信息以后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver
通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。 - Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver
的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
Spark设计核心思想
- RDD是Spark计算的核心,也就是弹性数据集;
MapReduce是面向过程的大数据计算
Spark则是面向对象的大数据计算
Spark编程考虑的是如何将一个RDD对象转换成另外一个RDD对象,重心放在RDD上;
- RDD函数分为转换函数和执行函数两种,转换函数返回RDD,执行函数则不返回;
- Spark将计算过程拆分为多个stage,形成DAG(有向无环图),Spark调度器根据DAG执行计算阶段;

计算阶段的拆分是依据shuffle而不是转换函数的类型;
- 优先使用内存中的数据中间计算结果进行计算,减少HDFS的io,更高效
(二)Spark计算快于MapReduce的原因
- RDD 的编程模型更简单
- DAG 切分的多阶段计算过程更快速
- 使用内存存储中间计算结果更高效
这三个特性使得 Spark 相对 Hadoop MapReduce 可以有更快的执行速度,以及更简单的编程实现。
备注:Spark的生态成员

七、HBase——BigTable的开源实现
Hbase是NoSQL数据库,关系型数据库在存储数据的同时要根据业务逻辑维护数据结构,而NoSQL比较单纯,聚焦在存储数据读取数据上,业务逻辑应该交由程序去处理;
Hbase底层是HDFS存储数据,他解决的就是HDFS数据的实时查询场景问题。
HBase是如何承载实时查询的呢,主要有以下几个特点
- HBase是可弹性扩展的
- HBase的高性能存储
1.HBase是可弹性扩展的
(1) 可弹性扩展架构

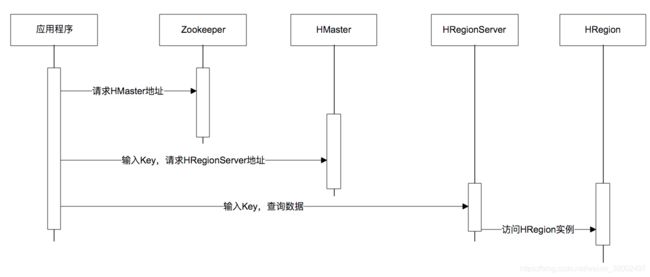
由图可见,HBase扩展的核心是可分裂的HRegion,HRegion是HBase的负责存储的主要进程,应用程序对数据的读写都是通过HRegion完成的。
每个 HRegion 中存储一段 Key 值区间[key1, key2) 的数据,所有 HRegion 的信息,包括存储的 Key 值区间、所在 HRegionServer 地址、访问端口号等,都记录在 HMaster 服务器上。为了保证 HMaster 的高可用,HBase 会启动多个 HMaster,并通过 ZooKeeper 选举出一个主服务器。
HMaster是负责管理和找到对应的HRegion,通过Zookeeper保证高可用,获取流程如下图
(2) 可扩展的数据模型
HBase是通过列族为存储方案,实际上就是把字段的名称、字段值,以Key-Value的方式存储的HBase中,写入的时候才指定,已达到随意扩展的目的。
2. HBase的高性能存储
根本原理: 连续读写很快,随机读写很慢
Hbase采用LSM树的数据结构存储
写入的时候以Log方式连续写入,然后一步对磁盘上的多个LSM进行合并;
如下图

读取的时候优先读取内存中的LSM树,没有才去访问磁盘;
八、流式计算解决方案——Storm,Flink、Spark Streaming
实时计算其实就是解决计算的速度问题,在流式计算方案出来之前,已经有了相关的解决方案就是通过消息队列解决时效性的问题
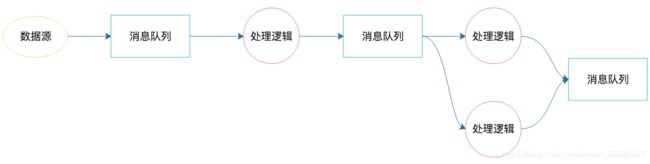
1.Storm
Storm就是基于解决消息传输、流程处理的流计算引擎,将固定的模式抽象成为框架,让开发者专注于业务逻辑,架构如下图
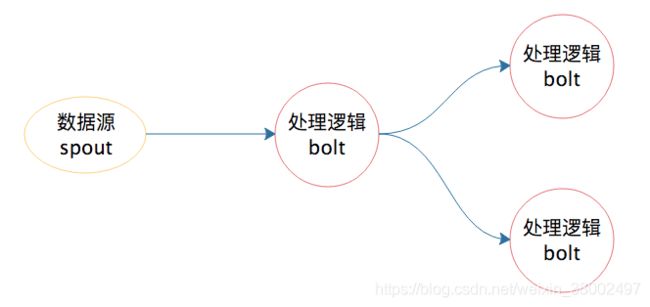
有了 Storm 后,开发者无需再关注数据的流转、消息的处理和消费,只要编程开发好数据处理的逻辑 bolt 和数据源的逻辑 spout,以及它们之间的拓扑逻辑关系 toplogy,提交到 Storm 上运行就可以了。

nimbus 是集群的 Master,负责集群管理、任务分配等。supervisor 是 Slave,是真正完成计算的地方,每个 supervisor 启动多个 worker 进程,每个 worker 上运行多个 task,而 task 就是 spout 或者 bolt。supervisor 和 nimbus 通过 ZooKeeper 完成任务分配、心跳检测等操作。
2.Sparking Stream
Spark Streaming 巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在一起,当作一批数据,再去交给 Spark 去处理。下图这张图描述了 Spark Streaming 将数据分段、分批的过程。

其实Spark Streaming负责将流数据转换成小的批数据,交给Spark处理,只要数据足够小,就可以达到实时计算的效果;
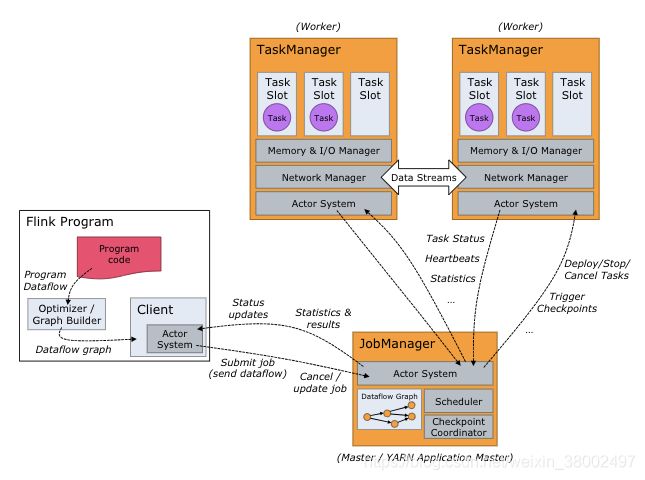
2.Flink
Flink是直接按照流处理计算的方式设计,即使是读取出来的数据,也当做流。所以Flink既可以用作实时计算,也可以作为批处理系统;
(1)如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
(2)如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile("/path/to/file");
(3) Flink的各种计算都是在DataSet或者DataStream上进行,flink会对处理的数据流进行window操作,切换成一个个小的window里,进行处理。整体交媾如下